langchain 正式学习1
langchain 正式学习1
-
langchain的pypi:
https://pypi.org/project/langchain/
让New Bing 给我推荐些博客和笔记
好的,我为你找到了一些LangChain的学习笔记,你可以参考以下的链接:
- LangChain: Introduction and Getting Started | Pinecone:这篇文章介绍了LangChain的基本概念和功能,以及如何使用LangChain来调用不同的语言模型¹。
- Quickstart Guide — \uD83E\uDD9C\uD83D\uDD17 LangChain 0.0.118:这篇指南教你如何安装LangChain,以及如何使用LangChain提供的各种模块来构建语言模型应用²。
- Quickstart Guide | Langchain:这篇指南教你如何使用LangChain的JavaScript版本,以及如何创建和运行链式语言模型³。
- LangChain AI Handbook | Pinecone:这是一个系列文章,涵盖了LangChain的各个方面,比如提示模板、对话记忆、代理等⁴。
希望这些学习笔记对你有用!
Source: Conversation with Bing, 2023/3/23(1) LangChain: Introduction and Getting Started | Pinecone. https://www.pinecone.io/learn/langchain-intro/ Accessed 2023/3/23.
(2) Quickstart Guide — LangChain 0.0.118. https://langchain.readthedocs.io/en/latest/getting_started/getting_started.html Accessed 2023/3/23.
(3) Quickstart Guide | Langchain. https://hwchase17.github.io/langchainjs/docs/getting-started/ Accessed 2023/3/23.
(4) LangChain AI Handbook | Pinecone. https://www.pinecone.io/learn/langchain/ Accessed 2023/3/23.
-
油管一个不错的入门教程
(145) Getting Started with GPT-3 vs. Open Source LLMs - LangChain #1 - YouTube
-
我就跟着这个博主学啦,这是他视频对应的文档
LangChain: Introduction and Getting Started | Pinecone
下面我的工作主要是搬运(当然也记录自己的东西
Langchain简介
-
博主给的介绍如下
LangChain appeared around the same time. Its creator, Harrison Chase, made the first commit in late October 2022. Leaving a short couple of months of development before getting caught in the LLM wave.
Despite being early days for the library, it is already packed full of incredible features for building amazing tools around the core of LLMs. In this article, we’ll introduce the library and start with the most straightforward component offered by LangChain — LLMs.
langchain + huggingface
我还是用我上次创建的huggingface虚拟环境
首先需要huggingface账号,然后创建 ACCESS TOKEN
然后所在的虚拟环境需要pip install huggingface_hub、pip install langchain
首先引入自己的TOKEN (这样的写法应该并不安全,最好还是写在配置文件里?)
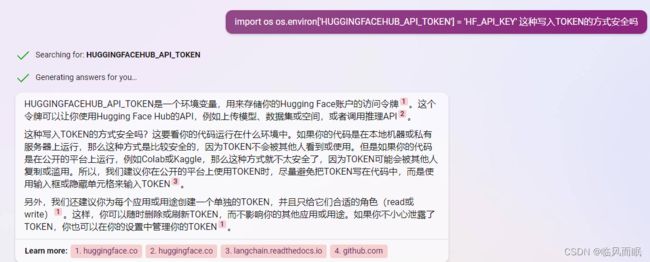
import os
os.environ['HUGGINGFACEHUB_API_TOKEN'] = 'HF_API_KEY'
We can then generate text using a HF Hub model (we’ll use
google/flan-t5-x1) using the Inference API built into Hugging Face Hub.
_接着我们可以使用 Hugging Face Hub 中内置的推理 API,使用 HF Hub 模型(这里选用
google/flan-t5-x1)生成文本。
英文表达积累
- Large Language Models (LLMs) entered the world stage with the release of OpenAI’s GPT-3 in 2020 [1]. Since then, they’ve enjoyed a steady growth in popularity.
That is until late 2022. Interest in LLMs and the broader discipline of generative AI has skyrocketed. The reasons for this are likely the continuous upward momentum of significant advances in LLMs.
We saw the dramatic news about Google’s “sentient” LaMDA chatbot. The first high-performance and open-source LLM called BLOOM was released. OpenAI released their next-generation text embedding model and the next generation of “GPT-3.5” models.
After all these giant leaps forward in the LLM space, OpenAI released ChatGPT — thrusting LLMs into the spotlight.
以下为Notion AI 的迭代翻译(prompt:有点僵硬,重新翻译
自从2020年OpenAI发布了GPT-3以来,大型语言模型(Large Language Models,LLM)逐渐在世界范围内受到关注。
直到2022年末,对LLM和生成AI领域的兴趣突然飙升。原因可能是LLM的不断提升带来的持续上升势头。
我们看到了关于Google“有感知”的LaMDA聊天机器人的重大新闻,第一个高性能开源LLM——BLOOM也发布了。OpenAI也推出了他们的下一代文本嵌入模型和下一代“GPT-3.5”模型。在LLM领域取得了这些巨大的飞跃之后,OpenAI推出了ChatGPT,将LLM推向了聚光灯下。
-
然后就可以调用了
from langchain import PromptTemplate, HuggingFaceHub, LLMChain # initialize HF LLM # 初始化HF LLM flan_t5 = HuggingFaceHub( repo_id="google/flan-t5-xl", # temperature是温度参数,值越小,生成的文本越有逻辑性,但是越不自然 model_kwargs={"temperature": 1e-10} ) # build prompt template for simple question-answering template = """Question: {question} Answer: """ prompt = PromptTemplate(template=template, input_variables=["question"]) llm_chain = LLMChain( prompt=prompt, llm=flan_t5 ) question = "Which NFL team won the Super Bowl in the 2010 season?" # Which NFL team won the Super Bowl in the 2010 season?翻译是:2010赛季的超级碗冠军是哪支NFL球队? questionChinese = "2010赛季的超级碗冠军是哪支NFL球队?" # print(llm_chain.run(questionChinese)) print(llm_chain.run(question))from langchain import PromptTemplate, HuggingFaceHub, LLMChain # initialize HF LLM # 初始化HF LLM flan_t5 = HuggingFaceHub( repo_id="google/flan-t5-xl", # temperature是温度参数,值越小,生成的文本越有逻辑性,但是越不自然 model_kwargs={"temperature": 1e-10} ) # build prompt template for simple question-answering template = """Question: {question} Answer: """ prompt = PromptTemplate(template=template, input_variables=["questijieiex返回的结果是
green bay packers试了试如果用中文, 会显示远程主机强制关闭连接…… ji
-
接下来尝试问多个问题
如果我们想问多个问题,可以通过传递一个字典对象列表来实现,其中字典必须包含在我们prompt模板中设置的输入变量(
"question"),该变量映射到我们想要问的问题。qs = [ {'question': "Which NFL team won the Super Bowl in the 2010 season?"}, {'question': "If I am 6 ft 4 inches, how tall am I in centimeters?"}, {'question': "Who was the 12th person on the moon?"}, {'question': "How many eyes does a blade of grass have?"} ] res = llm_chain.generate(qs) res返回如下
LLMResult(generations=[[Generation(text='green bay packers', generation_info=None)], [Generation(text='184', generation_info=None)], [Generation(text='john glenn', generation_info=None)], [Generation(text='one', generation_info=None)]], llm_output=None)看看
type(res):langchain.schema.LLMResult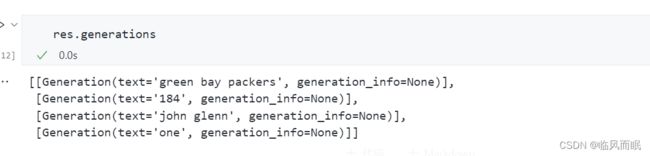
-
当然,把几个问题放在一个字符串也是可以的
multi_template = """Answer the following questions one at a time. Questions: {questions} Answers: """ long_prompt = PromptTemplate( template=multi_template, input_variables=["questions"] ) llm_chain = LLMChain( prompt=long_prompt, llm=flan_t5 ) qs_str = ( "Which NFL team won the Super Bowl in the 2010 season?\n" + "If I am 6 ft 4 inches, how tall am I in centimeters?\n" + "Who was the 12th person on the moon?" + "How many eyes does a blade of grass have?" ) print(llm_chain.run(qs_str))但是它的回答不太好噢…… 它的回答居然是把第二个问题重复了一遍……If I am 6 ft 4 inches, how tall am I in centimeters
OpenAI + langchain
-
首先是要有账号,有api key,然后环境里面
pip install openai -
然后可以写入环境中
import os os.environ['OPENAI_API_TOKEN'] = 'OPENAI_API_KEY'os.environ是Python中的一个对象,它表示用户的环境变量¹。它返回一个字典,字典的键是环境变量的名字,字典的值是环境变量的值²。os.environ像一个Python字典一样,所以可以进行所有常见的字典操作,例如get和set¹。我们也可以修改os.environ,但是任何修改只对当前进程有效,不会永久改变环境变量的值¹。
例如,如果我们想获取HOME环境变量的值,我们可以这样写:
import os home = os.environ.get("HOME") print("HOME:", home)这样就可以打印出HOME环境变量的值了。
Source: Conversation with Bing, 2023/3/23(1) Python | os.environ object - GeeksforGeeks. https://www.geeksforgeeks.org/python-os-environ-object/ Accessed 2023/3/23.
(2) os — Miscellaneous operating system interfaces — Python 3.11.2 … https://docs.python.org/3/library/os.html Accessed 2023/3/23.
(3) Os.environ - The Environment Variables Mapping In Python. https://pythontic.com/modules/os/environ Accessed 2023/3/23.
(4) How can I access the environment variables in Python using the os … https://blog.gitnux.com/code/python-os-environ-object/ Accessed 2023/3/23. -
接下来我们选择
text-davinci-003来试试 , 模板和之前hugging face用的是一样的from langchain.llms import OpenAI davinci = OpenAI(model_name='text-davinci-003') -
看看前面同样的问题,用这个模型会返回什么结果
llm_chain = LLMChain( prompt=prompt, llm=davinci ) print(llm_chain.run(question))返回的结果:
The New Orleans Saints won the Super Bowl in the 2010 season. -
重复之前做的事情
qs = [ {'question': "Which NFL team won the Super Bowl in the 2010 season?"}, {'question': "If I am 6 ft 4 inches, how tall am I in centimeters?"}, {'question': "Who was the 12th person on the moon?"}, {'question': "How many eyes does a blade of grass have?"} ] llm_chain.generate(qs)LLMResult(generations=[[Generation(text=' The Green Bay Packers won the Super Bowl in the 2010 season.', generation_info={'finish_reason': 'stop', 'logprobs': None})], [Generation(text=' 193.04 cm', generation_info={'finish_reason': 'stop', 'logprobs': None})], [Generation(text=' Eugene A. Cernan was the 12th and last person to walk on the moon. He was part of the Apollo 17 mission, which launched on December 7, 1972.', generation_info={'finish_reason': 'stop', 'logprobs': None})], [Generation(text=' A blade of grass does not have any eyes.', generation_info={'finish_reason': 'stop', 'logprobs': None})]], llm_output={'token_usage': {'total_tokens': 138, 'completion_tokens': 63, 'prompt_tokens': 75}, 'model_name': 'text-davinci-003'})qs = [ "Which NFL team won the Super Bowl in the 2010 season?", "If I am 6 ft 4 inches, how tall am I in centimeters?", "Who was the 12th person on the moon?", "How many eyes does a blade of grass have?" ] print(llm_chain.run(qs))1. The New Orleans Saints 2. 193 centimeters 3. Harrison Schmitt 4. None -
放到一个字符串里面
multi_template = """Answer the following questions one at a time. Questions: {questions} Answers: """ long_prompt = PromptTemplate( template=multi_template, input_variables=["questions"] ) llm_chain = LLMChain( prompt=long_prompt, llm=davinci ) qs_str = ( "Which NFL team won the Super Bowl in the 2010 season?\n" + "If I am 6 ft 4 inches, how tall am I in centimeters?\n" + "Who was the 12th person on the moon?" + "How many eyes does a blade of grass have?" ) print(llm_chain.run(qs_str))The New Orleans Saints won the Super Bowl in the 2010 season. If you are 6 ft 4 inches, you are 193.04 centimeters tall. The 12th person on the moon was Harrison Schmitt. A blade of grass does not have eyes.