阿里巴巴2017实习生笔试题(二)——总结
具体题目来自阿里巴巴2017实习生笔试题,本文仅为整理与汇总。

本题应该往C++的多态性进行理解,多态中的动态链接在执行时进行,静态链接在编译时进行。其中A、C、D 都是动态链接的优点,B 时静态链接的优点。
减少页面交换可从如下角度进行理解:
Y个程序中使用了相同的代码(假设这部分代码占用X个内存页),如果使用的是静态链接,这些相同的代码在各程序运行时必须重新加载到内存,那么Y个程序加载这部分代码会至少造成 Y*X 次缺页。如果使用的是动态链接库,运行这些程序时,这个动态链接库可能只需要被加载到内存一次,最少可能只造成 X 次缺页。

利用快排的patition思想,基于数组的第k个数来调整,将比第k个数小的都位于数组的左边,比第k个数大的都调整到数组的右边,这样调整后,位于数组右边的k个数最大的k个数(这k个数不一定是排好序的)
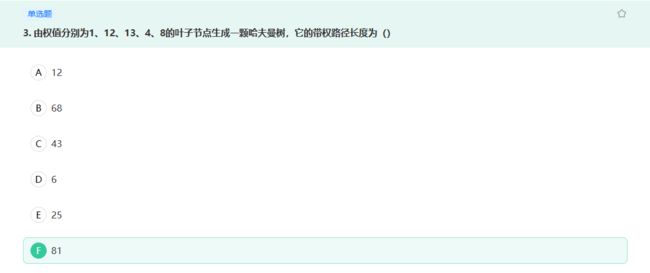
哈夫曼树每次都将最小的两个节点聚合成新节点,画出哈夫曼树并进行计算即可。
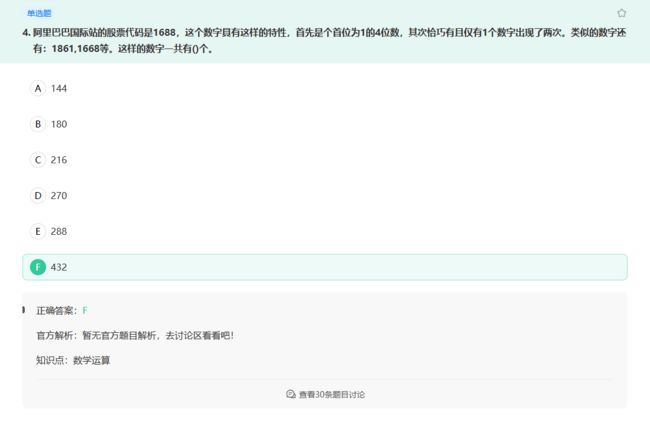
8 × 9 × 3 + 8 × 9 × 3 = 432 8\times 9\times 3 + 8\times 9\times 3 = 432 8×9×3+8×9×3=432

不改变选择选中的几率是 1 / 3 1/3 1/3,改变后选中几率为 2 / 3 2/3 2/3。

(1)程序直接访问方式跟循环检测IO方式,应该是一个意思吧,是最古老的方式。CPU和IO串行,每读一个字节(或字),CPU都需要不断检测状态寄存器的busy标志,当busy=1时,表示IO还没完成;当busy=0时,表示IO完成。此时读取一个字的过程才结束,接着读取下一个字。
(2)中断控制方式:循环检测先进些,IO设备和CPU可以并行工作,只有在开始IO和结束IO时,才需要CPU。但每次只能读取一个字。
(3)DMA方式:Direct Memory Access,直接存储器访问,比中断先进的地方是每次可以读取一个块,而不是一个字。
(4)通道方式:比DMA先进的地方是,每次可以处理多个块,而不只是一个块。
其中通道一次多个块,因此效率最高。
- 管道( pipe ):管道是一种半双工的通信方式,数据只能单向流动,而且只能在具有亲缘关系的进程间使用。进程的亲缘关系通常是指父子进程关系。
- 信号量( semophore ) : 信号量是一个计数器,可以用来控制多个进程对共享资源的访问。它常作为一种锁机制,防止某进程正在访问共享资源时,其他进程也访问该资源。因此,主要作为进程间以及同一进程内不同线程之间的同步手段。
- 消息队列( message queue ) : 消息队列是由消息的链表,存放在内核中并由消息队列标识符标识。消息队列克服了信号传递信息少、管道只能承载无格式字节流以及缓冲区大小受限等缺点。
- 共享内存( shared memory ) :共享内存就是映射一段能被其他进程所访问的内存,这段共享内存由一个进程创建,但多个进程都可以访问。共享内存是最快的 IPC 方式,它是针对其他进程间通信方式运行效率低而专门设计的。它往往与其他通信机制,如信号量,配合使用,来实现进程间的同步和通信。
- 套接字( socket ) : 套接口也是一种进程间通信机制,与其他通信机制不同的是,它可用于不同机器间的进程通信。
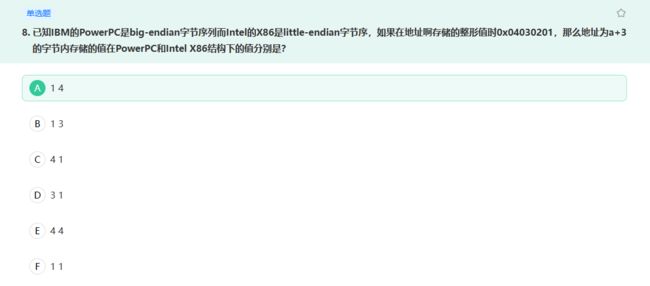
PowerPC 从大地址开始进行存储,故从 04 开始进行存储,因此 a + 3 中存放的是 01 。
Intel X86 从小地址开始进行存储,故从 01 开始进行存储,因此 a + 3 中存放的是 04 。
D的状态是断开连接

根据先序和中序的“根左右”、“左根右” 的顺序判断出二叉树的结构后进行后序遍历。
只有 F 中 A 肯定无法在 B 之前出栈。
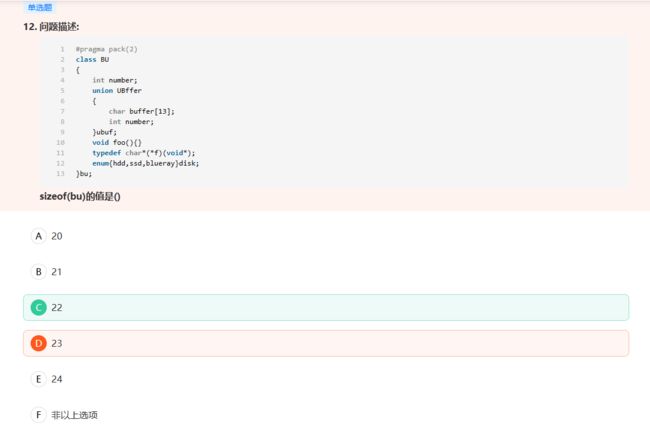
4 + 14 + 0 + 0 + 4 = 22 4+14 +0 +0 +4 = 22 4+14+0+0+4=22,其中 #pragma pack(2) ,因此为了实现内存对齐,需要将原先最长的char buffer[13]扩展到 14 位。enum类型的大小固定为4字节。
每个线程都有自己独立的线程上下文,包括线程ID,栈,栈指针,程序计数器,条件码和通用目的寄存器。
线程函数可以调用函数,而被调用函数中又是可以层层嵌套的,所以线程必须拥有自己的函数堆栈, 使得函数调用可以正常执行,不受其他线程的影响。

系统调用通过中断完成,这一过程中系统由用户态变为内核态(又程系统态)。 在内核态下,系统可以无限制的访问内核资源
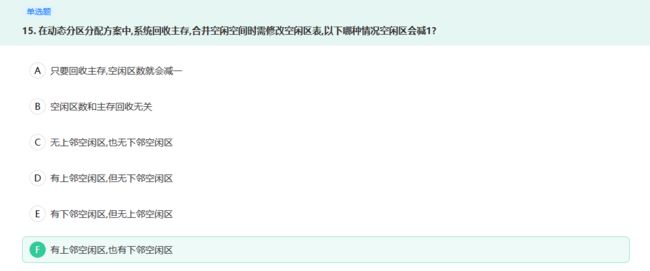
假设原来是2个空闲分区,新回收一个,发现前后都是空闲的,将三个合并为1个,最后结果为1个空闲分区,空闲分数个数减1

VLAN通过限制广播帧的转发范围,从而分割广播域。不同的VLAN进行通信需要用到路由器。VLAN只是局域网给用户提供的一种服务,而不是新型局域网。
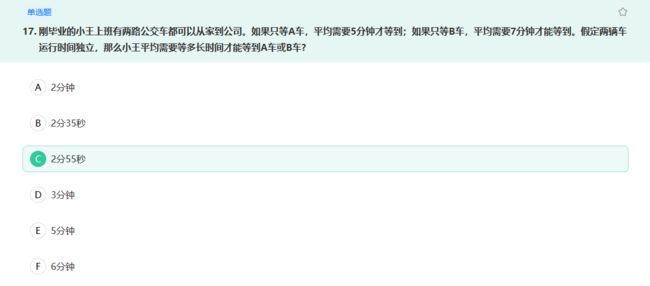
A车每分钟可以等来1/5辆;B车每分钟可以等来1/7辆,因为是相互独立的,相加,每分钟可以等来车12/35辆,那么等来1辆车需要的时间就是=1除以12/35=35/12min,故答案选择C。
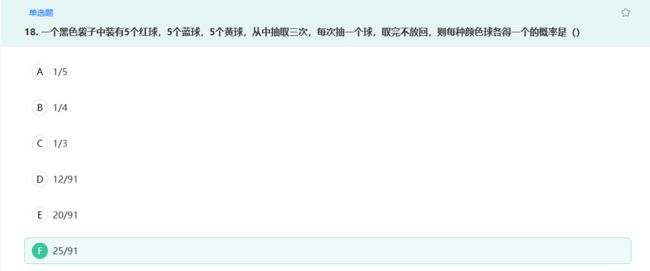
共15个球,第一次可以任意取。第二次从剩下的14个里面抽剩下的两种颜色,概率为10/14。第三次从剩下的13个里面抽剩下的一种颜色,概率为5/13。答案为10/14 * 5/13=25/91

- 在初始化中只有地址才能赋值给指针,因此*int p=0是指p指向地址0x00。
- int型数占4个字节,因此加6表示偏移了24个字节,结果的地址应为0x18,即是24。

题中已说明,电池损坏的条件是:至少存在一节电池已经放完电,且至少存在一节电池还剩100毫安以上的电量。
很显然,如果没有电池放完电,则不可能出现电池损坏的情况。而电池只有900毫安和1100毫安两种电量,所以如果放电量低于900毫安时不会有电池损坏,C 对。
电池的电量是有概率的,对于 n 节串联的电池,出现电池损坏是概率事件,不存在必然的情况,所以 ABFE 错。
损坏最多的情况应该是:1节电池为1100毫安,其他 n-1 节均为900毫安,最多损坏 n-1 节,D 错。
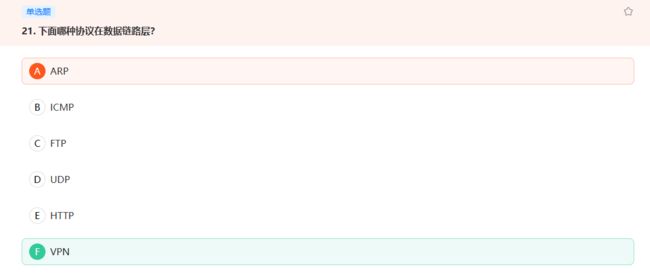
HTTP FTP在应用层
TCP UDP在传输层
ICMP,IGMP,IP,ARP在网络层
VPN协议在很多层都有,虚拟专用网VPN,数据链路层VPN,网络层VPN,SSL‐VPN 。
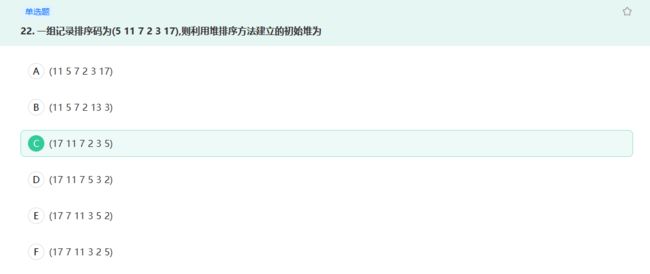
修改 17 的位置,最终与 5 进行交换。
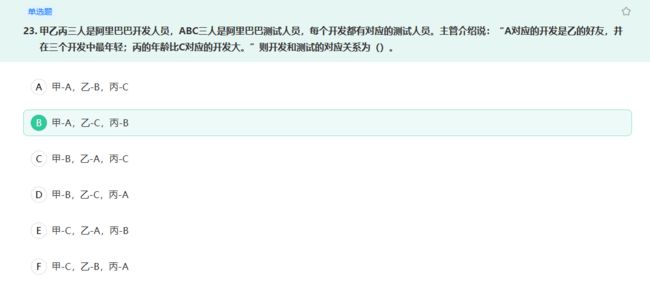
排除法

一共有六天,周六和周日的回答应该一样,故肯定为阿里。