【C++】面向对象之继承
文章目录
-
- 基本概念和语法
-
- 引入
- 定义
- 继承方式
- 基类和派生类的赋值转换
- 继承中的作用域
- 派生类的默认成员函数
-
- 构造函数
- 拷贝构造函数
- 赋值运算符重载
- 析构函数
- 继承与友元
- 继承与静态成员
- 复杂的继承场景
-
- 复杂继承
- 菱形继承引发的数据冗余和二义性
- 虚拟继承及其原理
- 如何写一个不能被继承的类
谈到面向对象的三大特性,必然绕不开封装、继承和多态。
但是需要明确的是三大特性是所有的支持面向对象的语言都有的,
但是具体语言可能还有具体特性。
下面就看一下C++中的继承。
基本概念和语法
引入
当我们在写一个大的项目需要定义多个类的时候,
譬如写一个校园管理系统,
我们需要定义学生类、教师类、职工类等等…
但这些类必然都有一些共同的属性,
譬如姓名、性别、身份证号等等…
所有的这些属性在定义不同类的时候都要重复定义多次,
那有没有一种方法能实现代码的复用,我们只需定义一次就好呢?
以前学过的知识其实能帮我们解决这个问题,
就是通过组合的方法。
比如我现在将各个类的共同属性抽象出来写成一个Person类:
class Person
{
public:
//...
protected:
string _name;
string _id;
string _gender;
//...
};
然后通过组合的方法定义Teacher类:
class Teacher
{
public:
//...
protected:
Person _basic_info;
string _job_id; //工号
string _title; //职称
//...
};
组合当然不是这里要讲的重点,
而且这里会有一个缺点,就是我们无法在Teacher类中直接访问_basic_info中的成员变量,
因为它们被设置成了类外面不可见。
所以我们用继承的方法来定义一个Student类:
class Student : public Person
{
public:
//...
protected:
string _stu_id;
string _grade;
//...
};
所以继承是什么呢?
定义
继承(inheritance)机制是面向对象程序设计使代码可以复用的最重要的手段,
它允许程序员在保持原有类特性的基础上进行扩展,增加功能,
这样产生新的类,称派生类,也叫做子类,
被继承的类称为基类,也叫父类。
继承呈现了面向对象程序设计的层次结构,
体现了由简单到复杂的认知过程。
以前我们接触的复用都是函数复用,继承是类设计层次的复用。
我们刚刚写的一个继承其实分为三部分:

派生类和基类我们已经通过继承的定义差不多理解了,
那继承方式又是什么呢?
继承方式
首先先说明继承方式当时一共有三种,
分别是public、protected、private。
但是这里的继承方式和访问限定符虽然同名,但可不是一个意思。
下面先给出一个表格总结再做解释:
| 访问限定/继承方式 | public继承 | protected继承 | private继承 |
|---|---|---|---|
| 基类的public成员 | 派生类的public成员 | 派生类的protected成员 | 派生类的private成员 |
| 基类的protected成员 | 派生类的protected成员 | 派生类的protected成员 | 派生类的private成员 |
| 基类的private成员 | 派生类不可见 | 派生类不可见 | 派生类不可见 |
此前对于访问限定符protected和private,
我们只知道这俩都是限定成员在类外不可见,
除此之外没有区别。
所以他俩的区别是在继承这里拉开的。
在以public继承的前提下,
private限制成员对外绝对不可见,
虽然派生类继承下来之后给它分配空间了,
但是你派生类只能用我基类提供的接口去访问。
而如果想要基类的成员在派生类中也可访问,
则可以定义成protected成员。
还有一个问题,当我们用struct定义类的时候,
类的成员默认都是用的public限定,
对于继承方式也是如此,默认使用public继承;
相应地,class就完全反过来,
两个都用的private。
想判断一个成员在派生类中的访问权限,
其实可以取巧一点:
我们定义访问权限大小:public > protected > private,
那么成员在派生类中的访问权限就是min{成员在基类的访问限定符,继承方式}。
对于protected继承和private继承,
因为它们太鸡肋了,基本是见不到的,
所以我们一般都是用的public继承。
基类和派生类的赋值转换
我们现在定义了两个类:
class Person
{
protected:
string _name; // 姓名
string _sex; // 性别
int _age; // 年龄
};
class Student : public Person
{
public:
int _No ; // 学号
};
其中Person是基类,Student是派生类。
然后我们创建两个对象:
Person p;
Student s;
既然这两个对象存在部分相同性质的成员,
那么我们可不可以用p给s赋值,或者用s给p赋值这种奇怪的操作呢?

看来后者是可以的。
因为p包含了s的所有成员,
而这种复制方式其实就是所谓的切片或切割,
通俗点就是可以把派生类对象赋值给基类,
将派生类中基类的那一部分切出来给父类:

更甚至,我们还可以将派生类对象赋给基类的指针、引用:
Person* ptr = &s;
Person& ref = s;
和给基类对象赋值不同的是,
将派生类对象赋给基类的指针或引用是让指针或引用可以访问基类部分的成员,
并没有发生实际的切片。
另外还与直接赋值不一样的是,
我们还可以通过强制类型转换将基类对象赋值给派生类的指针、引用,
这样也是合法的:
Student* ptr_stu = (Student*)&p;
Student& ref_stu = (Student&)p;
但是这样就要考虑越界访问的问题了。
这里我们就要思考一个问题了,
将派生类对象赋给基类/基类指针/基类引用的时候,
是不是发生了隐式类型转换呢?
我们只考虑将对象赋给引用,
当我们想用一个类型赋给另一种类型的引用时是行不通的:
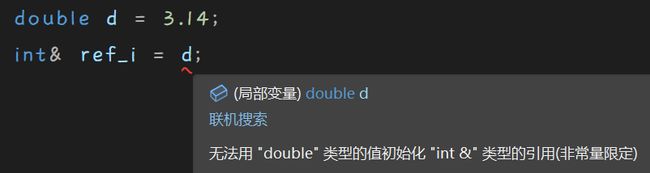
这是因为发生类型转换时会产生一个临时变量。
首先会截取d的整数部分赋给整形类型的临时变量,
然后引用指向该临时变量。
而这个临时变量是常量属性的,
我们不能用一个非const引用类型引用一个const对象,
所以这样就是允许的:
double d = 3.14;
const int& ref_i = d;
而我们上面用基类引用类型引用派生类对象,
明明是不同类型,为什么不加const却可以呢?
这是因为赋值的时候并没有发生类型转换!
继承中的作用域
在继承体系中基类和派生类都有各自的作用域。
这意味着我们可以在基类中定义同名成员变量或同名成员函数,
class Person
{
protected:
string _name = "李四";
//...
}
class Teacher : public Person
{
protected:
string _name = "李老师";
//...
}
同名成员构成隐藏关系,
所以如果我们在Teacher类中直接访问_name成员,
实际上访问到的是"李老师",
如果想在Teacher类中访问Person类中的_name时,
则需要加作用域限定符Person::_name。
需要注意,只要子类和派生类中的成员名相同,
就会构成隐藏关系,也叫重定义,
函数也是如此:
class A
{
public:
void fun()
{
cout << "func()" << endl;
}
};
class B : public A
{
public:
void fun(int i)
{
A::fun();
cout << "func(int i)->" <需要注意的是,因为A和B是两个不同的域,
所以fun()函数即使函数同名参数不同,
也不能构成重载,函数重载的前提是函数在同一作用域。
所以函数也是构成隐藏关系的。
派生类的默认成员函数
构造函数
对于构造函数,
派生类一定是调用基类的默认构造函数去初始化基类的那一部分成员的,
如果基类没有默认构造函数可用,
则必须在派生类构造函数的初始化列表显示调用:
class A
{
public:
A()
:_a(1)
{}
protected:
int _a;
}
class B : class A
{
public:
B(int a, int b)
:A(a)
, _b(b)
{}
protected:
int _b;
}
这里其实还有一个细节就是关于基类子对象和派生类对象的构造顺序问题,
因为初始化列表的初始化顺序只与类成员变量的声明顺序有关,
这里默认基类成员先于派生类声明,
所以派生类对象初始化总是会先调用基类构造再调派生类构造。
拷贝构造函数
对于拷贝构造函数也是如此:
派生类的拷贝构造函数必须调用基类的拷贝构造完成基类的拷贝初始化:
class A
{
public:
A(const A& aa)
:_a(aa._a)
{}
protected:
int _a;
}
class B : class A
{
public:
B(const B& bb)
:A(bb)
, _b(bb._b)
{}
protected:
int _b;
}
在派生类的构造函数调用基类的拷贝构造传参时就体现出切片了。
赋值运算符重载
派生类的operator=必须要调用基类的operator=完成基类的复制,
因为派生类和基类的赋值运算符重载函数是同名的,
同名函数会构成隐藏,
所以在派生类中想要调用基类的赋值运算符重载一定要加作用域限定符,
否则会发生无穷递归:
class A
{
public:
A& operator=(const A& aa)
{
if (this != &aa)
{
_a = aa._a;
}
}
protected:
int _a;
}
class B : class A
{
public:
B& operator=(const B& bb)
{
if (this != &bb)
{
A::operator=(bb);
_b = bb._b;
}
}
protected:
int _b;
}
析构函数
上面都还好理解,下面的析构函数就有点特殊了。
第一点,如果我们想在派生类的析构函数中去显示调用基类的析构函数,
来清理基类的那部分成员,
直接调用是不行的:

因为编译器会将~识别为操作符,
所以我们要加作用域限定符:
~B()
{
A::~A();
}
但实际上大可不必,
因为派生类的析构函数会在被调用完成后自动调用基类的析构函数清理基类成员,
简而言之就是我们不用再派生类的析构函数中去显示调用基类的析构函数,
如果显示调用了,
对于不含有动态分配的成员的基类还好还好,
如果有的话就意味着对同一个指针进行了两次delete,
用下面的代码测试一下:
class A
{
public:
~A()
{
delete[] _a;
}
protected:
int* _a = new int[10];
};
class B : public A
{
public:
~B()
{
A::~A();
delete[] _b;
}
protected:
int* _b = new int[10];
};
int main()
{
B bb;
}
现在问你,这段代码有什么问题?
A.语法错误 B.编译错误 C.运行错误 D.无错误
答案是C,因为对同一个指针释放了两次。
我们可以用这段代码来验证是否真调用了两次:
class A
{
public:
~A()
{
cout << "~A()" << endl;
}
protected:
int _a;
};
class B : public A
{
public:
~B()
{
A::~A();
cout << "~B" << endl;
}
protected:
int* _b;
};
int main()
{
B bb;
}
运行结果如下:

此外,对于析构函数还有其他问题,
比还是以上面的代码为例,
如果这么定义了一个对象:
int main()
{
A* p = new B;
delete p;
return 0;
}
此时运行结果如下:

此时只调用了A的析构,
对B的部分成员并没有处理,
因此造成了内存泄漏!
这个问题的解决方法会在后续多态的文章中讲解解决方案。
继承与友元
现在有一个基类的友元:
class A
{
friend void Print(A aa);
protected:
int _a = 10;
};
void Print(A aa)
{
cout << aa._a << endl;
}
然后有一个派生类:
class B : public A
{
protected:
int _b = 20;
};
我们可以将B类对象作为基类友元函数的参数进行传参:
B bb;
Print(bb);

看起来友元关系似乎也能继承,
但这实际上是切片的体现,
如果想在Print()函数中访问_b则就不行了,
所以实际上友元关系是不能继承的,
我们并不能在基类友元中访问派生类的私有或保护成员。
继承与静态成员
我们现在在基类中定义了一个静态成员并对其进行了初始化:
class Person
{
public:
Person ()
{
_count++;
}
protected:
string _name;
public:
static int _count; //统计一共创建了多少个Person对象
};
int Person::_count = 0;
现在有两个派生类:
class Student : public Person
{
protected:
int _stuNum; //学号
};
class Teacher : public Person
{
protected:
int _jobNum; //工号
};
看下面代码的运行结果:
int main()
{
Person p;
Student s;
Teacher t;
cout << Person::_count << endl;
cout << Student::_count << endl;
cout << Teacher::_count << endl;
return 0;
}

可以看出,
基类定义了static静态成员,
则整个继承体系里面只有一个这样的成员,
这个静态成员为继承体系里的所有类及其对象共有。
复杂的继承场景
复杂继承
这里有三种相对简单继承复杂一点的继承,
一种是一条龙下来的单继承:
class A
{};
class B : public A
{};
class C : public B
{};
//...

一种是较为复杂一点点的多继承:
class A
{};
class B
{};
class C : public A, public B
{};

放到具体场景,
比如助教有学生和老师的双重身份,
所以声明助教类时采用多继承是没问题的:
class Teacher
{};
class Student
{};
class Assistant : public Teacher, public Student
{};
但是此时就有一个问题,
Teacher类和Student类还要一个Person基类呢!
所以就又有了更为复杂的一种继承方式 —— 菱形继承:
class Person
{};
class Teacher : public Person
{};
class Student : public Person
{};
class Assistant : public Teacher, public Student
{};

而这种继承方式会有什么问题呢?
菱形继承引发的数据冗余和二义性
还是以上面的例子为例,
现在丰富一下类的成员,为了方便演示都设置为公有:
class Person
{ public: string _name = "张三"; };
class Teacher : public Person
{ public: int _jobID = 100001; };
class Student : public Person
{ public: int _stuID = 200001; };
class Assistant : public Teacher, public Student
{ public: string _assistCourse = "面向对象的程序设计"; };
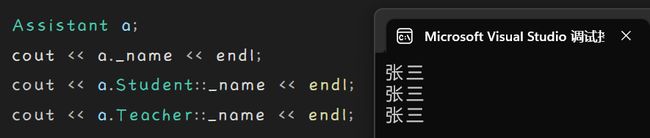
那么我们实例化出来一个Assistant对象后就会出现这样一幕:

这是因为对象中存在两个_name,
一个继承自Teacher类,一个继承自Student类,
所以如果要访问的话还必须得加作用域限定符:

作用域限定符解决了数据的二义性问题,
但是实打实的两个_name还是同时存在,
数据的冗余问题仍然没有解决。
所以又有了下面的虚拟继承。
虚拟继承及其原理
虚拟继承涉及到一个关键字virtual。
对于上面的情况,
想要解决数据冗余,
我们只能在声明Teacher和Student类时进行虚拟继承:
class Person
{ public: string _name = "张三"; };
class Teacher : virtual public Person
{ public: int _jobID = 100001; };
class Student : virtual public Person
{ public: int _stuID = 200001; };
class Assistant : public Teacher, public Student
{ public: string _assistCourse = "面向对象的程序设计"; };
一定要注意虚拟继承的使用位置。
如此Assistant的实例化对象中就只有一个_name了:
下面通过一个简化模型去研究一下虚拟继承的原理。
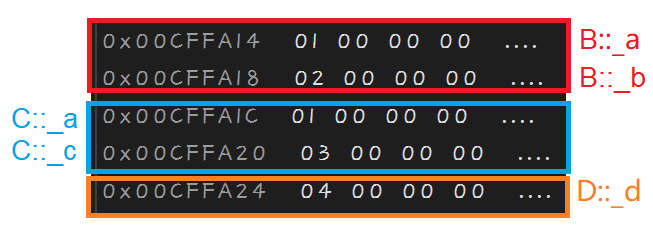
首先先通过下面的代码看一下普通菱形继承引发的数据冗余性问题:
class A
{ public: int _a = 1; };
class B : public A
{ public: int _b = 2; };
class C : public A
{ public: int _c = 3; };
class D : public B, public C
{ public: int _d = 4; };
int main()
{
D dd;
return 0;
}
内存监视窗口如下:
下面是使用虚拟继承后的代码和内存监视窗口信息:
class A
{ public: int _a = 1; };
class B : virtual public A
{ public: int _b = 2; };
class C : virtual public A
{ public: int _c = 3; };
class D : public B, public C
{ public: int _d = 4; };
int main()
{
D dd;
return 0;
}
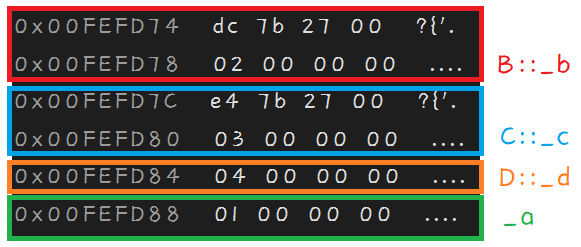
好像确实解决了数据冗余,只有一份_a了,
但是又多了两个奇奇怪怪的值。
这两个值放在这里有什么特殊意义呢?
实际上这是两个指针值,叫做虚基表指针,
他俩指向的就是虚基表,
下面就看看虚基表是怎么一回事:

先看一下B的,它的虚基表有一个0x00000014,
而B的起始地址0x00FEFD74和_a的地址0x00FEFD88正好差了0x00000014个字节,
再看一下C的,它的虚基表有一个0x0000000c,
而C的起始地址0x00FEFD7C和_a的地址0x00FEFD88正好差了0x0000000c个字节。
所以虚基表存放点实际上就是B、C相对于公共部分的内存偏移量。
那问题来了,这不也没节省空间吗?甚至比原来还多了一个空间。
这是因为定义的成员太少,当成员多起来后空间优化就显得十分明显了。
每个虚拟继承得到的派生类其实都有一个虚基表,
可以通过虚基表找到基类的成员。
我们可以再从内存窗口看一下B实例化出来的对象:

因为虚拟继承得到的派生类存储结构发生了变化,
基类的公共成员都放在了最后,
那么在切片的时候就要特殊处理,
而虚基表其实就是这么一种特殊处理机制。
如何写一个不能被继承的类
按照已经学过的知识,
想写一个类,这个类不能被继承,
最暴力的方法就是把构造函数定义成私有的,
但这样做没什么实际意义,
因为这个类就用不了了。
C++11给出了一种解决方案,
就是在定义类的时候加一个关键字final:
class A final
{}
表示这是一个最终类。
这里再多提一嘴,
怎样定义一个只能用new构造对象的类?
也就是说只能这样使用:
class A
{
//...
}
int main()
{
A aa; //no
A* p = new A; //yes
}
如果用上面的方法,
将构造函数设置成私有,
但这样new也不能完成构造了,
因为new会主动去调用构造函数。
所以正确的解决方式就是将析构函数定义成私有的。
这样一来,直接实例化出来的对象在生命周期结束后会去调用析构函数,
但是析构函数被设置成私有了,
所以这样做肯定会报错。
但是如果使用new构造对象,
只要我不使用delete去释放,
就不会去调用析构函数,
因为delete第一步会调用类的析构函数释放类的成员,
第二步再free掉指针指向的空间。
但是这么一来就引发了内存泄漏问题,
所以也没有什么实用性,所以看看就好。