循环神经网络模型及应用,循环神经网络应用举例
神经网络算法的三大类分别是?
神经网络算法的三大类分别是:1、前馈神经网络:这是实际应用中最常见的神经网络类型。第一层是输入,最后一层是输出。如果有多个隐藏层,我们称之为“深度”神经网络。他们计算出一系列改变样本相似性的变换。
各层神经元的活动是前一层活动的非线性函数。2、循环网络:循环网络在他们的连接图中定向了循环,这意味着你可以按照箭头回到你开始的地方。他们可以有复杂的动态,使其很难训练。他们更具有生物真实性。
循环网络的目的是用来处理序列数据。在传统的神经网络模型中,是从输入层到隐含层再到输出层,层与层之间是全连接的,每层之间的节点是无连接的。但是这种普通的神经网络对于很多问题却无能无力。
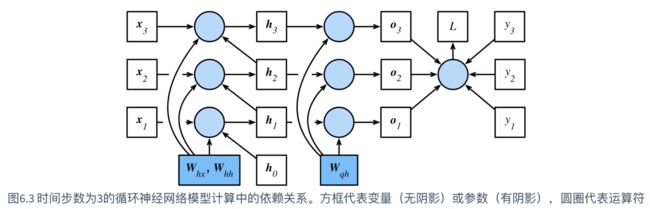
循环神经网路,即一个序列当前的输出与前面的输出也有关。
具体的表现形式为网络会对前面的信息进行记忆并应用于当前输出的计算中,即隐藏层之间的节点不再无连接而是有连接的,并且隐藏层的输入不仅包括输入层的输出还包括上一时刻隐藏层的输出。
3、对称连接网络:对称连接网络有点像循环网络,但是单元之间的连接是对称的(它们在两个方向上权重相同)。比起循环网络,对称连接网络更容易分析。这个网络中有更多的限制,因为它们遵守能量函数定律。
没有隐藏单元的对称连接网络被称为“Hopfield网络”。有隐藏单元的对称连接的网络被称为玻尔兹曼机。
扩展资料:应用及发展:心理学家和认知科学家研究神经网络的目的在于探索人脑加工、储存和搜索信息的机制,弄清人脑功能的机理,建立人类认知过程的微结构理论。
生物学、医学、脑科学专家试图通过神经网络的研究推动脑科学向定量、精确和理论化体系发展,同时也寄希望于临床医学的新突破;信息处理和计算机科学家研究这一问题的目的在于寻求新的途径以解决不能解决或解决起来有极大困难的大量问题,构造更加逼近人脑功能的新一代计算机。
谷歌人工智能写作项目:小发猫

循环神经网络的反向传播
可以采用MATLAB软件中的神经网络工具箱来实现BP神经网络算法rfid。BP神经网络的学习过程由前向计算过程、误差计算和误差反向传播过程组成。
双含隐层BP神经网络的MATLAB程序,由输入部分、计算部分、输出部分组成,其中输入部分包括网络参数与训练样本数据的输入、初始化权系、求输入输出模式各分量的平均值及标准差并作相应数据预处理、读入测试集样本数据并作相应数据预处理;计算部分包括正向计算、反向传播、计算各层权矩阵的增量、自适应和动量项修改各层权矩阵;输出部分包括显示网络最终状态及计算值与期望值之间的相对误差、输出测试集相应结果、显示训练,测试误差曲线。
如何使用TensorFlow构建,训练和改进循环神经网络
。
基本使用使用TensorFlow,你必须明白TensorFlow:使用图(graph)来表示计算任务.在被称之为会话(Session)的上下文(context)中执行图.使用tensor表示数据.通过变量(Variable)维护状态.使用feed和fetch可以为任意的操作(arbitraryoperation)赋值或者从其中获取数据.综述TensorFlow是一个编程系统,使用图来表示计算任务.图中的节点被称之为op(operation的缩写).一个op获得0个或多个Tensor,执行计算,产生0个或多个Tensor.每个Tensor是一个类型化的多维数组.例如,你可以将一小组图像集表示为一个四维浮点数数组,这四个维度分别是[batch,height,width,channels].一个TensorFlow图描述了计算的过程.为了进行计算,图必须在会话里被启动.会话将图的op分发到诸如CPU或GPU之类的设备上,同时提供执行op的方法.这些方法执行后,将产生的tensor返回.在Python语言中,返回的tensor是numpyndarray对象;在C和C++语言中,返回的tensor是tensorflow::Tensor实例.。
如何有效的区分和理解RNN循环神经网络与递归神经网络
NN建立在与FNN相同的计算单元上,以牺牲计算的功能性为代价来简化这一训练过程,其中信息从输入单元向输出单元单向流动,在这些连通模式中并不存在不定向的循环。FNN是建立在层面之上。
因此,为了创建更为强大的计算系统,我们允许RNN打破这些人为设定强加性质的规定,神经元在实际中是允许彼此相连的,两者之间区别在于:组成这些神经元相互关联的架构有所不同,我们还是加入了这些限制条件。
事实上:RNN无需在层面之间构建,同时定向循环也会出现。尽管大脑的神经元确实在层面之间的连接上包含有不定向循环。
如何用PyTorch实现递归神经网络
从Siri到谷歌翻译,深度神经网络已经在机器理解自然语言方面取得了巨大突破。
这些模型大多数将语言视为单调的单词或字符序列,并使用一种称为循环神经网络(recurrentneuralnetwork/RNN)的模型来处理该序列。
但是许多语言学家认为语言最好被理解为具有树形结构的层次化词组,一种被称为递归神经网络(recursiveneuralnetwork)的深度学习模型考虑到了这种结构,这方面已经有大量的研究。
虽然这些模型非常难以实现且效率很低,但是一个全新的深度学习框架PyTorch能使它们和其它复杂的自然语言处理模型变得更加容易。
虽然递归神经网络很好地显示了PyTorch的灵活性,但它也广泛支持其它的各种深度学习框架,特别的是,它能够对计算机视觉(computervision)计算提供强大的支撑。
PyTorch是FacebookAIResearch和其它几个实验室的开发人员的成果,该框架结合了Torch7高效灵活的GPU加速后端库与直观的Python前端,它的特点是快速成形、代码可读和支持最广泛的深度学习模型。
开始SPINN链接中的文章()详细介绍了一个递归神经网络的PyTorch实现,它具有一个循环跟踪器(recurrenttracker)和TreeLSTM节点,也称为SPINN——SPINN是深度学习模型用于自然语言处理的一个例子,它很难通过许多流行的框架构建。
这里的模型实现部分运用了批处理(batch),所以它可以利用GPU加速,使得运行速度明显快于不使用批处理的版本。
SPINN的意思是堆栈增强的解析器-解释器神经网络(Stack-augmentedParser-InterpreterNeuralNetwork),由Bowman等人于2016年作为解决自然语言推理任务的一种方法引入,该论文中使用了斯坦福大学的SNLI数据集。
该任务是将语句对分为三类:假设语句1是一幅看不见的图像的准确标题,那么语句2(a)肯定(b)可能还是(c)绝对不是一个准确的标题?
(这些类分别被称为蕴含(entailment)、中立(neutral)和矛盾(contradiction))。
例如,假设一句话是「两只狗正跑过一片场地」,蕴含可能会使这个语句对变成「户外的动物」,中立可能会使这个语句对变成「一些小狗正在跑并试图抓住一根棍子」,矛盾能会使这个语句对变成「宠物正坐在沙发上」。
特别地,研究SPINN的初始目标是在确定语句的关系之前将每个句子编码(encoding)成固定长度的向量表示(也有其它方式,例如注意模型(attentionmodel)中将每个句子的每个部分用一种柔焦(softfocus)的方法相互比较)。
数据集是用句法解析树(syntacticparsetree)方法由机器生成的,句法解析树将每个句子中的单词分组成具有独立意义的短语和子句,每个短语由两个词或子短语组成。
许多语言学家认为,人类通过如上面所说的树的分层方式来组合词意并理解语言,所以用相同的方式尝试构建一个神经网络是值得的。
下面的例子是数据集中的一个句子,其解析树由嵌套括号表示:((Thechurch)((has(cracks(in(theceiling)))).))这个句子进行编码的一种方式是使用含有解析树的神经网络构建一个神经网络层Reduce,这个神经网络层能够组合词语对(用词嵌入(wordembedding)表示,如GloVe)、和/或短语,然后递归地应用此层(函数),将最后一个Reduce产生的结果作为句子的编码:X=Reduce(“the”,“ceiling”)Y=Reduce(“in”,X)...etc.但是,如果我希望网络以更类似人类的方式工作,从左到右阅读并保留句子的语境,同时仍然使用解析树组合短语?
或者,如果我想训练一个网络来构建自己的解析树,让解析树根据它看到的单词读取句子?
这是一个同样的但方式略有不同的解析树的写法:Thechurch)hascracksintheceiling)))).))或者用第3种方式表示,如下:WORDS:Thechurchhascracksintheceiling.PARSES:SSRSSSSSRRRRSRR我所做的只是删除开括号,然后用「S」标记「shift」,并用「R」替换闭括号用于「reduce」。
但是现在可以从左到右读取信息作为一组指令来操作一个堆栈(stack)和一个类似堆栈的缓冲区(buffer),能得到与上述递归方法完全相同的结果:1.将单词放入缓冲区。
2.从缓冲区的前部弹出「The」,将其推送(push)到堆栈上层,紧接着是「church」。3.弹出前2个堆栈值,应用于Reduce,然后将结果推送回堆栈。
4.从缓冲区弹出「has」,然后推送到堆栈,然后是「cracks」,然后是「in」,然后是「the」,然后是「ceiling」。
5.重复四次:弹出2个堆栈值,应用于Reduce,然后推送结果。6.从缓冲区弹出「.」,然后推送到堆栈上层。7.重复两次:弹出2个堆栈值,应用于Reduce,然后推送结果。
8.弹出剩余的堆栈值,并将其作为句子编码返回。我还想保留句子的语境,以便在对句子的后半部分应用Reduce层时考虑系统已经读取的句子部分的信息。
所以我将用一个三参数函数替换双参数的Reduce函数,该函数的输入值为一个左子句、一个右子句和当前句的上下文状态。该状态由神经网络的第二层(称为循环跟踪器(Tracker)的单元)创建。
Tracker在给定当前句子上下文状态、缓冲区中的顶部条目b和堆栈中前两个条目s1\s2时,在堆栈操作的每个步骤(即,读取每个单词或闭括号)后生成一个新状态:context[t+1]=Tracker(context[t],b,s1,s2)容易设想用你最喜欢的编程语言来编写代码做这些事情。
对于要处理的每个句子,它将从缓冲区加载下一个单词,运行跟踪器,检查是否将单词推送入堆栈或执行Reduce函数,执行该操作;然后重复,直到对整个句子完成处理。
通过对单个句子的应用,该过程构成了一个大而复杂的深度神经网络,通过堆栈操作的方式一遍又一遍地应用它的两个可训练层。
但是,如果你熟悉TensorFlow或Theano等传统的深度学习框架,就知道它们很难实现这样的动态过程。你值得花点时间回顾一下,探索为什么PyTorch能有所不同。
图论图1:一个函数的图结构表示深度神经网络本质上是有大量参数的复杂函数。深度学习的目的是通过计算以损失函数(loss)度量的偏导数(梯度)来优化这些参数。
如果函数表示为计算图结构(图1),则向后遍历该图可实现这些梯度的计算,而无需冗余工作。
每个现代深度学习框架都是基于此反向传播(backpropagation)的概念,因此每个框架都需要一个表示计算图的方式。
在许多流行的框架中,包括TensorFlow、Theano和Keras以及Torch7的nngraph库,计算图是一个提前构建的静态对象。
该图是用像数学表达式的代码定义的,但其变量实际上是尚未保存任何数值的占位符(placeholder)。图中的占位符变量被编译进函数,然后可以在训练集的批处理上重复运行该函数来产生输出和梯度值。
这种静态计算图(staticcomputationgraph)方法对于固定结构的卷积神经网络效果很好。但是在许多其它应用中,有用的做法是令神经网络的图结构根据数据而有所不同。
在自然语言处理中,研究人员通常希望通过每个时间步骤中输入的单词来展开(确定)循环神经网络。
上述SPINN模型中的堆栈操作很大程度上依赖于控制流程(如for和if语句)来定义特定句子的计算图结构。在更复杂的情况下,你可能需要构建结构依赖于模型自身的子网络输出的模型。
这些想法中的一些(虽然不是全部)可以被生搬硬套到静态图系统中,但几乎总是以降低透明度和增加代码的困惑度为代价。
该框架必须在其计算图中添加特殊的节点,这些节点代表如循环和条件的编程原语(programmingprimitive),而用户必须学习和使用这些节点,而不仅仅是编程代码语言中的for和if语句。
这是因为程序员使用的任何控制流程语句将仅运行一次,当构建图时程序员需要硬编码(hardcoding)单个计算路径。
例如,通过词向量(从初始状态h0开始)运行循环神经网络单元(rnn_unit)需要TensorFlow中的特殊控制流节点tf.while_loop。
需要一个额外的特殊节点来获取运行时的词长度,因为在运行代码时它只是一个占位符。
#TensorFlow#(thiscoderunsonce,duringmodelinitialization)#“words”isnotareallist(it’saplaceholdervariable)so#Ican’tuse“len”cond=lambdai,h:i
在这样的框架(也称为运行时定义(define-by-run))中,计算图在运行时被建立和重建,使用相同的代码为前向通过(forwardpass)执行计算,同时也为反向传播(backpropagation)建立所需的数据结构。
这种方法能产生更直接的代码,因为控制流程的编写可以使用标准的for和if。
它还使调试更容易,因为运行时断点(run-timebreakpoint)或堆栈跟踪(stacktrace)将追踪到实际编写的代码,而不是执行引擎中的编译函数。
可以在动态框架中使用简单的Python的for循环来实现有相同变量长度的循环神经网络。
#PyTorch(alsoworksinChainer)#(thiscoderunsoneveryforwardpassofthemodel)#“words”isaPythonlistwithactualvaluesinith=h0forwordinwords:h=rnn_unit(word,h)PyTorch是第一个define-by-run的深度学习框架,它与静态图框架(如TensorFlow)的功能和性能相匹配,使其能很好地适合从标准卷积神经网络(convolutionalnetwork)到最疯狂的强化学习(reinforcementlearning)等思想。
所以让我们来看看SPINN的实现。代码在开始构建网络之前,我需要设置一个数据加载器(dataloader)。
通过深度学习,模型可以通过数据样本的批处理进行操作,通过并行化(parallelism)加快训练,并在每一步都有一个更平滑的梯度变化。
我想在这里可以做到这一点(稍后我将解释上述堆栈操作过程如何进行批处理)。以下Python代码使用内置于PyTorch的文本库的系统来加载数据,它可以通过连接相似长度的数据样本自动生成批处理。
运行此代码之后,train_iter、dev_iter和test_itercontain循环遍历训练集、验证集和测试集分块SNLI的批处理。
fromtorchtextimportdata,datasetsTEXT=.ParsedTextField(lower=True)TRANSITIONS=.ShiftReduceField()LABELS=data.Field(sequential=False)train,dev,test=.splits(TEXT,TRANSITIONS,LABELS,wv_type='glove.42B')TEXT.build_vocab(train,dev,test)train_iter,dev_iter,test_iter=data.BucketIterator.splits((train,dev,test),batch_size=64)你可以在中找到设置训练循环和准确性(accuracy)测量的其余代码。
让我们继续。
如上所述,SPINN编码器包含参数化的Reduce层和可选的循环跟踪器来跟踪句子上下文,以便在每次网络读取单词或应用Reduce时更新隐藏状态;以下代码代表的是,创建一个SPINN只是意味着创建这两个子模块(我们将很快看到它们的代码),并将它们放在一个容器中以供稍后使用。
importtorchfromtorchimportnn#subclasstheModuleclassfromPyTorch’sneuralnetworkpackageclassSPINN(nn.Module):def__init__(self,config):super(SPINN,self).__init__()self.config=configself.reduce=Reduce(config.d_hidden,config.d_tracker)ifconfig.d_trackerisnotNone:self.tracker=Tracker(config.d_hidden,config.d_tracker)当创建模型时,SPINN.__init__被调用了一次;它分配和初始化参数,但不执行任何神经网络操作或构建任何类型的计算图。
在每个新的批处理数据上运行的代码由SPINN.forward方法定义,它是用户实现的方法中用于定义模型向前过程的标准PyTorch名称。
上面描述的是堆栈操作算法的一个有效实现,即在一般Python中,在一批缓冲区和堆栈上运行,每一个例子都对应一个缓冲区和堆栈。
我使用转移矩阵(transition)包含的「shift」和「reduce」操作集合进行迭代,运行Tracker(如果存在),并遍历批处理中的每个样本来应用「shift」操作(如果请求),或将其添加到需要「reduce」操作的样本列表中。
然后在该列表中的所有样本上运行Reduce层,并将结果推送回到它们各自的堆栈。
defforward(self,buffers,transitions):#Theinputcomesinasasingletensorofwordembeddings;#Ineedittobealistofstacks,oneforeachexamplein#thebatch,thatwecanpopfromindependently.Thewordsin#eachexamplehavealreadybeenreversed,sothattheycan#bereadfromlefttorightbypoppingfromtheendofeach#list;theyhavealsobeenprefixedwithanullvalue.buffers=[list(torch.split(b.squeeze(1),1,0))forbintorch.split(buffers,1,1)]#wealsoneedtwonullvaluesatthebottomofeachstack,#sowecancopyfromthenullsintheinput;thesenulls#areallneededsothatthetrackercanrunevenifthe#bufferorstackisemptystacks=[[buf[0],buf[0]]forbufinbuffers]ifhasattr(self,'tracker'):self.tracker.reset_state()fortrans_batchintransitions:ifhasattr(self,'tracker'):#IdescribedtheTrackerearlierastaking4#arguments(context_t,b,s1,s2),buthereI#providethestackcontentsasasingleargument#whilestoringthecontextinsidetheTracker#objectitself.tracker_states,_=self.tracker(buffers,stacks)else:tracker_states=itertools.repeat(None)lefts,rights,trackings=[],[],[]batch=zip(trans_batch,buffers,stacks,tracker_states)fortransition,buf,stack,trackinginbatch:iftransition==SHIFT:stack.append(())eliftransition==REDUCE:rights.append(())lefts.append(())trackings.append(tracking)ifrights:reduced=iter(self.reduce(lefts,rights,trackings))fortransition,stackinzip(trans_batch,stacks):iftransition==REDUCE:stack.append(next(reduced))return[()forstackinstacks]在调用self.tracker或self.reduce时分别运行Tracker或Reduce子模块的向前方法,该方法需要在样本列表上应用前向操作。
在主函数的向前方法中,在不同的样本上进行独立的操作是有意义的,即为批处理中每个样本提供分离的缓冲区和堆栈,因为所有受益于批处理执行的重度使用数学和需要GPU加速的操作都在Tracker和Reduce中进行。
为了更干净地编写这些函数,我将使用一些helper(稍后将定义)将这些样本列表转化成批处理张量(tensor),反之亦然。
我希望Reduce模块自动批处理其参数以加速计算,然后解批处理(unbatch)它们,以便可以单独推送和弹出。
用于将每对左、右子短语表达组合成父短语(parentphrase)的实际组合函数是TreeLSTM,它是普通循环神经网络单元LSTM的变型。
该组合函数要求每个子短语的状态实际上由两个张量组成,一个隐藏状态h和一个存储单元(memorycell)状态c,而函数是使用在子短语的隐藏状态操作的两个线性层(nn.Linear)和将线性层的结果与子短语的存储单元状态相结合的非线性组合函数tree_lstm。
在SPINN中,这种方式通过添加在Tracker的隐藏状态下运行的第3个线性层进行扩展。图2:TreeLSTM组合函数增加了第3个输入(x,在这种情况下为Tracker状态)。
在下面所示的PyTorch实现中,5组的三种线性变换(由蓝色、黑色和红色箭头的三元组表示)组合为三个nn.Linear模块,而tree_lstm函数执行位于框内的所有计算。
图来自Chenetal.(2016)。
CNN(卷积神经网络)、RNN(循环神经网络)、DNN(深度神经网络)的内部网络结构有什么区别?
如下:1、DNN:存在着一个问题——无法对时间序列上的变化进行建模。然而,样本出现的时间顺序对于自然语言处理、语音识别、手写体识别等应用非常重要。
对了适应这种需求,就出现了另一种神经网络结构——循环神经网络RNN。2、CNN:每层神经元的信号只能向上一层传播,样本的处理在各个时刻独立,因此又被称为前向神经网络。
3、RNN:神经元的输出可以在下一个时间戳直接作用到自身,即第i层神经元在m时刻的输入,除了(i-1)层神经元在该时刻的输出外,还包括其自身在(m-1)时刻的输出!
介绍神经网络技术起源于上世纪五、六十年代,当时叫感知机(perceptron),拥有输入层、输出层和一个隐含层。输入的特征向量通过隐含层变换达到输出层,在输出层得到分类结果。
早期感知机的推动者是Rosenblatt。在实际应用中,所谓的深度神经网络DNN,往往融合了多种已知的结构,包括卷积层或是LSTM单元。
关于循环神经网络RNN,隐藏层是怎么来的?
RNN的隐藏层也可以叫循环核,简单来说循环核循环的次数叫时间步,循环核的个数就是隐藏层层数。
循环核可以有两个输入(来自样本的输入x、来自上一时间步的激活值a)和两个输出(输出至下一层的激活值h、输出至本循环核下一时间步的激活值a),输入和输出的形式有很多变化,题主想了解可以上B站搜索“吴恩达深度学习”其中第五课是专门对RNN及其拓展进行的讲解,通俗易懂。
B站链接:网页链接参考资料:网页链接。