【自然语言处理】Transformer 模型:概述及分类(综述)
Transformer 模型:概述及分类
在过去的数年里,基于 Transformer 的相关模型层出不穷。本文将对当下最流行的 Transformer 模型做一个简单全面的介绍。
1.Transformers 简介
Transformers 是一类具有某些特征架构的深度学习模型。 2017 年,Google 研究人员在著名论文《Attention is All you Need》及相关博客中首次提出了这个概念。
近两三年,编码器-解码器 模型开始流行,而 Transformer 架构则是该模型的一个具体实例。在此之前,注意力(Attention)仅是这些模型使用的机制之一,大部分是基于 LSTM 和其他 RNN 变体的。Transformer 论文的核心要点在于,注意力被用作推导输入和输出之间依赖关系的唯一机制。本文不会深入探讨 Transformer 架构的所有细节,感兴趣可以去阅读原论文及相关博客。
1.1 Encoder-Decoder 架构
通用 编码器-解码器 架构由两个模型组成。编码器获取输入并将其编码为固定长度的向量。解码器获取该向量并将其解码为输出序列。编码器和解码器以最小化条件对数似然为目标进行联合训练。经过训练的编码器-解码器可以在给定输入序列的情况下生成输出,或者对一对输入/输出序列进行评分。

在原始 Transformer 架构中,编码器和解码器都有 6 6 6 个相同的层。在这 6 6 6 层中的每一层中,编码器都有两个子层:一个多头注意力层(Multi-Head Attention)和一个简单的前馈网络(Feed Forward Network)。每个子层都有一个残差连接(Residual Connection)和一个归一化层(Normalization),即上图中的 Add & Norm。编码器的输出大小为 512 512 512。解码器添加了第三个子层,即掩码多头注意力层(Masked Multi-Head Attention)。
1.2 Attention 机制
多头注意力(multi-headed attention)是模型架构的亮点,可以将其理解为一种 带缩放的点积注意力(scaled dot-product attention)的并行计算。有关注意力(Attention)机制工作的更多细节,可以参考我的这篇博客《图解 Transformer》。主要思想如下图所示。

与 RNN 和 CNN 相比,注意力层有几个优点,其中最重要的两点是其 较低的计算复杂性 和 较高的连接性,特别适用于学习序列中的长期依赖性。
1.3 Transformer 为何如此受欢迎?
最初,Transformer 是为语言翻译任务设计的,一开始是从英语到德语。但是,原始论文已经表明该架构可以很好地泛化到其他语言任务。这一趋势很快引起了研究界的注意。在接下来的几个月里,大多数与语言相关的 ML 任务排行榜都被某些 Transformer 架构霸榜。
Transformer 能够如此迅速地占据大多数 NLP 排行榜的关键原因之一是它们能够快速适应其他任务,即 迁移学习。预训练的 Transformer 模型可以非常容易并快速地适应它们没有接受过训练的任务。作为 ML 从业者,不再需要在庞大的数据集上训练大型模型。你需要做的就是在你的任务中重新使用预训练模型,也许只是稍微使用更小的数据集对其进行调整。用于使预训练模型适应不同任务的特定技术即所谓的 微调。
事实证明,Transformer 适应其他任务的能力非常强悍,以至于虽然它们最初是为了语言相关任务开发的,但它们很快就显现出对其他任务的帮助。例如,从视觉、音频和音乐应用,到下棋、做数学题等。
当然,因为有很多相关的工具,任何人都可以仅编写几行代码就轻松使用它们。Transformers 不仅迅速集成到了主要的 AI 框架(即 Pytorch 和 TensorFlow)中,而且甚至能够围绕它们创建一个公司。 Huggingface 是一家迄今已筹集超过 6000 6000 6000 万美元的初创公司,核心想法就是将其开源 Transformers 库商业化。
最后,要考虑到 GPT-3 对 Transformer 普及的影响。 作为 GPT 和 GPT-2 的后续之作,GPT-3 是 OpenAI 于 2020 2020 2020 年 5 5 5 月推出的 Transformer 模型。从那时起,该模型被发布,而且通过 OpenAI 和微软之间的合作伙伴关系实现了商业化。 GPT-3 为 300 300 300 多种不同的应用程序提供支持,并且是 OpenAI 商业战略的基础。
1.4 基于人类反馈的强化学习(RLHF)
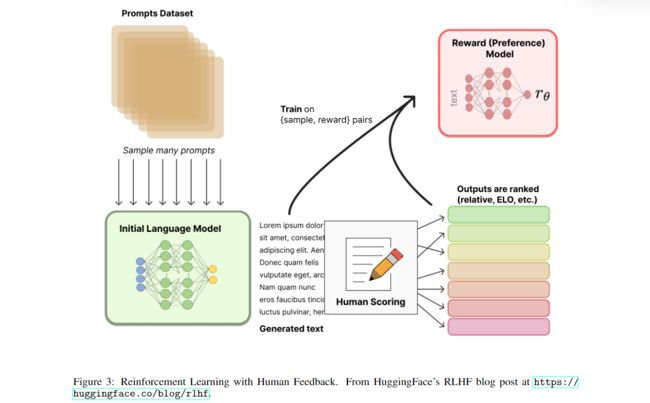
基于人类反馈的强化学习(Reinforcement Learning from Human Feedback,RLHF) 于 2017 2017 2017 年在论文《Deep reinforcement learning from human preferences》首次被引入。最近,它已经被应用于 ChatGPT 和类似的对话代理,如 BlenderBot3 或 Sparrow。但它的核心概念比较容易理解:当语言模型经过预训练后,我们可以对一段对话生成不同的响应,同时让人对结果进行排名。在随后的强化学习环境中使用这些排名结果(也称为偏好或反馈)来进行训练。
1.5 扩散(Diffusion)模型
扩散(Diffusion)模型已经成为图像生成任务的新 SOTA,明显优于之前的诸如生成对抗网络(GAN)等方法。
SOTA:State of the Art,并不是特指某个具体的模型,而是指在该项研究任务中,目前最好或最先进的模型。
扩散模型是一类经过训练的变分推理的隐变量模型。在实际操作中,会训练一个神经网络模型对加入噪声的图像进行去噪。通过这种方式训练的网络会学习这些图像所代表的潜在空间。

2.Transformers 分类
2.1 分类依据
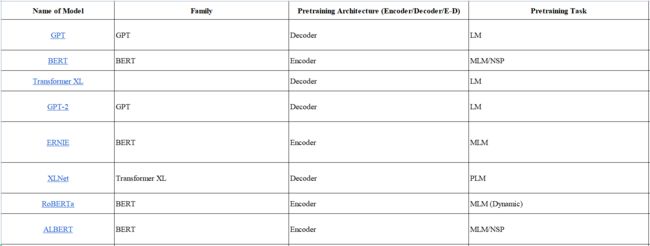
我将根据 预训练架构、预训练任务、压缩、应用、年份 和 参数数量 等特征对每个模型进行分类。
2.2 类别表
此处提供一个列出了所有模型的表格,访问链接。
2.3 族谱

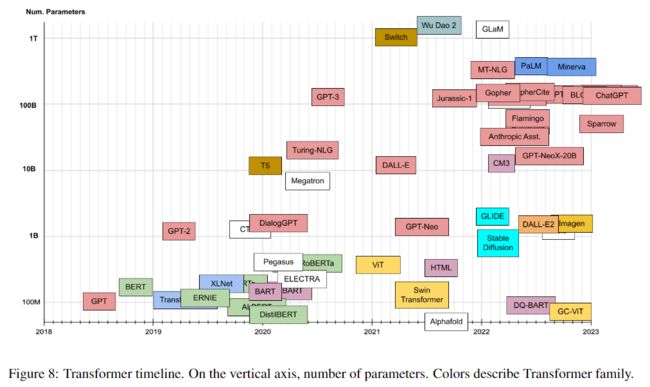
2.4 发布时间线

2.5 类别清单
原文列出的清单中介绍了每一种模型的相关特征,以 ALBERT 为例,如下图所示。更多内容请参考原文。

本文译自论文 Transformer models: an introduction and catalog。