Java-SpringBoot:SpringBoot+Dubbo+Zookeeper
学习视频:B站 狂神说Java – https://www.bilibili.com/video/BV1PE411i7CV
学习文档: 微信公众号 狂神说 –https://mp.weixin.qq.com/mp/homepage?__biz=Mzg2NTAzMTExNg==&hid=1&sn=3247dca1433a891523d9e4176c90c499&scene=18&uin=&key=&devicetype=Windows+10+x64&version=63020170&lang=zh_CN&ascene=7&fontgear=2
SpringBoot 官方文档链接 – https://docs.spring.io/spring-boot/docs/2.2.5.RELEASE/reference/htmlsingle/#appendix
Dubbo官方连接-- https://dubbo.apache.org/zh/
Dubbo的官方文档连接:
- https://dubbo.apache.org/zh/docs/v2.7/
- https://dubbo.apache.org/zh/docs/
zookeeper官方链接-- https://dubbo.apache.org/zh/docs/v2.7/user/references/registry/zookeeper/
分布式系统
什么是分布式系统?
在《分布式系统原理与范型》一书中有如下定义:“分布式系统是若干独立计算机的集合,这些计算机对于用户来说就像单个相关系统”;
分布式系统是由一组通过网络进行通信、为了完成共同的任务而协调工作的计算机节点组成的系统。分布式系统的出现是为了用廉价的、普通的机器完成单个计算机无法完成的计算、存储任务。其目的是利用更多的机器,处理更多的数据。
分布式系统(distributed system)是建立在网络之上的软件系统。
首先需要明确的是,只有当单个节点的处理能力无法满足日益增长的计算、存储任务的时候,且硬件的提升(加内存、加磁盘、使用更好的CPU)高昂到得不偿失的时候,应用程序也不能进一步优化的时候,我们才需要考虑分布式系统。因为,分布式系统要解决的问题本身就是和单机系统一样的,而由于分布式系统多节点、通过网络通信的拓扑结构,会引入很多单机系统没有的问题,为了解决这些问题又会引入更多的机制、协议,带来更多的问题。。。
例如:假设百度、淘宝系统,它们有100个服务器。这些服务器会完成各自特定的功能。在原来的情况下,每个机器 都能完成一个完整的下单、出货、结账的功能。当业务量猛增/数据量海量上升的时候,增加服务器去完成这个功能(某些服务器处理下单、一些服务器处理库存、另一些服务器处理账单)。那么此时就要去考虑,如何调用其中的某台服务器去执行完成特定任务呢?它们之间的通信连接是如何进行的?
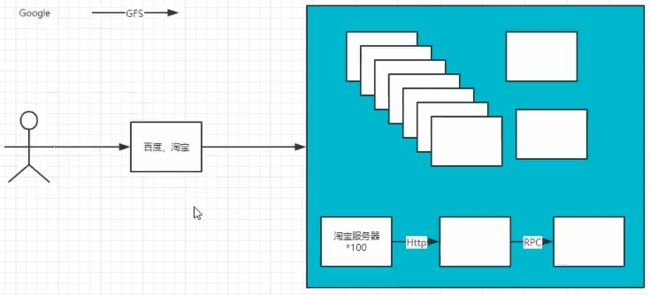
分布式:将一个大的系统划分为多个业务模块,业务模块分别部署到不同的机器上,各个业务模块之间通过接口进行数据交互。
分布式、集群两者之间的区别:
- 分布式:【不同机器不同业务】
- 不同的模块部署在不同服务器上
- 作用:分布式解决网站高并发带来问题;分散压力
- 集群:【相同的服务】
- 多台服务器部署相同应用构成一个集群;
- 作用:通过负载均衡设备共同对外提供服务;
- 集群是每台服务器都具有相同的功能,处理请求时调用那台服务器都可以,主要起分流作用。
分布式系统、微服务架构之间的区别:
- 区别分布式的方式是根据不同机器不同业务。
- 微服务与分布式的细微差别是,微服务的应用不一定是分散在多个服务器上,他也可以是同一个服务器。
- 分布式系统是服务的分散化;微服务架构是服务的专业化和细分化(精细分工)。将单一的应用程序划分成一组小的服务。
- 微服务架构通过更细粒度的服务切分,使得整个系统的迭代速度并行程度更高,但是运维的复杂度和性能会随着服务的粒度更细而增加。
分布式理论
CAP 原理
C:Consistency 即一致性,访问所有的节点得到的数据应该是一样的。注意,这里的一致性指的是强一致性,也就是数据更新完,访问任何节点看到的数据完全一致,要和弱一致性,最终一致性区分开来。
**A:Availability 即可用性,所有的节点都保持高可用性。**注意,这里的高可用还包括不能出现延迟,比如:如果节点B由于等待数据同步而阻塞请求,那么节点 B 就不满足高可用性。也就是说,任何没有发生故障的服务必须在有限的时间内返回合理的结果集。
**P:Partiton tolerence 即分区容忍性,这里的分区是指网络意义上的分区。**由于网络是不可靠的,所有节点之间很可能出现无法通讯的情况,在节点不能通信时,要保证系统可以继续正常服务。
CAP 原理说:一个数据分布式系统不可能同时满足 C 和 A 和 P 这3个条件。所以系统架构师在设计系统时,不要将精力浪费在如何设计能满足三者的完美分布式系统,而是应该进行取舍。由于网络的不可靠性质,大多数开源的分布式系统都会实现 P,也就是分区容忍性,之后在 C 和 A 中做抉择。
CAP 理论告诉我们一个悲惨但不得不接受的事实——我们只能在 C、A、P 中选择两个条件。而对于业务系统而言,我们**往往选择牺牲一致性来换取系统的可用性和分区容错性。**不过这里要指出的是,所谓的“牺牲一致性”并不是完全放弃数据一致性,而是牺牲强一致性换取弱一致性。
Dubbo
Dubbo简介
Dubbo的官网链接:https://dubbo.apache.org/zh/
Apache Dubbo 是一款高性能、轻量级的开源 Java 服务框架。Apache Dubbo |ˈdʌbəʊ| 提供了六大核心能力:
- 面向接口代理的高性能RPC调用,
- 智能容错和负载均衡,
- 服务自动注册和发现,
- 高度可扩展能力,
- 运行期流量调度,
- 可视化的服务治理与运维。

随着互联网的发展,网站应用的规模不断扩大,常规的垂直应用架构已无法应对,分布式服务架构以及流动计算架构势在必行,急需一个治理系统确保架构有条不紊的演进。在Dubbo官方文档中,关于应用架构的演变图:
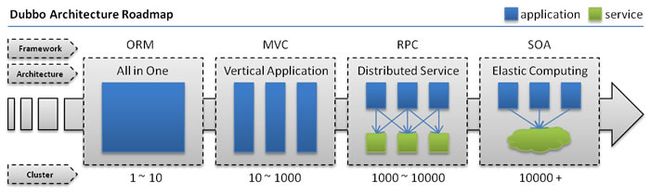
系统应用架构
单一应用架构
原来的单一应用架构:当网站流量很小时,只需一个应用,将所有功能都部署在一起,以减少部署节点和成本。此时,用于简化增删改查工作量的数据访问框架(ORM)是关键。
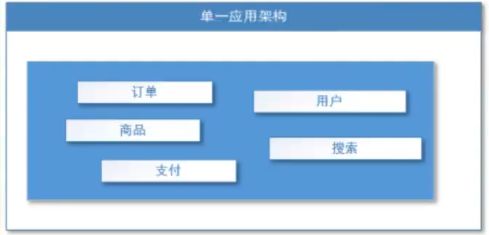
单一应用架构适用于小型网站,小型管理系统,将所有功能都部署到一个功能里,简单易用。
缺点:
1、性能扩展比较难
2、协同开发问题
3、不利于升级维护
垂直应用架构
当访问量逐渐增大,单一应用增加机器带来的加速度越来越小,将应用拆成互不相干的几个应用,以提升效率。此时,用于加速前端页面开发的Web框架(MVC)是关键。
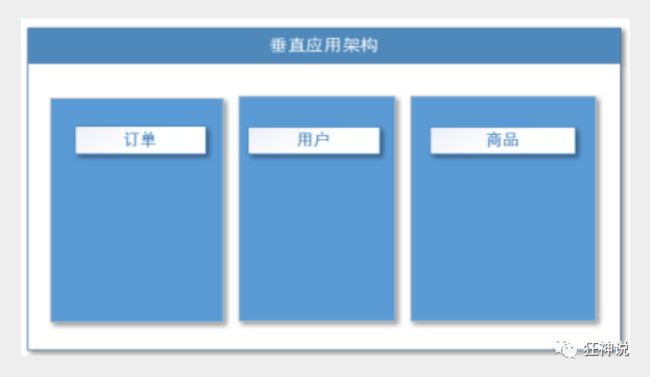
通过切分业务来实现各个模块独立部署,降低了维护和部署的难度,团队各司其职更易管理,性能扩展也更方便,更有针对性。
缺点:公用模块无法重复利用,开发性的浪费
分布式服务架构
当垂直应用越来越多,应用之间交互不可避免,将核心业务抽取出来,作为独立的服务,逐渐形成稳定的服务中心,使前端应用能更快速的响应多变的市场需求。此时,用于提高业务复用及整合的**分布式服务框架(RPC)**是关键。
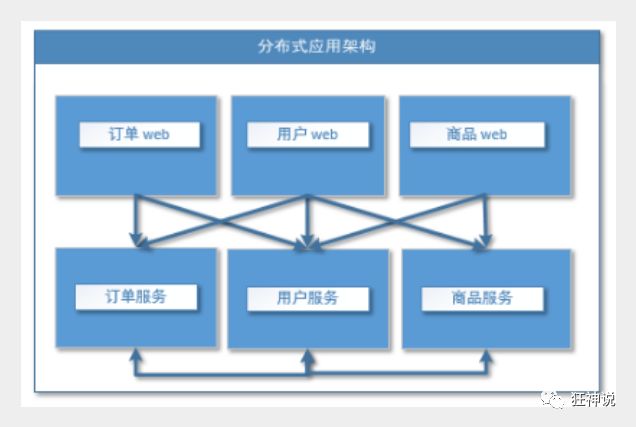
流动计算架构
当服务越来越多,容量的评估,小服务资源的浪费等问题逐渐显现,此时需增加一个调度中心基于访问压力实时管理集群容量,提高集群利用率。此时,用于提高机器利用率的资源调度和治理中心(SOA)[ Service Oriented Architecture]是关键。
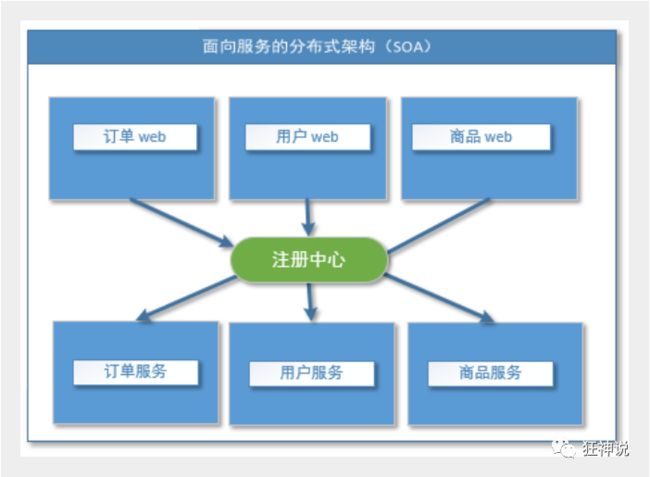
Dubbo要解决的问题/为什么要用Dubbo?
在分布式系统中,系统被拆分为了不同的服务,每个服务器去负责提供整个业务系统的某项核心任务。这种分布式架构能够利用多台服务器去减轻单个服务器的负载,提高了系统的并发量和性能。比如电商系统可以简单地拆分成订单系统、商品系统、登录系统等等,拆分之后的每个服务可以部署在不同的机器上,如果某一个服务的访问量比较大的话也可以将这个服务同时部署在多台机器上。
当一个系统被划分到不同服务器上的服务时,在要完成整个服务功能的时候,就需要这些服务之间相互联系 通信连接 去协作完成任务。
我们可以使用 Java RMI(Java Remote Method Invocation)、Hessian这种支持远程调用的框架来简单地暴露和引用远程服务。但是!当服务越来越多之后,服务调用关系越来越复杂。当应用访问压力越来越大后,负载均衡以及服务监控的需求也迫在眉睫。我们可以用 F5 这类硬件来做负载均衡,但这样增加了成本,并且存在单点故障的风险。
不过,Dubbo 的出现让上述问题得到了解决。Dubbo 帮助我们解决了什么问题呢?
- 负载均衡 : 同一个服务部署在不同的机器时该调用那一台机器上的服务。
- 服务调用链路生成 : 随着系统的发展,服务越来越多,服务间依赖关系变得错踪复杂,甚至分不清哪个应用要在哪个应用之前启动,架构师都不能完整的描述应用的架构关系。Dubbo 可以为我们解决服务之间互相是如何调用的。
- 服务访问压力以及时长统计、资源调度和治理 :基于访问压力实时管理集群容量,提高集群利用率。
- …
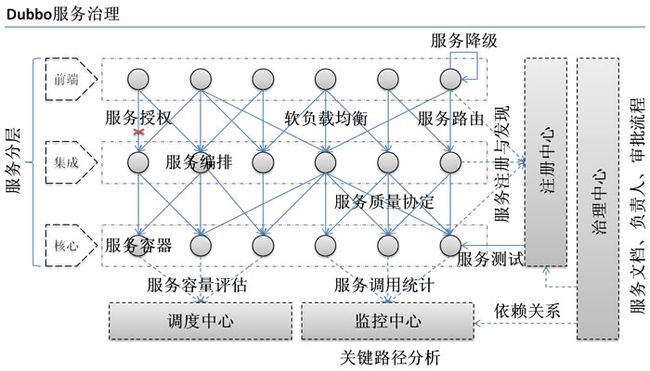
另外,Dubbo 除了能够应用在分布式系统中,也可以应用在现在比较火的微服务系统中。不过,由于 Spring Cloud 在微服务中应用更加广泛,所以,我觉得一般我们提 Dubbo 的话,大部分是分布式系统的情况。
RPC基础
什么是RPC?链接:https://www.jianshu.com/p/2accc2840a1b
RPC(Remote Procedure Call) 即远程过程调用。
RPC是一种进程间通信方式,他是一种技术的思想,而不是规范。它允许程序调用另一个地址空间(通常是共享网络的另一台机器上)的过程或函数,而不用程序员显式编码这个远程调用的细节。即程序员无论是调用本地的还是远程的函数,本质上编写的调用代码基本相同。
也就是说两台服务器A,B,一个应用部署在A服务器上,想要调用B服务器上应用提供的函数/方法,由于不在一个内存空间,不能直接调用,需要通过网络来表达调用的语义和传达调用的数据。为什么要用RPC呢?就是无法在一个进程内,甚至一个计算机内通过本地调用的方式完成的需求,比如不同的系统间的通讯,甚至不同的组织间的通讯,由于计算能力需要横向扩展,需要在多台机器组成的集群上部署应用。RPC就是要像调用本地的函数一样去调远程函数。
两个不同的服务器上的服务提供的方法不在一个内存空间,所以,需要通过网络编程才能传递方法调用所需要的参数。并且,方法调用的结果也需要通过网络编程来接收。 在实现这个过程调用中,我们需要考虑:考虑底层传输方式(TCP还是UDP)、序列化方式等等方面。
通过 RPC 可以帮助我们调用远程计算机上某个服务的方法,这个过程就像调用本地方法一样简单。并且!我们不需要了解底层网络编程的具体细节。
总结一下,RPC要解决的两个问题:
- 解决分布式系统中,服务之间的调用问题。
- 远程调用时,要能够像本地调用一样方便,让调用者感知不到远程调用的逻辑。
实际情况下,RPC很少用到http协议来进行数据传输,毕竟我只是想传输一下数据而已,何必动用到一个文本传输的应用层协议呢,我为什么不直接使用二进制传输?比如直接用Java的Socket协议进行传输?
RPC基本原理
RPC框架基本示意图:
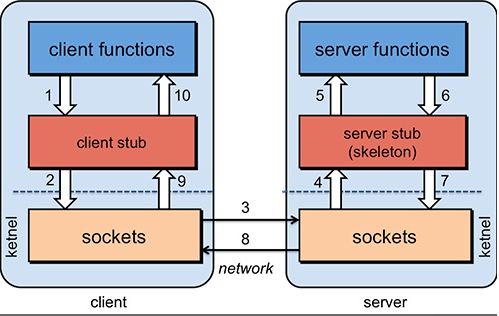
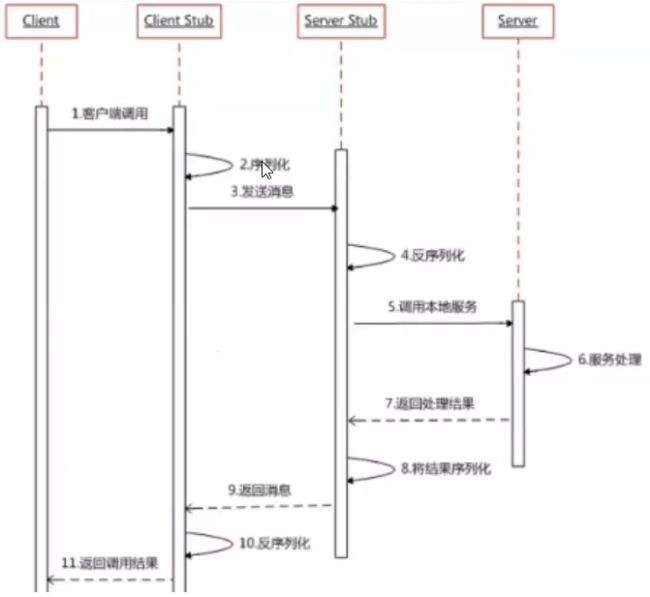
RPC的步骤解析:
- 服务消费方(client)调用以本地调用方式调用服务;
- client stub接收到调用后负责将方法、参数等组装成能够进行网络传输的消息体;
- client stub找到服务地址,并将消息发送到服务端;
- server stub收到消息后进行解码;
- server stub根据解码结果调用本地的服务;
- 本地服务执行并将结果返回给server stub;
- server stub将返回结果打包成消息并发送至消费方;
- client stub接收到消息,并进行解码;
- 服务消费方得到最终结果。
RPC两个核心模块:通讯、序列化
- 序列化:数据传输需要转换
- 通讯:TCP或者UDP(HTTP通信);二进制传输?比如直接用Java的Socket协议进行传输
HTTP :SpringCloud(生态)中使用通信的方式
Netty:30天~
Dubbo~18年重启! Dubbo 3.x RPC Error Exception Dubbo主要用来做RPC。
专业的事,交给专业的人来做~
Dubbo 架构
Dubbo 架构中的核心角色有哪些?
官方文档中的框架设计章节 已经介绍的非常详细了,我这里把一些比较重要的点再提一下。
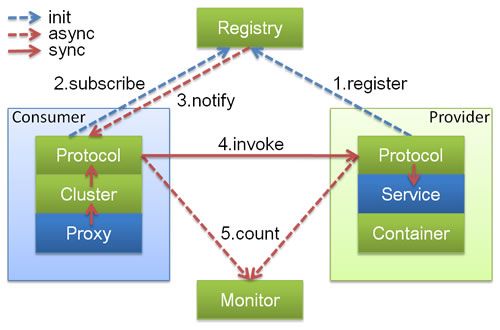
上述节点简单介绍以及他们之间的关系:
-
Container: 服务运行容器,负责加载、运行服务提供者。必须。
-
Provider: 暴露服务的服务提供方,会向注册中心注册自己提供的服务。必须。
-
Consumer: 调用远程服务的 服务消费方,会向注册中心订阅自己所需的服务。必须。
-
Registry: 服务注册与发现的注册中心。注册中心会返回服务提供者地址列表给消费者。非必须。
-
Monitor: 统计服务的调用次数和调用时间的监控中心。服务消费者和提供者会定时发送统计数据到监控中心。 非必须。
服务提供者(Provider):暴露服务的服务提供方,服务提供者在启动时,向注册中心注册自己提供的服务。
服务消费者(Consumer):调用远程服务的服务消费方,服务消费者在启动时,向注册中心订阅自己所需的服务,服务消费者,从提供者地址列表中,基于软负载均衡算法,选一台提供者进行调用,如果调用失败,再选另一台调用。
注册中心(Registry):注册中心返回服务提供者地址列表给消费者,如果有变更,注册中心将基于长连接推送变更数据给消费者
监控中心(Monitor):服务消费者和提供者,在内存中累计调用次数和调用时间,定时每分钟发送一次统计数据到监控中心
调用关系说明
l 服务容器负责启动,加载,运行服务提供者。
l 服务提供者在启动时,向注册中心注册自己提供的服务。
l 服务消费者在启动时,向注册中心订阅自己所需的服务。
l 注册中心返回服务提供者地址列表给消费者,如果有变更,注册中心将基于长连接推送变更数据给消费者。
l 服务消费者,从提供者地址列表中,基于软负载均衡算法,选一台提供者进行调用,如果调用失败,再选另一台调用。
l 服务消费者和提供者,在内存中累计调用次数和调用时间,定时每分钟发送一次统计数据到监控中心。
Dubbo 中的 Invoker 概念了解么?
Invoker 是 Dubbo 领域模型中非常重要的一个概念,你如果阅读过 Dubbo 源码的话,你会无数次看到这玩意。就比如下面我要说的负载均衡这块的源码中就有大量 Invoker 的身影。
简单来说,Invoker 就是 Dubbo 对远程调用的抽象。
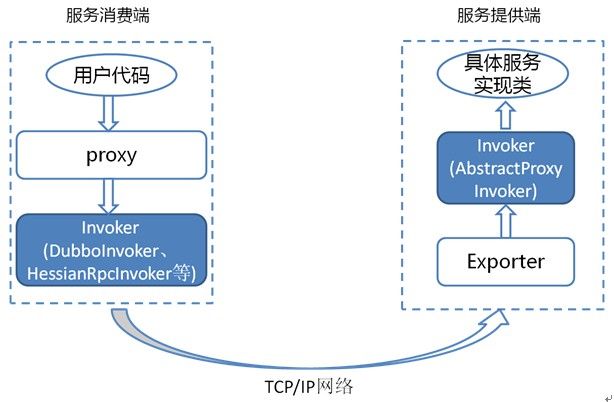
按照 Dubbo 官方的话来说,Invoker 分为
- 服务提供
Invoker - 服务消费
Invoker
假如我们需要调用一个远程方法,我们需要动态代理来屏蔽远程调用的细节吧!我们屏蔽掉的这些细节就依赖对应的 Invoker 实现, Invoker 实现了真正的远程服务调用。
Dubbo 的工作原理了解么?
下图是 Dubbo 的整体设计,从下至上分为十层,各层均为单向依赖。
左边淡蓝背景的为服务消费方使用的接口,右边淡绿色背景的为服务提供方使用的接口,位于中轴线上的为双方都用到的接口。
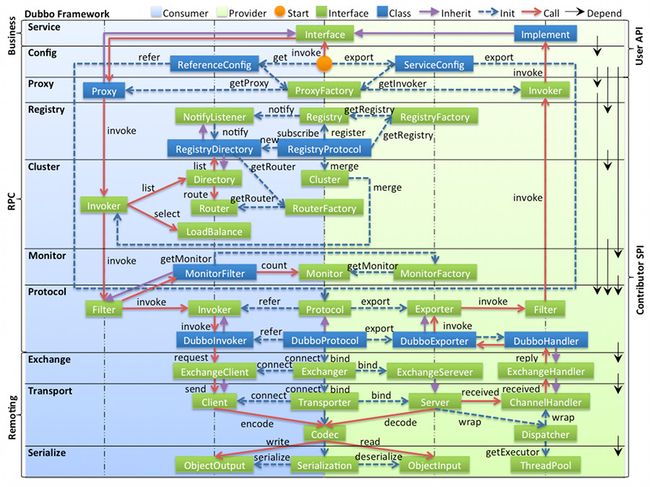
- config 配置层:Dubbo相关的配置。支持代码配置,同时也支持基于 Spring 来做配置,以
ServiceConfig,ReferenceConfig为中心 - proxy 服务代理层:调用远程方法像调用本地的方法一样简单的一个关键,真实调用过程依赖代理类,以
ServiceProxy为中心。 - registry 注册中心层:封装服务地址的注册与发现。
- cluster 路由层:封装多个提供者的路由及负载均衡,并桥接注册中心,以
Invoker为中心。 - monitor 监控层:RPC 调用次数和调用时间监控,以
Statistics为中心。 - protocol 远程调用层:封装 RPC 调用,以
Invocation,Result为中心。 - exchange 信息交换层:封装请求响应模式,同步转异步,以
Request,Response为中心。 - transport 网络传输层:抽象 mina 和 netty 为统一接口,以
Message为中心。 - serialize 数据序列化层 :对需要在网络传输的数据进行序列化。
Dubbo环境搭建
Zookeeper
zookeeper官方链接:https://dubbo.apache.org/zh/docs/v2.7/user/references/registry/zookeeper/
在apache中有zookeeper的下载链接:https://zookeeper.apache.org/releases.html
在使用的时候添加关于 zookeeper的客户端 jar 依赖:
<dependency>
<groupId>org.apache.zookeepergroupId>
<artifactId>zookeeperartifactId>
<version>3.8.0version>
dependency>
zookeeper下载和安装教程(for windows)链接:https://blog.csdn.net/zlbdmm/article/details/109669049
Zookeeper安装
1、下载zookeeper :地址https://zookeeper.apache.org/releases.html, 我们下载3.4.14 , 最新版!解压zookeeper
2、运行/bin/zkServer.cmd ,初次运行会报错,没有zoo.cfg配置文件;
可能遇到问题:闪退 !
解决方案:编辑zkServer.cmd文件末尾添加pause 。这样运行出错就不会退出,会提示错误信息,方便找到原因。

运行 zkServer.cmd文件,提示错误。错误:
apache-zookeeper-3.6.3-bin\bin\..\conf\zoo.cfg file is missing
这提示我们的 conf 配置文件夹中缺失 zoo.cfg 。然后我们将conf文件中的 zoo_sample.cfg 复制,并粘贴到该文件夹下,名字改为:zoo.cfg。

zoo.cfg:zookeeper配置文件中的参数:
- dataDir=./ 临时数据存储的目录(可写相对路径)
- clientPort=2181 zookeeper的端口号

这时候发现还是不对,虽然不闪退了。
但是错误提示的是: 找不到或无法加载主类 org.apache.zookeeper.server.quorum.QuorumPeerMain
原因是:【解决该问题的博客:https://blog.csdn.net/yemuyouhan/article/details/106959830】
也就是下载的是未编译的 jar 包。
注:zookeeper 好像从 3.5 版本以后,命名就发生了改变,如果是 apache-zookeeper-3.5.5.tar.gz 这般命名的,都是未编译的,而 apache-zookeeper-3.5.5-bin.tar.gz 这般命名的,才是已编译的包。
我重新去下载了 *.bin.tar.gz的 编译的jar包进行解压安装。然后重新去进行复制创建 zoo.cfg文件,管理员身份启动运行 zkServer.cmd 文件。
运行结果如下所示, 表示成功

zookeeper简单操作
使用客户端连接 zookeeper:
-
运行 zkCli.cmd文件:
-
或者在bin目录下的命令窗口 cmd中执行:
zkCli.cmd -server 127.0.0.1:2181
打开运行结果:

在客户端使用ls命令来查看当前Zookeeper中所包含的内容:
-
命令:ls /
[zk: 127.0.0.1:2181(CONNECTED) 0] ls / [zookeeper] [zk: 127.0.0.1:2181(CONNECTED) 1]
创建一个新的znode节点“zk"以及与它关联的字符串:
-
命令:create -e /alzn 123 ,表示 创建一个alzn节点,值为123
[zk: localhost:2181(CONNECTED) 3] create -e /alzn 123 Created /alzn [zk: localhost:2181(CONNECTED) 4] -
命令:create /al zn 表示创建一个 al 节点,值为 zn
[zk: localhost:2181(CONNECTED) 4] create /al zn Created /al -
查看此时所有的节点:ls /
一共有三个节点,为 al,alzn,zookeeper
[zk: localhost:2181(CONNECTED) 5] ls / [al, alzn, zookeeper]
获取znode节点‘zk’
-
命令:get /al 表示获取节点 al 的值
[zk: localhost:2181(CONNECTED) 7] get /alzn 123 [zk: localhost:2181(CONNECTED) 8] get /al zn
删除znode节点"zk"
-
命令: delete /al 表示删除节点 al
[zk: localhost:2181(CONNECTED) 10] delete /alzn [zk: localhost:2181(CONNECTED) 11] delete /al [zk: localhost:2181(CONNECTED) 12] ls / [zookeeper]
退出 zookeeper客户端:
- 命令: quit
Windowns下安装dubbo-admin
dubbo本身并不是一个服务软件。它其实就是一个jar包,能够帮你的java程序连接到zookeeper,并利用zookeeper消费、提供服务。
但是为了让用户更好的管理监控众多的dubbo服务,官方提供了一个可视化的监控程序dubbo-admin,不过这个监控即使不装也不影响使用。
我们这里来安装一下:
1、下载dubbo-admin
地址 :https://github.com/apache/dubbo-admin/tree/master
2、解压进入目录
修改 dubbo-admin\src\main\resources \application.properties 指定zookeeper地址。我们找到 application.properties 配置文件:
application.properties:
# centers in dubbo2.7, if you want to add parameters, please add them to the url
admin.registry.address=zookeeper://127.0.0.1:2181
admin.config-center=zookeeper://127.0.0.1:2181
admin.metadata-report.address=zookeeper://127.0.0.1:2181
admin.root.user.name=root
admin.root.user.password=root
#session timeout, default is one hour
admin.check.sessionTimeoutMilli=3600000
#compress
server.compression.enabled=true
server.compression.mime-types=text/css,text/javascript,application/javascript
server.compression.min-response-size=10240
#token timeout, default is one hour
admin.check.tokenTimeoutMilli=3600000
#Jwt signingKey
admin.check.signSecret=86295dd0c4ef69a1036b0b0c15158d77
#dubbo config
dubbo.application.name=dubbo-admin
dubbo.registry.address=${admin.registry.address}
# h2
spring.datasource.url=jdbc:h2:mem:~/dubbo-admin;
spring.datasource.username=sa
spring.datasource.password=
# id generate type
mybatis-plus.global-config.db-config.id-type=none
在application.properties 资源配置文件中:
- admin.registry.address 注册中心
- admin.config-center 配置中心
- admin.metadata-report.address 元数据中心
在该资源配置文件中添加 zookeeper的port信息、dubbo-admin的服务port信息等:
server.port=7001
spring.velocity.cache=false
spring.velocity.charset=UTF-8
spring.velocity.layout-url=/templates/default.vm
spring.messages.fallback-to-system-locale=false
spring.messages.basename=i18n/message
spring.root.password=root
spring.guest.password=guest
dubbo.registry.address=zookeeper://127.0.0.1:2181
3、在我们的项目目录下打包dubbo-admin
mvn clean package -Dmaven.test.skip=true
第一次打包的过程有点慢,需要耐心等待!直到成功!
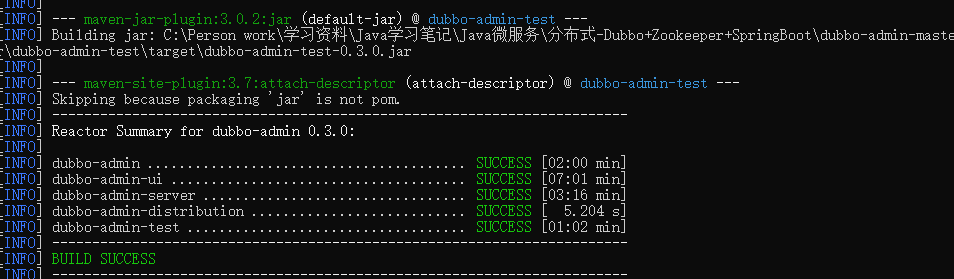
可能由于我是对整个 dubbo-admin-master 文件夹进行了打包,所以打包的时间有点长。
在dubbo-admin-server 以及 dubbo-admin-test 这两个文件夹下都有 target,即打包好的 jar包。
【我前面是在 dubbo-admin-server中的资源配置文件中修改的端口号 7001,所以运行这个文件夹下的 jar 包】
4、执行 dubbo-admin\target 路径下打包好的 jar 包
java -jar dubbo-admin-server-0.3.0.jar
【注意:zookeeper的服务一定要打开!】
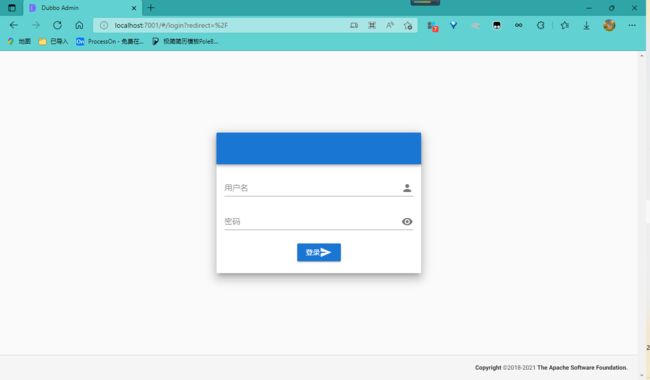
执行完毕,我们去访问一下 Dubbo Admin ,url路径:http://localhost:7001/ 这时候我们需要输入登录账户和密码,我们都是默认的root-root;
在前面的 application.properties 中的定义账户和密码:
admin.root.user.name=root
admin.root.user.password=root
登录成功后,查看界面:
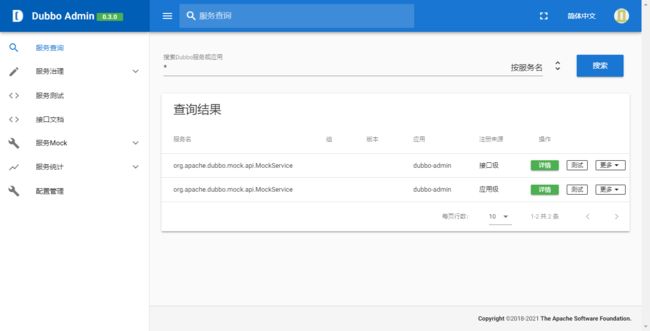 安装完成!
安装完成!
SpringBoot + Dubbo + zookeeper:服务注册实战
在前面已经完成了Zookeeper 的安装,以及 dubbo-admin的可视化监控程序来查看服务。
在这里,SpringBoot整合Dubbo+Zookeeper 去实现 服务注册、服务发现。
环境搭建
启动zookeeper !!!
创建一个空的项目:dubbo+zookeeper。
服务端:提供服务
新建一个模块 module,选择SpringBoot创建。依赖选择spring web。
provider-server模块:【关于买票的服务】
- 编写一个服务。创建service 包。
- 编写service类。在service包中下创建一个接口 TicketService和接口实现类TicketServiceImpl。
TicketService:
package com.al.service;
public interface TicketService {
public String getTicket();
}
TicketServiceImpl:
package com.al.service;
public class TicketServiceImpl implements TicketService{
@Override
public String getTicket() {
return "《毛主席语录》";
}
}
服务消费者:获取服务消费
在这里同样创建一个模块 module。选择SpringBoot创建,依赖选择spring web。
consumer-server模块:
- 编写一个服务,创建service包。
- 在客户端这里的 service包/文件夹,用于接收TicketService接口,获取服务提供者的服务。(服务消费者:获取服务消费)
UserService:
package com.al.service;
public class UserService {
//我们需要去拿去注册中心的服务
}
系统的需求:现在用户想要去使用买票的服务,如何去获取呢?因为这属于两个微服务 SpringBoot项目。
不同的服务之间如何进行通信连接?如何传输数据,进行治理? 在这里,我们先查看Dubbo+zookeeper是如何解决的。
将服务注册到注册中心,这样 用户端就能够从注册中心去获取该服务的应用。
服务消费者消费服务提供者的服务:Dubbo+Zookeeper
为了便于去接收,那么在 application.properties 配置文件中关于 port:
- 服务端的配置文件中,设置端口为8001
- 客户端的配置文件中,设置端口为8002
服务提供者
将服务提供者注册到注册中心,我们需要整合Dubbo和zookeeper,所以需要导包。我们从dubbo官网进入github,看下方的帮助文档,找到dubbo-springboot,找到依赖包。
- 同样的,服务消费者端也要导入同样的依赖。
导入依赖:dubbo+zookeeper
- zookeeper及其依赖包,解决日志冲突,我们需要剔除日志依赖;
<dependency>
<groupId>org.apache.dubbogroupId>
<artifactId>dubbo-spring-boot-starterartifactId>
<version>3.0.2.1version>
dependency>
<dependency>
<groupId>com.github.sgroschupfgroupId>
<artifactId>zkclientartifactId>
<version>0.1version>
dependency>
<dependency>
<groupId>org.apache.curatorgroupId>
<artifactId>curator-frameworkartifactId>
<version>5.2.1version>
dependency>
<dependency>
<groupId>org.apache.curatorgroupId>
<artifactId>curator-recipesartifactId>
<version>5.2.1version>
dependency>
<dependency>
<groupId>org.apache.zookeepergroupId>
<artifactId>zookeeperartifactId>
<version>3.8.0version>
<exclusions>
<exclusion>
<groupId>org.slf4jgroupId>
<artifactId>slf4j-log4j12artifactId>
exclusion>
exclusions>
dependency>
在springboot配置文件中配置dubbo相关属性。配置文件application.properties:
- 服务提供者的端口号:port=8001
- 配置注册中心的地址,以及服务发现名,和要扫描的包
# 服务提供者
server.port=8001
# 服务应用名字
dubbo.application.name=provider-server
# 注册中心地址
dubbo.registry.address=zookeeper://127.0.0.1:2181
# 哪些服务要被注册
dubbo.scan.base-packages=com.al.service
在service的实现类中配置服务注解,发布服务!
- 在想要被注册的服务上面~增加一个注解@Service。 注意这个注解的包是 dubbo中的。org.apache.dubbo.config.annotation.Service;
- 原来在Spring中将service层的类注入到bean容器中,我们可以采用@Component,或者@Service。对于将类注入到Spring IOC容器bean中的注解@Service的包为: org.springframework.stereotype.Service;
TicketServiceImpl:
- @Service //将服务发布出去。在项目一启动的时候就被扫描,然后自动注册到注册中心
- @Component // 放在容器Bean中。在使用dubbo之后就尽量不要使用@Service注解 实现bean对象的注入
package com.al.service;
import org.apache.dubbo.config.annotation.Service;
import org.springframework.stereotype.Component;
// 服务注册与发现
@Service //将服务发布出去。在项目一启动的时候就被扫描,然后自动注册到注册中心
@Component // 放在容器Bean中。在使用dubbo之后就尽量不要使用@Service注解 实现bean对象的注入
public class TicketServiceImpl implements TicketService{
@Override
public String getTicket() {
return "《毛主席语录》";
}
}
实现的逻辑:在项目启动之后,会去扫描指定的包下带有@Component注解的服务,对于@Service注解的服务,将它发布在指定的注册中心。
服务消费者
消费者如何进行消费呢?
- 导入相关的依赖
- 在配置中添加注册中心的地址,配置自己的服务名
- 远程注入服务:获取远程的服务提供者 的接口,获取服务提供者的服务
关于pom.xml中的maven依赖:和服务提供者一样
- dubbo和zookeeper的相关maven依赖
<dependency>
<groupId>org.apache.dubbogroupId>
<artifactId>dubbo-spring-boot-starterartifactId>
<version>3.0.2.1version>
dependency>
<dependency>
<groupId>com.github.sgroschupfgroupId>
<artifactId>zkclientartifactId>
<version>0.1version>
dependency>
<dependency>
<groupId>org.apache.curatorgroupId>
<artifactId>curator-frameworkartifactId>
<version>5.2.1version>
dependency>
<dependency>
<groupId>org.apache.curatorgroupId>
<artifactId>curator-recipesartifactId>
<version>5.2.1version>
dependency>
<dependency>
<groupId>org.apache.zookeepergroupId>
<artifactId>zookeeperartifactId>
<version>3.8.0version>
<exclusions>
<exclusion>
<groupId>org.slf4jgroupId>
<artifactId>slf4j-log4j12artifactId>
exclusion>
exclusions>
dependency>
配置参数:
在springboot配置文件中配置dubbo相关属性。配置文件application.properties:
- 服务消费者的端口号:port=8002
- 配置参数:注册中心的地址信息(消费者知道去哪拿服务进行消费);配置自己的service名
# 服务消费者
server.port=8002
# 当前应用的名字。消费者去哪里取服务,需要暴露自己的名字
dubbo.application.name=consumer-server
# 注册中心的地址.知道去哪里拿服务
dubbo.registry.address=zookeeper://127.0.0.1:2181
远程注入服务:
本来正常步骤是需要将服务提供者的接口打包,然后用pom文件导入,我们这里使用简单的方式,直接将服务的接口拿过来,路径必须保证正确,即和服务提供者相同;
在这个service层中也创建一个 TicketService:
- **两边的接口需要相同,才能调用。**路径需要一样。
完善消费者的服务类 service类:
UserService:
package com.al.service;
import org.apache.dubbo.config.annotation.Reference;
import org.springframework.stereotype.Service;
// 服务消费者
@Service //放到spring IOC容器中
public class UserService {
//想要拿到 provider-server中提供的票 服务,我们需要去注册中心拿到服务。
// @Reference //远程引用指定的服务,他会按照全类名进行匹配,看谁给注册中心注册了这个全类名
@Reference //引用。 pom坐标,可以定义路径相同的接口名
TicketService ticketService;
public void buyTicket(){
String ticket = ticketService.getTicket();
System.out.println("在注册中心拿到=>"+ticket);
}
}
测试:
在服务消费者/客户端这里编写测试类,测试看能否获取服务进行消费。
package com.al;
import com.al.service.UserService;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
@SpringBootTest
class ConsumerServerApplicationTests {
@Autowired
UserService userService;
@Test
void contextLoads() {
userService.buyTicket();
}
}
启动项目进行测试:
- 开启zookeeper
- 开启服务提供者服务
- 服务消费者的消费测试,查看结果。
错误提示:
在启动服务提供者服务的时候,一直报错:
java.lang.RuntimeException: java.lang.NoClassDefFoundError: org/apache/curator/x/discovery/ServiceDiscoveryBuilder
java.lang.RuntimeException: java.lang.NoClassDefFoundError: org/apache/curator/x/discovery/ServiceDiscoveryBuilder
错误信息提示的是没有找到这个定义的类: org/apache/curator/x/discovery/ 。但在我前面的依赖中已经导入了 curator的相关依赖:curator-framework、curator-recipes
<dependency>
<groupId>org.apache.curatorgroupId>
<artifactId>curator-frameworkartifactId>
<version>5.2.1version>
dependency>
<dependency>
<groupId>org.apache.curatorgroupId>
<artifactId>curator-recipesartifactId>
<version>5.2.1version>
dependency>
此时还需要再导入这个关于 curator的maven依赖:curator-x-discovery
<dependency>
<groupId>org.apache.curatorgroupId>
<artifactId>curator-x-discoveryartifactId>
<version>5.2.1version>
dependency>
同样的,我们在服务提供者模块中的pom.xml配置信息中也添加关于 curator-x-discovery 这个curator的maven依赖。
此时再重新启动 provider-server 服务提供者主程序,启动consumer-server服务消费者的测试类,查看结果。可以看到在控制台输出:
在注册中心拿到=>《毛主席语录》