大一Python期末复习笔记
目录
前言
一,输出格式控制
①多行输出
②不换行输出
③精度保留和对齐
Ⅰ.format
Ⅱ.f'{}'
Ⅲ.%
二,嵌套
①嵌套循环
Ⅰ.for
Ⅱ.while
②嵌套列表,字典
三,列表与字符串
①添加元素
②切片访问与逆序,join
③count,find,index
④删除与替换
list
str
四,函数
①lambda
②复合函数
③可变长参数
④递归函数与迭代器
Ⅰ.递归
Ⅱ.yield
⑤eval
⑥assert
⑦zip,zip(*),*zip
Ⅰ、zip
Ⅱ、zip(*)
Ⅲ、*zip
五,文件读取和处理
①open
②with
③常用的处理
六,numpy
①数组的创建
②shape&reshape
③zeros&ones
④eye&diagonal
⑤比较运算
⑥切片和索引
⑦vectorize
七,曲线绘制
八,字典
①元素的增加,删除,查找,修改
②keys&values
③items&for
九、is,==,copy
①is&==
②copy&deepcopy
结语
前言
一个寒假没碰Python,难免会生疏。本文是作者综合了学校考试,平时笔记还有Educoder作业,以及网上相关资源提取出来的知识点的呈现,既帮助了本人复习,也希望对你有所帮助。记得一键三连哦~~
一,输出格式控制
①多行输出
六个单引号
print('''hello
wolrd''')
output:
hello
wolrd
②不换行输出
print('hello',end='---')#指定连接符,可为空
print('world',end='---')
print('!')
output:
hello---world---!③精度保留和对齐
Ⅰ.format
>>> print('{:+.2f}'.format(3.1415))#带符号保留两位小数
+3.14
>>> print('{:%}'.format(0.1415))#以%形式保留
14.150000%Ⅱ.f'{}'
username=input("What's your name?\n")#\n为换行符
print(f'Hello, {username.title()}!')
What's your name?
he
Hello, He!Ⅲ.%
>>> print('%+.2f'%(12.3456))#带符号保留两位小数
+12.35
>>> print('%.2g'%(12.3456))#保留2位有效数字
12print('%-8.2f'%(3.14159),end='')#左对齐占用八个
print('hello')
print('%8.2f'%(3.14159),end='')#右对齐
print('world')
3.14 hello
3.14world二,嵌套
①嵌套循环
Ⅰ.for
for i in s1:
for j in s2:
# do something
# do something elseⅡ.while
while expression1:
while expression2:
# do something
# do something else②嵌套列表,字典
l=[[1,2,3],[4,5,6],[7,8,9,[10]]]
print(l[2][3])
print(l[2][3][0])
d={1:'a',2:'b',3:'c',4:{5:'f',6:{7:'g'}}}
print(d[4][6])
print(d[4][6][7])
[10]
10
{7: 'g'}
g三,列表与字符串
列表与字符串有很多相似之处,故将其并在一起
①添加元素
l=[1,2,3]
l.append(4)
l.append('567')
l.append((8,9))#添加元组
l.extend('abc')#逐个添加
print(l)
s='qwer'
s+='tyui'
print(s)[1, 2, 3, 4, '567', (8, 9), 'a', 'b', 'c']
qwertyui②切片访问与逆序顺序,join
l=[1,2,3,4,5,6,7]
s='1234567'
print(l[0:7:1],s[0:7:1])#l[start:end:step],均可缺省,end取不到
print(l[6:0:-1],s[6:0:-1])#step小于0从右至左,start>end
print(l[::-1],s[::-1])#返回逆序
print(reversed(l),type(reversed(l)))#使用reversed不会返回列表,而是一个迭代器
#因此要进行数据转化。而字符串的要通过join来实现
print(reversed(s),type(reversed(s)))
print(list(reversed(l)),''.join(reversed(s)))#'连接符'.join(str/list)
[1, 2, 3, 4, 5, 6, 7] 1234567
[7, 6, 5, 4, 3, 2] 765432
[7, 6, 5, 4, 3, 2, 1] 7654321
[7, 6, 5, 4, 3, 2, 1] 7654321 reverse和reversed,sort和sorted
>>> l=[1,2,3,5,4]
>>> l.reverse()
>>> l
[4, 5, 3, 2, 1]
>>> list(reversed(l))
[1, 2, 3, 5, 4]
>>> l.sorted()
>>> l.sort()
>>> l
[1, 2, 3, 4, 5]③count,find,index
>>> l=[1,2,3,4,1,1,2]
>>> l.count(1)
3
>>> l.index(1)#返回第一个1的index
0
>>> s='1234112'
>>> s.count('1')
3
>>> s.find('1')#返回第一个1的index
0关于find和index的区别
>>> s='qwertyuiop'
>>> s.find('a')#当find中的字符段不在其中时,返回-1
-1
>>> s[-1]#值得注意的是,s[-1]是存在的,而find只会返回正向索引值
'p'
>>> l=[1,2,3,4]
>>> l.index(5)#而index与find不同,会报错
Traceback (most recent call last):
File "", line 1, in
l.index(5)
ValueError: 5 is not in list ④删除与替换
list
Ⅰ.del/pop
>>> l=[0,1,2,3,4]
>>> l.pop(0)#会返回被删去的值,且只能用索引进行操作,不支持切片
0
>>> l
[1, 2, 3, 4]
>>> del l[0:2]#支持切片
>>> l
[3, 4]Ⅱ.remove
>>> l=[0,1,2,3,4,5,1,1,2]
>>> l.remove(1)#删除第一个1
>>> l
[0, 2, 3, 4, 5, 1, 1, 2]如要删除所有的特定元素,可结合count和循环使用
⑤创建嵌套列表
>>> #创建3*4嵌套全0列表(初始化)
>>> l=[[0]*4 for i in range(3)]
>>> l
[[0, 0, 0, 0], [0, 0, 0, 0], [0, 0, 0, 0]]str
Ⅰ.strip
>>> s = '****abcd**efgh***-***'
>>> s=s.lstrip('*')#删除左边指定字符并重新赋值给s
>>> s
'abcd**efgh***-***'
>>> s=s.rstrip('*')#右边。若两边都要删除,可直接用strip()
>>> s
'abcd**efgh***-'Ⅱ.replace
>>> s=s.replace('*','!')#replace(a,b),replace a with b
>>> s
'!!!!abcd!!efgh!!!-!!!'Ⅲsplit
>>> s='1,2,3,4'
>>> s=s.split(',')#指定分隔符,返回一个列表
>>> s
['1', '2', '3', '4']四,函数
①lambda
>>> f=lambda x,y:x*y+x+y #变量名称,函数关系
>>> f(1,2)
5②复合函数
from math import sin, cos
delX = 0.001
x = float(input())
def diff(f):#求f(x)的导数
g=lambda x:(f(x+delX)-f(x-delX))/(2*delX)
return g
print("%.2f"%(diff(sin)(x)))#f是指定的具体函数,返回其导函数的估计值,x为代入点
0
1.00
>>> ③可变长参数
def method(*args,**kwargs):
print(args,type(args))#*args被解读为元组
print(kwargs,type(kwargs))#**kargs被解读为字典
for arg in args:
print('arg:',arg)
for kwarg in kwargs:#**参数一定出现在整个参数列表的最后
print('%s:' %kwarg,kwargs[kwarg])
method(1,'one',a = 1,b = 'two')(1, 'one')
{'a': 1, 'b': 'two'}
arg: 1
arg: one
a: 1
b: two ④递归函数与迭代器
求解斐波那契数列
Ⅰ.递归
def fib(n):
if n ==1:
return 0
elif n==2:
return 1
else:
return fib(n-1)+fib(n-2)Ⅱ.yield
理解:
'''在一个函数中添加了yield关键字之后,该函数在调用时会变成一个生
成器。通过使用next关键字可以使该生成器运行到第一个yield处停止。
再次使用next,使代码接着上次停止的地方运行至下一个yield(如果
没有则结束)。'''
def generator():
print("debug 1")
yield 1
print("debug 2")
yield 2
print("debug 3")
yield 3
G = generator()#如果不将generator()赋值给G调用,那么每次调用都会重新开始
print( next(G), "\n")
print( next(G), "\n")
print( next(G), "\n")
print(next(generator()))
'''
debug 1
1
debug 2
2
debug 3
3
debug 1
1
'''利用yield解决斐波那契数列
def fib():
a = 0
b = 1
yield a # 第一次的返回值
yield b # 第二次的返回值
while True:
a,b = b, a+b
yield b # 后面项的返回值
f = fib()
n = int(input())
for i in range(n):
s=next(f)
print(s)⑤eval
'''eval(expression),eval()函数用于执行一个字符串表达式,
并且返回该表达式的值。'''
s='x**2+y**2+x-y'
f=lambda x,y:eval(s)
print(f(1,2))#return 4
⑥assert
def zero(s):
a = int(s)
assert a > 0,"a超出范围" #这句的意思:如果a确实大于0,程序正常往下运行
return a
print(zero(float(input())))
#但是如果a是小于0的,程序会抛出AssertionError错误,报错为参数内容“a超出范围”
⑦zip,zip(*),*zip
Ⅰ、zip
>>> l1=[0,1,2]
>>> l2=[1,2,3]
>>> l3=[2,3,4,5]
>>> z1=zip(l1,l2)
>>> z1 #返回一个对象,如同map,reversed
>>> list(z1)
[(0, 1), (1, 2), (2, 3)]
>>> z2=zip(l1,l3)
>>> list(z2)
[(0, 2), (1, 3), (2, 4)]#长度不一致以小的为标准
>>> d1={'1':1,'2':2,'3':3}
>>> z1=zip(d1)
>>> list(z1)
[('1',), ('2',), ('3',)]#返回keys Ⅱ、zip(*)
>>> l1=[[1,2,3],[4,5,6]]#l1=[p1,p2],是一个压缩列表
>>> z1=zip(*l1) #认为前面一个储存x的所有值,后面储存y的所有值
>>> list(z1) #返回[(x,y)]
[(1, 4), (2, 5), (3, 6)]#解压缩
>>> l2=[['1','2','3'],[1,2,3]] #[[keys],[values]]
>>> z2=zip(*l2)
>>> dict(z2)
{'1': 1, '2': 2, '3': 3}Ⅲ、*zip
>>> l1=[1,2,3]
>>> l2=[5,6,7]
>>> z1=*zip(l1,l2)
SyntaxError: can't use starred expression here
>>> *zip(l1,l2)
SyntaxError: can't use starred expression here
>>> zip(*zip(l1,l2))
>>> print(*zip(l1,l2))
(1, 5) (2, 6) (3, 7)
#注:*不能单独使用,常用于函数的传参,此处print即为函数 五,文件读取和处理
①open
f=open('text.txt','w')
f.write('hello\n')#注意添加换行符
f.write('world')
f.close()#记得关闭文件②with
with open('filepath','r') as f:
for line in f:
#无需close,当语句在with缩进外时会自动关闭③常用的处理
f=open('path','r').readlines()#返回列表,行数-1即为索引值
result=[0]*len(f)
for i in range(len(f)):#对每一行进行处理,一般为数据提取
l=f[i].strip('\n').split()#去除换行符,得到一个列表
reslut=l[0]#例如需要将文档第一列数据提取出来
六,numpy
参考pyhon之numpy详细教程
①数组的创建
>>> a=np.array([[1,2],[3,4]])#2×2
>>> print(a,type(a))
[[1 2]
[3 4]] ②shape&reshape
>>> a.shape
(2, 2)
>>> b=a.reshape(1,4)
>>> b
array([[1, 2, 3, 4]])③zeros&ones
>>> import numpy as np
>>> a=np.zeros((2,2))
>>> a
array([[0., 0.],
[0., 0.]])
>>> b=np.zeros_like(a)#创建同型矩阵
>>> b
array([[0., 0.],
[0., 0.]])
>>> c=np.ones_like(a)
>>> c
array([[1., 1.],
[1., 1.]])④eye&diagonal
>>> e=np.eye(3)#n阶单位方阵
>>> e
array([[1., 0., 0.],
[0., 1., 0.],
[0., 0., 1.]])
>>> d=np.diag((1,2,3))#创建对角矩阵
>>> d
array([[1, 0, 0],
[0, 2, 0],
[0, 0, 3]])⑤比较运算
>>> import numpy as np
>>> a=np.arange(1,10).reshape(3,3)
>>> a
array([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
>>> a>5#返回bool矩阵
array([[False, False, False],
[False, False, True],
[ True, True, True]])
>>> a[a>5]#根据bool矩阵,True对应的值
array([6, 7, 8, 9])⑥切片和索引
>>> a=np.arange(10)
>>> b=a[2:7:2]#[start:end:step],不包括end
>>> b
array([2, 4, 6])
>>> a=np.arange(1,10).reshape(3,3)
>>> b=a[(0,1,2),(2,1,0)]#返回(0,2),(1,1),(2,0)为索引的值
>>> a
array([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
>>> b
array([3, 5, 7])⑦vectorize
import numpy as np
f=lambda x:x**3+x**2+x+1
g=np.vectorize(f)#与map相似
a=np.array([1,2,3,4,5])
print(g(a),type(g(a)))#[ 4 15 40 85 156]
关于otypes的说明
vectorize输出的数据类型是通过使用输入的第一个元素调用函数来确定的。通过指定otypes参数可以避免这种情况。以下为例,第一个数据为0,被认为是int,所以后面生成的都当作int,故需要指定otypes=[float]
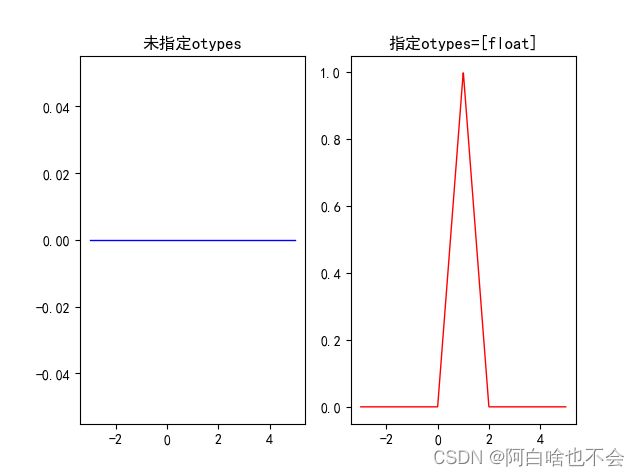
import matplotlib.pyplot as plt
import numpy as np
plt.rcParams['font.sans-serif'] = ['SimHei']#显示中文标签
plt.rcParams['axes.unicode_minus'] = False#显示负号
def f(x):
if x<0 or x>=2:
s=0
return s
elif 0<=x<1:
s=x
return s
else:
s=2-x
return s
H=np.vectorize(f)
g=np.vectorize(f,otypes=[float])
x=np.linspace(-3,5,1000)
y=H(x)
z=g(x)
plt.subplot(1,2,1)
plt.plot(x,y,'b-',linewidth=1)
plt.title('未指定otypes')
plt.subplot(1,2,2)
plt.plot(x,z,'r-',linewidth=1)
plt.title('指定otypes=[float]')
plt.show()⑧mean
>>> import numpy as np
>>>#array
>>> b=np.array([[1,2,3],[4,5,6]])
>>> b
array([[1, 2, 3],
[4, 5, 6]])
>>> np.mean(b)#返回整体均值
3.5
>>> np.mean(b,0)#0,1表示维度
array([2.5, 3.5, 4.5])
>>> np.mean(b,1)
array([2., 5.])
>>>#matrix
>>> a=np.mat([[1,2,3],[4,5,6]])#创建2*3矩阵
>>> a
matrix([[1, 2, 3],
[4, 5, 6]])
>>> np.mean(a)
3.5
>>> np.mean(a,0)
matrix([[2.5, 3.5, 4.5]])
>>> np.mean(a,1)
matrix([[2.],
[5.]])七,曲线绘制
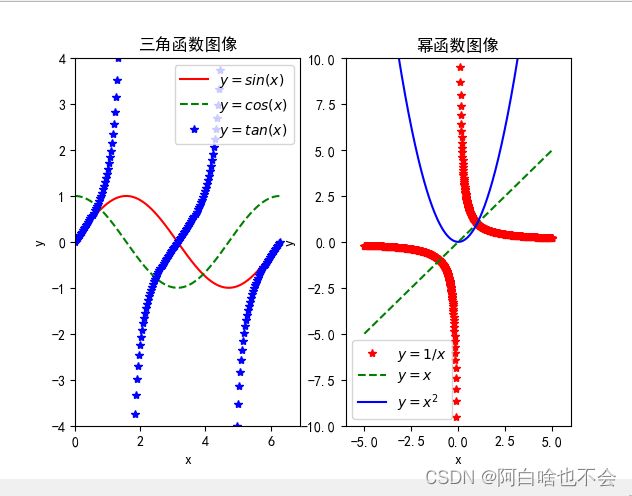
以三角函数和幂函数图形绘制来说明,参考python绘制初等函数
import matplotlib.pyplot as plt
import numpy as np
plt.rcParams['font.sans-serif'] = ['SimHei']#显示中文标签
plt.rcParams['axes.unicode_minus'] = False#显示负号
x = np.linspace(0,2*np.pi, 200)
f1 = np.sin(x)
f2 = np.cos(x)
f3 = np.tan(x)
plt.subplot(1,2,1)#声明:在这张画布上有1*2个图,现在画第一个
plt.plot(x, f1,'-r',x,f2,'--g',x,f3,'b*')#直接传入数据就可,引号内为linestyle
plt.xlim(x.min() * 1.1, x.max() * 1.1)# limit x range
plt.ylim(-4, 4) # limit y range
plt.legend([r'$y=sin(x)$',r'$y=cos(x)$',r'$y=tan(x)$'],loc='best')
plt.xlabel('x')#说明x,y轴
plt.ylabel('y')
plt.title('三角函数图像')#添加标题
plt.subplot(1,2,2)#画1*2的第二张图
x=np.linspace(-5,5,1000)
g1=1/x
g2=x
g3=x**2
plt.axis([-6,6,-10,10])#axis([xmin xmax ymin ymax])
plt.plot(x, g1,'r*',x,g2,'--g',x,g3,'b-')
plt.legend([r'$y=1/x$',r'$y=x$',r'$y=x^2$'],loc='best')
plt.xlabel('x')
plt.ylabel('y')
plt.title('幂函数图像')
plt.show()
八,字典
①元素的增加,删除,查找,修改
字典是无序的,不支持索引和切片
>>> d={'name':'zhangsan','age':18,'sex':'male'}
>>> d['city']='changsha'#增加
>>> d
{'name': 'zhangsan', 'age': 18, 'sex': 'male', 'city': 'changsha'}
>>> d['sex']#查找
'male'
>>> d['name']='lisi'#修改
>>> d['name']
'lisi'
>>> del d['name']#删除
>>> d
{'age': 18, 'sex': 'male', 'city': 'changsha'}
>>> d.pop('age')
18
>>> d#pop的用法:删除指定key,返回对应的value.与在list中的用法相同
{'sex': 'male', 'city': 'changsha'}②keys&values
>>> d
{'age': 18, 'sex': 'male', 'city': 'changsha'}
>>> d.keys()
dict_keys(['age', 'sex', 'city'])
>>> d.values()
dict_values([18, 'male', 'changsha'])③items&for
遍历一个字典
>>> d.items()#返回列表,键值对以元组形式存放
dict_items([('age', 18), ('sex', 'male'), ('city', 'changsha')])
>>> for i,j in d.items():
print((i,j))
('age', 18)
('sex', 'male')
('city', 'changsha')④按values排序
soted(d,key=),key 后面接自定排序规则
>>> d={'a':1,'b':4,'c':2,'d':3}
>>> d.items()
dict_items([('a', 1), ('b', 4), ('c', 2), ('d', 3)])
>>> d1=sorted(d.items(),key=lambda x:x[1]) #升序
>>> d1
[('a', 1), ('c', 2), ('d', 3), ('b', 4)]
>>> d2=sorted(d.items(),key=lambda x:x[1],reverse=True) #降序
>>> d2
[('b', 4), ('d', 3), ('c', 2), ('a', 1)]九、is,==,copy
①is&==
is比较的是两个对象的地址值,也就是两个对象是否为同一个实例对象
==比较的是对象的值是否相等,其调用了对象的__eq__()方法。
l1=[1,2]
l2=l1
l3=list(l1)
print(id(l1),id(l2),id(l3))
>>> 2646623610248 2646623610248 2646625833928
f=lambda i,j,k:print(i==j,i==k)#这里命名两个函数方便判断
g=lambda i,j,k:print(i is j,i is k)
f(l1,l2,l3)
>>> True True
g(l1,l2,l3)
>>> True False②copy&deepcopy
①浅拷贝,指的是重新分配一块内存,创建一个新的对象,但里面
的元素是原对象中各个子对象的引用。
②深拷贝,是指重新分配一块内存,创建一个新的对象,并且将原对象中的元素,
以递归的方式,通过创建新的子对象拷贝到新对象中。因此,新对象和原对象没
有任何关联。
import copy as c
l4=[[0,1],[2,3]]
l5=c.copy(l4)#浅拷贝
l6=c.deepcopy(l4)#深拷贝
f(l4,l5,l6) #三个对象的值的相等
>>>True True
g(l4,l5,16)
>>>False False
print(id(l4),id(l5),id(l6))#三个的id都不相同
>>> 3085327296264 3085327296328 3085327296456
l4[0]=2
print(l4,l5,l6)#l5的输出与l6相同
>>> [2, [2, 3]] [[0, 1], [2, 3]] [[0, 1], [2, 3]]
l4[1][0]=4
print(l4,l5,l6)#l5的输出与l6不同
>>> [2, [4, 3]] [[0, 1], [4, 3]] [[0, 1], [2, 3]]
'''
总结一下:deepcopy后的l6若要改变只能直接对l6操作(l4,l6没有关联)
为什么l4[0]=2时l5不跟着变? copy是对子对象的引用,shallow copy中的子list内部
发生改变,则shallow copy 的值也会改变
'''
再看一个例子
>>> import copy as c
>>> l1=[[1,2,[3,4]],5,6] #[1,2,[3,4]]是子list,其内部发生任何改变都会影响l2
>>> l2=c.copy(l1) #但l1[0]=0 对l2无影响
>>> l1[1]=0
>>> l2
[[1, 2, [3, 4]], 5, 6]
>>> l1[0][0]=0
>>> l2
[[0, 2, [3, 4]], 5, 6]
>>> l1[0][2]=0
>>> l2
[[0, 2, 0], 5, 6]结语
如果你坚持看到这,感谢你的认真和支持,祝愿你取得好成绩!