深度学习实战(六):从零开始实现表情识别
深度学习实战(六):从零开始实现表情识别
- 1. 项目简介
- 2. 数据获取
-
- 2.1 数据爬取
- 2.2 数据整理
- 2.3 数据清洗
- 2.4 提取嘴唇区域
- 3. 模型训练
-
- 3.1 数据接口准备
-
- 3.1.1 datasets.ImageFolder
- 3.1.2 Transforms和DataLoader
- 3.2 模型定义
-
- 3.2.2 网络结构定义
- 3.2.3 forward方法
- 3.3 优化方法和优化目标
- 3.4 添加可视化代码
- 3.5 模型训练
- 4. 模型测试

相关资源来自言有三AI(强推)丰富的AI学习资源
1. 项目简介
为了让新手们能够一次性体验一个工业级别的图像分类任务的完整流程,本次我们选择带领大家完成一个对视频中人脸进行表情识别的任务。人脸表情识别(facial expression recognition, FER)作为人脸识别技术中的一个重要组成部分,近年来在人机交互、安全、机器人制造、自动化、医疗、通信和驾驶领域得到了广泛的关注,成为学术界和工业界的研究热点,是人脸属性分析的重点。
本项目有以下几个特点:
- 任务常见且比较基础。本次选择的是一个基于嘴唇来识别4种常见表情的任务,之所以选择嘴唇而不是整个人脸,一方面是因为嘴唇部分效果比较稳定显著,另外一方面是可以让大家使用OpenCV对人脸进行和关键点进行检测,加深数据预处理的理解。
- 流程非常完善。包括从数据的获取,数据的预处理,到模型的定义,模型训练,模型测试,麻雀虽小五脏俱全,对于初学者理解CV任务是非常合适的,这也算是我们平台的金标准任务了,在各个地方都介绍过。
下面就是项目的视频效果展示,可以识别4种表情,包括无表情(neural),嘟嘴(pouting),微笑(smile),张嘴(open)。
2. 数据获取
很多实际项目我们不会有现成的数据集,虽然可以通过开源数据集获取,但是我们还是要学会自己从零开始获取和整理。下面讲述如何准备好本次项目所需要的数据集,包括以下部分。
- 学会使用爬虫爬取图像。
- 对获得的图片数据进行整理,包括重命名,格式统一。
- 利用OpenCV的人脸检测算法删选出有用的样本,利用Dlib关键点检测算法裁剪出用于算法训练的嘴唇区域。
2.1 数据爬取
由于没有直接对应的开源数据集,或者开源数据集中的数据比较少,尤其是对于嘟嘴,张嘴等类的数据,而搜索引擎上有海量数据,所以我们可以从中爬取。下面开始讲述具体的步骤,我们的任务是一个表情分类任务,因此需要爬取相关图片,包括嘟嘴,微笑,大笑等表情。
这里为大家推荐一个爬虫工具。Google,Baidu,Bing三大搜素引擎图片爬虫这个爬虫由ID为sczhengyabin的用户整理。可以按要求爬取百度、Bing、Google上的图片,我已经用了几年了,提供了非常人性化的GUI方便操作,使用python image_downloader_gui.py调用GUI界面,配置好参数(关键词,路径,爬取数目等),关键词可以直接在这里输入也可以选择从txt文件中选择。可以配置需要爬取的样本数目,这里一次爬了2000张,妥妥的3分钟搞定。

我们对百度搜索引擎,自行定义搜索词(比如嘟嘴),爬取图片结果如下:
2.2 数据整理
爬取得到的数据是比较脏的,需要进行整理,主要包括统一图片后缀和重命名。统一后缀格式可以减少以后写数据API时的压力,也可以测试图片是不是可以正常的读取,及时防止未知问题的出现,这很重要。
首先我们看下爬取完毕的数据有多少种数据格式。

总共1364张图,可以看到有jpeg,bmp,png格式,我们首先将其全部转换为jpg格式,这也是所有框架支持的格式,格式转换代码如下:
import os
import sys
import cv2
import numpy as np
def listfiles(rootDir):
list_dirs = os.walk(rootDir)
for root, dirs, files in list_dirs:
for d in dirs:
print os.path.join(root,d)
for f in files:
fileid = f.split('.')[0]
filepath = os.path.join(root,f)
try:
src = cv2.imread(filepath,1)
print "src=",filepath,src.shape
os.remove(filepath) cv2.imwrite(os.path.join(root,fileid+".jpg"),src)
except:
os.remove(filepath)
continue
listfiles(sys.argv[1]) ##输入文件夹即可
统一格式为jpg之后预览如下:

2.3 数据清洗
利用搜索引擎爬取得到的图片肯定有不符合要求的,数据清洗主要是删除不合适的图片,即非人脸的照片。

可以采用肉眼观察的方式,也可以利用程序进行筛选,我们调用opencv的人脸检测算法进行筛选,代码如下:
#coding:utf8
import cv2
import dlib
import numpy as np
import sys
import os
cascade_path='haarcascade_frontalface_default.xml'
cascade = cv2.CascadeClassifier(cascade_path)
images = os.listdir(sys.argv[1])
for image in images:
im=cv2.imread(os.path.join(sys.argv[1],image),1)
rects = cascade.detectMultiScale(im, 1.3,5)
print "detected face",len(rects)
if len(rects) == 0:
cv2.namedWindow('Result',0)
cv2.imshow('Result',im)
os.remove(os.path.join(sys.argv[1],image))
k =cv2.waitKey(0)
if k == ord('q'):
break
这个人脸检测算法是传统算法,召回率不高,因此会有一些好样本被删除。

最后剩下732张样本,可以看到都是比较好的样本了,后面提取人脸关键点也会简单很多。
2.4 提取嘴唇区域
接下来我们要将样本处理成我们真正训练所需要的图像,本任务只对嘴唇部分的表情进行识别,我们利用Opencv+Dlib算法提取嘴唇区域,Dlib算法会得到面部的68个关键点,我们从中得到嘴唇区域,并适当扩大。
import cv2
import dlib
import numpy as np
import sys
import os
PREDICTOR_PATH = "shape_predictor_68_face_landmarks.dat"
predictor = dlib.shape_predictor(PREDICTOR_PATH)
cascade_path='haarcascade_frontalface_default.xml'
cascade = cv2.CascadeClassifier(cascade_path)
def get_landmarks(im):
rects = cascade.detectMultiScale(im, 1.3,5)
x,y,w,h =rects[0]
rect=dlib.rectangle(x,y,x+w,y+h)
return np.matrix([[p.x, p.y] for p in predictor(im, rect).parts()])
def annotate_landmarks(im, landmarks):
im = im.copy()
for idx, point in enumerate(landmarks):
pos = (point[0, 0], point[0, 1])
cv2.putText(im, str(idx), pos,
fontFace=cv2.FONT_HERSHEY_SCRIPT_SIMPLEX,
fontScale=0.4,
color=(0, 0, 255))
cv2.circle(im, pos, 5, color=(0, 255, 255))
return im
def getlipfromimage(im,landmarks):
xmin = 10000
xmax = 0
ymin = 10000
ymax = 0
for i in range(48,67):
x = landmarks[i,0]
y = landmarks[i,1]
if x < xmin:
xmin = x
if x > xmax:
xmax = x
if y < ymin:
ymin = y
if y > ymax:
ymax = y
print "xmin=",xmin
print "xmax=",xmax
print "ymin=",ymin
print "ymax=",ymax
roiwidth = xmax - xmin
roiheight = ymax - ymin
roi = im[ymin:ymax,xmin:xmax,0:3]
if roiwidth > roiheight:
dstlen = 1.5*roiwidth
else:
dstlen = 1.5*roiheight
diff_xlen = dstlen - roiwidth
diff_ylen = dstlen - roiheight
newx = xmin
newy = ymin
imagerows,imagecols,channel = im.shape
if newx >= diff_xlen/2 and newx + roiwidth + diff_xlen/2 < imagecols:
newx = newx - diff_xlen/2;
elif newx < diff_xlen/2:
newx = 0;
else:
newx = imagecols - dstlen;
if newy >= diff_ylen/2 and newy + roiheight + diff_ylen/2 < imagerows:
newy = newy - diff_ylen/2;
elif newy < diff_ylen/2:
newy = 0;
else:
newy = imagecols - dstlen;
roi = im[int(newy):int(newy+dstlen),int(newx):int(newx+dstlen),0:3]
return roi
def listfiles(rootDir):
list_dirs = os.walk(rootDir)
for root, dirs, files in list_dirs:
for d in dirs:
print os.path.join(root,d)
for f in files:
fileid = f.split('.')[0]
filepath = os.path.join(root,f)
try:
im = cv2.imread(filepath,1)
landmarks = get_landmarks(im)
roi = getlipfromimage(im,landmarks)
roipath = filepath.replace('.jpg','_mouth.png')
cv2.imwrite(roipath,roi)
except:
print "error"
continue
listfiles(sys.argv[1])
结果如下,自此就获得了一类数据集。

经过整理后,我们的完整数据集包括4类:

一共15000多张图,包含微笑,嘟嘴,大笑,无表情4类,按照9:1均匀划分为训练集与测试集,各个类别的数据数目如下,格式被统一为128*128大小,jpg类型图像。
- 无表情0none:4763 训练集4287 测试集476
- 嘟嘴1pouting:3154 训练集2839 测试集315
- 微笑2smile:4841 训练集4357 测试集484
- 张嘴3openmouth:2348 训练集2114 测试集234
3. 模型训练
得到了数据之后,接下来咱们使用Pytorch这个框架来进行模型的训练,当然你也可以选择使用其他框架,文末我们会提供13个开源框架的训练代码。
整个训练流程包括数据接口准备、模型定义、结果保存与分析。
3.1 数据接口准备
Pytorch可以使用torchvision的数据集读取接口来进行图像分类任务的读取,使用torchvision的transform接口来进行数据预处理与数据增强,核心代码如下:
import torchvision
from torchvision import datasets, models, transforms
data_dir = './data' ##数据目录
## 创建数据预处理函数,训练预处理包括随机裁剪缩放、随机翻转、归一化,验证预处理包括中心裁剪,归一化
data_transforms = {
'train': transforms.Compose([
transforms.RandomSizedCrop(48),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.5,0.5,0.5], [0.5,0.5,0.5])
]),
'val': transforms.Compose([
transforms.Scale(64),
transforms.CenterCrop(48),
transforms.ToTensor(),
transforms.Normalize([0.5,0.5,0.5], [0.5,0.5,0.5])
]),
}
## 使用torchvision的dataset ImageFolder接口读取数据
image_datasets = {x: datasets.ImageFolder(os.path.join(data_dir, x),
data_transforms[x]) for x in ['train', 'val']}
## 创建数据指针,设置batch大小,shuffle,多进程数量
dataloaders = {x: torch.utils.data.DataLoader(image_datasets[x],
batch_size=16,
shuffle=True,
num_workers=4) for x in ['train', 'val']}
下面对上述代码进行简单讲解。
3.1.1 datasets.ImageFolder
Pytorch的torchvision模块中提供了一个dataset 包,它包含了一些基本的数据集如mnist、coco、imagenet和一个通用的数据加载器ImageFolder,只需要将不同类别的数据放置在不同的目录下,就可以实现加载,对于我们这个任务来说,目录结构如下:
data
├── train
│ ├── 0
│ ├── 1
│ ├── 2
│ └── 3
└── val
├── 0
├── 1
├── 2
└── 3
imagefolder有3个成员变量。
self.classes:用一个list保存类名,就是文件夹的名字。
self.class_to_idx:类名对应的索引,可以理解为 0、1、2、3 等。
self.imgs:保存(imgpath,class),是图片和类别的数组。
3.1.2 Transforms和DataLoader
在transforms中定义了一系列数据集的预处理和增强操作,比如训练预处理包括随机裁剪缩放、随机翻转、归一化,验证预处理包括中心裁剪,归一化。然后使用torch.utils.data.DataLoader创建数据指针。
3.2 模型定义
创建数据接口后,我们在网络脚本文件net.py中定义一个简单的模型simpleconv3。
## 3层卷积神经网络simpleconv3定义
## 包括3个卷积层,3个BN层,3个ReLU激活层,3个全连接层
class simpleconv3(nn.Module):
## 初始化函数
def __init__(self,nclass):
super(simpleconv3,self).__init__()
self.conv1 = nn.Conv2d(3, 12, 3, 2) #输入图片大小为3*48*48,输出特征图大小为12*23*23,卷积核大小为3*3,步长为2
self.bn1 = nn.BatchNorm2d(12)
self.conv2 = nn.Conv2d(12, 24, 3, 2) #输入图片大小为12*23*23,输出特征图大小为24*11*11,卷积核大小为3*3,步长为2
self.bn2 = nn.BatchNorm2d(24)
self.conv3 = nn.Conv2d(24, 48, 3, 2) #输入图片大小为24*11*11,输出特征图大小为48*5*5,卷积核大小为3*3,步长为2
self.bn3 = nn.BatchNorm2d(48)
self.fc1 = nn.Linear(48 * 5 * 5 , 1200) #输入向量长为48*5*5=1200,输出向量长为1200
self.fc2 = nn.Linear(1200 , 128) #输入向量长为1200,输出向量长为128
self.fc3 = nn.Linear(128 , nclass) #输入向量长为128,输出向量长为nclass,等于类别数
## 前向函数
def forward(self, x):
## relu函数,不需要进行实例化,直接进行调用
## conv,fc层需要调用nn.Module进行实例化
x = F.relu(self.bn1(self.conv1(x)))
x = F.relu(self.bn2(self.conv2(x)))
x = F.relu(self.bn3(self.conv3(x)))
x = x.view(-1 , 48 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
上面就是我们定义的网络,是一个简单的3层网络,包括3个卷积层,3个BN层,3个ReLU激活层,3个全连接层,要求输入的图像大小是34848,每一层特征图的大小可以使用print函数来查看。核心代码包括以下几个部分:
### 3.2.1 simpleconv3(nn.Module)继承
继承nn.Module,Pytorch的网络层是包含在nn.Module 里,所以所有的网络定义,都需要继承该网络层,并实现super方法,如下:
super(simpleconv3,self).__init__()
3.2.2 网络结构定义
torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True)
网络定义在nn包中,完整的接口如上,定义的第一个卷积层如下,输入通道为3,输出通道为12,卷积核大小为3,stride=2:
nn.Conv2d(3, 12, 3, 2)
3.2.3 forward方法
backward方法不需要自己实现,但是forward函数是必须要自己实现的,从上面可以看出,forward 函数也是非常简单,串接各个网络层就可以了。Pytorch已经提供了默认初始化,如果我们想实现自己的初始化,可以这么做:
init.xavier_uniform(self.conv1.weight)init.constant(self.conv1.bias, 0.1)
它会对conv1的权重和偏置进行初始化。如果要对所有conv层使用 xavier 初始化呢?可以定义一个函数:
def weights_init(m):
if isinstance(m, nn.Conv2d):
xavier(m.weight.data)
xavier(m.bias.data)
net = Net()
net.apply(weights_init)
3.3 优化方法和优化目标
接下来看优化方法和优化目标的定义
criterion = nn.CrossEntropyLoss()
optimizer_ft = optim.SGD(model.parameters(), lr=0.1, momentum=0.9)
exp_lr_scheduler = lr_scheduler.StepLR(optimizer_ft, step_size=100, gamma=0.1)
可以看出优化目标使用了交叉熵,优化方法使用带动量项的SGD,学习率迭代策略为step,每隔100个epoch,变为原来的0.1倍。
3.4 添加可视化代码
为了方便监控训练过程,我们可以使用TensorboardX进行可视化。Tensorboard的具体使用分三步。
第一步,引入包定义创建变量
from tensorboardX import SummaryWriter
writer = SummaryWriter()
第二步,记录变量,如train阶段的 loss
writer.add_scalar('data/trainloss', epoch_loss, epoch)
第三步,在终端根据提示打开tensorboardX,比如打开日志目录logs下的文件
tensorboard --logdir=logs
然后在浏览器中根据提示打开网页。
3.5 模型训练
接下来看训练的核心代码train.py,如下。
## 训练主函数
def train_model(model, criterion, optimizer, scheduler, num_epochs=25):
for epoch in range(num_epochs):
print('Epoch {}/{}'.format(epoch, num_epochs - 1))
for phase in ['train', 'val']:
if phase == 'train':
scheduler.step()
model.train(True) ## 设置为训练模式
else:
model.train(False) ## 设置为验证模式
running_loss = 0.0 ## 损失变量
running_accs = 0.0 ##精度变量
## 从dataloaders中获得数据
for data in dataloaders[phase]:
inputs, labels = data
if use_gpu:
inputs = inputs.cuda()
labels = labels.cuda()
optimizer.zero_grad() ##清空梯度
outputs = model(inputs) ##前向运行
_, preds = torch.max(outputs.data, 1) ##使用max()函数对输出值进行操作,得到预测值索引
loss = criterion(outputs, labels) ##计算损失
if phase == 'train':
loss.backward() ##误差反向传播
optimizer.step() ##参数更新
running_loss += loss.data.item()
running_accs += torch.sum(preds == labels).item()
## 得到每一个epoch的平均损失与精度
epoch_loss = running_loss / dataset_sizes[phase]
epoch_acc = running_accs / dataset_sizes[phase]
## 收集精度和损失用于可视化
if phase == 'train':
writer.add_scalar('data/trainloss', epoch_loss, epoch)
writer.add_scalar('data/trainacc', epoch_acc, epoch)
else:
writer.add_scalar('data/valloss', epoch_loss, epoch)
writer.add_scalar('data/valacc', epoch_acc, epoch)
print('{} Loss: {:.4f} Acc: {:.4f}'.format(
phase, epoch_loss, epoch_acc))
writer.close()
return model
分析一下上面的代码,外层循环是epoches,然后利用 for data in dataloders[phase] 循环取一个epoch 的数据,送入model。
需要注意的是,每一次forward要将梯度清零,即optimizer.zero_grad(),因为梯度会记录前一次的状态,然后计算loss进行反向传播。
loss.backward()
optimizer.step()
下面可以分别得到精度acc和损失loss,每一次epoch完成计算。
epoch_loss = running_loss / dataset_sizes[phase]
epoch_acc = running_accs / dataset_sizes[phase]
_, preds = torch.max(outputs.data, 1)
loss = criterion(outputs, labels)
在浏览器中进行实时监控,得到如下所示的训练结果图,从而可以判断模型的收敛情况。
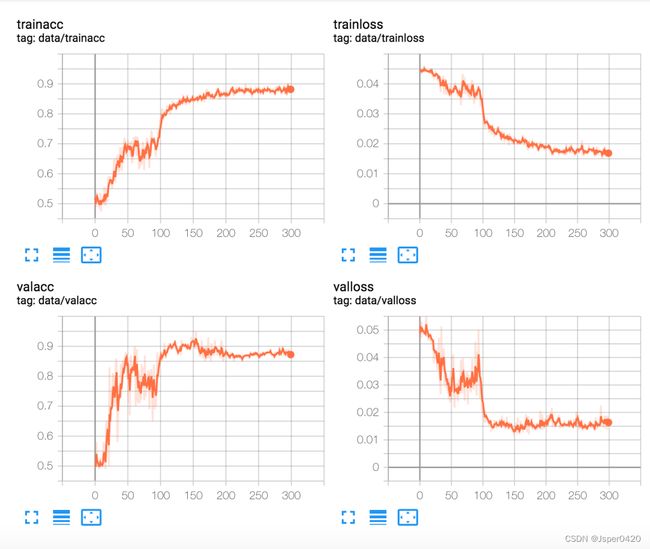
4. 模型测试
上面已经训练好了模型,我们接下来的目标,就是要用它来做推理,真正把模型用起来,下面我们载入一个图片,用模型进行测试。
#coding:utf8
# Copyright 2019 longpeng2008. All Rights Reserved.
# Licensed under the Apache License, Version 2.0 (the "License");
# If you find any problem,please contact us
#
# [email protected]
#
# or create issues
# =============================================================================
import sys
import numpy as np
import cv2
import os
import dlib
import torch
import torch.nn as nn
import torch.optim as optim
from torch.optim import lr_scheduler
from torch.autograd import Variable
import torchvision
from torchvision import datasets, models, transforms
import time
import os
from PIL import Image
import sys
import torch.nn.functional as F
## 全局变量
## sys.argv[1] 权重文件
## sys.argv[2] 图像文件夹
testsize = 48 ##测试图大小
from net import simpleconv3
net = simpleconv3(2) ## 定义模型
net.eval() ## 设置推理模式,使得dropout和batchnorm等网络层在train和val模式间切换
torch.no_grad() ## 停止autograd模块的工作,以起到加速和节省显存
## 载入模型权重
modelpath = sys.argv[1]
net.load_state_dict(torch.load(modelpath,map_location=lambda storage,loc: storage))
## 定义预处理函数
data_transforms = transforms.Compose([
transforms.Resize(48),
transforms.ToTensor(),
transforms.Normalize([0.5,0.5,0.5], [0.5,0.5,0.5])])
## 读取3通道图片,并扩充为4通道tensor
imagepath = sys.argv[2]
image = Image.open(imagepath)
imgblob = data_transforms(image).unsqueeze(0)
## 获得预测结果predict,得到预测的标签值label
predict = net(imgblob)
index = np.argmax(predict.detach().numpy())
## print(predict)
## print(index)
从上面的代码可知,需要做的事情包括:
- 定义网络并使用torch.load和load_state_dict载入模型。
-
使用net.eval()设置推理模式,使得dropout和batchnorm等网络层在train和val模式间切换,使用torch.no_grad()停止autograd模块的工作,以起到加速和节省显存。 - 使用PIL的Image读取图片,它会将图片按照RGB的格式,归一化到 0~1 之间。读取图片之后,必须转化为Tensor变量。
然后就可以自己输入图片得到推理结果,index就是预测的类别。
项目源码:公主号AiCharm 输入“表情识别”
