大数据学习——hadoop分布式计算框架MapReduce之词频获取
MapReduce介绍和优缺点
MapReduce是Hadoop中面向大数据并行处理的计算模型,框架和平台。其具有
1.易于编程(实现接口便可完成程序)
2.平滑无缝的可扩展性(可布置在廉价服务器上,并且只要增加机器数量便可提高MapReduce集群的计算性能)
3.高容错性(MapReduce框架有多种有效的错误检测和恢复机制)
4.高吞吐量(可处理PB级别的数据)
的特点。
但是,MapReduce也具有以下缺点:
1.难以提供实时计算(因其处理的是磁盘上的数据,会受到磁盘读写速度的限制,无法实施返回结果)
2.不能流式计算(其处理的是存储在磁盘上的静态数据,而流式计算的数据是动态的)
3.难以用于DAG计算(DAG——有向无环图计算中,多个任务存在依赖关系,后一个任务的输入可能是前一个任务的输出。因MapReduce的输出结果存于磁盘,使用MapReduce会造成大量的磁盘IO口占用,从而会降低集群的性能)
MapReduce三要素:
1.输入Input
2.Map和Reduce阶段
3.输出Output
—————————————————————————————————————————————
(分界线)
原理
下面介绍如何使用MapReduce词频统计编程实例。
在这个示例中,我们需要获得每个单词出现的次数。
我们首先介绍原理
比如有如下文本:
hello hadoop bigdata
hello hadoop mapreduce
hello hadoop hdfs
bigdata perfect
Map阶段
在运行程序后,会进入map阶段。在map阶段里,程序会并行读取文本,然后对每个单词执行自定义的map函数,形成
程序一行一行的读取文本,
读取第一行:hello hadoop bigdata
读取第二行:hello hadoop mapreduce
读取第三行:hello hadoop hdfs
读取第四行:bigdata perfect
然后形成相应键值对:
第一行:
第二行:
第三行:
第四行:
Reduce阶段
Reduce阶段的操作就是对Map的结果进行排序、合并,最后得到结果。
reduce() 函数循环执行前会经过混排、重组等过程,将上面得到的键值对中相同的key合并,并将其value值重组成数组,执行后结果如下:
然后Ruduce端循环执行Reduce(K,V[]),分别统计每个单词出现的次数,得到如下结果:
以上便是读取词频次数的原理
—————————————————————————————————————————————
以下是实现代码:
在编写代码之前,我们需要配置使用的maven环境。
传送门:运行环境配置
在词频读取的包中我们需要三个java类
分别是
Map类:WCMapper
这个类用于把文本转化成String类,然后把得到的字符串切割成单词。
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/*
KEYIN : 输入的key类型
VALUEIN: 输入的value类型
KEYOUT: 输出的key类型
VALUEOUT: 输出的value类型
*/
public class wcMapper extends Mapper<LongWritable, Text,Text, IntWritable> {
Text k=new Text();
IntWritable v=new IntWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//1.将文本转化成String
String line=value.toString();
//2.将字符串切割 这里的设置是按空格切割
String words[]=line.split("\\s+");
//3.将每一个单词写出去
for (String word : words) {
k.set(word);
context.write(k,v);
}
}
}
Reduce类:wcReduce
接收并处理从Map类获得的单词
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/*
KEYIN:reduce端输入的key类型,即map端输出的key类型
VALUEIN: reduce端输入的value类型,即map端输出的value类型
KEYOUT:reduce端输出的key类型
VALUEOUT: reducer输出的value类型
*/
public class wcReducer extends Reducer<Text, IntWritable,Text,IntWritable> {
int sum;
IntWritable v =new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
//reduce端接收到的类型大概是 (hadoop,(1,1,1))
sum=0;
//遍历迭代器 累加求出出现次数
for (IntWritable count : values) {
//对迭代器进行累加求和
sum+=count.get();
}
//将key和value进行写出
v.set(sum);
context.write(key,v);
}
}
Driver类:wcDriver
配置类,配置驱动,配置文件,运行程序, 其中大部分都是固定的。
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class wcDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//1.创建配置文件
Configuration conf=new Configuration();
Job job=Job.getInstance(conf,"wordcount");//(文件类型,"名称")
//2.设置jar的位置
job.setJarByClass(wcDriver.class);//(Driver类)
//3.设置Map和Reducer的位置
job.setMapperClass(wcMapper.class);//(Map类)
job.setReducerClass(wcReducer.class);//(Reduce类)
//4.设置map输出的key,value类型
job.setMapOutputKeyClass(Text.class);//(map输出的key类型)
job.setMapOutputValueClass(IntWritable.class);//(map输出值的类型)
//5.设置reduce输出的key,value类型
job.setOutputKeyClass(Text.class);//(Reduce输出的key类型)
job.setOutputValueClass(IntWritable.class);//(Reduce输出的value类型)
//6.设置输入输出路径
FileInputFormat.setInputPaths(job,new Path("D:\\A代码\\ad\\data\\wcinput"));// 这个路径的获取在下面介绍
FileOutputFormat.setOutputPath(job,new Path("D:\\A代码\\ad\\data\\wcoutput"));//在工程中我们是没有wcoutput这个文件夹的,但是程序运行之后系统会自动生成,并将结果存放在里面,属于无中生有,大家不用自己建。
//7.提交程序运行 固定
boolean result=job.waitForCompletion(true);
System.exit(result?0:1);
}
}
以下是获取路径及其注意点。把文件放入工程中,然后这里的地址我们获取的是文本文件所在的上一级目录的地址。
注意,是上一级目录,不用文件所在地址。右击选择复制地址即可。
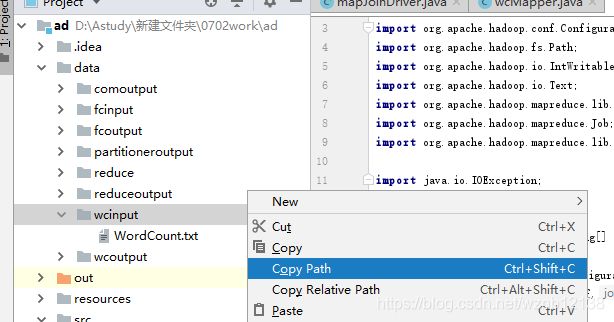
运行程序后,系统便会自动生成wcoutput文件夹,运行结果在里面可以看到。
这里使用的是之前的运行结果,将就着看大概是这么个意思。
