Oracle 正则表达式详解(regexp_substr、regexp_instr、regexp_replace、regexp_like)
文章目录
- 1 概述
- 2 匹配规则
- 3 正则函数
-
- 3.1 regexp_substr()
- 3.2 regexp_instr()
- 3.3 regexp_replace()
- 3.4 regexp_like()
1 概述
1. 作用:处理字符时,很强大
2. 分类:与下列相似,但功能更加强大('支持正则表达式')
(1) regexp_like : 同 like 功能相似(模糊 '匹配')
(2) regexp_instr : 同 instr 功能相似(返回字符所在 '下标')
(3) regexp_substr : 同 substr 功能相似('截取' 字符串)
(4) regexp_replace: 同 replace 功能相似( '替换' 字符串)
-- 使用了 '正则表达式' 替代了老的 '百分比 %' 和 '通配符 _'
-- 上述 四个 函数,正则用法相似,知晓一个,其它皆可参考
2 匹配规则
主要的类型如下:
| 分组 | 元字符 | 描述 |
|---|---|---|
| 特殊的 | \ | 转义字符。“\n”:换行,"\\n":文本 ‘\n’ |
| . | 匹配除转义字符外的 任何单字符 | |
| 定位元字符 | ^ | 使表达式定位至一行的 开头 |
| $ | 使表达式定位至一行的 末尾 | |
| 量词或重复操作符 | * | 匹配 0 次或多次(任意次数) |
| ? | 匹配 0 次或 1 次(最多 1 次) | |
| + | 匹配 1 次或多次(至少 1 次) | |
| {m} | 正好 匹配 m 次 | |
| {m, } | 至少 匹配 m 次 | |
| {m, n} | 匹配 m 到 n 次 | |
| 表达式的替换和分组 | | | 替换,通常和分组操作符 () 一起使用 |
| () | 分组,并且 的关系 | |
| [char] | 字符列表,或者 的关系 | |
| 预定义的 posix 字符类 | [:alpah:] | 任何字母 |
| [:lower:] | 任何小写字母 | |
| [:upper:] | 任何大写字母 | |
| [:digit:] | 任何数字,相当于 [0-9] | |
| [:xdigit:] | 任何 16 进制的数字,相当于 [0-9a-fA-F] | |
| [:alnum:] | 任何字符或数字字符 | |
| [:space:] | 空白字符,如:回车符,换行符、竖直制表符和换页符 | |
| [:punct:] | 任何标点符号 |
示例:此案例来源于网络,略作修改,挺适合参考的
1. 查询 value 中以 1 开头 60 结尾的记录并且长度是 7 位
select * from table_name where value like '1____60'; -- 4 个 _
select * from table_name where regexp_like(value, '1....60');
2. 查询 value 中以 1 开头 60 结尾的记录并且长度是 7 位且全部是数字的记录
此时,用 like 就不是很好实现了
select * from table_name where regexp_like(value, '^1[0-9]{4}60$');
select * from table_name where regexp_like(value, '^1[[:digit:]]{4}60$');
3. 查询 value 中不包含任何数字的记录
select * from table_name where regexp_like(value, '^[^[:digit:]]+$'); -- [] 内的 ^ 表示 '非'
4. 查询 value 中不是纯数字的记录
select * from table_name where not regexp_like(value, '^[[:digit:]]+$');
5. 查询以 12 或 1b 开头的记录,区分大小写
select * from table_name where regexp_like(value, '^(12)|^(1b)');
select * from table_name where regexp_like(value, '^1[2b]');
6. 查询以 12 或 1b 开头的记录,不区分大小写
select * from table_name where regexp_like(value, '^1[2b]', 'i');
7. 查询所有均为 小写字母 或 数字的记录
select * from table_name where regexp_like(value, '^([a-z]+|[0-9]+)$');
8. 查询包含 空白 的记录
select * from table_name where regexp_like(value, '[[:space:]]');
9. 查询包含 标点符号 的记录
select * from table_name where regexp_like(value, '[[:punct:]]');
3 正则函数
- 扩展:Oracle 官方文档 - regexp_substr
3.1 regexp_substr()
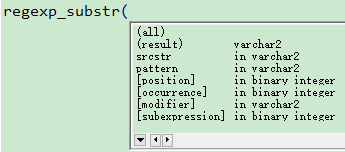
参数解释:
srcstr : 源字符串 -- source string
pattern : 正则表达式
position : 起始位置,默认 1
occurrence : 第几次出现,默认 1(匹配成功的次数,依次递增)
modifier : 模式('i': 不区分大小写,'c': 区分大小写。 默认 'c')
subexpression: 含有子表达式 0-9, 默认 0:不含子表达式,1:第一个子表达式,以此类推
例1:
select regexp_substr('abc,CBA121ABC,cba', ',[^,]+,') rs1, -- ,CBA121ABC,
regexp_substr('1234567890', '(123)(4(56)(78))', 1, 1, 'i', 1) rs2 -- 123
from dual;
例2:拆分邮箱
with temp_email as (
select 1 user_no, '[email protected]' email from dual union all
select 2 user_no, '[email protected]' email from dual union all
select 3 user_no, '[email protected]' email from dual
)
select t.user_no 用户编号,
regexp_substr(t.email,'[[:alnum:]]+') 用户名,
regexp_substr(t.email, '\@[[:alnum:]]+\.[[:alnum:]]+') 邮箱后缀
-- 两者等同
-- regexp_substr(t.email,'[a-zA-Z0-9]+') 用户名2,
-- regexp_substr(t.email, '\@[a-zA-Z0-9]+\.[a-zA-Z0-9]+') 邮箱后缀2
from temp_email t;
测试结果:
用户编号 用户名 邮箱后缀
1 a1 @qq.com
2 bb2 @sina.com
3 ccc3 @aliyun.com
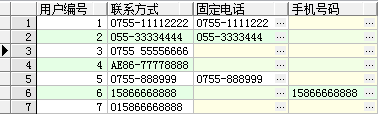
例3:匹配固定电话号码和手机号码
--*************************************************************
-- 固定电话格式:0开头 + 2到3位任意数字 + '-' + 6到7位任意数字
-- 手机号码格式:1开头 + 10位任意数字(11位)
--*************************************************************
with temp_phone as (
select 1 user_no, '0755-11112222' phone_no from dual union all
select 2 user_no, '055-33334444' phone_no from dual union all
select 3 user_no, '0755 55556666' phone_no from dual union all
select 4 user_no, 'AE86-77778888' phone_no from dual union all
select 5 user_no, '0755-888999' phone_no from dual union all
select 6 user_no, '15866668888' phone_no from dual union all
select 7 user_no, '015866668888' phone_no from dual
)
select t.user_no 用户编号,
t.phone_no 联系方式,
regexp_substr(t.phone_no,'^0[0-9]{2,3}-[0-9]{6,7}') 固定电话,
regexp_substr(t.phone_no,'^1[0-9]{10}') 手机号码
from temp_phone t;
测试结果:
3.2 regexp_instr()

参数解释:
srcstr : 源字符串 -- source string
pattern : 正则表达式
position : 起始位置,默认 1
occurrence : 第几次出现,默认 1(匹配成功的次数,依次递增)
returnparam : 返回参数对应的下标(0:第一个位置的下标,非0:最后一个位置的下标)
modifier : 模式('i': 不区分大小写,'c': 区分大小写。 默认 'c')
subexpression: 含有子表达式 0-9, 默认 0:不含子表达式,1:第一个子表达式,以此类推
示例:
select regexp_instr('1,23,456,7890', '[0-9]+', 1, 3) 匹配到的第一个字符下标, -- 6
regexp_instr('1,23,456,7890', '[0-9]+', 1, 3, 1) 最后一个字符后一位的下标, -- 9
regexp_instr('1234567890', '(123)(4)(56)(78)', 1, 1, 0, 'i', 4) 匹配到的第四个子表达式 -- 7
from dual;
查询结果:
匹配到的第一个字符下标 最后一个字符后一位的下标 匹配到的第四个子表达式
6 9 7
3.3 regexp_replace()

示例:
with temp_strings as (
select 'abc123' str from dual union all
select '123abc' str from dual union all
select 'a1b2c3' str from dual
)
select t.str 源字符串,
regexp_replace(t.str, '[0-9]', '', 1) 无数字字符串
from temp_strings t;
查询结果:
源字符串 无数字字符串
1 abc123 abc
2 123abc abc
3 a1b2c3 abc
3.4 regexp_like()

示例:
with temp_strings as (
select 'abc123' str from dual union all
select '12abcd' str from dual union all
select 'a1b2c3' str from dual
)
select t.str 连续的三个数字字符
from temp_strings t
where regexp_like(t.str, '[0-9]{3}');
查询结果:
连续的三个数字字符
abc123