pytorch mmrotate训练自定义数据集xml转txt
摘要
mmrotate是旋转目标检测框架,效果如下图所示,主要讲解如果xml文件标注信息转成dota格式用txt存储标注信息,以及如何实现顺时针逆时针矩形框旋转。
数据处理
首先学会矩形框旋转运算,主要是利用sin和cos进行计算旋转后的x,y坐标点信息
逆时针公式
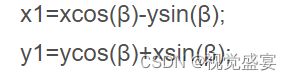
顺时针公式

具体代码案例
import math
x=1
y=1
angle=90
x1=x*math.cos(math.radians(angle))-y*math.sin(math.radians(angle));
y1=y*math.cos(math.radians(angle))+x*math.sin(math.radians(angle));
print((x1,y1))
逆时针旋转90度刚好为(-1,1),顺时针换个公式就可以实现了。

自定义数据转dota格式
数据分为二个部分,一部分xml文件,另一部分图像
修改路径就可以使用了,我这里是逆时针代标注的代码,如果顺时针需要修改一下
import os
import xml.etree.ElementTree as ET
import math
import cv2 as cv
all_name=[]
change=['light truck','heavy truck']
change_dict={'light truck':'light-truck','heavy truck':'heavy-truck'}
def voc_to_dota(xml_path, xml_name):
txt_name = xml_name[:-4] + '.txt'
txt_path = xml_path + '/txt_label'
if not os.path.exists(txt_path):
os.makedirs(txt_path)
txt_file = os.path.join(txt_path, txt_name)
file_path = os.path.join(xml_path, file_list[i])
tree = ET.parse(os.path.join(file_path))
root = tree.getroot()
# print(root[6][0].text)
image_path = 'D:/racedata\detrota/2_Aligned_RGB_infrared\data/train\image-H/'
out_path = 'D:/racedata\detrota/2_Aligned_RGB_infrared/data/show/'
filename = image_path + xml_name[:-4] + '.png'
img = cv.imread(filename)
print(filename)
with open('D:/racedata\detrota/2_Aligned_RGB_infrared\data/train/anno-H-txt-new/'+txt_name, "w+", encoding='UTF-8') as out_file:
for obj in root.findall('object'):
name = obj.find('name').text
if name not in all_name:
all_name.append(name)
if name in change:
name=change_dict[name]
difficult = obj.find('difficult').text
# print(name, difficult)
robndbox = obj.find('rbox')
cx = float(robndbox.find('cx').text)
cy = float(robndbox.find('cy').text)
w = float(robndbox.find('w').text)
h = float(robndbox.find('h').text)
angle = float(robndbox.find('angle').text)
#angle=angle+90
#angle = 180-angle
# print(cx, cy, w, h, angle)
p0x, p0y = rotatePoint(cx, cy, cx - w / 2, cy - h / 2, -angle)
p1x, p1y = rotatePoint(cx, cy, cx + w / 2, cy - h / 2, -angle)
p2x, p2y = rotatePoint(cx, cy, cx + w / 2, cy + h / 2, -angle)
p3x, p3y = rotatePoint(cx, cy, cx - w / 2, cy + h / 2, -angle)
# 找最左上角的点
dict = {p0y:p0x, p1y:p1x, p2y:p2x, p3y:p3x }
list = find_topLeftPopint(dict)
#print((list))
if list[0] == p0x:
list_xy = [p0x, p0y, p1x, p1y, p2x, p2y, p3x, p3y]
elif list[0] == p1x:
list_xy = [p1x, p1y, p2x, p2y, p3x, p3y, p0x, p0y]
elif list[0] == p2x:
list_xy = [p2x, p2y, p3x, p3y, p0x, p0y, p1x, p1y]
else:
list_xy = [p3x, p3y, p0x, p0y, p1x, p1y, p2x, p2y]
# 在原图上画矩形 看是否转换正确
cv.line(img, (int(list_xy[0]), int(list_xy[1])), (int(list_xy[2]), int(list_xy[3])), color=(255, 0, 0), thickness= 3)
cv.line(img, (int(list_xy[2]), int(list_xy[3])), (int(list_xy[4]), int(list_xy[5])), color=(0, 255, 0), thickness= 3)
cv.line(img, (int(list_xy[4]), int(list_xy[5])), (int(list_xy[6]), int(list_xy[7])), color=(0, 0, 255), thickness= 2)
cv.line(img, (int(list_xy[6]), int(list_xy[7])), (int(list_xy[0]), int(list_xy[1])), color=(255, 255, 0), thickness= 2)
#data= str(str(cx)+" "+str(cy)+' '+str(w)+' '+str(h)+' '+str(angle))
data = str(list_xy[0]) + " " + str(list_xy[1]) + " " + str(list_xy[2]) + " " + str(list_xy[3]) + " " + \
str(list_xy[4]) + " " + str(list_xy[5]) + " " + str(list_xy[6]) + " " + str(list_xy[7]) + " "
data = data + name + " " + difficult + "\n"
out_file.write(data)
#cv.imwrite(out_path + xml_name[:-4] + '.png', img)
def find_topLeftPopint(dict):
dict_keys = sorted(dict.keys()) # y值
temp = [dict[dict_keys[0]], dict[dict_keys[1]]]
minx = min(temp)
if minx == temp[0]:
miny = dict_keys[0]
else:
miny = dict_keys[1]
return [minx, miny]
# 转换成四点坐标
def rotatePoint(xc, yc, xp, yp, theta):
xoff = xp - xc
yoff = yp - yc
cosTheta = math.cos(math.radians(theta))
sinTheta = math.sin(math.radians(theta))
pResx = cosTheta * xoff - sinTheta * yoff
pResy = sinTheta * xoff + cosTheta * yoff
# pRes = (xc + pResx, yc + pResy)
# 保留一位小数点
return float(format(xc + pResx, '.1f')), float(format(yc + pResy, '.1f'))
if __name__ == '__main__':
root_path = 'D:/racedata\detrota/2_Aligned_RGB_infrared/anno-H'
file_list = os.listdir(root_path)
for i in range(0, len(file_list)):
if ('.xml' in file_list[i]) or ('.XML' in file_list[i]):
voc_to_dota(root_path, file_list[i])
print('----------------------------------------{}{}----------------------------------------'
.format(file_list[i], ' has Done!'))
else:
print(file_list[i] + ' is not xml file')
print(all_name)
训练
训练配置文件修改,一个是你的类别数目和数据的位置,和数据类别
dataset_type = 'DOTADataset'
img_norm_cfg = dict(
mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
init_cls = ['car','bus', 'light-truck', 'heavy-truck']
data = dict(
samples_per_gpu=8,
workers_per_gpu=8,
train=dict(
type='DOTADataset',
ann_file='data2/anno-H-txt-new/',
classes=['car','bus', 'light-truck', 'heavy-truck'],
img_prefix='data2/train/image-H/',
pipeline=[
dict(type='LoadImageFromFile'),
dict(type='LoadAnnotations', with_bbox=True),
dict(type='RResize', img_scale=(640, 640)),
dict(
type='RRandomFlip',
flip_ratio=[0.25, 0.25, 0.25],
direction=['horizontal', 'vertical', 'diagonal'],
version='oc'),
dict(
type='Normalize',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
to_rgb=True),
dict(type='Pad', size_divisor=32),
dict(type='DefaultFormatBundle'),
dict(type='Collect', keys=['img', 'gt_bboxes', 'gt_labels'])
],
version='oc'),
val=dict(
type='DOTADataset',
ann_file='data2/anno-H-txt-new/',
classes=['car','bus', 'light-truck', 'heavy-truck'],
img_prefix='data2/train/image-H/',
pipeline=[
dict(type='LoadImageFromFile'),
dict(
type='MultiScaleFlipAug',
img_scale=(640, 640),
flip=False,
transforms=[
dict(type='RResize'),
dict(
type='Normalize',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
to_rgb=True),
dict(type='Pad', size_divisor=32),
dict(type='DefaultFormatBundle'),
dict(type='Collect', keys=['img'])
])
],
version='oc'),
test=dict(
type='DOTADataset',
ann_file='data2/anno-H-txt-new/',
classes=['car','bus', 'light-truck', 'heavy-truck'],
img_prefix='data2/train/image-H/',
pipeline=[
dict(type='LoadImageFromFile'),
dict(
type='MultiScaleFlipAug',
img_scale=(640, 640),
flip=False,
transforms=[
dict(type='RResize'),
dict(
type='Normalize',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
to_rgb=True),
dict(type='Pad', size_divisor=32),
dict(type='DefaultFormatBundle'),
dict(type='Collect', keys=['img'])
])
],
version='oc'))
evaluation = dict(interval=12, metric='mAP')
optimizer = dict(
#_delete_=True,
type='AdamW',
lr=0.0001,
betas=(0.9, 0.999),
weight_decay=0.05,
paramwise_cfg=dict(
custom_keys={
'absolute_pos_embed': dict(decay_mult=0.),
'relative_position_bias_table': dict(decay_mult=0.),
'norm': dict(decay_mult=0.)
}))
optimizer_config = dict(grad_clip=dict(max_norm=35, norm_type=2))
lr_config = dict(
policy='step',
warmup='linear',
warmup_iters=500,
warmup_ratio=0.3333333333333333,
step=[15, 19])
runner = dict(type='EpochBasedRunner', max_epochs=24)
checkpoint_config = dict(interval=12)
log_config = dict(interval=50, hooks=[dict(type='TextLoggerHook')])
dist_params = dict(backend='nccl')
log_level = 'INFO'
load_from = None
#load_from = '/home/a1804/cp/mmrotate/weights/rotated_retinanet_obb_r50_fpn_fp16_1x_dota_le90-01de71b5.pth'
resume_from = None
workflow = [('train', 1)]
opencv_num_threads = 0
mp_start_method = 'fork'
angle_version = 'oc'
custom_imports = dict(imports=['mmcls.models'], allow_failed_imports=False)
checkpoint_file = 'https://download.openmmlab.com/mmclassification/v0/convnext/downstream/convnext-tiny_3rdparty_32xb128-noema_in1k_20220301-795e9634.pth'
model = dict(
type='RotatedRetinaNet',
backbone=dict(
#_delete_=True,
type='mmcls.ConvNeXt',
arch='tiny',
out_indices=[0, 1, 2, 3],
drop_path_rate=0.4,
layer_scale_init_value=1.0,
gap_before_final_norm=False,
init_cfg=dict(
type='Pretrained', checkpoint=checkpoint_file,
prefix='backbone.')),
neck=dict(
type='FPN',
in_channels=[96, 192, 384, 768],
out_channels=256,
start_level=1,
add_extra_convs='on_input',
num_outs=5),
bbox_head=dict(
type='RotatedRetinaHead',
num_classes=4,
in_channels=256,
stacked_convs=4,
feat_channels=256,
assign_by_circumhbbox=None,
anchor_generator=dict(
type='RotatedAnchorGenerator',
octave_base_scale=4,
scales_per_octave=3,
ratios=[1.0, 0.5, 2.0],
strides=[8, 16, 32, 64, 128]),
bbox_coder=dict(
type='DeltaXYWHAOBBoxCoder',
angle_range='oc',
norm_factor=None,
edge_swap=False,
proj_xy=False,
target_means=(0.0, 0.0, 0.0, 0.0, 0.0),
target_stds=(1.0, 1.0, 1.0, 1.0, 1.0)),
loss_cls=dict(
type='FocalLoss',
use_sigmoid=True,
gamma=2.0,
alpha=0.25,
loss_weight=1.0),
loss_bbox=dict(type='L1Loss', loss_weight=1.0)),
train_cfg=dict(
assigner=dict(
type='MaxIoUAssigner',
pos_iou_thr=0.5,
neg_iou_thr=0.4,
min_pos_iou=0,
ignore_iof_thr=-1,
iou_calculator=dict(type='RBboxOverlaps2D')),
allowed_border=-1,
pos_weight=-1,
debug=False),
test_cfg=dict(
nms_pre=2000,
min_bbox_size=0,
score_thr=0.05,
nms=dict(iou_thr=0.1),
max_per_img=2000))
work_dir = './new_dirs/baseline-convtiny'
auto_resume = False
gpu_ids = range(0, 1)
可视化
单张可视化
from argparse import ArgumentParser
from mmdet.apis import inference_detector, init_detector, show_result_pyplot
import mmrotate # noqa: F401
config = 'new_dirs/baseline-convtiny/test.py'
checkpoint = 'new_dirs/baseline-convtiny/epoch_24.pth'
model = init_detector(config, checkpoint, device='cpu')
img='/home/a1804/cp/mmrotate/data2/val/Infrared/DJI_2022090101_0096.png'
result = inference_detector(model, img)
print(result)
print("++++++++++++++++++++")
print(result[0][:][4])
show_result_pyplot(
model,
img,
result,
score_thr=0.3,
out_file='showdir/1.png'
)
根据推理生成的json进行全部可视化预测
import cv2
import matplotlib.pyplot as plt
import numpy as np
import math
import json
def rotatePoint(xc, yc, xp, yp, theta):
xoff = xp - xc
yoff = yp - yc
cosTheta = math.cos(math.radians(theta))
sinTheta = math.sin(math.radians(theta))
pResx = cosTheta * xoff - sinTheta * yoff
pResy = sinTheta * xoff + cosTheta * yoff
# pRes = (xc + pResx, yc + pResy)
# 保留一位小数点
return float(format(xc + pResx, '.1f')), float(format(yc + pResy, '.1f'))
with open('result.json','r') as f:
data=json.load(f)
for img_data in data:
reline=img_data['result']
name=img_data['img_filename']
if name[0]=="I":
name=name[8:-4]+'.png'
else:
continue
print(name)
img=cv2.imread('data2/val/Infrared/'+name)
all_data=[]
for line in reline:
cx,cy,w,h,angle=int(line['rbox'][0]),int(line['rbox'][1]),int(line['rbox'][2]),int(line['rbox'][3]),float(line['rbox'][4])
x1 = int(cx - w / 2)
y1 = int(cy - h / 2)
x2 = int(cx + w / 2)
y2 = int(cy + h / 2)
# img = cv2.rectangle(img, (x1, y1), (x2, y2), (255, 0, 0), 2)
# img = cv2.putText(img, str(int(angle)), (x1, y1), cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 0, 0), 2)
p0x, p0y = rotatePoint(cx, cy, cx - w / 2, cy - h / 2, -angle)
p1x, p1y = rotatePoint(cx, cy, cx + w / 2, cy - h / 2, -angle)
p2x, p2y = rotatePoint(cx, cy, cx + w / 2, cy + h / 2, -angle)
p3x, p3y = rotatePoint(cx, cy, cx - w / 2, cy + h / 2, -angle)
all_data.append(np.array([[int(p0x), int(p0y)], [int(p1x), int(p1y)], [int(p2x), int(p2y)], [int(p3x), int(p3y)]]))
cv2.polylines(img, all_data, True, (0, 0, 255), 2)
cv2.imwrite('showdir/' +name, img)
推理代码
这是一个比赛的提交格式,mmrotate预测生成的坐标信息是cx cy w h 弧度制预测 score,我们需要将弧度制预测*180/pi 算出具体的弧度就可以了。
from argparse import ArgumentParser
import json
from mmdet.apis import inference_detector, init_detector, show_result_pyplot
import math
import mmrotate # noqa: F401
import os
config = 'new_dirs/baseline-convtiny/test.py'
checkpoint = 'new_dirs/baseline-convtiny/epoch_24.pth'
model = init_detector(config, checkpoint, device='cuda:2')
allimg=os.listdir('data2/val/Infrared/')
root='data2/val/Infrared/'
result_json=[]
#change_cate={0:0,1:2,2:3,3:2}
def make_json(result,img):
le=len(result)
temp_all={"img_filename":'0',"result":[]}
temp_all2={"img_filename":'0',"result":[]}
temp_all['img_filename']='RGB/'+img+'.jpg'
temp_all2['img_filename']='Infrared/'+img+'.jpg'
for i in range(le):
for j in range(len(result[i])):
temp_box={"category_id": 0,"rbox": [0,0,0,0,0],"score": 0}
x,y,width,height,angle,score=result[i][j]
if score<0.3:
continue
angle=angle*180/math.pi
temp_box['category_id']=int(i)
temp_box['rbox']=[float(x),float(y),float(width),float(height),360-float(angle)]
temp_box['score']=float(score)
temp_all['result'].append(temp_box)
temp_all2['result'].append(temp_box)
result_json.append(temp_all)
result_json.append(temp_all2)
for img in allimg:
print(img)
path_img=root+img
result = inference_detector(model,path_img)
make_json(result,img[:-4])
with open("./result.json", 'w') as f:
json.dump(result_json, f, indent=4)