selenium使用大全
-
selenium使用
使用selenium有一个硬性条件,1;使用Google浏览器 2:下载chromedrive.exe工具。
驱动的下载地址如下:
http://chromedriver.storage.googleapis.com/index.html
查看浏览器的版本:浏览器右上角三个点: > 帮助 > 关于Google chrome -- 89.0.4389.90 根据这个数字去找对应的版本工具 -- 找到之后点进去: linux, mac win -- 89.0.4389.90 不一定完全一模一样,,, 选择最接近的上一个或者下一个... -- chromedriver.zip 压缩包 解压缩 > chromedriver.exe -- 把这个chromedriver.exe复制到跟你的解释器同一目录之下 -- cmd 中 where python -- chromedriver.exe 跟 python.exe(指定执行pycharm这个python解释器) 放在一起 selenium: 是一个第三方库 python安装命令 :pip install selenium -i https://pypi.douban.com/simple
实际上去依赖这个跟python解释器放在一起的chromedriver.exe打开的谷歌浏览器... 1.因为放在一起,,所以可以直接调用.. 2.如果没有放在一起,,就需要在创建浏览器对象的时候,手动指定,,指定使用chromedriver.exe驱动打开
# 导包
from selenium.webdriver import Chrome
if __name__ == '__main__':
# 1.创建对象. 大写的C
chrome_obj = Chrome() # 运行会自动打开谷歌浏览器,上面会有提示,Chrome正受到自动化测试工具的控制
# 手动指定浏览器驱动
# chrome_obj = Chrome(executable_path='驱动文件的绝对路径/chromedriver.exe') # 运行会自动打开谷歌浏览器,上面会有提示,Chrome正受到自动化测试工具的控制
# 进行请求的发送,向网页地址栏填入url参数
chrome_obj.get('https://www.baidu.com') # 往浏览器的网页地址栏填入url参数
# 重要:获取当前页面的数据 >>> 是网页源代码 elements 使用selenium做的(json html)
# data_ = chrome_obj.page_source
#
# print(data_)
# with open('baidu01.html','w',encoding='utf-8') as f:
# f.write(data_)
import time
from selenium.webdriver import Chrome
if __name__ == '__main__':
# 1.创建浏览器对象
chrome_obj = Chrome()
# 2.发送一个请求
chrome_obj.get('https://www.baidu.com')
# 1 浏览器最大化
chrome_obj.maximize_window()
# 2.网页的截图 使用selenium建议图片保存格式.png
chrome_obj.save_screenshot('baidu02.png') # 图片的名称
time.sleep(1.5)
# 3打开一下新的页面:在原来的窗口重新输入一个url
chrome_obj.get('https://www.bilibili.com/')
#
time.sleep(1.5)
# 4 回退操作
chrome_obj.back()
#
time.sleep(1.5)
# 5 前进操作
chrome_obj.forward()
# 6 打开一个新的窗口: selenium执行js代码
time.sleep(1.5)
chrome_obj.execute_script('window.open("https://www.baidu.com")')
# 7 切换窗口
# 1.获取窗口: 获取到一个列表,当前浏览器对象打开了几个窗口,, 列表里面就有多少个元素
res_ = chrome_obj.window_handles
# print(res_)
# 进行窗口的切换
time.sleep(1.5)
chrome_obj.switch_to_window(res_[0]) # 切换到第一个窗口
time.sleep(1.5)
chrome_obj.switch_to_window(res_[1]) # 切换到第二个窗口
# 3.selenium关闭浏览器
# (1)关闭当前的页面窗口
time.sleep(1.5)
chrome_obj.close()
#
# # (2)关闭整个浏览器对象
time.sleep(1.5)
chrome_obj.quit()
selenium:依赖网络,类似刚才的打开图形化界面的操作,,渲染网页,,, 都是会打开我们看得见的浏览器,,,图形化界面.... 不去打开我们看得见的浏览器, 图形化界面的操作 >>> 无界面模式,,无头模式
if __name__ == '__main__':
# 创建无界面模式对象
options_ = Options()
# 1.第一种设置无界面模式的方式
options_.add_argument('--headless') # 添加无界面参数
# 2.第二种设置无界面模式的方式
options_.headless = True
# 3.第三种置无界面模式的方式
options_.set_headless()
# 1.创建浏览器对象: 添加参数,,不让浏览器打开,,,,
chrome_obj = Chrome(options=options_)
# 2.发送一个请求
chrome_obj.get('https://www.baidu.com')
print(chrome_obj.page_source)
优点: 较为迅速,可以省去一眼眼花的浏览器操作
缺点: 效果没有那么的直观
代码的编写,,调试的时候,,使用有界面模式...
整体下来没有问题之后,,,就可以设置成无界面模式去进行一个运行.
-
selenium反检测
"""
反检测的演示:
具体的网站还是要根据具体的实现
"""
from selenium.webdriver import Chrome
# 导入反检测使用的
from selenium.webdriver import ChromeOptions
if __name__ == '__main__':
# 创建选项对象
options_ = ChromeOptions()
# 添加参数,进行隐藏
options_.add_experimental_option('excludeSwitches', ["enable-automation"]) # 不需要死记硬背
chrome_obj = Chrome(options=options_)
chrome_obj.get('https://www.baidu.com')
chrome_obj.quit()-
selenium页面滚动
selenium控制页面的滚动
1.可以执行像素单位进行移动
window.scrollTo(0,2000)
(横向x轴,竖向y轴)
2.可以以页面为单位进行移动(直接到达底部)
window.scrollTo(0,document.body.scrollHeight)
3.指定到达的坐标
document.documentElement.scrollTop=2000
到达指定的坐标单位
import time
from selenium.webdriver import Chrome
if __name__ == '__main__':
# 1.创建浏览器对象
chrome_obj = Chrome()
# 打开页面
chrome_obj.get('https://www.baidu.com/s?wd=%E5%86%AC%E5%A5%A5%E7%9B%9B%E4%BC%9A%E5%B0%86%E9%95%BF%E4%B9%85%E7%95%99%E4%B8%8B%E4%BB%80%E4%B9%88%EF%BC%9F&sa=fyb_n_homepage&rsv_dl=fyb_n_homepage&from=super&cl=3&tn=baidutop10&fr=top1000&rsv_idx=2&hisfilter=1')
time.sleep(1)
# chrome_obj.execute_script('window.scrollTo(0,200)')
# chrome_obj.execute_script('window.scrollTo(0,document.body.scrollHeight)')
chrome_obj.execute_script('document.documentElement.scrollTop=1000')
time.sleep(1.5)
chrome_obj.quit()-
selenium元素定位
"""
1.进入百度首页
2.找到搜索框,定位搜索框的方式
3.往搜索框对象填写关键字数据
4.点击百度一下
-- 先定位到百度一下这个节点部分
"""
import time
"""
元素定位:
单个节点定位: 直接直接右键检查之后,,找到对应的节点,,,
网页源代码elements当中,,在elements里面,,直接copy该节点的的xpath,,copy xpath
"""
from selenium.webdriver import Chrome
if __name__ == '__main__':
# 创建浏览器对象
chrome_obj = Chrome()
# 进入百度首页
chrome_obj.get('https://www.baidu.com')
time.sleep(0.5)
# 定位到搜索框对象
input_obj = chrome_obj.find_element_by_xpath('//*[@id="kw"]')
input_obj.send_keys('靓仔') # 发送关键字数据
time.sleep(0.5)
# 定位到百度一下的节点部分
click_obj = chrome_obj.find_element_by_xpath('//*[@id="su"]')
# 触发点击
click_obj.click()-
iframe窗口介绍
有时候使用selenium点击出现错误可能是因为有iframe窗口
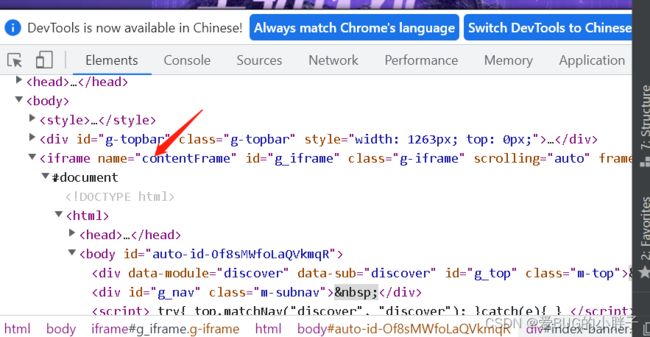
"""
iframe窗口的介绍
iframe:页面中的页面,网页中的网页
查看:
1.右键检查进入elements:
网上找节点:看看是否顶级节点,, 是不是iframe frame
2.elements中搜索frame,,找到iframe frame 节点
鼠标放上去
"""
import time
"""
1.进入网易云的首页
2.定位到短视频变装神曲
3.点击进入详情页
"""
from selenium.webdriver import Chrome
if __name__ == '__main__':
# 1.创建浏览器对象
chrome_obj = Chrome()
# 2.进入网易云首页
chrome_obj.get('https://music.163.com/')
time.sleep(1)
# 此时此刻,网页最外层页面,切换到iframe页面
chrome_obj.switch_to_frame('contentFrame') # 以iframe节点的name属性的值作为定位的参数
# 此时此刻 切换到iframe页
time.sleep(0.5)
# 3.节点元素的定位 //*[@id="discover-module"]/div[1]/div/div/div[1]/ul/li[1]/div/a
click_obj = chrome_obj.find_element_by_xpath('//*[@id="discover-module"]/div[1]/div/div/div[1]/ul/li[1]/div/a')
# 4.进行点击进入详情页
click_obj.click()
click_obj_1 = chrome_obj.find_element_by_xpath('//*[@id="content-operation"]/a[1]').click()
以上是selenium的基本使用方法。