python简单线性回归---鸢尾花
线性回归: 是回归分析中的一种,评估自变量x与因变量y之间是一种线性关系
简单的线性回归:一元线性回归 y = a X +b
目的找出a,b的值,即可建立一个简单的线性回归模型,从而进行趋势预测
对数据进行简单的线性回归分析:
1:获取数据集
2:指定特征值x 目标值y(如 特征值:屁股为红色,目标值为猴子)
3:数据集划分(训练集+测试集)
4:模型建立
5:模型评估
from sklearn.linear_model import LinearRegression # 导入线性回归类
from sklearn.model_selection import train_test_split # 数据集的划分
from sklearn.datasets import load_iris # 导入数据集
# 1. 获取数据集
iris = load_iris()
print(iris)
我们可以看到数据是一个二维的数组,后面有对数据集的介绍。(前面三个数据是特征,最后一个是结果)
# 2. 指定特征值 x 目标值(标签)y
x,y = iris.data[:,2].reshape(-1,1),iris.data[:,3]
#这里我们将一个特征取出来,和结果进行分析。将数据取出后我们需要将数据进行划分,一部分用来训练,一部分进行测试我们的模型预测的结果怎么样
# 3. 数据集划分 ( 训练集 + 测试集)
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size= 0.2,random_state=20) # random_state 随机种子 X_train ,x_text 分别为训练集的特征和测试集的特征,y_train y_test 分别为训练集的目标值和测试集的目标值,我们将数据分成四份,用x_train和y_train为训练集用来生成目标函数,用x_test ,y_text来测试我们生成的目标函数预测的值是否合理。test_size= 0.2 意思是将训练集和测试集的数据比例分为0.2,一般都是0.2-0.3这样子。看数据量。模型建立:
# 4. 模型建立
lr = LinearRegression()
# 用回归对象训练模型 --- y = ax+b ---》 得到a和b的值
lr.fit(x_train,y_train)
print("权重w:\n",lr.coef_)
print('截距b:\n',lr.intercept_)
# 5. 预测
y_pre = lr.predict(x_test)
print("真实值:\n",y_test)
print("预测值:\n",y_pre)
#运行结果
权重w:
[0.42249848]
截距b:
-0.37054437192218637
真实值:
[0.2 1.2 1.3 1.6 1. 1.3 2.3 0.4 1.8 0.1 2. 1.4 1.5 0.2 0.2 2. 0.1 1.3
2.4 1. 1.4 1.8 1.9 0.2 1.5 1. 1.1 0.2 2.2 1.5]
预测值:
[0.22095351 1.6151985 1.44619911 2.07994684 1.36169941 1.31944957
2.12219669 0.26320335 2.07994684 0.22095351 1.82644775 1.65744835
1.74194805 0.13645381 0.22095351 2.46019547 0.09420396 1.57294866
1.7841979 1.02370063 1.6151985 1.7841979 1.8686976 0.34770305
1.6996982 1.19270002 0.89695108 0.26320335 2.07994684 1.7841979 ]这个时候我们得到了数据,单纯的这样看看不出差距效果,那么我们就可以使用matplotib库进行画图。
# 绘图
import matplotlib.pyplot as plt
plt.rcParams['font.family'] = 'SimHei'
plt.figure(figsize=(15,6))
plt.plot(y_test,label='真实值',color='red',marker = 'o')
plt.plot(y_pre,label='预测值',color='green',ls='--',marker ='D')
plt.xlabel("测试集数据序号")
plt.ylabel("数据值")
plt.legend() # 显示图例
plt.show()这个就是绘制折线图的效果
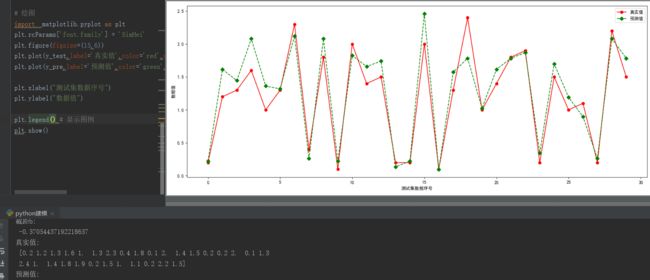
以上是通过一个特征进行预测的结果与真实值结果的对比。
定量评估模型
from sklearn.metrics import mean_squared_error,mean_absolute_error,r2_score
import numpy as np
print("均方误差",mean_squared_error(y_test,y_pre))
print("均方根误差",np.sqrt(mean_squared_error(y_test,y_pre)))
print("训练集r^2",r2_score(y_train,lr.predict(x_train)))
print("测试集r^2",r2_score(y_test,y_pre))
print("训练集r^2",lr.score(x_train,y_train))
print("测试集r^2",lr.score(x_test,y_test))