第十一届泰迪杯数据挖掘挑战赛-产品订单数据分析B题(完整代码)--数据分析--第三部分
导入所需要的库
代码链接来源https://mbd.pub/o/bread/ZJaTk5tw
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from datetime import datetime
from pandas import Series
from sklearn.metrics import mean_squared_error
from math import sqrt
from statsmodels.tsa.seasonal import seasonal_decompose
import statsmodels
import statsmodels.api as sm
from statsmodels.tsa.arima_model import ARIMA
%matplotlib inline
plt.rcParams['font.sans-serif'] = ["SimHei"]
plt.rcParams["axes.unicode_minus"] = False
更改日期格式
df["order_date"]=df["order_date"].apply(pd.to_datetime,format='%Y-%m-%d')
#删除多余列
df = df.drop(['order_date.1'],axis=1)#移动索引并查找差异
dff['step'] = dff['order_date']-dff['order_date'].shift(1)
zero = np.timedelta64(0, 's')
dff['step'][0] = np.timedelta64(0, 's')#将第一个变量从naT更改为零
dff['step'] = dff['step'].apply(lambda x: x>zero).cumsum()
dff.head()2 构建模型
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn import preprocessing
from sklearn.metrics import mean_squared_error,roc_auc_score,precision_score,accuracy_score,log_loss
from xgboost import XGBRegressor
import lightgbm as lgb
#optimizer
from functools import partial#train_df = dff 养成习惯,将dff作为备用数据变量,防止出错
train_df = dff
def smape(a, f):
*******************
train_df['step^2'] = train_df['step']**2#LinearRegression()
# split data
X_train,X_val,y_train,y_val = train_test_split(features,targets,test_size=0.05,shuffle=False)
model2 = LinearRegression()
model2.fit(X_train, y_train)
smape(y_val,model2.predict(X_val))
#指标解释
MSE
均方误差(Mean Square Error)当预测值与真实值完全吻合时等于0,即完美模型;误差越大,该值越大。
RMSE
均方根误差(Root Mean Square Error),其实就是MSE加了个根号,这样数量级上比较直观,比如RMSE=10,可以认为回归效果相比真实值平均相差10。当预测值与真实值完全吻合时等于0,即完美模型;误差越大,该值越大。
MAE
平均绝对误差(Mean Absolute Error),当预测值与真实值完全吻合时等于0,即完美模型;误差越大,该值越大
MAPE
平均绝对百分比误差(Mean Absolute Percentage Error)
MAPE 为0%表示完美模型,MAPE 大于 100 %则表示劣质模型。
可以看到,MAPE跟MAE很像,就是多了个分母。
SMAPE
对称平均绝对百分比误差(Symmetric Mean Absolute Percentage Error)
一个地区一个地区去检验 从101改至105,依次进行即可,之后可以根据需求对大类别特征,细类别特征进行探讨 就修改下方region_1 = region_1[(region_1["sales_region_code"]==101)]部分即可

#导入特征列
features = region_1[[ 'sales_region_code', 'item_code', 'first_cate_code',
'second_cate_code', 'sales_chan_name', 'item_price','Year',
'Month', 'day', 'day of the week', 'quarter', 'is_month_start',
'is_month_end', 'is_quarter_start', 'is_quarter_end', 'is_year_start',
'is_year_end', 'is_workday', 'is_holiday', 'sales','step', 'step^2']]
targets = region_1['ord_qty']# split data
X_train,X_val,y_train,y_val = train_test_split(features,targets,test_size=0.05,shuffle=False)model1 = LinearRegression()
****
#98.03167520705503
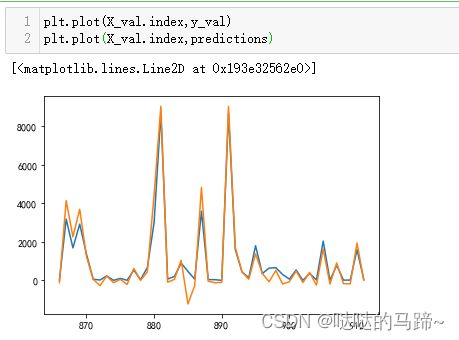
模型效果相差不大
#运用xgboost
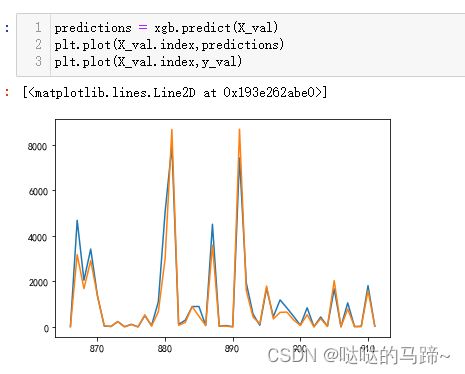
smape(y_val,predictions)
#30.41483734354367
#模型误差变小#绘制学习曲线

#修改参数

#模型误差变小
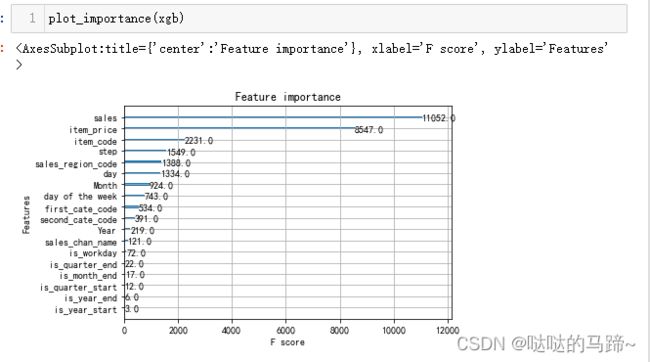
#得到变量的重要性
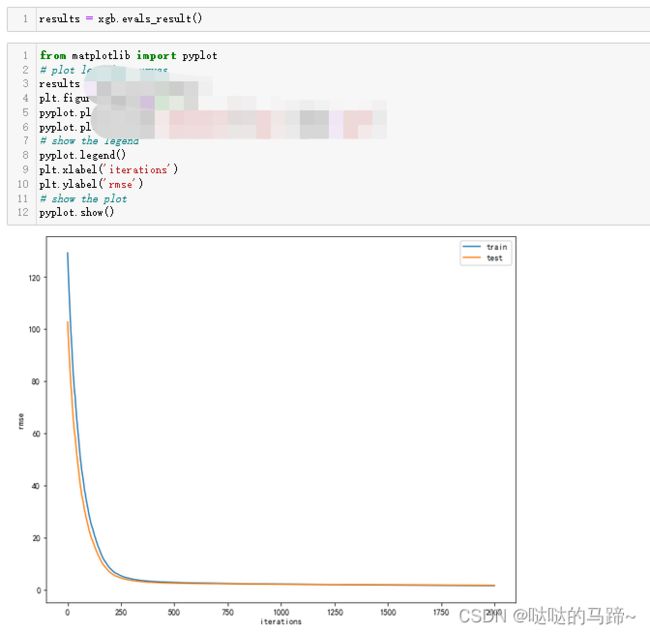
results = xgb.evals_result()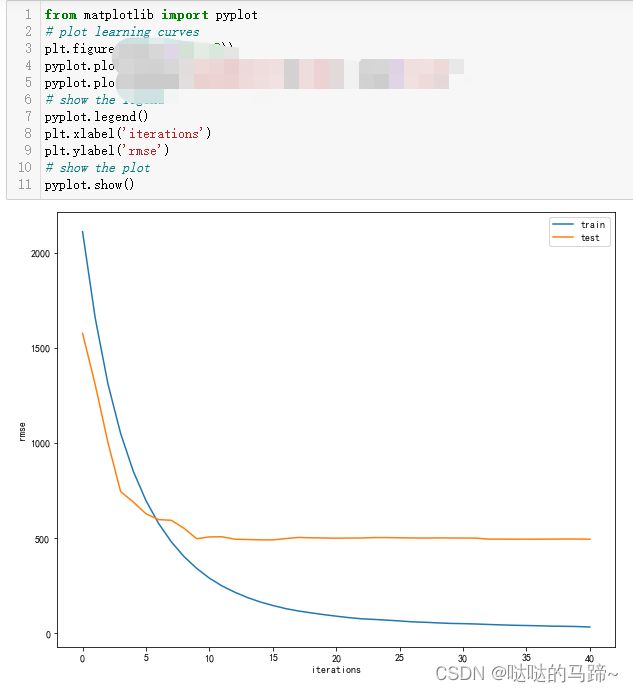
#CatBoostRegressor

模型在未调参时表现很好
进行超参数调整
def objective(trial,X,y, name='xgb'):
params = param = {
'tree_method':'gpu_hist',
'lambda': trial.suggest_loguniform(
'lambda', 1e-3, 10.0
),
'alpha': trial.suggest_loguniform(
'alpha', 1e-3, 10.0
),
'eta': trial.suggest_float('eta', 1e-5, 0.1),
'colsample_bytree': ******************
),
'subsample': trial.suggest_categorical(
******************
),
'learning_rate': trial.suggest_categorical(
********************
),
'n_estimators': trial.suggest_categorical(
"n_estimators"****************
),
'max_depth': trial.suggest_categorical(
*********************
),
'random_state': 42,
'min_child_weight': trial.suggest_int(
*********************
),
'random_state':10
}
model = XGBRegressor(**params)
model.fit(X_train,y_train,eval_set=[(X_val,y_val)],early_stopping_rounds=50,verbose=False)
train_score = ************, model.predict(X_train))), 5)
test_score = np.round(np.sqrt(mean_squared_error(*************)), 5)
print(f'TRAIN RMSE : {train_score} || TEST RMSE : {test_score}')
return test_scoreparams ={'lambda': 0.0012338191278124635, 'alpha': 3.284395992431614, 'eta': 0.09886834650237164, *****}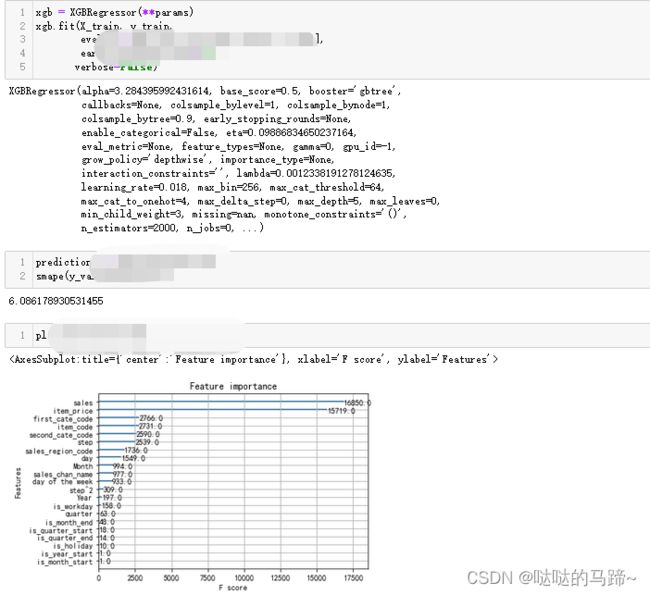

更精彩还在后续-敬请关注“哒哒的马蹄”下一博客
最后预测请关注下一博客
