Cluster(集群)模式
Cluster(集群)模式
- Cluster(集群)模式
-
- 存在问题
- 分布式和集群
- 一致性hash算法
-
- hash算法应用场景
- 集群时钟同步问题
- 分布式ID解决⽅案
-
- UUID(可用)
- 独立数据库的自增id(不推荐)
- snowflake 雪花算法(可用)
- 借助redis的incr命令获取全局唯一ID(推荐)
- 分布式调度问题
-
- 定时任务的场景
- 分布式调度
- 定时任务的实现
- elastic-job-lite
- Session共享问题
Cluster(集群)模式
存在问题
1、hash算法
2、集群时钟同步问题
3、分布式id问题
4、分布式调度问题(定时任务的分布式执行)
5、session共享问题
分布式和集群
分布式一定是集群,集群不一定是分布式。
分布式是把一个系统拆分为多个子系统,每个子系统负责各自的功能,独立部署。
集群是多个实例共同工作,例如:把一个应用复制多份部署。
一致性hash算法
hash算法,比如在安全加密中MD5、SHA等加密算法,在数据存储和查找方面有hash表等,一穿上都应用到了hash算法。
使用hash的原因:
hash算法较多的应用在数据存储和查找领域,最经典的就是hash表,他的查询效率非常高,其中的哈希算法设计比较合理的话,那么hash表的数据查询时间复杂度可以接近于O(1),即hash算法能够让数据平均分布,既能够节省空间,又能提高效率。
hash算法应用场景
hash算法在分布式集群架构中的应用场景。
hash算法在很多分布式集群产品中都有应用,比如分布式集群架构redis、hadoop、elasticSearch、mysql分库分表、nginx负载均衡等。
主要应用场景有两个:
请求的负载均衡(比如nginx的ip_hash的策略)
nginx的ip_hash的策略可以在客户端ip必变的情况下,将其发出的请求始终路由到同一个目标服务器上,实现回话沾滞,避免处理session共享问题。
如果没有ip_hash策略,可以维护一张映射表,存储客户端ip或者sessionid与具体目标服务器的映射关系。在客户端很多的情况下,会浪费内存空间;客户端上下线,目标服务器上下线都回导致重新维护映射表,映射表维护成本很大。
如果使用hash算法,我们可以对ip地址或者sessionid进行计算hash值,hash值与服务器数量进行取模运算,得到的值就是当前请求应该被路由到的服务器标号,这样同一个客户端ip发送过来的请求就可以路由到同一个服务器,这样可以实现会话沾滞
分布式存储(数据存储的位置,以redis为例)
redus1,redis2,redis3三台服务器
集群时钟同步问题
集群中各个服务器时间不同,会导致一系列问题。

1、分布式集群中各个服务器节点都可以连接互联⽹
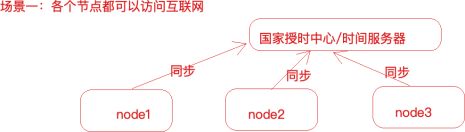
#使⽤ ntpdate ⽹络时间同步命令
ntpdate -u ntp.api.bz #从⼀个时间服务器同步时间
windows有计划任务
Linux也有定时任务,crond,可以使⽤linux的定时任务,每隔10分钟执⾏⼀次ntpdate命令
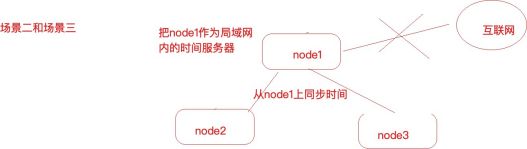
2、分布式集群中某⼀个服务器节点可以访问互联⽹或者所有节点都不能够访问互联⽹
分布式ID解决⽅案
分表之后ID不能重复,因此不能用主键自增。
UUID(可用)
通用唯一识别码,java中的java.util.UUID包中提供UUID
String s = UUID.randomUUID().toString();
生成的UUID特别长,没有什么规律。
独立数据库的自增id(不推荐)
统一出一个数据库,新建一张表A,使其id自增,其他服务器需要id 的时候,给A表添加一条数据,返回其id作为id,保证id唯一。不推荐该方式,如果表A数据库挂了,或者响应很慢,则会影响程序。
snowflake 雪花算法(可用)
雪花算法是Twitter推出的⼀个⽤于⽣成分布式ID的策略。
雪花算法是⼀个算法,基于这个算法可以⽣成ID,⽣成的ID是⼀个long型,那么在Java中⼀个long型是8个字节,算下来是64bit
1、符号位:固定为0
2、接下来41位用来记录时间戳,标识某一个毫秒
3、接下来10位代表机器id
4、最后12位,序列号,用来记录某个机器同一个毫秒内产生的不同序列号,代表同一个机器同一个毫秒可以产生的id序号。
借助redis的incr命令获取全局唯一ID(推荐)
redis incr命令将key中存储的数字值增一,如果可以不存在,那么key值会被初始化为0,再执行incr操作。
分布式调度问题
调度-》在分布式集群环境下定式任务这件事。
elastic-job(当当网开源的分布式调度框架)
定时任务的场景
定时任务的形式:每隔一定时间/特定某一时刻执行任务。
分布式调度
1、运行在分布式集群环境下的调度任务(同一个定时任务不熟多份,同一时刻只有一个定时任务在执行。)
2、分布式调度-》定式任务的分布式-》定时任务的拆分(即为吧一个打的作业拆分为多个小德作业任务,同时执行。)
定时任务和消息队列的区别
共同点:
- 异步处理
比如注册、下单事件 - 应用解耦
不管定时任务作业还是MQ都可以作为两个应用之间的齿轮实现应用解耦,这个齿轮可以中专数据,服务拆分的时候需要考虑 - 流量削峰
本质不同:
定时任务作业是时间驱动的,MQ是事件驱动的。
时间驱动是不可替代的。
定时任务作业更倾向于批处理,MQ倾向于逐条处理。
定时任务的实现
定时任务的实现⽅式有多种。早期没有定时任务框架的时候,我们会使⽤JDK中的Timer机制和多线程机制(Runnable+线程休眠)来实现定时或者间隔⼀段时间执⾏某⼀段程序;后来有了定时任务框架,⽐ 如Quartz任务调度框架,使⽤时间表达式(包括:秒、分、时、⽇、周、年)配置某⼀个任务什么时间去执⾏。
// 1、任务调度器
public static Scheduler createScheduler() throws SchedulerException {
SchedulerFactory schedulerFactory=new StdSchedulerFactory();
Scheduler scheduler = schedulerFactory.getScheduler();
return scheduler;
}
// 2、创建任务
public static JobDetail createJob(){
JobBuilder builder=JobBuilder.newJob(MyJob.class); //TODO 自定义任务类
builder.withIdentity("jobName","myJob");
JobDetail build = builder.build();
return build;
}
// 3、任务时间触发器
/**
* cron表达式由七个位置组成,空格分隔
* 1、Seconds(秒) 0~59
* 2、Minutes(分) 0~59
* 3、Hours(⼩时) 0~23
* 4、Day of Month(天)1~31,注意有的⽉份不⾜31天
* 5、Month(⽉) 0~11,或者JAN,FEB,MAR,APR,MAY,JUN,JUL,AUG,SEP,OCT,NOV,DEC
* 6、Day of Week(周) 1~7,1=SUN或者 SUN,MON,TUE,WEB,THU,FRI,SAT
* 7、Year(年)1970~2099 可选项
* 示例:
* 0 0 11 * * ? 每天的11点触发执⾏⼀次
* 0 30 10 1 * ? 每⽉1号上午10点半触发执⾏⼀次
*/
public static Trigger createTrigger(){
CronTrigger cronTrigger=TriggerBuilder.newTrigger().
withIdentity("triggerName","myTrigger").
startNow().
withSchedule(CronScheduleBuilder.cronSchedule("*/2 * * * * ?")).build();
return cronTrigger;
}
/**
* 开启定时任务
* @param args
*/
public static void main(String[] args) throws SchedulerException {
Scheduler scheduler = QuartzDemoClz.createScheduler();
JobDetail job = QuartzDemoClz.createJob();
Trigger trigger = QuartzDemoClz.createTrigger();
// 4、使用任务调度器根据时间触发器去执行任务
scheduler.scheduleJob(job,trigger);
scheduler.start();
}
elastic-job-lite
- 分布式调度协议
在分布式环境中,任务能够按指定的调度策略执行,并且能够避免同一任务多实例重复执行 - 丰富的调度策略
基于成熟的定时任务框架quartz cron表达式执行定式任务 - 弹性扩容缩容
当集群中增加某⼀个实例,它应当也能够被选举并执⾏任务;当集群减少⼀个实例时,它所执⾏的任务能被转移到别的实例来执⾏。 - 失效转移
某实例在任务执⾏失败后,会被转移到其他实例执⾏ - 错过执⾏作业重触发
若因某种原因导致作业错过执⾏,⾃动记录错过执⾏的作业,并在上次作业完成后⾃动触发。 - ⽀持并⾏调度
⽀持任务分⽚,任务分⽚是指将⼀个任务分为多个⼩任务项在多个实例同时执⾏。 - 业分⽚⼀致性
当任务被分⽚后,保证同⼀分⽚在分布式环境中仅⼀个执⾏实例。
Session共享问题
- Nginx的 IP_Hash 策略(可以使⽤)
同⼀个客户端IP的请求都会被路由到同⼀个⽬标服务器,也叫做会话粘滞 - Session共享,Session集中存储(推荐)
使用spring session+redis 来实现session共享
1、jar包
org.springframework.boot
spring-boot-starter-data-redis
org.springframework.session
spring-session-data-redis
2、配置redis
spring.redis.database=0
spring.redis.host=127.0.0.1
spring.redis.port=6379
3、在启动类上添加EnableRedisHttpSession注解