11万字数字政府智慧政务大数据建设平台(大数据底座、数据治理)
本资料来源公开网络,仅供个人学习,请勿商用,如有侵权请联系删除。
部分资料内容:
一.1.1 数据采集子系统
数据采集需要实现对全区各委办单位的数据采集功能,包括离线采集、准实时采集和实时采集的采集方式,根据各委办局业务数据的情况进行采集技术的实现。
Ø 数据采集:政府数据来源多样,包含视频类数据、物联感知类数据以及传统的政务公共数据,各数据来源的数据格式也不一致,在收集的过程中需对数据进行规范化处理,以便于管理使用。
Ø 大数据存储:实现现有应用的大量结构化数据、半结构化数据,以及将全市统一规划的大量图片、视频资料等非结构化数据的存储需求,要求大数据基础平台采用分布式文件系统实现对汇聚的多类型海量数据的存储。
Ø 大数据分析计算:数据分析的处理速度、准确度对实际应用的及时性、高效性都有至关重要的影响。大数据平台提供分布式计算、流式计算、内存计算多种数据计算引擎,能够针对不同的场景采用不同的计算模型,对数据进行大规模批量处理或者实时处理,大大提升政府部门的决策效率能力。
Ø 分布式资源管理和调度:Hadoop 2.0中的资源管理系统,它是一个通用的资源模块,可以为各类应用程序进行资源管理和调度。
Ø 大数据集群运维管理:作为运维系统,为数据基础支撑子平台提供高可靠、安全、容错、易用的集群管理能力,支持大规模集群的安装/升级/补丁、配置管理、监控管理、告警管理、用户管理、租户管理等。
一.1.2 数据治理子系统
建设大数据治理子平台,提供数据标准管理、元数据管理、数据质量管理能力,实现对数据的规范治理与管理;提供数据工厂能力,实现对归集的数据进行清洗、加工,支撑业务的数据应用需求。具体,在本次杨浦大数据资源平台建设项目中,数据治理子平台的建设内容包括:
Ø 资源目录管理:提供资源目录管理功能,包括:资源编目、目录提交、目录审核、目录发布、目录汇总、目录查询等;
Ø 数据标准管理:提供数据标准管理功能,包括:字典标准管理、命名标准管理、维度标准管理及数据项标准管理;
Ø 元数据管理:提供元数据管理功能,包括:元数据正向采集、元数据维护、元数据查询、元数据导入/导出、元数据血缘分析;
Ø 数据质量管理:提供数据质量管理功能,包括:质量模型配置、质量规则管理、方案配置调度、质检结果查看、质检分析报告;
Ø 数据开发平台:提供数据开发平台能力,支持可视化开发和原生态开发两种开发模式,实现原生态开发与可视化编排的互相转换;
Ø 统一调度管理:提供统一调度管理功能,提供流程设计与管理、调度策略管控、任务调度控制、等功能模块。
一.1.3 数据资源中心
在本次项目中,我们需要制定全区公共数据汇聚的标准规范和管理制度,归集全区各单位的政府公共数据,形成XX市的数据资源湖。同时经过对数据进行清洗、转换、融合、治理后,形成高质量的公共数据资源,构建形成杨浦标准化数据仓库。
基于全区的数据资源湖,利用经过治理后的数据,可以针对某一特领域的业务数据共享、应用需求,按主题归集形成专题库和主题库,并面向政务部门及社会进行数据开放。此外,我们还将持续开展、深入杨浦大数据的应用探索,围绕跨部门、跨领域、跨行业的数据应用需求,对数据实体进行数据关联、数据融合和衍生计算,生成算法标签,逐步建立不同领域的应用专题或主题库构建面向全区多部门提供统筹的数据共建共享共用的数据服务。具体,在本次杨浦大数据资源平台建设项目中,数据资源门户的建设内容包括:
Ø 建立XX市级数据湖:构建全区公共数据的存储与计算空间,支撑各类数据资源的汇聚存储、处理计算与查询应用,并依据部门类别、数据源类别等提供资源隔离的多租户数据应用空间;
Ø 完成数据对接的实施:完成与区各委办业务与管理系统、XX大数据资源平台以及物联网相关平台数据的对接,汇聚各类业务数据,形成全区公共数据资源池;
Ø 建设基础库:建设全区统一的基础人口综合库、法人综合库、电子证照库以及地理空间库,支撑全区人口、法人、电子证照与地理空间等数据相关应用;
Ø 建设主题库:建设全区统一的产业经济主题库、电子证照主题库、权力事项主题库等,支撑全区产业经济相关数据应用。
Ø 主题库
围绕跨部门、跨领域、跨行业等的通用应用服务,对数据实体进行数据关联、数据融合和衍生计算,生成算法标签,提供超级应用级数据服务。主题库的建设是为了满足某一特大型领域的业务共建共享需求,需要多个部门合作,在大数据主管部门的支撑下,构建面向全区多部门提供统筹的数据共建共享共用的数据服务。
为了解决目前全区面向企业法人提供服务缺失基础数据的情况,本次项目拟建设XX市企业精准服务主题库。
Ø 专题库
面向特定领域专题应用的数据服务。一般由各自委办局自行开发建设,也可以根据实际情况由委办局委托大数据中心代建代运营。作为领域的专题数据,一般不作为支撑大型跨领域、跨行业的超级综合应用并向外部门提供数据服务,更多的是满足部门自身需求。
一.1.4 数据共享子系统
为减少不同委办大数据服务中共性模块的重复建设,实现对外服务的规范、安全管理和成功案例的快速复制,最大程度吸引外部开发能力,建设大数据对外服务基础平台,提供数据交换管理、自助数据探索、个性化推荐、行业标签等共性服务功能,实现大数据对外服务的快速部署。
建设数据共享服务将功能和接口,要求以应用需求为导向,在政务服务、市场监管、城市管理、社会治理等领域探索开展公共数据共享应用,为跨区域协同发展提供数据支撑。
包含数据交换和服务管理,支持结构化库表下发、文件共享、API接口共享、非结构化数据共享、接口代理等多种数据共享方式。
一.1.5 门户子系统
在XX市大数据资源平台项目的基础上扩展功能。主要包括消息推送、数据推送、个人信息管理、系统管理等功能。
建立数据开放门户:主要实现数据目录、数据接口、数据应用、数据图谱、地图数据、互动交流、数据开发者、辅助事项、个人管理等各项门户目录的建设。包含业务流程申请、展示、统计、查询等功能。
Ø 分析、统计、展示功能
将数据共享情况、数据归集情况进行统计分析后展示。可对填报、统计分析数据设置审批岗,对数据进行双重把关,对统计结果进行推送。KPI指标监控、监控指标预警信息及时推送、数据钻取,实现由粗-细,切换维度的数据分析、可视化图表,易于信息获取。
Ø 查询及业务流程申请功能
当委办向大数据中心提出查询要求,需要通过申请审批完成数据资源分享,同意后,方可对委办开放查询服务,以满足委办对于某项或某类数据的需要。
大数据中心对接委办的管理流程,委办提出需求需要查询某数据项,将在该门户提出申请,如三清单一目录的申请,直接进行登记。
一.1.6 统一运维子系统
为了实现杨浦大数据资源平台下的高效运行和维护,提供标准化的监控管理指标和数据,对云资源、应用和业务对象的性能数据管理、运行状态监视和告警管理等,及时发现异常和潜在问题,对云管理运行过程中的监控及容量使用情况等运维数据进行深入分析,保障大数据资源平台稳定、高效的运行以及资源安全、合理的分配。构建一站式数据资产可视化管理,实现对数据生产的全过程监控,实现对数据资产的血缘谱系和信息资源目录的统一管理。
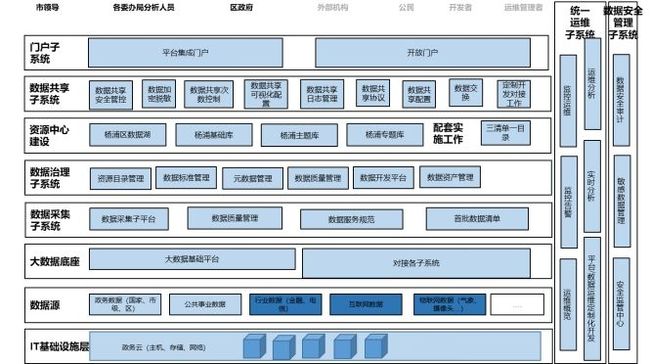
一.1.1 总架构图
本次项目建设的总体架构如下图:
一.1.1 数据治理子系统
建设大数据治理子平台,提供数据标准管理、元数据管理、数据质量管理能力,实现对数据的规范治理与管理;提供数据工厂能力,实现对归集的数据进行清洗、加工,支撑业务的数据应用需求。具体,在本次杨浦大数据资源平台建设项目中,数据治理子平台的建设内容包括:
Ø 资源目录管理:提供资源目录管理功能,包括:资源编目、目录提交、目录审核、目录发布、目录汇总、目录查询等;
Ø 数据标准管理:提供数据标准管理功能,包括:字典标准管理、命名标准管理、维度标准管理及数据项标准管理;
Ø 元数据管理:提供元数据管理功能,包括:元数据正向采集、元数据维护、元数据查询、元数据导入/导出、元数据血缘分析;
Ø 数据质量管理:提供数据质量管理功能,包括:质量模型配置、质量规则管理、方案配置调度、质检结果查看、质检分析报告;
Ø 数据开发平台:提供数据开发平台能力,支持可视化开发和原生态开发两种开发模式,实现原生态开发与可视化编排的互相转换;
统一调度管理:提供统一调度管理功能,提供流程设计与管理、调度策略管控、任务调度控制、等功能模块。
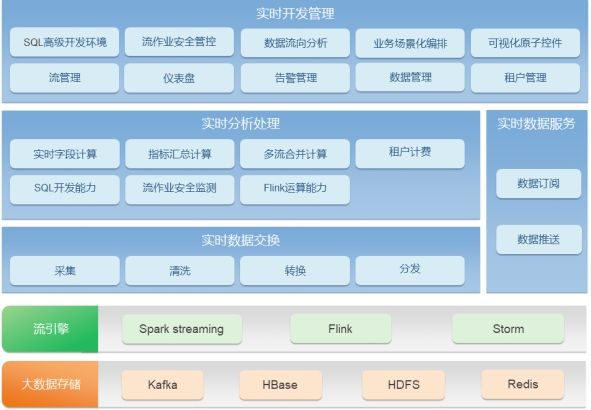
一.1.1.1 流处理引擎
为企业级用户搭建统一的分布式流式数据处理平台,实现统一的实时数据接入、处理、订阅,全面保障实时的业务场景开发。
实时开发管理:一站式完成流作业开发编排和管理能力,同时根据流数据的特征,进行统一建模管理;
实时数据服务:依据实时业务场景的特点,提供个性化数据订阅和数据推送能力;
实时分析处理:主要对流式数据进行业务逻辑运算,包括:字段计算、多流合并、维度汇总和复杂事件处理;
实时数据交换:主要完成B域订购数据、缴费数据、消费数据等的采集、清洗转换、分发,同时支持O域数据的采集;
一.1.1.1.1 实时流数据交换
采用Master-Slave的分布式架构,针对不同系统的多种数据源,提供一站式实时采集、预处理和分发的功能,全界面化数据流采集配置和管理,摆脱单调的自定义脚本和手动流程管理数据流。
· 异构系统间统一调度处理:支持异构系统、平台、数据库间数据调度流程的编排、调度、处理和监控;
· 全界面化操作能力:丰富的图形化操作界面,控件式无编码开发功能,开发0门槛。
· 分布式线性动态扩展:实现节点动态线性扩展,从而满足高性能要求。
· 对第三方软件集成能力:提供插件式开发,将对外服务、集成功能封装成API供其他软件调用;
一.1.1.1.2 实时流数据分析处理
通过高速分布式缓存Redis Cluster 完成流数据和批数据的关联运算,满足多维度指标的分组统计运算、实时汇总计算、多流合并计算。
实时字段计算:通过高速分布式缓存Redis Cluster 完成上网类、位置类、订单缴费类等流数据计算,运算速度快,高并发,高吞吐,并为用户提供托拉拽控件的方式,完成SQL即可完成标签,易用性强。
实时汇总计算:实时增量/全量数据汇总分析,支持多指标多维度并行计算,汇总结果直接输出给外部系统使用,提高效率,支持SQL语法,便捷、易用。
多流合并计算:解决多种流数据合并处理,例如:位置流+内容流的实时join场景,完全基于Spark、Flink内存机制,而非与外部组件交互,提供双时间窗口设定机制,规避时序性、延迟性。
一.1.1.1.3 实时数据开发
提供开发者基于控件模式的流数据开发编排能力,屏蔽了复杂的底层开发过程,降低开发门槛。提供向导式开发过程,简单易用,大幅提升客户感知。
一.1.1.1.4 实时任务监控及告警
全面展示作业运行的健康状态,包括运行时长、任务的运行情况。
提供实时和历史的性能指标分析和展示,同时提供性能优化的参数设定,即时生效。
Kafka核心指标实时监控,同时提供告警项和阈值设定,实时分级展示告警信息。
一.1.1.2 关联检索引擎
通过提供数据的存储、建立丰富的索引,多样化的查询接口,支持各种结构化业务数据解析,能够为更多的用户,丰富的数据类型,为多样化的业务提供通用的查询能力。
高效的查询性能:通过对不同业务场景建立索引,实现对流数据和批量数据的高效查询。
灵活的查询接口:提供可视化查询界面和API查询接口,通过定义丰富的查询参数支撑灵活的数据查询。
便捷的聚合查询:通过定义预定义函数,实现SQL的聚合查询,屏蔽底层查询的复杂性。

篇幅有限,无法完全展示,喜欢资料可转发+评论,私信了解更多信息。