笔精墨妙,妙手丹青,微软开源可视化版本的ChatGPT:Visual ChatGPT,人工智能AI聊天发图片,Python3.10实现
说时迟那时快,微软第一时间发布开源库Visual ChatGPT,把 ChatGPT 的人工智能AI能力和Stable Diffusion以及ControlNet进行了整合。常常被互联网人挂在嘴边的“赋能”一词,几乎已经变成了笑话,但这回,微软玩了一次真真正正的AI“赋能”,彻底打通了人工智能“闭环”。
配置Visual ChatGPT环境
老规矩,运行Git命令拉取Visual ChatGPT项目:
git clone https://github.com/microsoft/visual-chatgpt.git
进入项目目录:
cd visual-chatgpt
确保本机的Python版本不低于Python3.10.9
随后安装依赖文件:
pip3 install -r requirement.txt
这里有几个问题,一个是官方的Pytorch版本不是最新的,这里推荐1.13.1:
pip3 install torch==1.13.1
另外langchain的版本也推荐最新的107版本。
pip3 install langchain==0.0.107
安装好依赖之后,官方要求运行项目中的download.sh文件:
bash download.sh
这个shell脚本主要就是构建子项目ControlNet,同时下载所有的ControlNet模型,如果之前已经下载过相关模型,直接将模型文件拷贝到项目目录即可:
.
├── cldm_v15.yaml
├── cldm_v21.yaml
├── control_sd15_canny.pth
├── control_sd15_depth.pth
├── control_sd15_hed.pth
├── control_sd15_mlsd.pth
├── control_sd15_normal.pth
├── control_sd15_openpose.pth
├── control_sd15_scribble.pth
└── control_sd15_seg.pth
关于ControlNet,请移玉步至:登峰造极,师出造化,Pytorch人工智能AI图像增强框架ControlNet绘画实践,基于Python3.10, 这里不再赘述。
接着配置Openai的环境变量:
export OPENAI_API_KEY={你的openaik key}
如果是Windows用户,遵循下列步骤,配置好OPENAI_API_KEY:
打开“控制面板”,然后选择“系统和安全”。
选择“系统”,然后点击“高级系统设置”。
在“高级”选项卡下,点击“环境变量”。
在“用户变量”或“系统变量”下,选择要配置的变量,然后点击“编辑”。
在“变量值”字段中,输入要配置的值。
点击“确定”保存更改。
至此,大体上环境就配置好了。
Visual ChatGPT部分代码修改:
和ControlNet一样,Visual ChatGPT将运行方式写死为cuda,这对于不支持cuda模式的电脑不太友好,比如苹果M系列芯片的Mac系统,如果我们直接运行程序:
python3 visual_chatgpt.py
就会报这个错误:
AssertionError: Torch not compiled with CUDA enabled
这里需要将visual-chatgpt.py文件中写死的cuda模式改写为mps模式:
print("Initializing VisualChatGPT")
self.llm = OpenAI(temperature=0)
self.edit = ImageEditing(device="mps")
self.i2t = ImageCaptioning(device="mps")
self.t2i = T2I(device="mps")
关于MPS模式,请参照:闻其声而知雅意,M1 Mac基于PyTorch(mps/cpu/cuda)的人工智能AI本地语音识别库Whisper(Python3.10) ,这里不再赘述。
接着创建训练图片的文件夹:
mkdir image
随后还可能触发langchain库的内存溢出问题,需要将这行代码屏蔽:
# self.agent.memory.buffer = cut_dialogue_history(self.agent.memory.buffer, keep_last_n_words=500)
接着将内存缓冲区替换为保存上下文逻辑:
self.agent.memory.buffer = self.agent.memory.buffer + Human_prompt + 'AI: ' + AI_prompt
self.agent.memory.save_context({"input": Human_prompt}, {"output": AI_prompt})
当我们以为万事俱备只欠东风的时候,发现每次运行都会内存溢出,对此,官方给出了解释:
Here we list the GPU memory usage of each visual foundation model, one can modify self.tools with fewer visual foundation models to save your GPU memory:
Foundation Model Memory Usage (MB)
ImageEditing 6667
ImageCaption 1755
T2I 6677
canny2image 5540
line2image 6679
hed2image 6679
scribble2image 6679
pose2image 6681
BLIPVQA 2709
seg2image 5540
depth2image 6677
normal2image 3974
InstructPix2Pix 2795
这就是加载了所有模型之后的显存占用,整整70个G的显存占用,这是给人玩的吗?人们不禁要问。
没办法,只能另辟蹊径,将非必要的模型加载代码进行屏蔽操作,一顿修改,修改后的完整代码:
import sys
import os
sys.path.append(os.path.dirname(os.path.realpath(__file__)))
sys.path.append(os.path.dirname(os.path.dirname(os.path.realpath(__file__))))
import gradio as gr
from transformers import AutoModelForCausalLM, AutoTokenizer, CLIPSegProcessor, CLIPSegForImageSegmentation
import torch
from diffusers import StableDiffusionPipeline
from diffusers import StableDiffusionInstructPix2PixPipeline, EulerAncestralDiscreteScheduler
import os
from langchain.agents.initialize import initialize_agent
from langchain.agents.tools import Tool
from langchain.chains.conversation.memory import ConversationBufferMemory
from langchain.llms.openai import OpenAI
import re
import uuid
from diffusers import StableDiffusionInpaintPipeline
from PIL import Image
import numpy as np
from omegaconf import OmegaConf
from transformers import pipeline, BlipProcessor, BlipForConditionalGeneration, BlipForQuestionAnswering
import cv2
import einops
from pytorch_lightning import seed_everything
import random
from ldm.util import instantiate_from_config
from ControlNet.cldm.model import create_model, load_state_dict
from ControlNet.cldm.ddim_hacked import DDIMSampler
from ControlNet.annotator.canny import CannyDetector
from ControlNet.annotator.mlsd import MLSDdetector
from ControlNet.annotator.util import HWC3, resize_image
from ControlNet.annotator.hed import HEDdetector, nms
from ControlNet.annotator.openpose import OpenposeDetector
from ControlNet.annotator.uniformer import UniformerDetector
from ControlNet.annotator.midas import MidasDetector
VISUAL_CHATGPT_PREFIX = """Visual ChatGPT is designed to be able to assist with a wide range of text and visual related tasks, from answering simple questions to providing in-depth explanations and discussions on a wide range of topics. Visual ChatGPT is able to generate human-like text based on the input it receives, allowing it to engage in natural-sounding conversations and provide responses that are coherent and relevant to the topic at hand.
Visual ChatGPT is able to process and understand large amounts of text and images. As a language model, Visual ChatGPT can not directly read images, but it has a list of tools to finish different visual tasks. Each image will have a file name formed as "image/xxx.png", and Visual ChatGPT can invoke different tools to indirectly understand pictures. When talking about images, Visual ChatGPT is very strict to the file name and will never fabricate nonexistent files. When using tools to generate new image files, Visual ChatGPT is also known that the image may not be the same as the user's demand, and will use other visual question answering tools or description tools to observe the real image. Visual ChatGPT is able to use tools in a sequence, and is loyal to the tool observation outputs rather than faking the image content and image file name. It will remember to provide the file name from the last tool observation, if a new image is generated.
Human may provide new figures to Visual ChatGPT with a description. The description helps Visual ChatGPT to understand this image, but Visual ChatGPT should use tools to finish following tasks, rather than directly imagine from the description.
Overall, Visual ChatGPT is a powerful visual dialogue assistant tool that can help with a wide range of tasks and provide valuable insights and information on a wide range of topics.
TOOLS:
------
Visual ChatGPT has access to the following tools:"""
VISUAL_CHATGPT_FORMAT_INSTRUCTIONS = """To use a tool, please use the following format:
Thought: Do I need to use a tool? Yes
Action: the action to take, should be one of [{tool_names}]
Action Input: the input to the action
Observation: the result of the action
When you have a response to say to the Human, or if you do not need to use a tool, you MUST use the format:
Thought: Do I need to use a tool? No
{ai_prefix}: [your response here]
"""
VISUAL_CHATGPT_SUFFIX = """You are very strict to the filename correctness and will never fake a file name if it does not exist.
You will remember to provide the image file name loyally if it's provided in the last tool observation.
Begin!
Previous conversation history:
{chat_history}
New input: {input}
Since Visual ChatGPT is a text language model, Visual ChatGPT must use tools to observe images rather than imagination.
The thoughts and observations are only visible for Visual ChatGPT, Visual ChatGPT should remember to repeat important information in the final response for Human.
Thought: Do I need to use a tool? {agent_scratchpad}"""
def cut_dialogue_history(history_memory, keep_last_n_words=500):
tokens = history_memory.split()
n_tokens = len(tokens)
print(f"hitory_memory:{history_memory}, n_tokens: {n_tokens}")
if n_tokens < keep_last_n_words:
return history_memory
else:
paragraphs = history_memory.split('\n')
last_n_tokens = n_tokens
while last_n_tokens >= keep_last_n_words:
last_n_tokens = last_n_tokens - len(paragraphs[0].split(' '))
paragraphs = paragraphs[1:]
return '\n' + '\n'.join(paragraphs)
def get_new_image_name(org_img_name, func_name="update"):
head_tail = os.path.split(org_img_name)
head = head_tail[0]
tail = head_tail[1]
name_split = tail.split('.')[0].split('_')
this_new_uuid = str(uuid.uuid4())[0:4]
if len(name_split) == 1:
most_org_file_name = name_split[0]
recent_prev_file_name = name_split[0]
new_file_name = '{}_{}_{}_{}.png'.format(this_new_uuid, func_name, recent_prev_file_name, most_org_file_name)
else:
assert len(name_split) == 4
most_org_file_name = name_split[3]
recent_prev_file_name = name_split[0]
new_file_name = '{}_{}_{}_{}.png'.format(this_new_uuid, func_name, recent_prev_file_name, most_org_file_name)
return os.path.join(head, new_file_name)
def create_model(config_path, device):
config = OmegaConf.load(config_path)
OmegaConf.update(config, "model.params.cond_stage_config.params.device", device)
model = instantiate_from_config(config.model).to('mps')
print(f'Loaded model config from [{config_path}]')
return model
class MaskFormer:
def __init__(self, device):
self.device = device
self.processor = CLIPSegProcessor.from_pretrained("CIDAS/clipseg-rd64-refined")
self.model = CLIPSegForImageSegmentation.from_pretrained("CIDAS/clipseg-rd64-refined").to(device)
def inference(self, image_path, text):
threshold = 0.5
min_area = 0.02
padding = 20
original_image = Image.open(image_path)
image = original_image.resize((512, 512))
inputs = self.processor(text=text, images=image, padding="max_length", return_tensors="pt",).to(self.device)
with torch.no_grad():
outputs = self.model(**inputs)
mask = torch.sigmoid(outputs[0]).squeeze().cuda().numpy() > threshold
area_ratio = len(np.argwhere(mask)) / (mask.shape[0] * mask.shape[1])
if area_ratio < min_area:
return None
true_indices = np.argwhere(mask)
mask_array = np.zeros_like(mask, dtype=bool)
for idx in true_indices:
padded_slice = tuple(slice(max(0, i - padding), i + padding + 1) for i in idx)
mask_array[padded_slice] = True
visual_mask = (mask_array * 255).astype(np.uint8)
image_mask = Image.fromarray(visual_mask)
return image_mask.resize(image.size)
class ImageEditing:
def __init__(self, device):
print("Initializing StableDiffusionInpaint to %s" % device)
self.device = device
self.mask_former = MaskFormer(device=self.device)
self.inpainting = StableDiffusionInpaintPipeline.from_pretrained("runwayml/stable-diffusion-inpainting",).to(device)
def remove_part_of_image(self, input):
image_path, to_be_removed_txt = input.split(",")
print(f'remove_part_of_image: to_be_removed {to_be_removed_txt}')
return self.replace_part_of_image(f"{image_path},{to_be_removed_txt},background")
def replace_part_of_image(self, input):
image_path, to_be_replaced_txt, replace_with_txt = input.split(",")
print(f'replace_part_of_image: replace_with_txt {replace_with_txt}')
original_image = Image.open(image_path)
mask_image = self.mask_former.inference(image_path, to_be_replaced_txt)
updated_image = self.inpainting(prompt=replace_with_txt, image=original_image, mask_image=mask_image).images[0]
updated_image_path = get_new_image_name(image_path, func_name="replace-something")
updated_image.save(updated_image_path)
return updated_image_path
class Pix2Pix:
def __init__(self, device):
print("Initializing Pix2Pix to %s" % device)
self.device = device
self.pipe = StableDiffusionInstructPix2PixPipeline.from_pretrained("timbrooks/instruct-pix2pix", torch_dtype=torch.float16, safety_checker=None).to(device)
self.pipe.scheduler = EulerAncestralDiscreteScheduler.from_config(self.pipe.scheduler.config)
def inference(self, inputs):
"""Change style of image."""
print("===>Starting Pix2Pix Inference")
image_path, instruct_text = inputs.split(",")[0], ','.join(inputs.split(',')[1:])
original_image = Image.open(image_path)
image = self.pipe(instruct_text,image=original_image,num_inference_steps=40,image_guidance_scale=1.2,).images[0]
updated_image_path = get_new_image_name(image_path, func_name="pix2pix")
image.save(updated_image_path)
return updated_image_path
class T2I:
def __init__(self, device):
print("Initializing T2I to %s" % device)
self.device = device
self.pipe = StableDiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16)
self.text_refine_tokenizer = AutoTokenizer.from_pretrained("Gustavosta/MagicPrompt-Stable-Diffusion")
self.text_refine_model = AutoModelForCausalLM.from_pretrained("Gustavosta/MagicPrompt-Stable-Diffusion")
self.text_refine_gpt2_pipe = pipeline("text-generation", model=self.text_refine_model, tokenizer=self.text_refine_tokenizer, device=self.device)
self.pipe.to(device)
def inference(self, text):
image_filename = os.path.join('image', str(uuid.uuid4())[0:8] + ".png")
refined_text = self.text_refine_gpt2_pipe(text)[0]["generated_text"]
print(f'{text} refined to {refined_text}')
image = self.pipe(refined_text).images[0]
image.save(image_filename)
print(f"Processed T2I.run, text: {text}, image_filename: {image_filename}")
return image_filename
class ImageCaptioning:
def __init__(self, device):
print("Initializing ImageCaptioning to %s" % device)
self.device = device
self.processor = BlipProcessor.from_pretrained("Salesforce/blip-image-captioning-base")
self.model = BlipForConditionalGeneration.from_pretrained("Salesforce/blip-image-captioning-base").to(self.device)
def inference(self, image_path):
inputs = self.processor(Image.open(image_path), return_tensors="pt").to(self.device)
out = self.model.generate(**inputs)
captions = self.processor.decode(out[0], skip_special_tokens=True)
return captions
class image2canny:
def __init__(self):
print("Direct detect canny.")
self.detector = CannyDetector()
self.low_thresh = 100
self.high_thresh = 200
def inference(self, inputs):
print("===>Starting image2canny Inference")
image = Image.open(inputs)
image = np.array(image)
canny = self.detector(image, self.low_thresh, self.high_thresh)
canny = 255 - canny
image = Image.fromarray(canny)
updated_image_path = get_new_image_name(inputs, func_name="edge")
image.save(updated_image_path)
return updated_image_path
class canny2image:
def __init__(self, device):
print("Initialize the canny2image model.")
model = create_model('ControlNet/models/cldm_v15.yaml', device=device).to(device)
model.load_state_dict(load_state_dict('ControlNet/models/control_sd15_canny.pth', location='mps'))
self.model = model.to(device)
self.device = device
self.ddim_sampler = DDIMSampler(self.model)
self.ddim_steps = 20
self.image_resolution = 512
self.num_samples = 1
self.save_memory = False
self.strength = 1.0
self.guess_mode = False
self.scale = 9.0
self.seed = -1
self.a_prompt = 'best quality, extremely detailed'
self.n_prompt = 'longbody, lowres, bad anatomy, bad hands, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality'
def inference(self, inputs):
print("===>Starting canny2image Inference")
image_path, instruct_text = inputs.split(",")[0], ','.join(inputs.split(',')[1:])
image = Image.open(image_path)
image = np.array(image)
image = 255 - image
prompt = instruct_text
img = resize_image(HWC3(image), self.image_resolution)
H, W, C = img.shape
control = torch.from_numpy(img.copy()).float().to(device=self.device) / 255.0
control = torch.stack([control for _ in range(self.num_samples)], dim=0)
control = einops.rearrange(control, 'b h w c -> b c h w').clone()
self.seed = random.randint(0, 65535)
seed_everything(self.seed)
if self.save_memory:
self.model.low_vram_shift(is_diffusing=False)
cond = {"c_concat": [control], "c_crossattn": [self.model.get_learned_conditioning([prompt + ', ' + self.a_prompt] * self.num_samples)]}
un_cond = {"c_concat": None if self.guess_mode else [control], "c_crossattn": [self.model.get_learned_conditioning([self.n_prompt] * self.num_samples)]}
shape = (4, H // 8, W // 8)
self.model.control_scales = [self.strength * (0.825 ** float(12 - i)) for i in range(13)] if self.guess_mode else ([self.strength] * 13) # Magic number. IDK why. Perhaps because 0.825**12<0.01 but 0.826**12>0.01
samples, intermediates = self.ddim_sampler.sample(self.ddim_steps, self.num_samples, shape, cond, verbose=False, eta=0., unconditional_guidance_scale=self.scale, unconditional_conditioning=un_cond)
if self.save_memory:
self.model.low_vram_shift(is_diffusing=False)
x_samples = self.model.decode_first_stage(samples)
x_samples = (einops.rearrange(x_samples, 'b c h w -> b h w c') * 127.5 + 127.5).cuda().numpy().clip(0, 255).astype(np.uint8)
updated_image_path = get_new_image_name(image_path, func_name="canny2image")
real_image = Image.fromarray(x_samples[0]) # get default the index0 image
real_image.save(updated_image_path)
return updated_image_path
class image2line:
def __init__(self):
print("Direct detect straight line...")
self.detector = MLSDdetector()
self.value_thresh = 0.1
self.dis_thresh = 0.1
self.resolution = 512
def inference(self, inputs):
print("===>Starting image2hough Inference")
image = Image.open(inputs)
image = np.array(image)
image = HWC3(image)
hough = self.detector(resize_image(image, self.resolution), self.value_thresh, self.dis_thresh)
updated_image_path = get_new_image_name(inputs, func_name="line-of")
hough = 255 - cv2.dilate(hough, np.ones(shape=(3, 3), dtype=np.uint8), iterations=1)
image = Image.fromarray(hough)
image.save(updated_image_path)
return updated_image_path
class line2image:
def __init__(self, device):
print("Initialize the line2image model...")
model = create_model('ControlNet/models/cldm_v15.yaml', device=device).to(device)
model.load_state_dict(load_state_dict('ControlNet/models/control_sd15_mlsd.pth', location='mps'))
self.model = model.to(device)
self.device = device
self.ddim_sampler = DDIMSampler(self.model)
self.ddim_steps = 20
self.image_resolution = 512
self.num_samples = 1
self.save_memory = False
self.strength = 1.0
self.guess_mode = False
self.scale = 9.0
self.seed = -1
self.a_prompt = 'best quality, extremely detailed'
self.n_prompt = 'longbody, lowres, bad anatomy, bad hands, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality'
def inference(self, inputs):
print("===>Starting line2image Inference")
image_path, instruct_text = inputs.split(",")[0], ','.join(inputs.split(',')[1:])
image = Image.open(image_path)
image = np.array(image)
image = 255 - image
prompt = instruct_text
img = resize_image(HWC3(image), self.image_resolution)
H, W, C = img.shape
img = cv2.resize(img, (W, H), interpolation=cv2.INTER_NEAREST)
control = torch.from_numpy(img.copy()).float().to(device=self.device) / 255.0
control = torch.stack([control for _ in range(self.num_samples)], dim=0)
control = einops.rearrange(control, 'b h w c -> b c h w').clone()
self.seed = random.randint(0, 65535)
seed_everything(self.seed)
if self.save_memory:
self.model.low_vram_shift(is_diffusing=False)
cond = {"c_concat": [control], "c_crossattn": [self.model.get_learned_conditioning([prompt + ', ' + self.a_prompt] * self.num_samples)]}
un_cond = {"c_concat": None if self.guess_mode else [control], "c_crossattn": [self.model.get_learned_conditioning([self.n_prompt] * self.num_samples)]}
shape = (4, H // 8, W // 8)
self.model.control_scales = [self.strength * (0.825 ** float(12 - i)) for i in range(13)] if self.guess_mode else ([self.strength] * 13) # Magic number. IDK why. Perhaps because 0.825**12<0.01 but 0.826**12>0.01
samples, intermediates = self.ddim_sampler.sample(self.ddim_steps, self.num_samples, shape, cond, verbose=False, eta=0., unconditional_guidance_scale=self.scale, unconditional_conditioning=un_cond)
if self.save_memory:
self.model.low_vram_shift(is_diffusing=False)
x_samples = self.model.decode_first_stage(samples)
x_samples = (einops.rearrange(x_samples, 'b c h w -> b h w c') * 127.5 + 127.5).\
cuda().numpy().clip(0,255).astype(np.uint8)
updated_image_path = get_new_image_name(image_path, func_name="line2image")
real_image = Image.fromarray(x_samples[0]) # default the index0 image
real_image.save(updated_image_path)
return updated_image_path
class image2hed:
def __init__(self):
print("Direct detect soft HED boundary...")
self.detector = HEDdetector()
self.resolution = 512
def inference(self, inputs):
print("===>Starting image2hed Inference")
image = Image.open(inputs)
image = np.array(image)
image = HWC3(image)
hed = self.detector(resize_image(image, self.resolution))
updated_image_path = get_new_image_name(inputs, func_name="hed-boundary")
image = Image.fromarray(hed)
image.save(updated_image_path)
return updated_image_path
class hed2image:
def __init__(self, device):
print("Initialize the hed2image model...")
model = create_model('ControlNet/models/cldm_v15.yaml', device=device).to(device)
model.load_state_dict(load_state_dict('ControlNet/models/control_sd15_hed.pth', location='mps'))
self.model = model.to(device)
self.device = device
self.ddim_sampler = DDIMSampler(self.model)
self.ddim_steps = 20
self.image_resolution = 512
self.num_samples = 1
self.save_memory = False
self.strength = 1.0
self.guess_mode = False
self.scale = 9.0
self.seed = -1
self.a_prompt = 'best quality, extremely detailed'
self.n_prompt = 'longbody, lowres, bad anatomy, bad hands, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality'
def inference(self, inputs):
print("===>Starting hed2image Inference")
image_path, instruct_text = inputs.split(",")[0], ','.join(inputs.split(',')[1:])
image = Image.open(image_path)
image = np.array(image)
prompt = instruct_text
img = resize_image(HWC3(image), self.image_resolution)
H, W, C = img.shape
img = cv2.resize(img, (W, H), interpolation=cv2.INTER_NEAREST)
control = torch.from_numpy(img.copy()).float().to(device=self.device) / 255.0
control = torch.stack([control for _ in range(self.num_samples)], dim=0)
control = einops.rearrange(control, 'b h w c -> b c h w').clone()
self.seed = random.randint(0, 65535)
seed_everything(self.seed)
if self.save_memory:
self.model.low_vram_shift(is_diffusing=False)
cond = {"c_concat": [control], "c_crossattn": [self.model.get_learned_conditioning([prompt + ', ' + self.a_prompt] * self.num_samples)]}
un_cond = {"c_concat": None if self.guess_mode else [control], "c_crossattn": [self.model.get_learned_conditioning([self.n_prompt] * self.num_samples)]}
shape = (4, H // 8, W // 8)
self.model.control_scales = [self.strength * (0.825 ** float(12 - i)) for i in range(13)] if self.guess_mode else ([self.strength] * 13)
samples, intermediates = self.ddim_sampler.sample(self.ddim_steps, self.num_samples, shape, cond, verbose=False, eta=0., unconditional_guidance_scale=self.scale, unconditional_conditioning=un_cond)
if self.save_memory:
self.model.low_vram_shift(is_diffusing=False)
x_samples = self.model.decode_first_stage(samples)
x_samples = (einops.rearrange(x_samples, 'b c h w -> b h w c') * 127.5 + 127.5).cuda().numpy().clip(0, 255).astype(np.uint8)
updated_image_path = get_new_image_name(image_path, func_name="hed2image")
real_image = Image.fromarray(x_samples[0]) # default the index0 image
real_image.save(updated_image_path)
return updated_image_path
class image2scribble:
def __init__(self):
print("Direct detect scribble.")
self.detector = HEDdetector()
self.resolution = 512
def inference(self, inputs):
print("===>Starting image2scribble Inference")
image = Image.open(inputs)
image = np.array(image)
image = HWC3(image)
detected_map = self.detector(resize_image(image, self.resolution))
detected_map = HWC3(detected_map)
image = resize_image(image, self.resolution)
H, W, C = image.shape
detected_map = cv2.resize(detected_map, (W, H), interpolation=cv2.INTER_LINEAR)
detected_map = nms(detected_map, 127, 3.0)
detected_map = cv2.GaussianBlur(detected_map, (0, 0), 3.0)
detected_map[detected_map > 4] = 255
detected_map[detected_map < 255] = 0
detected_map = 255 - detected_map
updated_image_path = get_new_image_name(inputs, func_name="scribble")
image = Image.fromarray(detected_map)
image.save(updated_image_path)
return updated_image_path
class scribble2image:
def __init__(self, device):
print("Initialize the scribble2image model...")
model = create_model('ControlNet/models/cldm_v15.yaml', device=device).to(device)
model.load_state_dict(load_state_dict('ControlNet/models/control_sd15_scribble.pth', location='mps'))
self.model = model.to(device)
self.device = device
self.ddim_sampler = DDIMSampler(self.model)
self.ddim_steps = 20
self.image_resolution = 512
self.num_samples = 1
self.save_memory = False
self.strength = 1.0
self.guess_mode = False
self.scale = 9.0
self.seed = -1
self.a_prompt = 'best quality, extremely detailed'
self.n_prompt = 'longbody, lowres, bad anatomy, bad hands, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality'
def inference(self, inputs):
print("===>Starting scribble2image Inference")
print(f'sketch device {self.device}')
image_path, instruct_text = inputs.split(",")[0], ','.join(inputs.split(',')[1:])
image = Image.open(image_path)
image = np.array(image)
prompt = instruct_text
image = 255 - image
img = resize_image(HWC3(image), self.image_resolution)
H, W, C = img.shape
img = cv2.resize(img, (W, H), interpolation=cv2.INTER_NEAREST)
control = torch.from_numpy(img.copy()).float().to(device=self.device) / 255.0
control = torch.stack([control for _ in range(self.num_samples)], dim=0)
control = einops.rearrange(control, 'b h w c -> b c h w').clone()
self.seed = random.randint(0, 65535)
seed_everything(self.seed)
if self.save_memory:
self.model.low_vram_shift(is_diffusing=False)
cond = {"c_concat": [control], "c_crossattn": [self.model.get_learned_conditioning([prompt + ', ' + self.a_prompt] * self.num_samples)]}
un_cond = {"c_concat": None if self.guess_mode else [control], "c_crossattn": [self.model.get_learned_conditioning([self.n_prompt] * self.num_samples)]}
shape = (4, H // 8, W // 8)
self.model.control_scales = [self.strength * (0.825 ** float(12 - i)) for i in range(13)] if self.guess_mode else ([self.strength] * 13)
samples, intermediates = self.ddim_sampler.sample(self.ddim_steps, self.num_samples, shape, cond, verbose=False, eta=0., unconditional_guidance_scale=self.scale, unconditional_conditioning=un_cond)
if self.save_memory:
self.model.low_vram_shift(is_diffusing=False)
x_samples = self.model.decode_first_stage(samples)
x_samples = (einops.rearrange(x_samples, 'b c h w -> b h w c') * 127.5 + 127.5).cuda().numpy().clip(0, 255).astype(np.uint8)
updated_image_path = get_new_image_name(image_path, func_name="scribble2image")
real_image = Image.fromarray(x_samples[0]) # default the index0 image
real_image.save(updated_image_path)
return updated_image_path
class image2pose:
def __init__(self):
print("Direct human pose.")
self.detector = OpenposeDetector()
self.resolution = 512
def inference(self, inputs):
print("===>Starting image2pose Inference")
image = Image.open(inputs)
image = np.array(image)
image = HWC3(image)
detected_map, _ = self.detector(resize_image(image, self.resolution))
detected_map = HWC3(detected_map)
image = resize_image(image, self.resolution)
H, W, C = image.shape
detected_map = cv2.resize(detected_map, (W, H), interpolation=cv2.INTER_LINEAR)
updated_image_path = get_new_image_name(inputs, func_name="human-pose")
image = Image.fromarray(detected_map)
image.save(updated_image_path)
return updated_image_path
class pose2image:
def __init__(self, device):
print("Initialize the pose2image model...")
model = create_model('ControlNet/models/cldm_v15.yaml', device=device).to(device)
model.load_state_dict(load_state_dict('ControlNet/models/control_sd15_openpose.pth', location='mps'))
self.model = model.to(device)
self.device = device
self.ddim_sampler = DDIMSampler(self.model)
self.ddim_steps = 20
self.image_resolution = 512
self.num_samples = 1
self.save_memory = False
self.strength = 1.0
self.guess_mode = False
self.scale = 9.0
self.seed = -1
self.a_prompt = 'best quality, extremely detailed'
self.n_prompt = 'longbody, lowres, bad anatomy, bad hands, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality'
def inference(self, inputs):
print("===>Starting pose2image Inference")
image_path, instruct_text = inputs.split(",")[0], ','.join(inputs.split(',')[1:])
image = Image.open(image_path)
image = np.array(image)
prompt = instruct_text
img = resize_image(HWC3(image), self.image_resolution)
H, W, C = img.shape
img = cv2.resize(img, (W, H), interpolation=cv2.INTER_NEAREST)
control = torch.from_numpy(img.copy()).float().to(device=self.device) / 255.0
control = torch.stack([control for _ in range(self.num_samples)], dim=0)
control = einops.rearrange(control, 'b h w c -> b c h w').clone()
self.seed = random.randint(0, 65535)
seed_everything(self.seed)
if self.save_memory:
self.model.low_vram_shift(is_diffusing=False)
cond = {"c_concat": [control], "c_crossattn": [ self.model.get_learned_conditioning([prompt + ', ' + self.a_prompt] * self.num_samples)]}
un_cond = {"c_concat": None if self.guess_mode else [control], "c_crossattn": [self.model.get_learned_conditioning([self.n_prompt] * self.num_samples)]}
shape = (4, H // 8, W // 8)
self.model.control_scales = [self.strength * (0.825 ** float(12 - i)) for i in range(13)] if self.guess_mode else ([self.strength] * 13)
samples, intermediates = self.ddim_sampler.sample(self.ddim_steps, self.num_samples, shape, cond, verbose=False, eta=0., unconditional_guidance_scale=self.scale, unconditional_conditioning=un_cond)
if self.save_memory:
self.model.low_vram_shift(is_diffusing=False)
x_samples = self.model.decode_first_stage(samples)
x_samples = (einops.rearrange(x_samples, 'b c h w -> b h w c') * 127.5 + 127.5).cuda().numpy().clip(0, 255).astype(np.uint8)
updated_image_path = get_new_image_name(image_path, func_name="pose2image")
real_image = Image.fromarray(x_samples[0]) # default the index0 image
real_image.save(updated_image_path)
return updated_image_path
class image2seg:
def __init__(self):
print("Direct segmentations.")
self.detector = UniformerDetector()
self.resolution = 512
def inference(self, inputs):
print("===>Starting image2seg Inference")
image = Image.open(inputs)
image = np.array(image)
image = HWC3(image)
detected_map = self.detector(resize_image(image, self.resolution))
detected_map = HWC3(detected_map)
image = resize_image(image, self.resolution)
H, W, C = image.shape
detected_map = cv2.resize(detected_map, (W, H), interpolation=cv2.INTER_LINEAR)
updated_image_path = get_new_image_name(inputs, func_name="segmentation")
image = Image.fromarray(detected_map)
image.save(updated_image_path)
return updated_image_path
class seg2image:
def __init__(self, device):
print("Initialize the seg2image model...")
model = create_model('ControlNet/models/cldm_v15.yaml', device=device).to(device)
model.load_state_dict(load_state_dict('ControlNet/models/control_sd15_seg.pth', location='mps'))
self.model = model.to(device)
self.device = device
self.ddim_sampler = DDIMSampler(self.model)
self.ddim_steps = 20
self.image_resolution = 512
self.num_samples = 1
self.save_memory = False
self.strength = 1.0
self.guess_mode = False
self.scale = 9.0
self.seed = -1
self.a_prompt = 'best quality, extremely detailed'
self.n_prompt = 'longbody, lowres, bad anatomy, bad hands, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality'
def inference(self, inputs):
print("===>Starting seg2image Inference")
image_path, instruct_text = inputs.split(",")[0], ','.join(inputs.split(',')[1:])
image = Image.open(image_path)
image = np.array(image)
prompt = instruct_text
img = resize_image(HWC3(image), self.image_resolution)
H, W, C = img.shape
img = cv2.resize(img, (W, H), interpolation=cv2.INTER_NEAREST)
control = torch.from_numpy(img.copy()).float().to(device=self.device) / 255.0
control = torch.stack([control for _ in range(self.num_samples)], dim=0)
control = einops.rearrange(control, 'b h w c -> b c h w').clone()
self.seed = random.randint(0, 65535)
seed_everything(self.seed)
if self.save_memory:
self.model.low_vram_shift(is_diffusing=False)
cond = {"c_concat": [control], "c_crossattn": [self.model.get_learned_conditioning([prompt + ', ' + self.a_prompt] * self.num_samples)]}
un_cond = {"c_concat": None if self.guess_mode else [control], "c_crossattn": [self.model.get_learned_conditioning([self.n_prompt] * self.num_samples)]}
shape = (4, H // 8, W // 8)
self.model.control_scales = [self.strength * (0.825 ** float(12 - i)) for i in range(13)] if self.guess_mode else ([self.strength] * 13)
samples, intermediates = self.ddim_sampler.sample(self.ddim_steps, self.num_samples, shape, cond, verbose=False, eta=0., unconditional_guidance_scale=self.scale, unconditional_conditioning=un_cond)
if self.save_memory:
self.model.low_vram_shift(is_diffusing=False)
x_samples = self.model.decode_first_stage(samples)
x_samples = (einops.rearrange(x_samples, 'b c h w -> b h w c') * 127.5 + 127.5).cuda().numpy().clip(0, 255).astype(np.uint8)
updated_image_path = get_new_image_name(image_path, func_name="segment2image")
real_image = Image.fromarray(x_samples[0]) # default the index0 image
real_image.save(updated_image_path)
return updated_image_path
class image2depth:
def __init__(self):
print("Direct depth estimation.")
self.detector = MidasDetector()
self.resolution = 512
def inference(self, inputs):
print("===>Starting image2depth Inference")
image = Image.open(inputs)
image = np.array(image)
image = HWC3(image)
detected_map, _ = self.detector(resize_image(image, self.resolution))
detected_map = HWC3(detected_map)
image = resize_image(image, self.resolution)
H, W, C = image.shape
detected_map = cv2.resize(detected_map, (W, H), interpolation=cv2.INTER_LINEAR)
updated_image_path = get_new_image_name(inputs, func_name="depth")
image = Image.fromarray(detected_map)
image.save(updated_image_path)
return updated_image_path
class depth2image:
def __init__(self, device):
print("Initialize depth2image model...")
model = create_model('ControlNet/models/cldm_v15.yaml', device=device).to(device)
model.load_state_dict(load_state_dict('ControlNet/models/control_sd15_depth.pth', location='mps'))
self.model = model.to(device)
self.device = device
self.ddim_sampler = DDIMSampler(self.model)
self.ddim_steps = 20
self.image_resolution = 512
self.num_samples = 1
self.save_memory = False
self.strength = 1.0
self.guess_mode = False
self.scale = 9.0
self.seed = -1
self.a_prompt = 'best quality, extremely detailed'
self.n_prompt = 'longbody, lowres, bad anatomy, bad hands, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality'
def inference(self, inputs):
print("===>Starting depth2image Inference")
image_path, instruct_text = inputs.split(",")[0], ','.join(inputs.split(',')[1:])
image = Image.open(image_path)
image = np.array(image)
prompt = instruct_text
img = resize_image(HWC3(image), self.image_resolution)
H, W, C = img.shape
img = cv2.resize(img, (W, H), interpolation=cv2.INTER_NEAREST)
control = torch.from_numpy(img.copy()).float().to(device=self.device) / 255.0
control = torch.stack([control for _ in range(self.num_samples)], dim=0)
control = einops.rearrange(control, 'b h w c -> b c h w').clone()
self.seed = random.randint(0, 65535)
seed_everything(self.seed)
if self.save_memory:
self.model.low_vram_shift(is_diffusing=False)
cond = {"c_concat": [control], "c_crossattn": [ self.model.get_learned_conditioning([prompt + ', ' + self.a_prompt] * self.num_samples)]}
un_cond = {"c_concat": None if self.guess_mode else [control], "c_crossattn": [self.model.get_learned_conditioning([self.n_prompt] * self.num_samples)]}
shape = (4, H // 8, W // 8)
self.model.control_scales = [self.strength * (0.825 ** float(12 - i)) for i in range(13)] if self.guess_mode else ([self.strength] * 13) # Magic number. IDK why. Perhaps because 0.825**12<0.01 but 0.826**12>0.01
samples, intermediates = self.ddim_sampler.sample(self.ddim_steps, self.num_samples, shape, cond, verbose=False, eta=0., unconditional_guidance_scale=self.scale, unconditional_conditioning=un_cond)
if self.save_memory:
self.model.low_vram_shift(is_diffusing=False)
x_samples = self.model.decode_first_stage(samples)
x_samples = (einops.rearrange(x_samples, 'b c h w -> b h w c') * 127.5 + 127.5).cuda().numpy().clip(0, 255).astype(np.uint8)
updated_image_path = get_new_image_name(image_path, func_name="depth2image")
real_image = Image.fromarray(x_samples[0]) # default the index0 image
real_image.save(updated_image_path)
return updated_image_path
class image2normal:
def __init__(self):
print("Direct normal estimation.")
self.detector = MidasDetector()
self.resolution = 512
self.bg_threshold = 0.4
def inference(self, inputs):
print("===>Starting image2 normal Inference")
image = Image.open(inputs)
image = np.array(image)
image = HWC3(image)
_, detected_map = self.detector(resize_image(image, self.resolution), bg_th=self.bg_threshold)
detected_map = HWC3(detected_map)
image = resize_image(image, self.resolution)
H, W, C = image.shape
detected_map = cv2.resize(detected_map, (W, H), interpolation=cv2.INTER_LINEAR)
updated_image_path = get_new_image_name(inputs, func_name="normal-map")
image = Image.fromarray(detected_map)
image.save(updated_image_path)
return updated_image_path
class normal2image:
def __init__(self, device):
print("Initialize normal2image model...")
model = create_model('ControlNet/models/cldm_v15.yaml', device=device).to(device)
model.load_state_dict(load_state_dict('ControlNet/models/control_sd15_normal.pth', location='mps'))
self.model = model.to(device)
self.device = device
self.ddim_sampler = DDIMSampler(self.model)
self.ddim_steps = 20
self.image_resolution = 512
self.num_samples = 1
self.save_memory = False
self.strength = 1.0
self.guess_mode = False
self.scale = 9.0
self.seed = -1
self.a_prompt = 'best quality, extremely detailed'
self.n_prompt = 'longbody, lowres, bad anatomy, bad hands, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality'
def inference(self, inputs):
print("===>Starting normal2image Inference")
image_path, instruct_text = inputs.split(",")[0], ','.join(inputs.split(',')[1:])
image = Image.open(image_path)
image = np.array(image)
prompt = instruct_text
img = image[:, :, ::-1].copy()
img = resize_image(HWC3(img), self.image_resolution)
H, W, C = img.shape
img = cv2.resize(img, (W, H), interpolation=cv2.INTER_NEAREST)
control = torch.from_numpy(img.copy()).float().to(device=self.device) / 255.0
control = torch.stack([control for _ in range(self.num_samples)], dim=0)
control = einops.rearrange(control, 'b h w c -> b c h w').clone()
self.seed = random.randint(0, 65535)
seed_everything(self.seed)
if self.save_memory:
self.model.low_vram_shift(is_diffusing=False)
cond = {"c_concat": [control], "c_crossattn": [self.model.get_learned_conditioning([prompt + ', ' + self.a_prompt] * self.num_samples)]}
un_cond = {"c_concat": None if self.guess_mode else [control], "c_crossattn": [self.model.get_learned_conditioning([self.n_prompt] * self.num_samples)]}
shape = (4, H // 8, W // 8)
self.model.control_scales = [self.strength * (0.825 ** float(12 - i)) for i in range(13)] if self.guess_mode else ([self.strength] * 13)
samples, intermediates = self.ddim_sampler.sample(self.ddim_steps, self.num_samples, shape, cond, verbose=False, eta=0., unconditional_guidance_scale=self.scale, unconditional_conditioning=un_cond)
if self.save_memory:
self.model.low_vram_shift(is_diffusing=False)
x_samples = self.model.decode_first_stage(samples)
x_samples = (einops.rearrange(x_samples, 'b c h w -> b h w c') * 127.5 + 127.5).cuda().numpy().clip(0, 255).astype(np.uint8)
updated_image_path = get_new_image_name(image_path, func_name="normal2image")
real_image = Image.fromarray(x_samples[0]) # default the index0 image
real_image.save(updated_image_path)
return updated_image_path
class BLIPVQA:
def __init__(self, device):
print("Initializing BLIP VQA to %s" % device)
self.device = device
self.processor = BlipProcessor.from_pretrained("Salesforce/blip-vqa-base")
self.model = BlipForQuestionAnswering.from_pretrained("Salesforce/blip-vqa-base").to(self.device)
def get_answer_from_question_and_image(self, inputs):
image_path, question = inputs.split(",")
raw_image = Image.open(image_path).convert('RGB')
print(F'BLIPVQA :question :{question}')
inputs = self.processor(raw_image, question, return_tensors="pt").to(self.device)
out = self.model.generate(**inputs)
answer = self.processor.decode(out[0], skip_special_tokens=True)
return answer
class ConversationBot:
def __init__(self):
print("Initializing VisualChatGPT")
self.llm = OpenAI(temperature=0)
#self.edit = ImageEditing(device="mps")
self.i2t = ImageCaptioning(device="mps")
self.t2i = T2I(device="mps")
# self.image2canny = image2canny()
# self.canny2image = canny2image(device="mps")
# self.image2line = image2line()
# self.line2image = line2image(device="mps")
# self.image2hed = image2hed()
# self.hed2image = hed2image(device="mps")
# self.image2scribble = image2scribble()
# self.scribble2image = scribble2image(device="mps")
# self.image2pose = image2pose()
# self.pose2image = pose2image(device="mps")
# self.BLIPVQA = BLIPVQA(device="mps")
# self.image2seg = image2seg()
# self.seg2image = seg2image(device="mps")
# self.image2depth = image2depth()
# self.depth2image = depth2image(device="mps")
# self.image2normal = image2normal()
# self.normal2image = normal2image(device="mps")
#self.pix2pix = Pix2Pix(device="mps")
self.memory = ConversationBufferMemory(memory_key="chat_history", output_key='output')
self.tools = [
Tool(name="Get Photo Description", func=self.i2t.inference,
description="useful when you want to know what is inside the photo. receives image_path as input. "
"The input to this tool should be a string, representing the image_path. "),
Tool(name="Generate Image From User Input Text", func=self.t2i.inference,
description="useful when you want to generate an image from a user input text and save it to a file. like: generate an image of an object or something, or generate an image that includes some objects. "
"The input to this tool should be a string, representing the text used to generate image. "),
# Tool(name="Get Photo Description", func=self.i2t.inference,
# description="useful when you want to know what is inside the photo. receives image_path as input. "
# "The input to this tool should be a string, representing the image_path. "),
# Tool(name="Generate Image From User Input Text", func=self.t2i.inference,
# description="useful when you want to generate an image from a user input text and save it to a file. like: generate an image of an object or something, or generate an image that includes some objects. "
# "The input to this tool should be a string, representing the text used to generate image. "),
# Tool(name="Remove Something From The Photo", func=self.edit.remove_part_of_image,
# description="useful when you want to remove and object or something from the photo from its description or location. "
# "The input to this tool should be a comma seperated string of two, representing the image_path and the object need to be removed. "),
# Tool(name="Replace Something From The Photo", func=self.edit.replace_part_of_image,
# description="useful when you want to replace an object from the object description or location with another object from its description. "
# "The input to this tool should be a comma seperated string of three, representing the image_path, the object to be replaced, the object to be replaced with "),
# Tool(name="Instruct Image Using Text", func=self.pix2pix.inference,
# description="useful when you want to the style of the image to be like the text. like: make it look like a painting. or make it like a robot. "
# "The input to this tool should be a comma seperated string of two, representing the image_path and the text. "),
# Tool(name="Answer Question About The Image", func=self.BLIPVQA.get_answer_from_question_and_image,
# description="useful when you need an answer for a question based on an image. like: what is the background color of the last image, how many cats in this figure, what is in this figure. "
# "The input to this tool should be a comma seperated string of two, representing the image_path and the question"),
# Tool(name="Edge Detection On Image", func=self.image2canny.inference,
# description="useful when you want to detect the edge of the image. like: detect the edges of this image, or canny detection on image, or peform edge detection on this image, or detect the canny image of this image. "
# "The input to this tool should be a string, representing the image_path"),
# Tool(name="Generate Image Condition On Canny Image", func=self.canny2image.inference,
# description="useful when you want to generate a new real image from both the user desciption and a canny image. like: generate a real image of a object or something from this canny image, or generate a new real image of a object or something from this edge image. "
# "The input to this tool should be a comma seperated string of two, representing the image_path and the user description. "),
# Tool(name="Line Detection On Image", func=self.image2line.inference,
# description="useful when you want to detect the straight line of the image. like: detect the straight lines of this image, or straight line detection on image, or peform straight line detection on this image, or detect the straight line image of this image. "
# "The input to this tool should be a string, representing the image_path"),
# Tool(name="Generate Image Condition On Line Image", func=self.line2image.inference,
# description="useful when you want to generate a new real image from both the user desciption and a straight line image. like: generate a real image of a object or something from this straight line image, or generate a new real image of a object or something from this straight lines. "
# "The input to this tool should be a comma seperated string of two, representing the image_path and the user description. "),
# Tool(name="Hed Detection On Image", func=self.image2hed.inference,
# description="useful when you want to detect the soft hed boundary of the image. like: detect the soft hed boundary of this image, or hed boundary detection on image, or peform hed boundary detection on this image, or detect soft hed boundary image of this image. "
# "The input to this tool should be a string, representing the image_path"),
# Tool(name="Generate Image Condition On Soft Hed Boundary Image", func=self.hed2image.inference,
# description="useful when you want to generate a new real image from both the user desciption and a soft hed boundary image. like: generate a real image of a object or something from this soft hed boundary image, or generate a new real image of a object or something from this hed boundary. "
# "The input to this tool should be a comma seperated string of two, representing the image_path and the user description"),
# Tool(name="Segmentation On Image", func=self.image2seg.inference,
# description="useful when you want to detect segmentations of the image. like: segment this image, or generate segmentations on this image, or peform segmentation on this image. "
# "The input to this tool should be a string, representing the image_path"),
# Tool(name="Generate Image Condition On Segmentations", func=self.seg2image.inference,
# description="useful when you want to generate a new real image from both the user desciption and segmentations. like: generate a real image of a object or something from this segmentation image, or generate a new real image of a object or something from these segmentations. "
# "The input to this tool should be a comma seperated string of two, representing the image_path and the user description"),
# Tool(name="Predict Depth On Image", func=self.image2depth.inference,
# description="useful when you want to detect depth of the image. like: generate the depth from this image, or detect the depth map on this image, or predict the depth for this image. "
# "The input to this tool should be a string, representing the image_path"),
# Tool(name="Generate Image Condition On Depth", func=self.depth2image.inference,
# description="useful when you want to generate a new real image from both the user desciption and depth image. like: generate a real image of a object or something from this depth image, or generate a new real image of a object or something from the depth map. "
# "The input to this tool should be a comma seperated string of two, representing the image_path and the user description"),
# Tool(name="Predict Normal Map On Image", func=self.image2normal.inference,
# description="useful when you want to detect norm map of the image. like: generate normal map from this image, or predict normal map of this image. "
# "The input to this tool should be a string, representing the image_path"),
# Tool(name="Generate Image Condition On Normal Map", func=self.normal2image.inference,
# description="useful when you want to generate a new real image from both the user desciption and normal map. like: generate a real image of a object or something from this normal map, or generate a new real image of a object or something from the normal map. "
# "The input to this tool should be a comma seperated string of two, representing the image_path and the user description"),
# Tool(name="Sketch Detection On Image", func=self.image2scribble.inference,
# description="useful when you want to generate a scribble of the image. like: generate a scribble of this image, or generate a sketch from this image, detect the sketch from this image. "
# "The input to this tool should be a string, representing the image_path"),
# Tool(name="Generate Image Condition On Sketch Image", func=self.scribble2image.inference,
# description="useful when you want to generate a new real image from both the user desciption and a scribble image or a sketch image. "
# "The input to this tool should be a comma seperated string of two, representing the image_path and the user description"),
# Tool(name="Pose Detection On Image", func=self.image2pose.inference,
# description="useful when you want to detect the human pose of the image. like: generate human poses of this image, or generate a pose image from this image. "
# "The input to this tool should be a string, representing the image_path"),
# Tool(name="Generate Image Condition On Pose Image", func=self.pose2image.inference,
# description="useful when you want to generate a new real image from both the user desciption and a human pose image. like: generate a real image of a human from this human pose image, or generate a new real image of a human from this pose. "
# "The input to this tool should be a comma seperated string of two, representing the image_path and the user description")
]
self.agent = initialize_agent(
self.tools,
self.llm,
agent="conversational-react-description",
verbose=True,
memory=self.memory,
return_intermediate_steps=True,
agent_kwargs={'prefix': VISUAL_CHATGPT_PREFIX, 'format_instructions': VISUAL_CHATGPT_FORMAT_INSTRUCTIONS, 'suffix': VISUAL_CHATGPT_SUFFIX}, )
def run_text(self, text, state):
print("===============Running run_text =============")
print("Inputs:", text, state)
print("======>Previous memory:\n %s" % self.agent.memory)
#self.agent.memory.buffer = cut_dialogue_history(self.agent.memory.buffer, keep_last_n_words=500)
res = self.agent({"input": text})
print("======>Current memory:\n %s" % self.agent.memory)
response = re.sub('(image/\S*png)', lambda m: f'})*{m.group(0)}*', res['output'])
state = state + [(text, response)]
print("Outputs:", state)
return state, state
def run_image(self, image, state, txt):
print("===============Running run_image =============")
print("Inputs:", image, state)
print("======>Previous memory:\n %s" % self.agent.memory)
image_filename = os.path.join('image', str(uuid.uuid4())[0:8] + ".png")
print("======>Auto Resize Image...")
img = Image.open(image.name)
width, height = img.size
ratio = min(512 / width, 512 / height)
width_new, height_new = (round(width * ratio), round(height * ratio))
img = img.resize((width_new, height_new))
img = img.convert('RGB')
img.save(image_filename, "PNG")
print(f"Resize image form {width}x{height} to {width_new}x{height_new}")
description = self.i2t.inference(image_filename)
Human_prompt = "\nHuman: provide a figure named {}. The description is: {}. This information helps you to understand this image, but you should use tools to finish following tasks, " \
"rather than directly imagine from my description. If you understand, say \"Received\". \n".format(image_filename, description)
AI_prompt = "Received. "
#self.agent.memory.buffer = self.agent.memory.buffer + Human_prompt + 'AI: ' + AI_prompt
self.agent.memory.buffer.save_context({"input": Human_prompt}, {"output": AI_prompt})
print("======>Current memory:\n %s" % self.agent.memory)
state = state + [(f"*{image_filename}*", AI_prompt)]
print("Outputs:", state)
return state, state, txt + ' ' + image_filename + ' '
if __name__ == '__main__':
bot = ConversationBot()
with gr.Blocks(css="#chatbot .overflow-y-auto{height:500px}") as demo:
chatbot = gr.Chatbot(elem_id="chatbot", label="Visual ChatGPT")
state = gr.State([])
with gr.Row():
with gr.Column(scale=0.7):
txt = gr.Textbox(show_label=False, placeholder="Enter text and press enter, or upload an image").style(container=False)
with gr.Column(scale=0.15, min_width=0):
clear = gr.Button("Clear️")
with gr.Column(scale=0.15, min_width=0):
btn = gr.UploadButton("Upload", file_types=["image"])
txt.submit(bot.run_text, [txt, state], [chatbot, state])
txt.submit(lambda: "", None, txt)
btn.upload(bot.run_image, [btn, state, txt], [chatbot, state, txt])
clear.click(bot.memory.clear)
clear.click(lambda: [], None, chatbot)
clear.click(lambda: [], None, state)
demo.launch(server_name="0.0.0.0", server_port=7860)
注意,以上代码是修改了MPS模式、langchain库bug以及屏蔽了多个模型后的修改版本。
运行Visual ChatGPT
折腾了大半天,终于可以无错误运行了:
python3 visual_chatgpt.py
程序返回:
➜ visual-chatgpt git:(main) ✗ python visual_chatgpt.py
Initializing VisualChatGPT
Initializing ImageCaptioning to mps
Initializing T2I to mps
/opt/homebrew/lib/python3.10/site-packages/transformers/models/clip/feature_extraction_clip.py:28: FutureWarning: The class CLIPFeatureExtractor is deprecated and will be removed in version 5 of Transformers. Please use CLIPImageProcessor instead.
warnings.warn(
Running on local URL: http://0.0.0.0:7860
编程的乐趣就在于,当你为了运行某个程序经历了千难万险,甚至濒临绝望的时候,突然,程序调通了,此时大脑皮层会大量分泌多巴胺(dopamine),那感觉,就像突然领悟了人生妙谛,又像是终于明白了天人化生、万物滋长的要道,简而言之,白日飞升,快乐加倍,那种精神上的享受,绝对比玩电子游戏或者享受美食更加的高级。
随后访问http://localhost:7860:

直接用中文开聊即可,不需要ControlNet那些令人厌烦的引导词。
后台程序逻辑:
Inputs: 给我一只大金毛 []
======>Previous memory:
chat_memory=ChatMessageHistory(messages=[]) output_key='output' input_key=None return_messages=False human_prefix='Human' ai_prefix='AI' memory_key='chat_history'
> Entering new AgentExecutor chain...
Yes
Action: Generate Image From User Input Text
Action Input: A golden retrieverSetting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
A golden retriever refined to A golden retriever,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,
100%|█████████████████████████████████████████████████████████████████████████████████| 50/50 [00:47<00:00, 1.05it/s]
Processed T2I.run, text: A golden retriever, image_filename: image/865c561f.png
Observation: image/865c561f.png
Thought: Do I need to use a tool? No
AI: Here is a golden retriever for you: image/865c561f.png
> Finished chain.
======>Current memory:
chat_memory=ChatMessageHistory(messages=[HumanMessage(content='给我一只大金毛', additional_kwargs={}), AIMessage(content='Here is a golden retriever for you: image/865c561f.png', additional_kwargs={})]) output_key='output' input_key=None return_messages=False human_prefix='Human' ai_prefix='AI' memory_key='chat_history'
Outputs: [('给我一只大金毛', 'Here is a golden retriever for you: *image/865c561f.png*')]
通过观察,我们可以得知,虽然是中文聊天,但其实ChatGPT会把中文翻译为英文,将“给我一只大金毛”翻译为:“a golden retriever”。
随后通过模型训练生成图片,再将聊天记录添加到上下文列表中,关于ChatGPT的聊天上下文,请参照:重新定义性价比!人工智能AI聊天ChatGPT新接口模型gpt-3.5-turbo闪电更新,成本降90%,Python3.10接入
当然,为了可以线下单机环境将Visual ChatGPT成功跑起来,所以屏蔽了多个ControlNet图像模型,因此有些图片场景并不那么尽如人意:
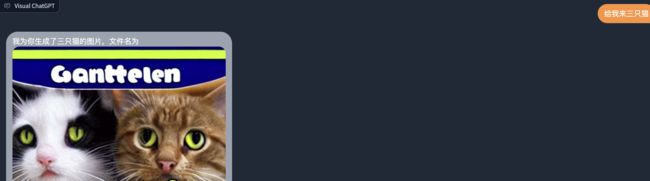
结语
有的时候,当我们称赞一项技术的时候,我们会称其为这样或者那样的行业标杆、教科书之类,但是对于ChatGPT来说,它已经超越了所谓的什么标杆,或者说得更准确一些,它是标杆中的标杆,其他的所谓的类ChatGPT产品,别说望其项背了,就连ChatGPT的尾气也闻不到,说白了,想碰瓷都不知道该怎么碰,因为神明早已在ChatGPT的命格中写下八个大字:前无古人,后无来者!最后,奉上修改后的项目代码,与众乡亲同飨:github.com/zcxey2911/visual_chatgpt_mps_cut