一场江湖恩怨从「聚合数据」说起——第五篇

清风的第 05 篇 Flink SQL 分享
中标了,中标了,中标了。
一大早,刚打开邮箱,跳入眼帘的是“实时计算大数据平台”中标喜报。
李回想本次中标的过程,真是来之不易。商务标大家几乎打成平手,势均力敌,技术标主要是靠三个方法微胜竞争对手。
第一个方法是 MiniBatch 做优化。
第二个方法是 LocalGlobal 做优化。
第三个方法是用 Split Distinct 做优化。
三招治敌,人生的关键点绝不能再掉链子!
01 临危受命
这是一场江湖的恩怨。
年底的部门绩效考核,按照合同金额考核,还差几百万,这几百万业绩指标,决定了部门几百人是开开心心拿着几个月年终奖过大年,还是垂头丧气白白辛苦一年,提心吊胆等着公司裁员的大锤抡下来。
有人的地方就有江湖,有江湖的地方就有恩怨,有恩怨的地方就会有斗争,有斗争就会有人出局。能否拿下这个项目,成了一把达摩克里斯剑悬在李的部门头上。
胜则举杯相庆,败则落井下石。
李所在部门老大,广发英雄帖,挑选敢接这个项目的敢死队。李这个愣头青不知个中厉害,以为这是个天将降大任于斯人也的天机,跑到领导办公室去揭榜了。
向使李爱八卦一点,打听打听其他部门的风声,必然会拒这个项目于千里之外。然,人常说祸兮福兮,危机危机,有危才有机。
揭榜后的第二天,李就有模有样的把项目团队给搭建起来了,还真有点雷厉风行的味道。与部门内部大家伙磨拳擦掌不同,另外几个部门则冷眼看着,静待笑话的发生,因为大家都很聪明,这个项目就是一个天坑,谁跳进去能爬出来就见鬼了,即使侥幸爬出这个坑,不死也得脱层皮。
这个项目的主要挑战在于:
第一点,戴着脚镣跳舞。项目一期是其他供应商交付的,客户不满意,二期的时候明确不让该供应商继续交付,但后续交付的供应商不能完全把一期的建设内容全部推翻,不然领导没法向上交代。
第二点,是勇士也是烈士。业界还没有成熟的方案,落地案例很少,换句话说这是一个吃螃蟹的项目,成了就是英雄,败了就是烈士。
第三点,钱少事多。客户是一个很强势的客户,和之前供应商了解到的是他们需求无边无际,经常是领导一句话,需求就变更了,不给钱但喜欢画饼,总在说做得好还有下一期可以做,这一期只是我们预算的一个零头。
疫情之下,大家明明知道这个项目是一瓶毒药,但还是忍不住要来抢着喝,抢到了,虽然会中毒,但万一后面有解药呢。不抢,则会死在裁员的路上。所以即便这样,也仍然吸引了好多家供应商参与。
正如一个网友所说:
灰云惨惨日光白,柳线依依气运衰。
生机潜在泥土里,只待好风吹便开。
熬过了寒冬,就是我花开时百花刹。
不入虎穴,焉得虎子。
02 攻坚克难
一月,李和部门其他同事,离开温暖的南方都市,前往正大雪纷飞的京城,来到了客户现场。
在客户提出的一干需求中,有一个需求的场景是这样的:
指标说明:量比是衡量相对成交量的指标。它是指股市开市后平均每分钟的成交量与过去 5 个交易日平均每分钟成交量之比。
计算公式:量比 = 前 N 分钟平均交易量 / 前 5 日平均每分钟交易量。这里的 N 支持用参数传入的方式实现。
应用场景:这个指标所反映出来的是当前盘口的成交力度与最近五天的成交力度的差别,这个差别的值越大表明盘口成交越趋活跃,从某种意义上讲,越能体现主力即时做盘,准备随时展开攻击前蠢蠢欲动的盘口特征。短线操作时参考较多。
参加本次项目 POC 测试的供应商有五家,除了李所在公司,其他四家皆有成熟的产品,丰富的落地案例,齐整的研发队伍,反观李所在部门,产品还是一个半成品,PPT 的方案则是吹得天花乱坠,队伍也是残缺不全,没有专门的产品经理,没有专门的项目经理,没有专门的架构师,整一个人人都是产品经理,人人都是项目经理,人人都是架构师。
就这半吊子的队伍,还需要外拿项目,内防其他部门背后捅刀。
五天的 POC 测试时间,不会有一丝空闲时间让大家有过多的空闲,必须是起步就是冲刺,开局就是决战。
分析完 POC 场景后,李提出如下技术方案:
第一种方案是使用 Flink SQL 直接实现。
第二种方案是使用 Java 代码编写,开启 MiniBatch 优化,提升性能。
第一种方案较简单,具体的实现这里不再展开,源码参考:https://github.com/cjjxfli/real-datawarehouse-cookbook.git/flinksql/05_flink_sql_aggregating_data.sql
第二种方案的实现原理说明如下:
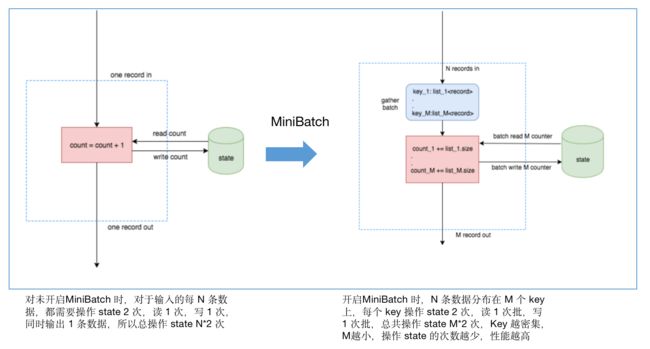
实现原理:MiniBatch 优化的核心思想是缓冲输入记录微批处理以减少对状态的访问,进而提升吞吐并减少数据的输出。
适用场景:仅适用于优化 GROUP BY,Flink SQL 流模式下,每来一条数据都会执行 State 操作,I/O 消耗较大。设置 miniBatch 后,同一个 Key 的一批数据只访问一次 State,且只输出最新的一条数据,既减少了 State 访问也减少了下游的数据更新。
说明:当前 MiniBatch 支持无限流 GroupBy 和无限流 Proctime Over Window,如果任务有热 Key,则非常适合启用 MiniBatch 优化, 一些任务启用了 MiniBatch,往下游发送的数据比原有少了约2个数量级。原因如下图所示:
java 源码参考:
Configuration configuration = tEnv.getConfig().getConfiguration();
configuration.setString("table.exec.mini-batch.enabled", "true");
configuration.setString("table.exec.mini-batch.allow-latency", "3 s");
configuration.setString("table.exec.mini-batch.size", "5000");
configuration.setString("table.optimizer.agg-phase-strategy", "ONE_PHASE");
完整代码参考:https://github.com/cjjxfli/real-datawarehouse-cookbook.git/flinktable/MiniBatchOptimization.java
对于数据倾斜这种情况,李还提出了下面的优化方案。
使用 LocalGlobal 解决聚合时的数据倾斜问题。
核心思想:将聚合分为两个阶段执行,先在上游进行局部(本地/Local)聚合,再在下游进行全局(Global)聚合,类似 MapReduce 的 Combine + Reduce,即先进行一个本地 Reduce,再进行全局 Reduce。
适用场景:LocalGlobal 优化针对普通聚合(例如 SUM、COUNT、MAX、MIN 和 AVG)有较好的效果,对于 COUNT DISTINCT 收效不明显,因为 COUNT DISTINCT 在 Local 聚合时,对于 DISTINCT KEY 的去重率不高,导致在 Global 节点仍然存在热点。
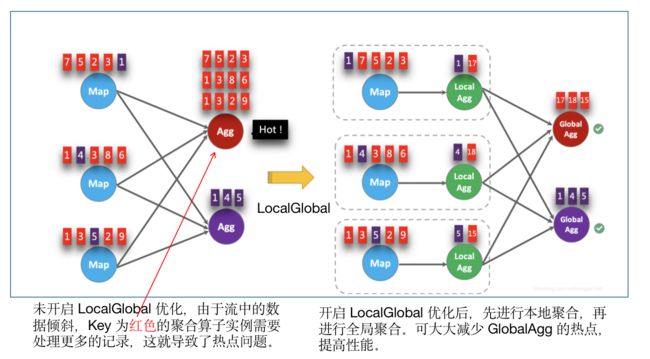
由上图可知:未开启 LocalGlobal 优化,由于流中的数据倾斜,Key 为红色的聚合算子实例需要处理更多的记录,这就导致了热点问题。
开启 LocalGlobal 优化后,先进行本地聚合,再进行全局聚合。可大大减少 GlobalAgg 的热点,提高性能。
LocalGlobal 优化需要先开启 MiniBatch,依赖于 MiniBatch 的参数。
table.optimizer.agg-phase-strategy: 聚合策略。默认 AUTO,支持参数 AUTO、TWO_PHASE(使用 LocalGlobal 两阶段聚合)、ONE_PHASE(仅使用 Global 一阶段聚合)。
相关的源码参考:
// 开启MiniBatch
configuration.setString("table.exec.mini-batch.enabled", "true");
configuration.setString("table.exec.mini-batch.allow-latency", "3 s");
configuration.setString("table.exec.mini-batch.size", "5000");
// 开启LocalGlobal
configuration.setString("table.optimizer.agg-phase-strategy", "TWO_PHASE");
完整代码参考 GitHub:https://github.com/cjjxfli/real-datawarehouse-cookbook.git/flinktable/LocalGlobalOptimization.java
在部分计算场景中,需要将股票代码进行去重统计,这就需要用到 COUNT DISTINCT,这会出现热点问题,对于这个问题,李提出可以用 Split Distinct 进行优化。
使用 Split Distinct 解决去重场景数据倾斜问题
核心思想:COUNT DISTINCT自动打散,将原始聚合拆分层两层聚合。
适用场景:Split Distinct优化可以用来解决COUNT DISTINCT的热点问题。在 FLink1.9.0 版本前需要手动编写打散功能,如使用 MOD(HASH_CODE(stock_code), 1024)。在 FLink1.9.0 后的版本,框架支持自动打散优化。
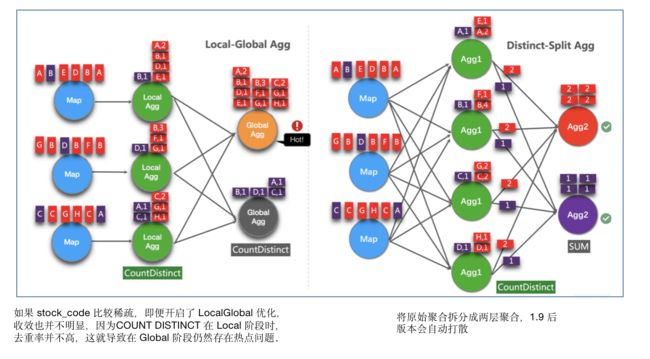
参数说明:
table.optimizer.distinct-agg.split.enabled: 启用Split Distinct优化。默认false,开启需要设置为true
table.optimizer.distinct-agg.split.bucket-num: Split Distinct优化在第一层聚合中,被拆分的bucket数目。默认1024。
参考代码:
// 开启MiniBatch
configuration.setString("table.exec.mini-batch.enabled", "true");
configuration.setString("table.exec.mini-batch.allow-latency", "3 s");
configuration.setString("table.exec.mini-batch.size", "5000");
// 开启LocalGlobal
configuration.setString("table.optimizer.agg-phase-strategy", "TWO_PHASE");
// 开启Split Distinct
configuration.setString("table.optimizer.distinct-agg.split.enabled", "true");
完整代码参考 GitHub:https://github.com/cjjxfli/real-datawarehouse-cookbook.git/flinktable/SplitDistinctOptimization.java
03 狭路相逢勇者胜

在讲标的过程中,李特意提到了 FlinkSQL 流式聚合中的三个优化方法:
(1)MiniBatch 通过缓冲输入记录微批处理以减少对状态的访问,进而提升吞吐并减少数据的输出 。
(2)LocalGlobal 将聚合分为两个阶段执行,先在上游进行局部(本地/ Local)聚合,再在下游进行全局(Global)聚合,提升如 SUM、COUNT、MAX、MIN 和 AVG 的性能。
(3)Split Distinct通过COUNT DISTINCT自动打散,将原始聚合拆分层两层聚合,解决COUNT DISTINCT的热点问题。
评委在听完汇报后,一致认为这种优化思路有可行性,在其他指标的计算过程中也可以如法炮制。最后给了一个最高分,项目最终以微弱优势胜出。
胜者为王败者寇,妩媚仅予凯旋君。
中标后,部门大会上,领导表扬了李,其他部门的同事则纷纷表达出羡慕之情。
此刻,李的心情只能用《七律·长征》来形容了:
红军不怕远征难,万水千山只等闲。
五岭逶迤腾细浪,乌蒙磅礴走泥丸。
金沙水拍云崖暖,大渡桥横铁索寒。
更喜岷山千里雪,三军过后尽开颜。
欢颜过后,李的心平静了下来。无人理睬时,坚定执着; 有人羡慕时,心如止水。
当大家还沉浸在中标的喜悦中时,李已经开始思考如何交付这个项目了。欲知后事如何,且听下回分解。
笔者公众号:数据中台知行合一,不定时的写一些技术类文章,感兴趣的朋友可以扫码关注或微信公众号搜索:数据中台知行合一
今天的分享就到这里,如果您觉得有用的话,记得关注哦,关注后才能第一时间看到清风君的每周分享。
<===> END <===>
