特征处理总结
目录
- 1. 特征类别
- 2. 数值特征
-
- 2.1 稠密向量
- 2.1 数据离散化
-
- 2.1.1 等距分桶
- 2.1.2 等频分桶
- 3. 类别特征
-
- 3.1 单值类别特征
-
- 3.1.1 one-hot编码
- 3.1.2 标签编码LabelEncoder
- 3.2 多值类别特征
- 4. 序列特征
基于Jupyter的特征工程手册
1. 特征类别
常见的特征类型有:
- 静态连续变量,数值特征预处理
- 静态类别变量,单值|多值类别特征的类别特征预处理
- 时间序列特征数据预处理
数据预处理部分:介绍了如何利用 scikit-learn 处理静态的连续变量,利用 Category Encoders 处理静态的类别变量以及利用 Featuretools 处理常见的时间序列变量。
2. 数值特征
数值特征最为常见,如一些统计类特征:ctr、click_num等。稠密特征加入模型的方法
2.1 稠密向量
- 特征截断:异常值可能直接影响特征处理之后的结果,这种情况下,使用特征截断,移除异常值,可以使特征的准确性更高,截断这里涉及到异常值检测。
- 数据平滑:对于比值型特征,小分母计算得到的特征值更不稳定,置信度低,这时候需要将数据进行平滑处理,使其更接近真实值。
比如对于ctr特征,有以下三个case:- case1:曝光100,点击3
- case2:曝光10000,点击300
- case3:曝光100000,点击3000。
很明显,case3计算得到的ctr会更接近真实值,因为曝光基数足够大。
- 数据归一化:需要: 基于参数的模型或基于距离的模型,都是要进行特征的归一化。
不需要:基于树的方法是不需要进行特征的归一化,例如随机森林,bagging 和 boosting等。
1. Min-Max标准化
import numpy as np
from sklearn import preprocessing
x = np.array([1.,2.,3.],[2.,0.,0.],[0.,1.,-1])
x_max_min_scaled = preprocessing.MinMaxScaler().fit_transform(x)
2. z-score标准化:
前提是特征值服从正态分布,标准化后,其转换成标准的正太分布
import numpy as np
from sklearn import preprocessing
x = np.array([1.,2.,3.],[2.,0.,0.],[0.,1.,-1])
x_scaled = preprocessing.scale(x)
3. 指数变换(log转换)
一般对数变换后特征分布更平稳,能够很好的解决随着自变量的增加,因变量方差增大的问题。另一方面,将非线性的数据通过对数变换,转换为线性数据,便于使用线性模型进行学习。
2.1 数据离散化
离散化连续变量可以使模型更加稳健。例如,当预测客户的购买行为时,一个已有 30 次购买行为的客户可能与一个已有 32 次购买行为的客户具有非常相似的行为。有时特征中的过精度可能是噪声,这就是为什么在 LightGBM 中,模型采用直方图算法来防止过拟合。离散连续变量有两种方法。此外,像点击量、点赞量、收藏量这类连续型统计特征,需要征映射到N个桶内,再进行one-hot编码。知识点预习p分位数
df = pd.DataFrame(np.array([[1, 1], [2, 10], [3, 100], [4, 100]]),
columns=['a', 'b'])
res = df.quantile(q=0.1, axis=0, numeric_only=True, interpolation='linear')
print(df.quantile([0.2, 0.5]))
2.1.1 等距分桶
但这种方式需要注意两个点:
- 这个特征的数值分布是否平均,如果长尾严重,显然不合理;
- 特征异常值对分桶的影响是否巨大,比如点击量中出现某个断层的最大值,会直接将其他的特征挤压到前面的桶里,后面的桶则很稀疏。
factors = np.random.randn(9)
res = pd.cut(factors, bins=[-3, -2, -1, 0, 1, 2, 3])
print(pd.cut(factors, 3).value_counts()) # 计算每个分组中含有的数的数量
2.1.2 等频分桶
先对数据的等分点进行统计,然后根据每个特征等分点的情况大致确定分桶阈值,这样可以基本保证以下两个原则:
- 每个桶内的特征量级差不多
- 每个桶内的特征具有一定的区分度
factors = np.random.randn(9)
res= pd.qcut(factors, 3, labels=["a", "b", "c"],retbins=True) # 返回每个数对应的分组,但分组名称由label指示)
cnt = pd.qcut(factors, 3).value_counts() # 计算每个分组中含有的数的数量
| 参数 | 说明 |
|---|---|
| x | ndarray 或Series |
| q | integer ,指示划分的数组 |
| labels | array 或bool,默认为None。当传入数组时,分组的名称由label指示;当传入False时,仅显示分组下标 |
| retbins | bool,是否返回bins,默认为False。当传入True时,额外返回bins,即每个边界值 |
| precision | int,精度,默认为3 |
SQL实现
ntile()函数的作用是实现等频分箱,ntile(n) over(order by col) as bucket_numn是指定的分箱数量。
select
col,
ntile(3) over( order by col) as group1, -- NULL默认为最小值
if(col is null, null, ntile(3) over( partition by if(col is null, 1, 0) order by col)) as group2 -- 将NULL单独为1组
from VALUES (5), (0.1), (0.15),(0.20), (0.25),(0.3),(null) AS tab(col);
补充:percent_rank() over(order by col):先得出每个值对应的百分位数,再根据实际需求分箱
3. 类别特征
3.1 单值类别特征
3.1.1 one-hot编码
独热编码(哑变量 dummy variable)是因为大部分算法是基于向量空间中的度量来进行计算的。使用one-hot编码,将离散特征的取值扩展到了欧式空间,离散特征的某个取值就对应欧式空间的某个点,常用的距离或相似度的计算都是在欧式空间的相似度计算,计算余弦相似性,基于的就是欧式空间。将离散型特征使用one-hot编码,会让特征之间的距离计算更加合理。离散特征进行one-hot编码后,编码后的特征,其实每一维度的特征都可以看做是连续的特征。就可以跟对连续型特征的归一化方法一样,对每一维特征进行归一化。
通过sklearn库实现
import numpy as np
import sklearn import preprocessing
one_hot_enc = preprocessing.OneHotEncoder()
one_hot_enc.fit([[1,1,2],[0,1,0],[0,1,2],[1,0,3]])
after_one_hot = one_hot_enc.transform([[0,1,3]]).toarray()
通过pandas库实现
one_hot_feature = pd.get_dummies(df[col], # 输入数据
prefix=col, # 列名前缀
prefix_sep='_') # 分隔符
# transformed_train = pd.get_dummies(train_df.drop(label_columns, axis=1), columns=categorical_columns)
# 合并至原始数据
df = df.join(one_hot_feature)
3.1.2 标签编码LabelEncoder
有些基于树的算法在处理变量时,并不是基于向量空间度量,数值只是个类别符号,即没有偏序关系,所以不用进行独热编码。 Tree Model不太需要one-hot编码: 对于决策树来说,one-hot的本质是增加树的深度。
利用LabelEncoder() 将转换成连续的数值型变量。即是对不连续的数字或者文本进行编号例如:
from sklearn import preprocessing
data = ['电脑','手机','手机','手表']
enc = preprocessing.LabelEncoder()
data = enc.fit_transform(data)
print(data) #[2 0 0 1]
3.2 多值类别特征
用户的行为兴趣特征就是多值类别特征,也就是一个用户可以有多个类别的兴趣,比如打篮球,乒乓球和跳舞等,并且不同用户的兴趣个数不一样。具体方案细节参考
features=[['话题1'],
['话题1','话题3','话题2'],
['话题2']]
对这种多值类别特征的常用处理方法总结归纳如下:
非加权法
 这样对多值类别特征进行处理之后,可以把每个多值类别特征转换在同一维度空间中,这样输入到神经网络中不用为了保持输入维度一致而进行padding,使输入变稀疏,也方便和其他特征做交叉特征。
这样对多值类别特征进行处理之后,可以把每个多值类别特征转换在同一维度空间中,这样输入到神经网络中不用为了保持输入维度一致而进行padding,使输入变稀疏,也方便和其他特征做交叉特征。
加权法

4. 序列特征
-
凑单算法
Graph Embedding:序列问题可以看作是有向图,可以根据场景自己定义边权重,Graph Embedding通过采样方法的不同,可以挖掘二度、三度、甚至多度的关系,对于长序列可以倾向于DFS采样。利用Graph Embedding来处理消费序列,解决凑单问题。 -
TextCNN处理序列特征
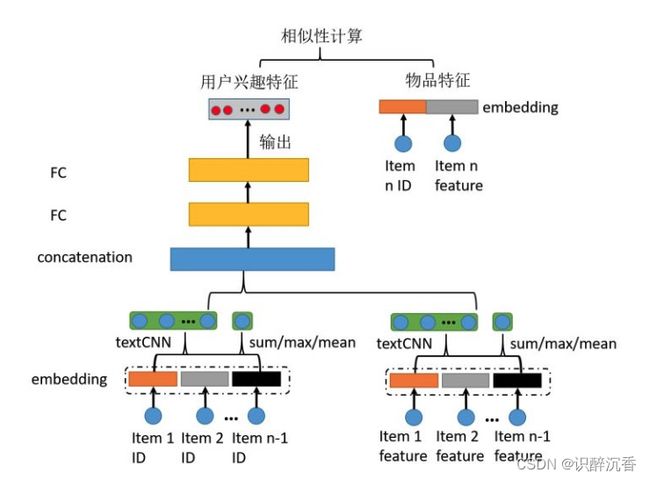
-
序列特征在推荐算法中的应用