基于OpenEuler搭建hadoop3.2.2开发环境
文章目录
- 前言
- 一、准备
- 二、安装步骤
-
- 1.安装java运行环境
- 2.安装并配置hadoop单机模式
- 3.hadoop伪分布式模式
- 总结
前言
提示:尝试在华为OpenEuler操作系统上搭建hadoop3.2.2环境,并运行实例。
提示:以下是本篇文章正文内容,下面案例可供参考,教程仅使用root用户进行操作,没有新创建用户。
一、准备
1,OpenEuler操作系统
2,Hadoop3.2.2安装包
(下载地址:https://hadoop.apache.org/release/3.2.2.html)
3,Java 1.8-jdk以上,要选择LINUX,ARM,64位的
(下载地址:https://www.oracle.com/java/technologies/javase/javase-jdk8-downloads.html)
二、安装步骤
1.安装java运行环境
输入如下命令,查看java版本信息,确认是否已安装java jdk,版本需要在1.8以上
java -version
这里系统已经装有1.8版本jdk了,无需自己再进行安装。如果没有的,需要装一下,详细教程网上都有。
openjdk version "1.8.0_242"
OpenJDK Runtime Environment (build 1.8.0_242-b08)
OpenJDK 64-Bit Server VM (build 25.242-b08, mixed mode)
2.安装并配置hadoop单机模式
模式介绍:hadoop最基本的模式,所有模块都运行在一个JVM进程中,使用本地文件系统,是安装后的默认模式。
1,使用root用户,在家目录下面创建目录tmp,并将hadoop安装包放到此目录下
mkdir ~/tmp #在当前用户家目录下创建tmp目录
pwd #查看当前目录
#/root/tmp
ls #查看安装包是否存在
#hadoop-3.2.2.tar.gz
2,解压hadoop-3.2.2.tar.gz,并将生成的hadoop-3.2.2目录放到家目录下并重命名为hadoop
tar -zxvf hadoop-3.2.2.tar.gz
mv hadoop-3.2.2 ~/hadoop
ll ~/ #查看家目录下是否有hadoop
#drwxr-xr-x 9 1000 mysql 4.0K Jan 3 18:11 hadoop
3,设置环境变量
vim ~/.bashrc
在末尾添加,保存并退出。
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.242.b08-1.h5.oe1.aarch64
export HADOOP_HOME=~/hadoop
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
使得配置生效
source ~/.bashrc
4,检查hadoop环境变量是否正确
whereis hdfs
#hdfs: /root/hadoop/bin/hdfs.cmd /root/hadoop/bin/hdfs
whereis start-all.sh
#start-all: /root/hadoop/sbin/start-all.sh /root/hadoop/sbin/start-all.cmd
5,使用hadoop命令查看版本信息
hadoop version
Hadoop 3.2.2
Source code repository Unknown -r 7a3bc90b05f257c8ace2f76d74264906f0f7a932
Compiled by hexiaoqiao on 2021-01-03T09:26Z
Compiled with protoc 2.5.0
From source with checksum 5a8f564f46624254b27f6a33126ff4
This command was run using /root/hadoop/share/hadoop/common/hadoop-common-3.2.2.jar
6,案例-----词频统计
#在家目录下创建文件exp7,并进入
mkdir ~/exp7
cd ~/exp7
#创建一个文件word.txt
vim word.txt
#写入以下内容,保存并退出
hello linux
hello root
hello hadoop
#执行命令
hadoop jar ~/hadoop/share/hadoop/mapreduce/sources/hadoop-mapreduce-examples-3.2.2-sources.jar org.apache.hadoop.examples.WordCount word.txt wordcount.txt
#查看结果
cat wordcount.txt/*
hadoop 1
hello 3
linux 1
root 1
结果如上,则表示运行成功,至此hadoop单机(本地)模式配置完成。
3.hadoop伪分布式模式
模式介绍:是指运行在一台主机上,使用多个java进程,模仿完全分布式运行在多个服务器中,一台服务器为一个节点。
1,修改配置文件hadoop-env.sh,core-site.xml , hdfs-site.xml,mapred-site.xml,yarn-site.xml
cd ~/hadoop/etc/hadoop/
ls

2,开始配置
先修改hadoop-env.sh文件
vim hadoop-env.sh +54
删除注释符号‘#’,并在‘=’后面添加java jdk路径,如下保存并退出。
# The java implementation to use. By default, this environment
# variable is REQUIRED on ALL platforms except OS X!
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.242.b08-1.h5.oe1.aarch64
接着修改 core-site.xml 文件
vim core-site.xml
在configuration与/configuration之间写入以下内容,保存并退出。192.168.0.39的位置为你的主机名或者写你的主机地址;port如果不设置,则使用默认端口9820。
fs.defaultFS</name>
hdfs://192.168.0.53:9820</value>
</property>
hadoop.tmp.dir</name>
/root/hadoop/tmp</value>
</property>
#查看主机地址
ifconfig
#查看主机名
hostname
接着修改 hdfs-site.xml 文件
vim hdfs-site.xml
在configuration与/configuration之间写入以下内容,保存并退出。
dfs.replication</name>
1</value>
</property>
接着修改mapred-site.xml文件
vim mapred-site.xml
在configuration与/configuration之间写入以下内容,保存并退出。
mapreduce.framework.name</name>
yarn</value>
</property>
yarn.app.mapreduce.am.env</name>
HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
mapreduce.map.env</name>
HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
mapreduce.reduce.env</name>
HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
最后再设置 yarn-site.xml文件
vim yarn-site.xml
在configuration与/configuration之间写入以下内容,保存并退出。
yarn.nodemanager.aux-services</name>
mapreduce_shuffle</value>
</property>
3,格式化Namenode节点
hdfs namenode -format
注意:格式化只能进行一次,再格式化会丢失 DataNode 进程,就需要重新启用。
4,修改配置使得可以以根用户(root)启动hadoop进程。默认是不可以的直接启动会报错。
vim ~/.bashrc +
添加如下内容,保存并退出
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
使配置生效
source ~/.bashrc
5,配置ssh免密登录
#创建公钥私钥,输入以下命令一路回车
ssh-keygen -t rsa
cd ~/.ssh
touch authorized_keys
chmod 600 authorized_keys
cat id_rsa.pub >> authorized_keys
6,启动验证hadoop进程
#启动hdfs
start-dfs.sh
#启动yarn
start-yarn.sh
#一起启动,提高效率,即上面两句合并为下面一句
start-all.sh
#jps验证
jps
114449 Jps
10291 DataNode
7124 ResourceManager
1668 WrapperSimpleApp
10616 SecondaryNameNode
9997 NameNode
100735 NodeManager
有DataNode,NameNode,ResourceManager,NodeManager,SecondaryNameNode则表示正确启动。
如果缺少某进程,就在hadoop下的logs文件中,查看相应的进程日志文件,到网上搜索解决方案。
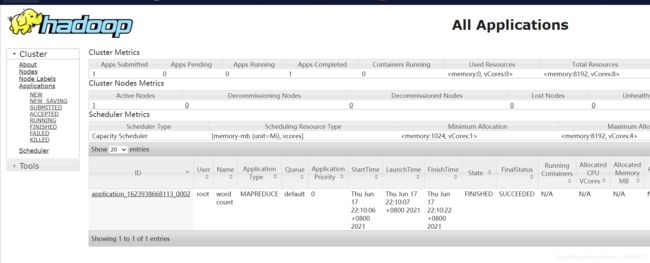
7,通过web访问hadoop
在浏览器输入ip:8088,进入YARN web界面
可以查看集群所有应用程序的信息

8042端口可以查看节点信息
9870端口可以通过web查看namenode
8,案例-----HDFS词频统计
在HDFS创建exp7文件夹,并将本地的word.txt上传到HDFS
hdfs dfs -mkdir /exp7
#进入本地exp7
cd ~/exp7
#上传文件
hdfs dfs -put word.txt /exp7
#查看是否上传成功
hdfs dfs -ls /exp7/*
执行命令进行统计
hadoop jar ~/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.2.jar wordcount /exp7/word.txt /exp7/wordcount
查看是否成功运行,在exp7目录下会生成一个wordcount目录,下面有_SUCCESS文件是一个空文件表示运行成功,part-r-00000文件是运行结果。
hdfs dfs -ls /exp7/*
hdfs dfs -cat /exp7/wordcount/*
运行结果如下
hadoop 1
hello 3
linux 1
root 1
9,通过web查看刚刚运行的作业信息
浏览器输入ip:port
关闭所有hadoop进程
stop-all.sh
jps
总结
至此,已经在OpenEuler成功搭建好了hadoop单机模式和伪分布式模式。在运行hadoop过程中一直会有一个警告,提示无法加载本机hadoop库,但不影响正常运行。初步判断是由于glibc版本问题,我在解决的过程中,虚拟机还挂了…(个人建议不要轻易尝试安装!)。有什么好的解决方案还请不吝赐教,遇到什么其他问题也可以留言一起讨论。
在之后也会继续尝试完全分布式的搭建。