Antlr g4 入门+深入
目录
一、ANTLR概述
二、JAVA开发工具使用举例
Idea中配置使用
Eclipse中配置使用
示例:计算机四则计算(官网照抄)
三、ANTLR4语法
grammar
options
import
tokens
channels
@header
@members
@parser:: name
@lexer:: name
returns
rule
type
fragment
点号 .
mode
pushMode
popMode
more
解耦方案
错误处理
四、遍历模式
1、Listener (观察者模式,通过结点监听,触发处理方法)
2、Visitor (访问者模式,主动遍历)
总结:
五、显示语法树展示
常见的语法分析器
一、ANTLR概述
ANTLR是一款强大的语法分析器生成工具,可用于读取、处理、执行和翻译结构化的文本或二进制文件。
ANTLR 是用JAVA写的语言识别工具,它用来声明语言的语法,简称为“元语言”。
学习ANTLR书籍: 《ANTLR4权威指南》
二、JAVA开发工具使用举例
Idea中配置使用
pom.xml添加
org.antlr
antlr4-runtime
4.7
jar
compile
Idea setting中安装ANTLR插件(我本机安装完了) Eclipse也类似的安装插件

Eclipse中配置使用
安装ANTLR4插件
Eclipse-->Help-->Eclipse Marketplace...-->搜索antlr-->如下图点击Install安装

配置编译版本路径等设置

查看G4节点:Syntax Diagram

示例:计算机四则计算(官网照抄)
1、新建g4文件,如Math.g4
grammar Math;
prog : stat+;
stat: expr NEWLINE # printExpr
| ID '=' expr NEWLINE # assign
| NEWLINE # blank
;
expr: expr op=('*'|'/') expr # MulDiv
| expr op=('+'|'-') expr # AddSub
| INT # int
| ID # id
| '(' expr ')' # parens
;
MUL : '*' ; // assigns token name to '*' used above in grammar
DIV : '/' ;
ADD : '+' ;
SUB : '-' ;
ID : [a-zA-Z]+ ;
INT : [0-9]+ ;
NEWLINE:'\r'? '\n' ;
WS : [ \t]+ -> skip;Idea 安装完ANTLR插件 右键g4文件可以看到,点击Configure ANTLR...

配置目录如下,按照你们自己的目录设置,点击OK

右键Math.g4文件,点击Generate ANTLR Recognizer

自动生成代码:

编写实现类,继承上面自动生成的类MathBaseVisitor,实现计算
public class MathVisitorImp extends MathBaseVisitor {
// 存储变量的值
private Map variable;
public MathVisitorImp() {
variable = new HashMap<>();
}
// 当遇到printExpr节点,计算出exrp的值,然后打印出来
@Override
public Integer visitPrintExpr(MathParser.PrintExprContext ctx) {
Integer result = ctx.expr().accept(this);
System.out.println(result);
return null;
}
// 分别获取子节点expr的值,然后做加减运算
@Override
public Integer visitAddSub(MathParser.AddSubContext ctx) {
Integer param1 = ctx.expr(0).accept(this);
Integer param2 = ctx.expr(1).accept(this);
if (ctx.op.getType() == MathParser.ADD) {
return param1 + param2;
}else {
return param1 - param2;
}
}
// 分别获取子节点expr的值,然后做乘除运算
@Override
public Integer visitMulDiv(MathParser.MulDivContext ctx) {
Integer param1 = ctx.expr(0).accept(this);
Integer param2 = ctx.expr(1).accept(this);
if (ctx.op.getType() == MathParser.MUL) {
return param1 * param2;
}else {
return param1 / param2;
}
}
// 当遇到int节点,直接返回数据
@Override
public Integer visitInt(MathParser.IntContext ctx) {
return Integer.parseInt(ctx.getText());
}
// 当遇到Id节点,从变量表获取值
@Override
public Integer visitId(MathParser.IdContext ctx) {
return variable.get(ctx.getText());
}
// 当遇到赋值语句,获取右边expr的值,然后将变量的值保存到variable集合
@Override
public Integer visitAssign(MathParser.AssignContext ctx) {
String name = ctx.ID().getText();
Integer value = ctx.expr().accept(this);
variable.put(name, value);
return null;
}
} 测试:
public class MathVisitorTest {
public static void exec(String input) {
MathLexer lexer = new MathLexer(CharStreams.fromString(input));
CommonTokenStream tokens = new CommonTokenStream(lexer);
MathParser parser = new MathParser(tokens);
parser.setBuildParseTree(true);
ParseTree root = parser.prog();
MathBaseVisitor visitor = new MathVisitorImp();
root.accept(visitor);
}
public static void main(String[] args) {
String input = "1+2+3+5-7+1\n";
// String input = "a = 14\n" +
// "b = a - 3\n" +
// "a + b\n";
exec(input);
}
} 结果输出为:5
g4检查语法是否通过
1.新建g4Test.txt内容如下
a=3
b=4
c=a+b
d=a+b+c
e=4**2
f=d+e
2.测试g4是否通过
public class g4Main {
public static void main(String[] args) throws Exception {
CharStream inputStream = CharStreams.fromFileName("D:\\g4\\g4Test.txt", Charset.forName("UTF-8"));
MathLexer lexer = new MathLexer(inputStream);
CommonTokenStream token=new CommonTokenStream(lexer);
MathParser parser=new MathParser(token);
MathParser.ProgContext tree = parser.prog();
tree.accept(new MathBaseVisitor结果输出为:
line 5:4 extraneous input '*' expecting {'(', ID, INT}
g4执行结束line 5:4 这是第5行第4列有语法不匹配的情况。
正常去修改Math.g4文件。以匹配语法。
三、ANTLR4语法
先分词,后组句。
ANTLR4语法结构:
//文件名G4Name.g4
grammar G4Name; //grammar:声明语法头,定义语法名称。需要注意的是文件名X.g4必须与grammar X相同。
options {...} //用来在grammar级别指定Antlr通过grammar文件生成代码的规则,如语言选项,输出选项,回溯选项,记忆选项等
import ... ;
tokens {...}
channels {...} // lexer only
@actionName {...}
rule1 // parser and lexer rules, possibly intermingled
...
ruleNgrammar
定义语法名称。需要注意的是文件名X.g4必须与grammar X相同。
词法语法分开定义
词法:
lexer grammar LexerName;语法:
parser grammar ParserName;
options { tokenVocab=LexerName; } options
用来在grammar级别指定Antlr通过grammar文件生成代码的规则,如语言选项,输出选项,回溯选项,记忆选项等:
superClass=XG4Base 相当于语法继承XG4Base类
options { output=AST; language=Java; }
options { tokenVocab=XLexer; superClass=XG4Base} //语法树中标识词法树名字,词法和语法文件分开的情况,使用XLexer.g4中的词法符号//superClass=XG4Base 相当于语法继承XG4Base类import
导入包
tokens
tokens块的目的是为那些没有关联词法规则的grammar来定义tokens的类型。许多时候,tokens被用来定义actions
channels
只有词法分析器的grammar中才能包含自定义的channels,下面是一个例子:
channels {
WHITESPACE_CHANNEL,
COMMENTS_CHANNEL
}上面定义的channels可以在词法分析规则中像枚举一样使用:
WS : [ \r\t\n]+ -> channel(WHITESPACE_CHANNEL) ;@header
会在recognizer class定义之前将代码注入生成的recognizer class`文件中。
@members
将代码作为值域和方法注入到recognizer class定义中。
@header {
package demos.java.antlr;
}
@members {
private String name = "测试";
}编译完g4文件生成java类,会在开头显示
package demos.java.antlr;类定义会有
private String name = "测试";@parser:: name
限制一段代码只出现在语法分析器
@lexer:: name
限制一段代码只出现在词法分析器
returns
返回值:指定返回值
e returns [int v]
: a=e op=('*'|'/') b=e {$v=eval($a.v,$op.type,$b.v);}
| '('e')' {$v=$e.v;}
;rule
这是核心,表示规则,以 “:” 开始, “;” 结束, 多规则以 "|" 分隔。
lexer定义时名字以大写字母开头。lexer用作词法分析。
parser定义时名字以小写字母开头。parser用作语法分析,是字符串和lexer的组合,用来匹配分析一个句子。
->skip、->channel(HIDDEN):词法分析器的指令,遇到被这些修饰的词法符号会被语法分析器忽略。
skip和channel(HIDDEN)区别:skip相当于去掉某些内容。channel(HIDDEN)隐藏掉某些内容,但是可以拿到。
?:可选
*:出现0次或多次
+:至少一次
~:词法中相当于"取反"的意思
{}:加?代表判定返回Boolean值;不加代表动作,在java中定义是一段方法逻辑。
{方法名(MATEST)} //MATEST词在mode模式下,说明:{方法名(MATEST)}所在的词的定义匹配也可以在语法里用MATEST表示。
例如:
OPEN : '<' {fixedName(MATEST)}; //MATEST词法代表满足fixedName方法逻辑的情况下,匹配OPEN的词法
mode no_mode_match;
MATEST : 'XXX'; //'XXX'无实际意义,为了按照fixedName方法满足的条件下的OPEN 词法逻辑运算符是右结合。
ANTLR将直接左递归替换为一个判定循环,该循环会比较前一个和下一个运算符的优先级。
ANTLR总是通过选择位置靠前的规则来解决词法歧义问题。
ANTLR将会为你的语法中的每条规则生成一个函数。
自顶向下,深度优先。
CONTEXT:上下文
type
F_ ->type(FILL) //F_按照FILL来匹配解析。
fragment
将一条规则声明为fragment可以告诉ANTLR,该规则本身不是一个词法符号,它只会被其他的词法规则使用。这意味着不能在文法规则中引用fragment下定义的词法。
FLOAT: DIGIT+ '.' DIGIT* //匹配 1. 39. 3.14159等....
| '.' DIGIT+ //匹配 .1 .14159
;
fragment DIGIT : [0-9];//匹配单个数字点号 .
STRING:'"' .*? '"' ; //匹配"..."间的任意文本其中,点号通配符匹配任意的单个字符。因此,.*就是一个循环,它匹配零个或多个字符组成的任意字符
序列。显然,它可以一直匹配到文件结束,但这没有任何意义。为解决这个问题,ANTLR通过标准
正则表达式的标记(? 后缀) 提供了对非贪婪匹配子规则的支持。
非贪婪匹配的基本含义是:"获取一些字符,直到发现匹配后续子规则的字符为止"。
更准确的描述,非贪婪的子规则匹配数量最少的字符。
与之相反,.*是贪婪的,因为它贪婪地消费掉一切匹配的字符。
mode
词法模式处理上下文相关的词法符号。词法模式允许我们将单个词法分析器分成多个子词法分析器。词法分析器会返回被当前模式下的规则匹配的词法符号。
一门语言能够进行模式切换的一个重要要求是包含清晰的词法"哨兵",它能够触发模式的来回切换。
OPEN : '<' ->mode(ISLAND); //切换到ISLAND模式
TEXT : ~'<'+ ;
mode ISLAND;
CLOSE : '>' ->mode(DEFAULT_MODE); //回到默认模式
SLASH : '/' ;
ID : [a-zA-Z]+ ;OPEN匹配到单个<,使用词法分析器指令mode(ISLAND)来切换模式。之后词法分析器就只会使用ISLAND模式下的规则进行工作。
ISLAND模式下,词法分析器匹配>、/和ID词法符号。
当词法分析器发现>时,它会执行切换回默认模式的指令,该模式由Lexer类中的常量DEFAULT_MODE标识。
mode和{}结合使用:
{方法名(MATEST)} //MATEST词在mode模式下,说明:{方法名(MATEST)}所在的词的定义匹配也可以在语法里用MATEST表示。
用例,在解析的时候一个词需要满足某种规则的情况下使用的时候。才会使用。
特定的词匹配会出现歧义的时候会使用。
例如:
OPEN : '<' {fixedName(MATEST)}; //MATEST词法代表满足fixedName方法逻辑的情况下,匹配OPEN的词法
mode no_mode_match;
MATEST : 'XXX'; //'XXX'无实际意义,为了按照fixedName方法满足的条件下的OPEN 词法逻辑pushMode
将某种模式"进栈",词法分析器就可以在未来"出栈",返回到调用者对应的模式。
popMode
词法指令:这个规则只需要弹出即可。
more
它命令词法分析器寻找下一个词法符号。
OPEN : '<' ->pushMode(INSIDE);
XMLDeclOpen : 'pushMode(INSIDE);
mode INSIDE;
CLOSE : '>' -> popMode ;
SPECIAL_CLOSE : '?>' -> popMode ;
IGNORE : . ->more ;解耦方案
解耦方案允许该语法被不同程序复用,但是由于方法调用的存在,它仍然和Java绑定在一起。
@members{
void startFile() { } //空实现
void finishFile() {}
void defineProperty(Token name,Token value) { }
}
file : {startFile();} prop+ {finishFile();} ;
prop : ID '=' STRING '\N' {defineProperty($ID,$STRING)} ;
ID : [a-z]+ ;
STRING : '"' .*? '"' ;错误处理
parser.removeErrorListeners();//移除ConsoleErrorListener
parser.addErrorListener(new DiagnosticErrorListener());四、遍历模式
1、Listener (观察者模式,通过结点监听,触发处理方法)
- 程序员不需要显示定义遍历语法树的顺序,实现简单
- 缺点,不能显示控制遍历语法树的顺序
- 动作代码与文法产生式解耦,利于文法产生式的重用
- 没有返回值,需要使用map、栈等结构在节点间传值
语法分析树监听器
ANTLR运行库提供了ParseTree-Walker类,我们可以自行实现ParseTreeListener接口,在其中填充自己的逻辑代码。

监听器机制的优秀之处在于,这一切都是自动进行的。我们不需要编写对语法分析树的遍历代码,也不需要让我们的监听器显式的访问子节点。
CodePointCharStream cs = CharStreams.fromString(STRING);//STRING 编写的语法
G4NameLexer lexer = new G4NamecLexer(cs);
CommonTokenStream tokens = new CommonTokenStream(lexer);
G4NameParser parser = new G4NameParser(tokens);
ParseTree tree = parser.expr();//expr语法树的根节点,也就是语法入口
ParseTreeWalker walker = new ParseTreeWalker();//ANTLR提供的标准的遍历器
MyListener listener = new MyListener (); //MyListener继承于extends G4NameBaseListener
walker.walk(listener, tree);//使用监听器初始化对语法分析树的遍历
return listener.result(); //自定义MyListener 中写result方法返回结果2、Visitor (访问者模式,主动遍历)
- 程序员可以显示定义遍历语法树的顺序
- 不需要与antlr遍历类ParseTreeWalker一起使用,直接对tree操作
- 动作代码与文法产生式解耦,利于文法产生式的重用
- visitor方法可以直接返回值,返回值的类型必须一致,不需要使用map这种节点间传值方式,效率高
语法监听器访问器:有时候我们希望遍历语法分析树的过程,通过显式的方法来访问子节点。

上图,粗虚线显示了对语法分析树进行深度优先遍历的过程。细虚线标示出访问器方法的调用顺序。我们可以在自己的程序代码实现访问器接口,然后调用visit()方法来开始对语法分析树的一次遍历。
G4NameLexer lexer = new G4NameLexer(CharStreams.fromString(input));//G4Name:g4文件名,input:语法一个字符串
CommonTokenStream tokens = new CommonTokenStream(lexer);
G4NameParser parser = new G4NameParser(tokens);
parser.setBuildParseTree(true);//true创建语法分析树、false不需要浪费时间建立语法分析树
ParseTree tree = parser.prog();//prog:g4语法的根节点
MyVisitor visitor = new MyVisitor ();//MyVisitor自定义访问器
visitor.visit(tree);//实际时调用tree.accept(visitor);//开始语法分析总结:
词法分析器处理字符序列并将生成的词法符号提供给语法分析器,语法分析器随即根据这些信息来检查语法的正确性并建造一颗语法分析树。
这个过程对应ANTLR类是CharStream、Lexer、Token、Parser,以及ParseTree。
连接词法分析器和语法分析器的“管道”就是TokenStream。
五、显示语法树展示
新建Hello.g4文件,放到D:\tools\g4下面
grammar Hello; //定义一个名为Hello的语法
r:'hello' ID; //匹配一个关键字hello和一个紧随其后的标识符
ID:[a-z]+;
WS:[ \t\r\n]+ ->skip;//系统级规则,忽略空格、Tab、换行符以及\r (Windows)1.下载antlr4运行包,这里我选择的版本是 antlr-4.7.1-complete.jar
2.新建运行脚本 antlr4.bat 和 grun.bat,放置于任意目录,如 D:/tools/antlr4
antlr4.bat 内容:
java org.antlr.v4.Tool %*grun.bat 内容:
java org.antlr.v4.gui.TestRig %*注:antlr依赖于java,如果java环境变量没有设置,请先行设置好。
3.设置antlr4的系统环境变量(classpath 和 path),设置完重启电脑,使配置生效
classpath:D:\tools\antlr4\antlr-4.7.1-complete.jar

path:(.bat所在目录) :D:\tools\antlr4

4.选择要分析的g4文件,运行命令生成相关java文件与token文件
cmd中打开
D:\tools\g4>antlr4 Hello.g4生成如下文件:

HelloParser.java:该文件包含一个语法分析器类的定义,这个语法分析器专门用来识别我们的"hello str"语法。
public class HelloParser extends Parser {...}在该类中每条规则都有对应的方法,除此之外,还有一些其他的辅助代码。
HelloLexer.java:ANTLR能够自动识别出我们的语法中的文法规则和词法规则。这个文件包含的是词法分析器的类定义。
public class HelloLexer extends Lexer {...}Hello.tokens:ANTLR会给每个我们定义的词法符号指定一个数字形式的类型,然后将它们的对应关系存储于该文件中。
HelloListener.java、HelloBaseListener.java:ANTLR生成的语法分析器能将输入文本转换为一颗语法分析树。在遍历语法分析树时,遍历器能够触发一系列“事件”(回调),并通知我们提供的监听器对象。HelloListener接口给出了这些回调方法的定义,我们可以实现它来完成自定义功能。HelloBaseListener是该接口的默认实现类,为其中每个方法提供了一个空实现。
通过-visitor命令行参数,ANTLR也可以为我们生成语法分析树的访问器
D:\tools\g4>antlr4 Hello.g4 -visitor
HelloVisitor.java、HelloBaseVisitor.java:
5.编译java文件
D:\tools\g4>javac ./*.java
6.分析语法树
输入grun命令回车,在命令行输入你要测试的语法,再回车,按Ctrl+z 后回车。
D:\tools\g4>grun Hello r -gui继续输入:hello hi
按回车-->按Ctrl+z -->回车,弹出Parse Tree Inspector
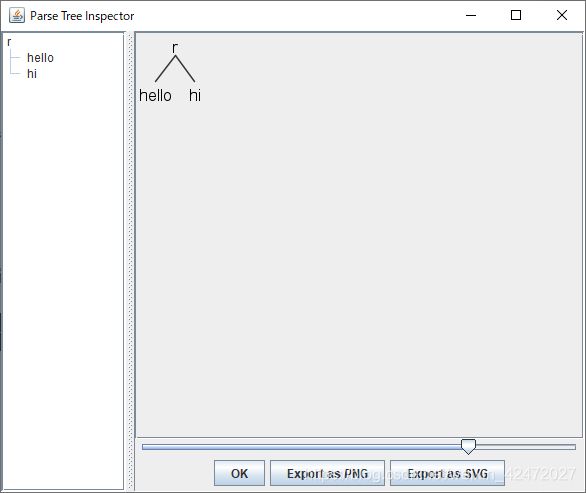
再重复不按规则输入
D:\tools\g4>grun Hello r -gui继续输入:hh ee
结果:
line 1:0 missing 'hello' at 'hh'

可以检证语法错误位置
7.打印出词法符号流
D:\tools\g4>grun Hello r -tokens继续输入:hello heabc
按回车-->按Ctrl+z -->回车
结果:
[@0,0:4='hello',<'hello'>,1:0]
[@1,6:10='heabc',
[@2,13:12='
再重复不按规则输入
D:\tools\g4>grun Hello r -tokens继续输入:hh ee
按回车-->按Ctrl+z -->回车
结果:
[@0,0:1='hh',
[@1,3:4='ee',
[@2,7:6='
line 1:0 missing 'hello' at 'hh'
可以检证语法错误位置
8.不带参数输入grun ,会产生一些帮助信息,出现结果如下
D:\tools\g4>grun
D:\tools\g4>java org.antlr.v4.gui.TestRig
java org.antlr.v4.gui.TestRig GrammarName startRuleName
[-tokens] [-tree] [-gui] [-ps file.ps] [-encoding encodingname]
[-trace] [-diagnostics] [-SLL]
[input-filename(s)]
Use startRuleName='tokens' if GrammarName is a lexer grammar.
Omitting input-filename makes rig read from stdin.
D:\tools\g4>简单介绍选项意思:
-tokens:打印出词法符号流。
-tree:以LISP格式打印出语法分析树。
-gui:在对话框中以可视化方式显示语法分析树。
-ps file.ps :以PostScript格式生成可视化语法分析树,然后将其存储于file.ps。
-encoding encodingname:若当前的区域设定无法正确读取输入,使用这个选项指定测试组件输入文件的编码。
-trace:打印规则的名字以及进入和离开该规则时的词法符号。
-diagnostics:开启解析过程中的调试信息输出。
-SLL:使用另外一种更快但是功能稍弱的解析策略。
常见的语法分析器
Antlr
Javacc
SqlParser (位于Alibaba的Druid库中)
其中Antlr和Javacc都是现代的语法解析器,两者都很优秀,其中Antlr要更胜一筹。
而SqlParser只能解析sql语句,功能比较单一。
另一语法分析器:JavaCC 学习
后续会继续补充...