(十三)全面理解并发编程之分布式架构下Redis、ZK分布式锁的前世今生
引言
在前面的大部分文章中,我们反复围绕着线程安全相关问题在对Java的并发编程进行阐述,但前叙的文章中都是基于单体架构的Java程序进行分析的,而如今单体的程序远不足以满足日益渐增的用户需求,所以一般目前Java程序都是通过多机器、分布式的架构模式进行部署。那么在多部署环境下,之前我们分析的CAS无锁、隐式锁、显式锁等方案是否还有效呢?答案是无效。
一、单体架构下的锁迁移分布式架构分析
在前面关于Synchronized关键字原理剖析以及AQS与ReetrantLock原理分析两篇文章中,曾得知这两种都是属于可以解决线程安全问题的锁,一种是Java原生的关键字,通过Java对象进行加锁的隐式锁,另一种则是JUC提供的显式锁方案。在开发过程中使用它们都能够保证多线程的安全问题。但把它们放在多机器/多应用部署的环境下,也能保证相同的效果吗?先来看一个案例:
两个服务:[订单服务:8000端口]、[商品服务:8001、8002端口]
数据库:订单库[db_order]、商品库[db_shopping]
订单服务中提供了一个下单接口,用户下单后会调用它,调用下单接口后,会通过restTemplate进行RPC调用商品服务的扣库存接口,实现库存扣减下单操作。
源码如下:
// 订单服务
@RestController
@RequestMapping("/order")
public class OrderApi{
// 库存服务的RPC前缀
private static final String REST_URL_PREFIX =
"http://SHOPPING/inventory";
@Autowired
private OrderService orderService;
@Autowired
private RestTemplate restTemplate;
// 下单接口
@RequestMapping("/placeAnOrder")
public String placeAnOrder(){
// 模拟商品ID
String inventoryId = "82391173-9dbc-49b6-821b-746a11dbbe5e";
// 生成一个订单ID(分布式架构中要使用分布式ID生成策略,此处是模拟)
String orderId = UUID.randomUUID().toString();
// 模拟生成订单记录
Order order = new
Order(orderId,"黄金竹子","88888.88",inventoryId);
// RPC调用库存接口
String responseResult = restTemplate.getForObject(
REST_URL_PREFIX + "/minusInventory?inventoryId="
+ inventoryId, String.class);
System.out.println("调用后库存接口结果:" + responseResult);
Integer n = orderService.insertSelective(order);
if (n > 0)
return "下单成功....";
return "下单失败....";
}
}
// 库存服务
@RestController
@RequestMapping("/inventory")
public class InventoryApi{
@Autowired
private InventoryService inventoryService;
@Value("${server.port}")
private String port;
// 扣库存接口
@RequestMapping("/minusInventory")
public String minusInventory(Inventory inventory) {
// 查询库存信息
Inventory inventoryResult =
inventoryService.selectByPrimaryKey(inventory.getInventoryId());
if (inventoryResult.getShopCount() <= 0) {
return "库存不足,请联系卖家....";
}
// 扣减库存
inventoryResult.setShopCount(inventoryResult.getShopCount() - 1);
int n = inventoryService.updateByPrimaryKeySelective(inventoryResult);
if (n > 0)
return "端口-" + port + ",库存扣减成功!!!";
return "端口-" + port + ",库存扣减失败!!!";
}
}
观察上述源码,存在什么问题?线程安全问题。按照之前的做法我们会对扣库存的接口使用Synchronized或ReetrantLock加锁,如下:
// 库存服务 → 扣库存接口
@RequestMapping("/minusInventory")
public String minusInventory(Inventory inventory) {
int n;
synchronized(InventoryApi.class){
// 查询库存信息
Inventory inventoryResult =
inventoryService.selectByPrimaryKey(inventory.getInventoryId());
if (inventoryResult.getShopCount() <= 0) {
return "库存不足,请联系卖家....";
}
// 扣减库存
inventoryResult.setShopCount(inventoryResult.getShopCount() - 1);
n = inventoryService.updateByPrimaryKeySelective(inventoryResult);
System.out.println("库存信息-剩余库存数量:" +
inventoryResult.getShopCount());
}
if (n > 0)
return "端口:" + port + ",库存扣减成功!!!";
return "端口:" + port + ",库存扣减失败!!!";
}
是不是感觉没问题了?看测试:
通过JMeter压测工具,1秒内对下单接口进行八百次调用,此时出现了一个比较有意思的现象,测试结果如下:
订单服务控制台日志:[端口:8000]
......
调用后库存接口结果:端口-8001,库存扣减成功!!!
调用后库存接口结果:端口-8002,库存扣减成功!!!
......
调用后库存接口结果:端口-8001,库存扣减成功!!!
调用后库存接口结果:端口-8001,库存扣减成功!!!
调用后库存接口结果:端口-8002,库存扣减成功!!!
......
商品服务控制台日志:[端口:8001]
......
库存信息-剩余库存数量:999
......
库存信息-剩余库存数量:788
库存信息-剩余库存数量:787
.....
商品服务控制台日志:[端口:8002]
......
库存信息-剩余库存数量:998
库存信息-剩余库存数量:996
库存信息-剩余库存数量:993
......
库存信息-剩余库存数量:788
.....
注意观察如上日志,在两个商品服务[8001/8002]中都出现了库存信息-剩余库存数量:788这么一条日志记录,这代表第799个商品被卖了两次,还是出现了线程安全问题,导致了库存超卖。可我们不是已经通过Class对象加锁了吗?为什么还会有这样的问题出现呢?下面我们来依次分析。
问题分析
在关于Synchronized关键字原理剖析的文章中已经得知:Synchronized关键字是依赖于对象做为锁资源进行加锁操作的,每个对象都会存在一个伴生的Monitor监视器,Synchronized则是通过它进行上锁,加锁过程如下:
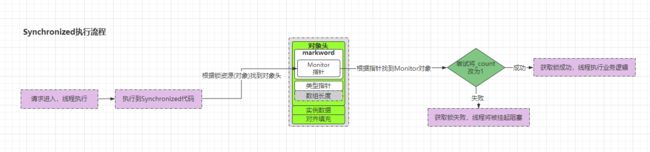
OK~,有了上述基础知识之后,再接着分析前面的问题。为什么会出现线程安全问题?
实际上这个问题也不难理解,前面的案例中,我们是通过
InventoryApi.class类对象进行上锁的,如果在单体程序中确实没有任何问题,因为Class对象是唯一的,当多条线程抢占一把Class锁时,同一时刻只会有一条线程获取锁成功,这样自然而然也不存在线程安全问题了。但目前的问题就出在这里,InventoryApi.class对象在单体程序中确实只存在一个,但目前商品服务是属于多应用/多机器部署的,目前商品服务有两个进程,那这就代表着存在两个不同的Java堆,在两个不同的堆空间中,都存在各自的InventoryApi.class对象,也就是代表着“此时Class对象并不是唯一的,此刻出现了两把锁”。而正是因为这个问题才最终导致了线程安全问题的出现。如下图:
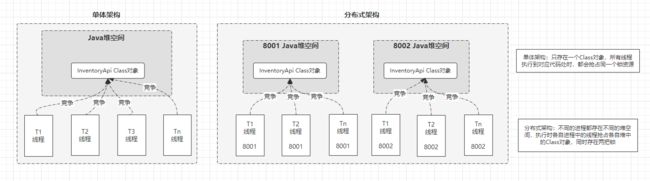
还是回到最开始叙述线程安全的起点,同一时刻满足三要素:“多线程”、“共享资源”以及“非原子性操作”便会产生线程安全问题,而Synchronized或ReetrantLock都是从破坏了第一个要素的角度出发,以此解决了线程安全问题。但目前在分布式架构中,Synchronized或ReetrantLock因为多进程导致的多个Java空间堆出现,所以不管是Synchronized还是ReetrantLock都已经无法保证同一时刻只有一条线程对共享资源进行非原子性操作,最终线程安全问题的出现已经无法避免。
二、分布式锁思想及其实现过程推导
经过前面的分析,已经得知了分布式架构下的线程安全问题产生的根本原因,那目前又该如何解决这个问题呢?可能学习过分布式锁的小伙伴会直接回答:分布式锁。但此刻请你抛下之前的记忆,我们完全从零开始对分布式锁进行推导。
大家可以先代入一个角色:假设市面上还没有成熟的解决方案,你是第一位遇到这个问题的人,那么你又该如何去解决这类问题呢?OK~,接下来我们一起逐步推导。
先思考思考前面的Synchronized、ReetrantLock是如何解决单体程序的线程安全问题的呢?
- Synchronized:
- 依赖堆中对象的Monitor监视器
- 通过操作监视器中的_count字段实现互斥
- ReetrantLock:
- 依赖于AQS同步器
- 通过操作AQS中volatile修饰的state成员实现互斥
它们有什么共同点呢?都存在一个互斥量,并且互斥量都是所有线程可见的。
OK~,明白了这两点之后,再反过来思考一下,分布式环境中又是因为什么原因导致的安全问题复发了呢?答案是:互斥量所在的区域对于其他进程中的线程来说是不可见的。比如Synchronized关键字通过某个Class对象作为锁对象,一个堆空间中的Class对象对于当前进程中的所有线程来说是可见的,但是对于其他进程的线程是不可见的。ReetrantLock也是同理,volatile修饰的state变量,对于当前进程中的所有线程可见,但对于另外进程中的线程是不可见的。
那么此时想要解决分布式情况下的线程安全问题的思路是不是明了啦?
我们只需要找一个多个进程之间所有线程可见的区域实现这个互斥量即可。
比如:在一台服务器的同一路径下创建一个文件夹。获取锁操作则是创建文件夹,反之,释放锁的逻辑则是删除文件夹,这样可以很好的实现一把分布式锁,因为OS特性规定,在同一路径下,相同名字的文件夹只能创建一个。所以当两条线程同时执行获取锁逻辑时,永远只会有一条线程创建成功,成功创建文件夹的那条线程则代表获取锁成功,那么可以去执行业务逻辑。当这条线程执行完业务后,再删除掉文件夹,代表释放锁,以便于其他线程可以再次获取锁。
上述的这种方式确实可以实现一把最基本的分布式锁,但问题在于:这样实现的话一方面性能会比较差,第二个也不能具备锁重入的功能,第三方面也没有具备合理的锁失效机制以及阻塞机制。而一个优秀的分布式锁的实现方案应该满足如下几个特性:
- ①在分布式环境中,可以保证不同进程之间的线程互斥
- ②在同一时刻,同时只允许一条线程成功获取到锁资源
- ③保存互斥量的地方需要保证高可用性
- ④要保证可以高性能的获取锁与释放锁
- ⑤可以支持同一线程的锁重入性
- ⑥具备合理的阻塞机制,竞争锁失败的线程也有处理方案
- ⑦支持非阻塞式获取锁,获取锁失败的线程可以直接返回
- ⑧具备合理的锁失效机制,如超时失效等,可以确保避免死锁情况出现
那么目前市面上对于分布式锁的成熟方案有哪些呢?
- ①基于DB实现
- ②基于Redis实现
- ③基于Zookeeper实现
对于第一种方式的实现并不难,无非是在数据库中创建一张lock表,表中设置方法名、线程ID等字段。并为方法名字段建立唯一索引,当线程执行某个方法需要获取锁时,就以这个方法名作为数据向表中插入,如果插入成功代表获取锁成功,如果插入失败,代表有其他线程已经在此之前持有锁了,当前线程可以阻塞等待或直接返回。同时,也可以基于表中的线程ID字段为锁重入提供支持。当然,当持有锁的线程业务逻辑执行完成后,应当删除对应的数据行,以此达到释放锁的目的。
这种方式依靠于数据库的唯一索引,所以实现起来比较简单,但是问题在于:因为是基于数据库实现的,所以获取锁、释放锁等操作都要涉及到数据落盘、删盘等磁盘IO操作,性能方面值得考虑。同时也对于超时失效机制很难提供支持,在实现过程中也会出现很多其他问题,为了确保解决各类问题,实现的方式也会越发复杂。
OK~,那么接下来再看看其他两种主流方案的实现,redis以及ZK实现分布式锁,也是目前应用最广泛的方式。
三、Redis实现分布式锁及其细节问题分析
Redis实现分布式锁是目前使用最广泛的方式之一,因为Redis属于中间件,独立部署在外,不附属于任何一个Java程序,对于不同的Java进程来说,都是可见的,同时它的性能也非常可观,可以依赖于其本身提供的指令setnx key value实现分布式锁。
setnx key value:往Redis中写入一个K-V值。不过与普通的set指令不同的是:setnx只有当key不存在时才会设置成功,当key已存在时,会返回设置失败。同时因为redis对于客户端的指令请求处理时,是使用epoll多路复用模型的,所以当同时多条线程一起向redis服务端发送setnx指令时,只会有一条线程设置成功。最终可以依赖于redis这些特性实现分布式锁。
OK~,下面通过setnx key value实现最基本的分布式锁,如下:
// 库存服务
@RestController
@RequestMapping("/inventory")
public class InventoryApi{
@Autowired
private InventoryService inventoryService;
@Value("${server.port}")
private String port;
// 注入Redis客户端
@Autowired
private StringRedisTemplate stringRedisTemplate;
// 扣库存接口
@RequestMapping("/minusInventory")
public String minusInventory(Inventory inventory) {
// 获取锁
String lockKey = "lock-" + inventory.getInventoryId();
Boolean flag = stringRedisTemplate.opsForValue()
.setIfAbsent(lockKey, "竹子-熊猫");
if(!flag){
// 非阻塞式实现
return "服务器繁忙...请稍后重试!!!";
// 自旋式实现(这种实现比较耗性能,
// 实际开发过程中需配合阻塞时间配合使用)
// return minusInventory(inventory);
}
// ----只有获取锁成功才能执行下述的减库存业务----
try{
// 查询库存信息
Inventory inventoryResult =
inventoryService.selectByPrimaryKey(inventory.getInventoryId());
if (inventoryResult.getShopCount() <= 0) {
return "库存不足,请联系卖家....";
}
// 扣减库存
inventoryResult.setShopCount(inventoryResult.getShopCount() - 1);
int n = inventoryService.updateByPrimaryKeySelective(inventoryResult);
} catch (Exception e) { // 确保业务出现异常也可以释放锁,避免死锁
// 释放锁
stringRedisTemplate.delete(lockKey);
}
if (n > 0)
return "端口-" + port + ",库存扣减成功!!!";
return "端口-" + port + ",库存扣减失败!!!";
}
}
如上源码,实现了一把最基本的分布式锁,使用setnx指令往redis中写入一条数据,以当前商品ID作为key值,这样可以确保锁粒度得到控制。同时也使用try-catch保证业务执行出错时也能释放锁,可以有效避免死锁问题出现。
一条线程(一个请求)想要执行扣库存业务时,需要先往redis写入数据,当写入成功时代表获取锁成功,获取锁成功的线程可以执行业务。反之,写入失败的线程代表已经有线程在之前已经获取锁了,可以自己处理获取锁失败的逻辑,如上源码实现了非阻塞式获取锁(可自行实现阻塞+重试+次数控制)。
3.1、宕机/重启死锁问题分析
前面已经通过Redis实现了一把最基本的分布式锁,但问题在于:假设8001机器的线程T1刚刚获取锁成功,但不巧的是:8001所在的服务器宕机或断电重启了。那此时又会出现问题:获取到锁的T1线程因为所在进程/服务器挂了,所以T1线程也会被迫死亡,那此时try-catch也无法保证锁的释放,T1线程不释放锁,其他线程尝试setnx获取锁时也不会成功,最终导致了死锁现象的出现。那这个问题又该如何解决呢?加上Key过期时间即可。如下:
// 扣库存接口
@RequestMapping("/minusInventory")
public String minusInventory(Inventory inventory) {
// 获取锁
String lockKey = "lock-" + inventory.getInventoryId();
int timeOut = 100;
Boolean flag = stringRedisTemplate.opsForValue()
.setIfAbsent(lockKey, "竹子-熊猫");
// 加上过期时间,可以保证死锁也会在一定时间内释放锁
stringRedisTemplate.expire(lockKey,timeOut,TimeUnit.SECONDS);
if(!flag){
// 非阻塞式实现
return "服务器繁忙...请稍后重试!!!";
// 自旋式实现(这种实现比较耗性能,
// 实际开发过程中需配合阻塞时间配合使用)
// return minusInventory(inventory);
}
// ----只有获取锁成功才能执行下述的减库存业务----
try{
// 查询库存信息
Inventory inventoryResult =
inventoryService.selectByPrimaryKey(inventory.getInventoryId());
if (inventoryResult.getShopCount() <= 0) {
return "库存不足,请联系卖家....";
}
// 扣减库存
inventoryResult.setShopCount(inventoryResult.getShopCount() - 1);
int n = inventoryService.updateByPrimaryKeySelective(inventoryResult);
} catch (Exception e) { // 确保业务出现异常也可以释放锁,避免死锁
// 释放锁
stringRedisTemplate.delete(lockKey);
}
if (n > 0)
return "端口-" + port + ",库存扣减成功!!!";
return "端口-" + port + ",库存扣减失败!!!";
}
如上,在基础版的分布式锁中,再加上一个超时失效的机制,这样可以有效避免死锁的情况出现。就算获取到分布式锁的那条线程所在机器不小心宕机或重启了,导致无法释放锁,那也不会产生死锁情况,因为Key设置了过期时间,在设定时间内,如果没有释放锁,那么时间一到,Redis会自动释放锁,以确保其他程序的线程可以获取到锁。
OK,解决掉宕机死锁的问题后,再来看看我们自己实现的这个分布式锁是否还有缺陷呢?
3.2、加锁与过期时间原子性问题分析
从上一步的叙述中,通过设定过期时间的方式解决了宕机死锁问题,但问题在于:前面分析过,Redis处理客户端指令时采用的是单线程多路复用的模型,这就代表着只会有一条线程在处理所有客户端的请求,因为实际开发过程中,往往会有多处同时操作redis,而前面的加锁与设置过期时间两条指令对于redis是分开的,这两条指令在执行时不一定可以确保同时执行,如下:

从上图可以看到,加锁与设置过期时间这两条指令不一定会随时执行,那会出现什么问题呢?因为指令是分开执行的,所以原子性没有保证,有可能导致时间和小几率死锁问题出现。所以加锁和设置过期时间这两条指令需保证原子性,怎么操作呢?两种方式:
- ①通过Lua语言编写脚本执行:
- redis是支持lua脚本执行的,会把lua编译成sha指令,支持同时执行多条指令
- ②通过redis提供的原子性指令执行:
- 在redis2.7版本后提供了一些原子性指令,其中就包括set指令,如下:
set key value ex 100 nx
- 可以通过这条指令代替之前的
setnx与expire两条指令
- 在redis2.7版本后提供了一些原子性指令,其中就包括set指令,如下:
那在Java程序中又该如何修改代码呢?实则非常简单,在SpringBoot整合Redis的模板中,只需要把如上代码稍微修改一下即可。如下:
Boolean flag = stringRedisTemplate.opsForValue().setIfAbsent(lockKey, "竹子-熊猫",timeOut,TimeUnit.SECONDS);
3.3、过期时间的合理性分析
前面关于死锁的问题已经通过合理的锁过期失效机制解决了,那再来思考一下这个过期时间的设定是否合理呢?前面案例中,设置的是100s过期时间,乍一看感觉没啥问题,但仔细往深处一想:如果一条线程获取锁之后死亡了,其他线程想要获取锁其不是需要等到100s之后?因为需要等到redis过期删除后,释放了锁才可获取。这明显不合理,100s的时间,如果分布式锁设计成了阻塞可重试类型的,那么可能会让当前程序在100s内堆积大量请求,同时对于用户体验感也并不好,在这一百秒内,用户无论怎么重试,都不会下单成功,所以时间太长显然不合理。
那可能有小伙伴会说:“简单!时间设置的短一些不就好了嘛”,比如设置成5s。
确实,一听也没啥毛病,但再仔细一想:分布式系统中,业务执行往往会设计多个系统的RPC远程调用,因为其中涉及网络调用,网络存在不稳定因素,所以往往一个业务执行的时间是很难具体的。这样下来,如果设置的时间太短,最终可能会造成一个问题出现:业务执行时长超过锁过期时长,导致redis中key过期,最终redis释放了锁。而这个问题则会引发分布式锁的ABC问题,如下:
线程A:获取锁成功,设置过期时间为5s,执行业务逻辑
线程B:获取锁失败,阻塞等待并在一定时间后重试获取锁
线程C:获取锁失败,阻塞等待并在一定时间后重试获取锁
假设此时线程A执行业务,因为网络波动等原因,执行总时长花费了7s,那么redis会在第五秒时将key删除,因为过期了。
而恰巧线程B正好在第六秒时,重试获取锁,哟嚯~,线程B一试,发现key不在了,自然就获取锁成功了。
到了第七秒时,线程A执行完了业务,直接执行了del lock_商品ID的指令,删除了key,但此时这个锁已经是线程B的了,线程A的锁已经被redis放掉了,所以线程A释放掉了线程B的锁。
最后,线程C醒了,去重试时,又发现redis中没有了Key,也获取锁成功,执行…
通过如上案例分析,不难发现一个问题,过期时间设置的太短,会导致锁资源错乱,出现ABC问题。如上问题主要是由于两个原因导致的:①锁过期时间太短 ②非加锁线程也可以释放锁。第二个问题待会儿再解决,目前先看看锁时长怎么才能设置合理这个问题。
经过前面分析,我们发现这个时间设置长了不合适,要是短了那更不行,此时进退两难,那怎么解决呢?实际上也比较容易,可以设置一条子线程,给当前锁资源续命。
开启一条子线程,间隔2-3s去查询一次Key是否过期,如果过期了则代表业务线程已经释放了锁,如果未过期,代表业务线程还在执行业务,那么则对于key的过期时间再加上5S秒钟。为了避免业务线程死亡,当前子线程一直续命,造成“长生锁”导致死锁的情况出现,可以把子线程变为业务线程的守护线程,这样可以有效避免这个问题的出现,实现如下:
// 续命子线程
public class GuardThread extends Thread {
// 原本的key和过期时间
private String lockKey;
private int timeOut;
private StringRedisTemplate stringRedisTemplate;
private static boolean flag = true;
public GuardThread(String lockKey,
int timeOut, StringRedisTemplate stringRedisTemplate){
this.lockKey = lockKey;
this.timeOut = timeOut;
this.stringRedisTemplate = stringRedisTemplate;
}
@Override
public void run() {
// 开启循环续命
while (flag){
try {
// 先休眠一半的时间
Thread.sleep(timeOut / 2 * 1000);
}catch (Exception e){
e.printStackTrace();
}
// 时间过了一半之后再去续命
// 先查看key是否过期
Long expire = stringRedisTemplate.getExpire(
lockKey, TimeUnit.SECONDS);
// 如果过期了,代表主线程释放了锁
if (expire <= 0){
// 停止循环
flag = false;
}
// 如果还未过期
// 再为则续命一半的时间
stringRedisTemplate.expire(lockKey,expire
+ timeOut/2,TimeUnit.SECONDS);
}
}
}
// 扣库存接口
@RequestMapping("/minusInventory")
public String minusInventory(Inventory inventory) {
// 获取锁
String lockKey = "lock-" + inventory.getInventoryId();
int timeOut = 10;
Boolean flag = stringRedisTemplate.opsForValue()
.setIfAbsent(lockKey, "竹子-熊猫",timeOut,TimeUnit.SECONDS);
if(!flag){
// 非阻塞式实现
return "服务器繁忙...请稍后重试!!!";
// 自旋式实现(这种实现比较耗性能,
// 实际开发过程中需配合阻塞时间配合使用)
// return minusInventory(inventory);
}
// 创建子线程为锁续命
GuardThread guardThread = new
GuardThread(lockKey,timeOut,stringRedisTemplate);
// 设置为当前 业务线程 的守护线程
guardThread.setDaemon(true);
guardThread.start();
// ----只有获取锁成功才能执行下述的减库存业务----
try{
// 查询库存信息
Inventory inventoryResult =
inventoryService.selectByPrimaryKey(inventory.getInventoryId());
if (inventoryResult.getShopCount() <= 0) {
return "库存不足,请联系卖家....";
}
// 扣减库存
inventoryResult.setShopCount(inventoryResult.getShopCount() - 1);
int n = inventoryService.updateByPrimaryKeySelective(inventoryResult);
} catch (Exception e) { // 确保业务出现异常也可以释放锁,避免死锁
// 释放锁
stringRedisTemplate.delete(lockKey);
}
if (n > 0)
return "端口-" + port + ",库存扣减成功!!!";
return "端口-" + port + ",库存扣减失败!!!";
}
如上实现,利用了一条子线程为分布式锁续命,同时为了确保主线程意外死亡等问题造成一直续命,所以将子线程变为了主(业务)线程的守护线程,主线程死亡那么作为守护线程的子线程也会跟着死亡,可以有效避免“长生锁”的现象出现。
3.4、获取锁与释放锁线程一致性分析
在上一个问题中,我们曾提到要确保加锁与释放锁的线程一致性,这个问题比较好解决,只需要把value的值换成一个唯一值即可,然后在释放锁时判断一下是否相等即可,如下:
// 扣库存接口
@RequestMapping("/minusInventory")
public String minusInventory(Inventory inventory) {
// 获取锁
String lockKey = "lock-" + inventory.getInventoryId();
// value值变为随机的UUID值
String lockValue = UUID.randomUUID().toString();
int timeOut = 10;
Boolean flag = stringRedisTemplate.opsForValue()
.setIfAbsent(lockKey,lockValue,timeOut,TimeUnit.SECONDS);
// 省略其他代码.....
// ----只有获取锁成功才能执行下述的减库存业务----
try{
// 省略其他代码.....
} catch (Exception e) {
// 先判断是否是当前线程加的锁
if(lockVlue!=stringRedisTemplate.opsForValue().get(lockKey)){
// 不是则抛出异常
throw new RuntimeException("非法释放锁....");
}
// 确实是再释放锁
stringRedisTemplate.delete(lockKey);
}
// 省略其他代码.....
}
在获取锁的时候,把写入redis的value值换成一个随机的UUID,然后在释放锁之前,先判断一下是否为当前线程加的锁,确实为当前线程加的锁那么则释放,反之抛出异常。
3.5、Redis主从架构锁失效问题分析
在一般开发过程中,为了保证Redis的高可用,都会采用主从复制架构做读写分离,从而提升Redis整体的吞吐量以及可用性。但问题在于:Redis的主从架构下,实现分布式锁时有可能会导致锁失效,为什么呢?
因为redis主从架构中的数据不是实时复制的,而是定时/定量复制。也就代表着一条数据写入了redis主机后,并不会同时同步给所有的从机,写入的指令只要在主机上写入成功会立即返回写入成功,数据同步则是在一定时间或一定量之后才同步给从机。
这样听着感觉也没啥问题,但再仔细一思考,如果8001的线程A刚刚往主机中写入了Key,成功获取到了分布式锁,但redis主机还没来得及把新数据同步给从机,正巧因为意外宕机了,此时发生主从切换,而推选出来的新主也就是原本的旧从,因为前面宕机的主机还有部分数据未复制过来,所以新主上不会有线程A的锁记录,此时8002的线程T1来尝试获取锁,发生新主上没有锁记录,那么则获取锁成功,此时又存在了两条线程同时获取到了锁资源,同时执行业务逻辑了。
OK~,如上描述的便是Redis主从架构导致的分布式锁失效问题,此时这个问题又该如何解决呢?方案如下:
- ①红锁算法:多台独立的Redis同时写入数据,锁失效时间之内,一半以上的机器写成功则返回获取锁成功,否则返回获取锁失败,失败时会释放掉那些成功的机器上的锁。
- 优点:可以完美解决掉主从架构带来的锁失效问题
- 缺点:成本高,需要线上部署多台独立的Redis节点
- 这种算法是Redis官方提出的解决方案:红锁算法
- ②额外记录锁状态:再通过额外的中间件等独立部署的节点记录锁状态,比如在DB中记录锁状态,在尝试获取分布式锁之前需先查询DB中的锁持有记录,如果还在持有则继续阻塞,只有当状态为未持有时再尝试获取分布式锁。
- 优点:可以依赖于项目中现有的节点实现,节约部署成本
- 缺点:
- 实现需要配合定时器实现过期失效,保证锁的合理失效机制
- 获取锁的性能方面堪忧,会大大增加获取锁的性能开销
- 所有过程都需自己实现,实现难度比较复杂
- 总结:这种方式类似于两把分布式锁叠加实现,先获取一把后再获取另一把
- ③Zookeeper实现:使用Zookeeper代替Redis实现,因为Zookeeper追求的是高稳定,所以Zookeeper实现分布式锁时,不会出现这个问题(稍后分析)
3.6、Redisson框架中的分布式锁
在上述的内容中,曾从分布式锁的引出到自己实现的每个细节问题进行了分析,但实际开发过程中并不需要我们自己去实现,因为自己实现的分布式锁多多少少会存在一些隐患问题。而这些工作实际已经有框架封装了,比如:Redisson框架,其内部已经基于redis为我们封装好了分布式锁,开发过程中屏蔽了底层处理,让我们能够像使用ReetrantLock一样使用分布式锁,如下:
/* ---------pom.xml文件-------- */
<dependency>
<groupId>org.redissongroupId>
<artifactId>redissonartifactId>
<version>3.8.2version>
dependency>
/* ---------application.yml文件-------- */
spring:
redis:
database: 0
host: 192.168.12.130
port: 6379
password: 123456
timeout: 2m
// 注入redisson的客户端
@Autowired
private RedissonClient redisson;
// 写入redis的key值
String lockKey = "lock-" + inventory.getInventoryId();
// 获取一个Rlock锁对象
RLock lock = redisson.getLock(lockKey);
// 获取锁,并为其设置过期时间为10s
lock.lock(10,TimeUnit.SECONDS);
try{
// 执行业务逻辑....
} finally {
// 释放锁
lock.unlock();
}
/* ---------RedissonClient配置类-------- */
@Configuration
public class RedissonConfig {
// 读取配置文件中的配置信息
@Value("${spring.redis.host}")
private String host;
@Value("${spring.redis.port}")
private String port;
@Value("${spring.redis.password}")
private String password;
// 注入RedissonClient的Bean交由Spring管理
@Bean
public RedissonClient redisson() {
//单机模式
Config config = new Config();
config.useSingleServer().
setAddress("redis://" + host + ":" + port).
setPassword(password).setDatabase(0);
return Redisson.create(config);
}
}
如上源码,即可获得一把最基本的分布式锁,同时除开最基本的加锁方法外,还支持其他形式的获取锁:
lock.tryLock(20,10,TimeUnit.SECONDS):非阻塞式获取锁,在获取锁失败后的20s内一直尝试重新获取锁,超出20s则直接返回获取锁失败lock.lockAsync(10,TimeUnit.SECONDS):异步阻塞式获取锁,可以支持异步获取加锁的结果,该方法会返回一个Future对象,可通过Future对象异步获取加锁结果lock.tryLockAsync(20,10,TimeUnit.SECONDS):异步非阻塞式获取锁,比上面那个多了一个超时时间
同时Redisson框架中的锁实现还不仅仅只有一种,如下:
- FairLock公平锁:与
ReetrantLock一样,支持创建公平锁,即先到的线程一定优化获取锁 - MultiLock连锁:多个
RLock对象组成一把锁,也就是几把锁组成的一把锁,可以用来实现红锁算法,因为RLock对象可以不是一个Redisson创建出来的,也就是可以使用多个Redis客户端的连接对象获取多把锁组成连锁,只有当所有个锁获取成功后,才能返回获取锁成功,如果获取一把个锁失败,则返回获取锁失败 - RedLock红锁:和前面分析的Redis官方给出的红锁算法实现一致,继承了连锁,主要用于解决主从架构锁失效的问题
3.7、Redisson框架中的连锁分析
连锁向上继承了RLock,向下为RedLock提供了实现,所以它是Redisson框架中最为关键的一种锁,先来看看它的使用方式:
// 获取多个RLock锁对象(redisson可以是不同的客户端)
RLock lock1 = redisson.getLock("lock-1");
RLock lock2 = redisson.getLock("lock-2");
RLock lock3 = redisson.getLock("lock-3");
// 将多把锁组合成一把连锁,通过连锁进行获取锁与释放锁操作
RedissonMultiLock lock = new RedissonMultiLock(lock1,lock2,lock3);
// 获取锁:一半以上的锁获取成功才能成功,反之删除写入成功的节点数据
lock.lock();
// 释放锁
lock.unlock();
使用方式并不难理解,只需要创建多个RLock锁对象后,再通过多个锁对象组和成一把连锁,通过连锁对象进行获取锁与释放锁的操作即可。
3.8、Redisson框架中的连锁源码实现分析
OK~,上面简单的给出了MultiLock连锁的使用方式,接下来重点分析一下它的源码实现,源码如下:
// RedissonMultiLock类 → lock()方法
public void lock() {
try {
// 调用了lockInterruptibly获取锁
this.lockInterruptibly();
} catch (InterruptedException var2) {
// 如果出现异常则中断当前线程
Thread.currentThread().interrupt();
}
}
// RedissonMultiLock类 → lockInterruptibly()方法
public void lockInterruptibly() throws InterruptedException {
// 这里传入了-1
this.lockInterruptibly(-1L, (TimeUnit)null);
}
// RedissonMultiLock类 → lockInterruptibly()重载方法
public void lockInterruptibly(long leaseTime, TimeUnit unit)
throws InterruptedException {
// 计算基础阻塞时间:使用锁的个数*1500ms。
// 比如之前的案例:3*1500=4500ms
long baseWaitTime = (long)(this.locks.size() * 1500);
long waitTime = -1L;
// 前面传入了-1,所以进入的是if分支
if (leaseTime == -1L) {
// 挂起时间为4500,单位毫秒(MS)
waitTime = baseWaitTime;
unit = TimeUnit.MILLISECONDS;
}
// 这里是对于外部获取锁时,指定了时间情况时的处理逻辑
else {
// 将外部传入的时间转换为毫秒值
waitTime = unit.toMillis(leaseTime);
// 如果外部给定的时间小于2000ms,那么赋值为2s
if (waitTime <= 2000L) {
waitTime = 2000L;
}
// 如果传入的时间小于前面计算出的基础时间
else if (waitTime <= baseWaitTime) {
// 获取基础时间的一半,如baseWaitTime=4500ms,waitTime=2250ms
waitTime = ThreadLocalRandom.current().
nextLong(waitTime / 2L, waitTime);
} else {
// 如果外部给定的时间大于前面计算出的基础时间会进这里
// 将基础时间作为阻塞时长
waitTime = ThreadLocalRandom.current().
nextLong(baseWaitTime, waitTime);
}
// 最终计算出挂起的时间
waitTime = unit.convert(waitTime, TimeUnit.MILLISECONDS);
}
// 自旋尝试获取锁,直至获取锁成功
while(!this.tryLock(waitTime, leaseTime, unit)) {
;
}
}
上述源码中,实际上不难理解,比之前文章中分析的JUC的源码可读性强很多,上述代码中,简单的计算了一下时间后,最终自旋调用了tryLock获取锁的方法一直尝试获取锁。接着来看看tryLock方法:
// RedissonMultiLock类 → tryLock()方法
public boolean tryLock(long waitTime, long leaseTime,
TimeUnit unit) throws InterruptedException {
long newLeaseTime = -1L;
// 如果外部获取锁时,给定了过期时间
if (leaseTime != -1L) {
// 将newLeaseTime变为给定时间的两倍
newLeaseTime = unit.toMillis(waitTime) * 2L;
}
// 获取当前时间
long time = System.currentTimeMillis();
long remainTime = -1L;
// 如果不是非阻塞式获取锁
if (waitTime != -1L) {
// 将过期时间改为用户给定的时间
remainTime = unit.toMillis(waitTime);
}
// 该方法是空实现,留下的拓展接口,直接返回了传入的值
long lockWaitTime = this.calcLockWaitTime(remainTime);
// 返回0,也是拓展接口,留给子类拓展的,红锁中就拓展了这两方法
// 这个变量是允许失败的最大次数,红锁中为个数的一半
int failedLocksLimit = this.failedLocksLimit();
// 获取组成连锁的所有RLock锁集合
List<RLock> acquiredLocks = new ArrayList(this.locks.size());
// 获取list的迭代器对象
ListIterator iterator = this.locks.listIterator();
// 通过List的迭代器遍历整个连锁集合
while(iterator.hasNext()) {
RLock lock = (RLock)iterator.next();
boolean lockAcquired;
// 尝试获取锁
try {
// 如果是非阻塞式获取锁
if (waitTime == -1L && leaseTime == -1L) {
// 直接尝试获取锁
lockAcquired = lock.tryLock();
} else {
// 比较阻塞时间和过期时间的大小
long awaitTime = Math.min(lockWaitTime, remainTime);
// 尝试重新获取锁
lockAcquired = lock.tryLock(awaitTime,
newLeaseTime, TimeUnit.MILLISECONDS);
}
// 如果redis连接中断/关闭了
} catch (RedisConnectionClosedException var21) {
// 回滚获取成功的锁(删除写入成功的key)
this.unlockInner(Arrays.asList(lock));
lockAcquired = false;
// 如果在给定时间内未获取到锁
} catch (RedisResponseTimeoutException var22) {
// 也回滚所有获取成功的个锁
this.unlockInner(Arrays.asList(lock));
lockAcquired = false;
} catch (Exception var23) {
// 如果是其他原因导致的,则直接返回获取锁失败
lockAcquired = false;
}
// 如果获取一把个锁成功
if (lockAcquired) {
// 那么则记录获取成功的个锁
acquiredLocks.add(lock);
} else {
// 如果获取一把个锁失败,此次失败的次数已经达到了
// 最大的失败次数,那么直接退出循环,放弃加锁操作
if (this.locks.size() - acquiredLocks.size()
== this.failedLocksLimit()) {
break;
}
// 允许失败的次数未0,获取一个个锁失败则回滚
if (failedLocksLimit == 0) {
// 回滚所有成功的锁
this.unlockInner(acquiredLocks);
// 如果是非阻塞式获取锁,则直接返回获取锁失败
if (waitTime == -1L && leaseTime == -1L) {
return false;
}
// 获取最新的失败锁的个数
failedLocksLimit = this.failedLocksLimit();
acquiredLocks.clear();
// 移动迭代器的指针位置到上一个
while(iterator.hasPrevious()) {
iterator.previous();
}
// 如果允许失败的次数不为0
} else {
// 每获取个锁失败一次就减少一个数
--failedLocksLimit;
}
}
// 如果不是非阻塞式获取锁
if (remainTime != -1L) {
// 计算本次获取锁的所耗时长
remainTime -= System.currentTimeMillis() - time;
time = System.currentTimeMillis();
// 如果已经超出了给定时间,则回滚所有成功的锁
if (remainTime <= 0L) {
this.unlockInner(acquiredLocks);
// 返回获取锁失败
return false;
}
}
}
// 能执行到这里肯定是已经获取锁成功了
// 判断是否设置了过期时间,如果设置了
if (leaseTime != -1L) {
// 获取加锁成功的个锁集合
List<RFuture<Boolean>> futures = new ArrayList(acquiredLocks.size());
Iterator var25 = acquiredLocks.iterator();
// 迭代为每个获取成功的个锁创建异步任务对象
while(var25.hasNext()) {
RLock rLock = (RLock)var25.next();
RFuture<Boolean> future =
rLock.expireAsync(unit.toMillis(leaseTime),
TimeUnit.MILLISECONDS);
futures.add(future);
}
// 获取Future的个锁集合迭代器对象
var25 = futures.iterator();
// 迭代每个Futrue对象
while(var25.hasNext()) {
RFuture<Boolean> rFuture = (RFuture)var25.next();
// 异步为每个获取个锁成功的对象设置过期时间
rFuture.syncUninterruptibly();
}
}
// 返回获取锁成功
return true;
}
如上源码,流程先不分析,先感慨一句:虽然看着长,但!!!真心的比JUC中的源码可读性和易读性高N倍,每句代码都容易弄懂,阅读起来并不算费劲。
OK~,感慨完之后来总结一下tryLock加锁方法的总体逻辑:
- ①计算出阻塞时间、最大失败数以及过期时间,然后获取所有组成连锁的个锁集合
- ②迭代每把个锁,尝试对每把个锁进行加锁,加锁是也会判断获取锁的方式是否为非阻塞式的:
- 是:直接获取锁
- 否:阻塞式获取锁,在给定时间内会不断尝试获取锁
- ③判断个锁是否获取成功:
- 成功:将获取成功的个锁添加到加锁成功的集合
acquiredLocks集合中 - 失败:判断此次获取锁失败的次数是否已经达到了允许的最大失败次数:
- 是:放弃获取锁,回滚所有获取成功的锁,返回获取锁失败
- 否:允许失败次数自减,继续尝试获取下一把个锁
- 注意:连锁模式下最大失败次数=0,红锁模式下为个锁数量的一半
- 成功:将获取成功的个锁添加到加锁成功的集合
- ④判断目前获取锁过程的耗时是否超出了给定的阻塞时长:
- 是:回滚所有获取成功的锁,然后返回获取锁失败
- 否:继续获取下把个锁
- ⑤如果连锁获取成功(代表所有个都锁获取成功),判断是否指定了过期时间:
- 是:异步为每个加锁成功的个锁设置过期时间并返回获取锁成功
- 否:直接返回获取锁成功
虽然获取锁的代码看着长,但其逻辑并不算复杂,上述过程是连锁的实现,而红锁则是依赖于连锁实现的,也比较简单,只是重写failedLocksLimit()获取允许失败次数的方法,允许获取锁失败的次数变为了个锁数量的一半以及略微加了一些小拓展,感兴趣的可以自己去分析其实现。
接着来看看释放锁的源码实现:
// RedissonMultiLock类 → unlock()方法
@Override
public void unlock() {
// 创建为没把个锁创建一个Future
List<RFuture<Void>> futures = new
ArrayList<RFuture<Void>>(locks.size());
// 遍历所有个锁
for (RLock lock : locks) {
// 释放锁
futures.add(lock.unlockAsync());
}
// 阻塞等待所有锁释放成功后再返回
for (RFuture<Void> future : futures) {
future.syncUninterruptibly();
}
}
// RedissonMultiLock类 → unlockInnerAsync()方法
protected RFuture<Boolean> unlockInnerAsync(long threadId) {
// 获取个锁的Key名称并通过Lua脚本释放锁(确保原子性)
return commandExecutor.evalWriteAsync(getName(),
LongCodec.INSTANCE, RedisCommands.EVAL_BOOLEAN,
"if (redis.call('exists', KEYS[1]) == 0) then " +
"redis.call('publish', KEYS[2], ARGV[1]); " +
"return 1; " +
"end;" +
"if (redis.call('hexists', KEYS[1], ARGV[3]) == 0) then " +
"return nil;" +
"end; " +
"local counter = redis.call('hincrby', KEYS[1], ARGV[3], -1); " +
"if (counter > 0) then " +
"redis.call('pexpire', KEYS[1], ARGV[2]); " +
"return 0; " +
"else " +
"redis.call('del', KEYS[1]); " +
"redis.call('publish', KEYS[2], ARGV[1]); " +
"return 1; "+
"end; " +
"return nil;",
Arrays.<Object>asList(getName(), getChannelName()),
LockPubSub.unlockMessage, internalLockLeaseTime,
getLockName(threadId));
}
释放锁的逻辑更加简单,遍历所有的个锁,然后异步通过Lua脚本删除所有的key,在连锁的释放代码中会同步阻塞等待所有锁的Key删除后再返回。
四、Zookeeper实现分布式锁剖析
Zookeeper分布式锁是依赖于其内部的顺序临时节点实现的,其原理就类似于最开始举例的那个文件夹分布式锁,因为Zookeeper实际上就类似于一个文件系统的结构。我们可以通过Curator框架封装的API操作Zookeeper,完成分布式锁的实现。如下:
// 创建分布式锁对象
InterProcessMutex lock = InterProcessMutex(client,
"/locks/distributed_商品ID");
lock.acquire(); // 获取锁/加锁
// 执行业务逻辑...
lock.release(); // 释放锁
如上,通过Curator实现分布式锁非常简单,因为已经封装好了API,所以应用起来也非常方便,同时Zookeeper也可以实现公平锁与非公平锁两种方案,如下:
- 公平锁:先请求锁的线程一定先获取锁
- 实现方式:通过临时顺序节点实现,每条线程请求锁时为其创建一个有序节点,创建完成之后判断自己创建的节点是不是最小的,如果是则直接获取锁成功,反之获取锁失败,创建一个监听器,监听自己节点的前一个节点状态,当前一个节点被删除(代表前一个节点的创建线程释放了锁)自己尝试获取锁
- 优劣势:可以保证请求获取锁的有序性,但性能方面比非公平锁低
- 非公平锁:先请求锁的线程不一定先获取锁
- 实现方式:多条线程在同一目录下,同时创建一个名字相同的节点,谁创建成功代表获取锁成功,反之则代表获取锁失败
- 优劣势:性能良好,但无法保证请求获取锁时的有序性
对于这两种实现方式,非公平锁的方案与前面的Redis实现差不多,所以不再分析。下面重点来分析一下Zookeeper实现分布式的公平锁的大致原理。但在分析之前先简单说明一些Zookeeper中会用到的概念。如下:
- 节点类型:
- ①持久节点:被创建后会一直存在的节点信息,除非有删除操作主动清楚才会销毁
- ②持久顺序节点:持久节点的有序版本,每个新创建的节点会在后面维护自增值保持先后顺序,可以用于实现分布式全局唯一ID
- ③临时节点:被创建后与客户端的会话生命周期保持一致,连接断开则自动销毁
- ④临时顺序节点:临时节点的有序版本,与其多了一个有序性。分布式锁则依赖这种类型实现
- 监视器:当zookeeper创建一个节点时,会为该节点注册一个监视器,当节点状态发生改变时,watch会被触发,zooKeeper将会向客户端发送一条通知。不过值得注意的是watch只能被触发一次
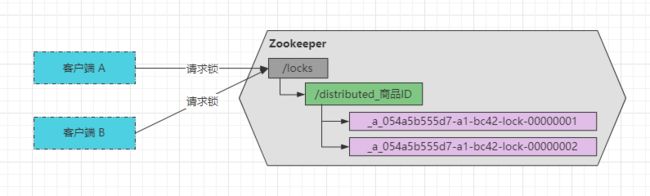
ok~,假设目前8001服务中的线程T1尝试获取锁,那么会T1会在Zookeeper的/locks/distributed_商品ID目录下创建一个临时节点,Zookeeper内部会生成一个名字为xxx....-0000001临时顺序节点。当第二条线程来尝试获取锁时,也会在相同位置创建一个临时顺序节点,名字为xxx....-0000002。值得注意的是最后的数字是一个递增的状态,从1开始自增,Zookeeper会维护这个先后顺序。如下图:
当线程创建节点完成后,会查询/locks/distributed_商品ID目录下所有的子节点,然后会判断自己创建的节点是不是在所有节点的第一个,也就是判断自己的节点是否为最小的子节点,如果是的话则获取锁成功,因为当前线程是第一个来获取分布式锁的线程,在它之前是没有线程获取锁的,所以当然可以加锁成功,然后开始执行业务逻辑。如下:
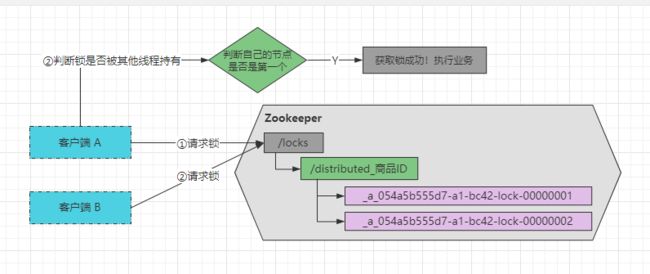
而第二条线程创建节点成功后,也会去判断自己是否是最小的节点。哦豁!第二条线程判断的时候会发现,在自己的节点之前还有一个xxx...-0001节点,所以代表在自己前面已经有线程持有了分布式锁,所以会对上个节点加上一个监视器,监视上个节点的状态变化。如下:
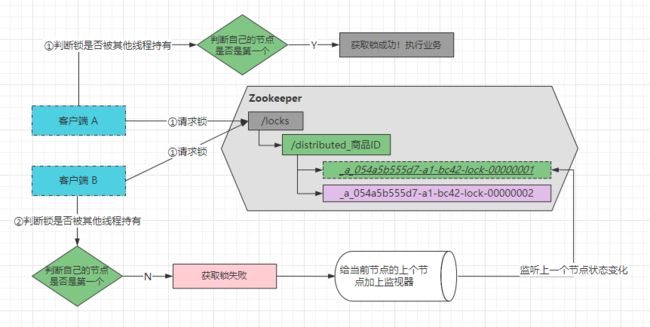
此时,第一条线程T1执行完了业务代码,准备释放锁,也就是删除自己创建的xxx...-0001临时顺序节点。而第二条线程创建的监视器会监视着前面一个节点的状态,当发现前面的节点已经被删除时,就知道前面一条线程已经执行完了业务,释放了锁资源,所以再次尝试获取锁。如下:
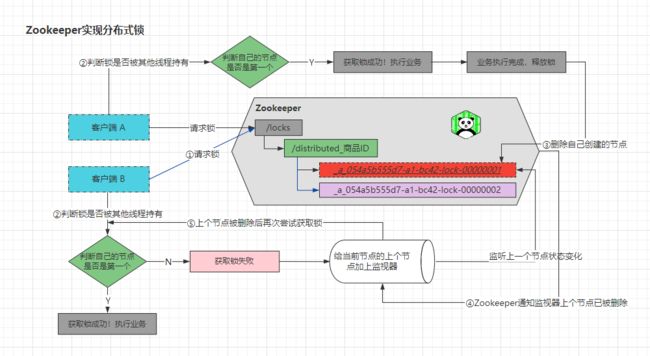
第二条线程重新尝试获取锁时,拿到当前目录下的所有节点判断发现,哟!自己是第一个(最小的那个)节点啊?然后获取锁成功,开始执行业务逻辑,后续再来新的线程则依次类推…
至此,整个Zookeeper实现分布式锁的过程分析完毕,关于自己动手基于Zookeeper实现一遍我这边就不再写了,大家可以自习了解。实际开发过程中,Curator框架自带的分布式锁实现便已经够用了,同时使用也非常的方便。
五、分布式锁性能优化
经过前述的分析,大家对分布式锁应该都有一个全面认知了,但是请思考:如果对于类似于抢购、秒杀业务,又该如何处理呢?因为在这种场景下,往往在一段时间内会有大量用户去请求同一个商品。从技术角度出发,这样会导致在同一时间内会有大量的线程去请求同一把锁。这会有何种隐患呢?会出现的问题是:虽然并发能抗住,但是对于用户体验感不好,同时大量的用户点击抢购,但是只能有一个用户抢购成功,明显不合理,这又该如何优化?
参考并发容器中的分段容器,可以将共享资源(商品库存)做提前预热,分段分散到redis中。举个例子:
1000个库存商品,10W个用户等待抢购,抢购开始时间为下午15:00
提前预热:两点半左右开始将商品数量拆成10份或N份,如:[shopping_01;0-100]、[shopping_02;101-200]、[shopping_03;201-300]、[…]
也就是往redis中写入十个key,值为100,在抢购时,过来的请求随机分散到某个key上去,但是在扣减库存之前,需要先获取锁,这样就同时有了十把锁,性能自然就上去了。
六、分布式锁总结
本篇中从单机锁的隐患 -> 分布式架构下的安全问题引出 -> 分布式锁的实现推导 -> redis实现分布式锁 -> redis实现分布式锁的细节问题分析 -> redisson框架实现及其连锁应用与源码分析 -> zookeeper实现分布式锁 -> zookeeper实现原理这条思路依次剖析了分布式锁的前世今生,总的一句话概括分布式锁的核心原理就是:在多个进程中所有线程都可见的区域实现了互斥量而已。
最后再来说说Redis与Zookeeper实现的区别与项目中如何抉择?
Redis数据不是实时同步的,主机写入成功后会立即返回,存在主从架构锁失效问题。
Zookeeper数据是实时同步的,主机写入后需一半节点以上写入成功才会返回。
所以如果你的项目追求高性能,可以放弃一定的稳定性,那么推荐使用Redis实现。比如电商、线上教育等类型的项目。
但如果你的项目追求高稳定,愿意牺牲一部分性能换取稳定性,那么推荐使用Zookeeper实现。比如金融、银行、政府等类型的项目。
当然,如果你的项目是基于SpringCloud开发的,也可以考虑使用SpringCloud的全局锁,但是不推荐,一般还是优先考虑Redis和Zookeeper。