4.8 Pandas中的Dataframe 缺失值NaN数据处理(Python)
Pandas中的Dataframe 缺失值NaN数据处理
- 目录
-
-
- 前言
- 一、初期数据准备
-
- 1. 初期数据定义
- 二、Dataframe 缺失值NaN数据处理
-
- ==1. 特殊值替换缺失值==
- ==2. 空值处理函数fillna替换缺失值==
- ==3. 使用邻值填充缺失值==
- ==4. 使用众数填充缺失值==
- ==5. 使用平均数填充缺失值==
-
目录
前言
数据的缺失导致NaN的出现,直接插入DB中会报错,所以要特殊处理一下。
一、初期数据准备
1. 初期数据定义
# -*- coding: utf-8 -*-
import numpy as np
import pandas as pd
data = {
'name': ['NAME0', 'NAME1', 'NAME2', 'NAME3', 'NAME4', 'NAME5', 'NAME6', 'NAME7', 'NAME8', 'NAME9'],
'age': [0, 1, 2, 3, 4, 5, 6, 7, 8, 9],
'weight': ["weight0", 101, 102, np.nan, np.nan, 105, np.nan, 107, 108, 109],
'is_single_dog': ['yes', 'yes', 'no', 'yes', 'no', 'no', 'no', 'yes', 'no', 'no']
}
indexs = ['index0', 'index1', 'index2', 'index3', 'index4', 'index5', 'index6', 'index7', 'index8', 'index9']
df = pd.DataFrame(data, index=indexs)
print(df)
控制台输出结果:
name age weight isMarried
index0 NAME0 0 weight0 yes
index1 NAME1 1 101 yes
index2 NAME2 2 102 no
index3 NAME3 3 NaN yes
index4 NAME4 4 NaN no
index5 NAME5 5 105 no
index6 NAME6 6 NaN no
index7 NAME7 7 107 yes
index8 NAME8 8 108 no
index9 NAME9 9 109 no
二、Dataframe 缺失值NaN数据处理
1. 特殊值替换缺失值
# 用0替换NaN
df = df.where(df.notnull(), 0)
print(df)
控制台输出结果:
name age weight is_single_dog
index0 NAME0 0 weight0 yes
index1 NAME1 1 101 yes
index2 NAME2 2 102 no
index3 NAME3 3 0 yes
index4 NAME4 4 0 no
index5 NAME5 5 105 no
index6 NAME6 6 0 no
index7 NAME7 7 107 yes
index8 NAME8 8 108 no
index9 NAME9 9 109 no
# 用''替换NaN
df = df.where(df.notnull(), '')
print(df)
控制台输出结果:
name age weight is_single_dog
index0 NAME0 0 weight0 yes
index1 NAME1 1 101 yes
index2 NAME2 2 102 no
index3 NAME3 3 yes
index4 NAME4 4 no
index5 NAME5 5 105 no
index6 NAME6 6 no
index7 NAME7 7 107 yes
index8 NAME8 8 108 no
index9 NAME9 9 109 no
# 用None替换NaN
df = df.where(df.notnull(), None)
print(df)
控制台输出结果:
name age weight is_single_dog
index0 NAME0 0 weight0 yes
index1 NAME1 1 101 yes
index2 NAME2 2 102 no
index3 NAME3 3 None yes
index4 NAME4 4 None no
index5 NAME5 5 105 no
index6 NAME6 6 None no
index7 NAME7 7 107 yes
index8 NAME8 8 108 no
index9 NAME9 9 109 no
2. 空值处理函数fillna替换缺失值
fillna函数的属性:
| 属性 | 描述 |
|---|---|
| value | 标量值或字典型对象用于填充缺失值 |
| method | 插值方法,如果没有其他参数,默认是‘ffill’ |
| axis | 需要填充轴,默认axis=0(横轴) |
| inplace | 修改被调用对象,而不是生成一个备份 |
| limit | 用于前向或后向填充时最大的填充范围 |
# 用0替换NaN
df = df.fillna(value=0)
print(df)
控制台输出结果:
name age weight is_single_dog
index0 NAME0 0 weight0 yes
index1 NAME1 1 101 yes
index2 NAME2 2 102 no
index3 NAME3 3 0 yes
index4 NAME4 4 0 no
index5 NAME5 5 105 no
index6 NAME6 6 0 no
index7 NAME7 7 107 yes
index8 NAME8 8 108 no
index9 NAME9 9 109 no
# 用''替换NaN
df = df.fillna(value='')
print(df)
控制台输出结果:
name age weight is_single_dog
index0 NAME0 0 weight0 yes
index1 NAME1 1 101 yes
index2 NAME2 2 102 no
index3 NAME3 3 yes
index4 NAME4 4 no
index5 NAME5 5 105 no
index6 NAME6 6 no
index7 NAME7 7 107 yes
index8 NAME8 8 108 no
index9 NAME9 9 109 no
# 用None替换NaN
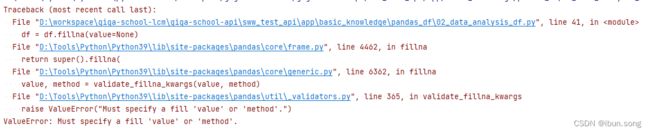
df = df.fillna(value=None)
print(df)
控制台输出结果:
ValueError: Must specify a fill 'value' or 'method'.
# 用None替换NaN 改成 用'None'替换NaN
df = df.fillna(value='None')
print(df)
控制台输出结果:
name age weight is_single_dog
index0 NAME0 0 weight0 yes
index1 NAME1 1 101 yes
index2 NAME2 2 102 no
index3 NAME3 3 None yes
index4 NAME4 4 None no
index5 NAME5 5 105 no
index6 NAME6 6 None no
index7 NAME7 7 107 yes
index8 NAME8 8 108 no
index9 NAME9 9 109 no
3. 使用邻值填充缺失值
# 用上一行的值填充,最大填充范围为1行
df = df.fillna(method = 'ffill', limit=1)
print(df)
控制台输出结果:
name age weight is_single_dog
index0 NAME0 0 weight0 yes
index1 NAME1 1 101 yes
index2 NAME2 2 102 no
index3 NAME3 3 102 yes
index4 NAME4 4 NaN no
index5 NAME5 5 105 no
index6 NAME6 6 105 no
index7 NAME7 7 107 yes
index8 NAME8 8 108 no
index9 NAME9 9 109 no
注意事项: 如果某列有连续2行值为NaN,最大填充范围为1行,则第2行的值不会被充填,仍为NaN
# 用下一行的值填充,最大填充范围为2行
df = df.fillna(method = 'backfill', limit=2)
print(df)
控制台输出结果:
name age weight is_single_dog
index0 NAME0 0 weight0 yes
index1 NAME1 1 101 yes
index2 NAME2 2 102 no
index3 NAME3 3 105 yes
index4 NAME4 4 105 no
index5 NAME5 5 105 no
index6 NAME6 6 107 no
index7 NAME7 7 107 yes
index8 NAME8 8 108 no
index9 NAME9 9 109 no
4. 使用众数填充缺失值
# 用出现次数最多的值来填充NaN
df['weight'] = df['weight'].fillna(df['weight'].mode()[0])
print(df)
控制台输出结果:
UserWarning: Unable to sort modes: '<' not supported between instances of 'str' and 'int'
warn(f"Unable to sort modes: {err}")
name age weight is_single_dog
index0 NAME0 0 weight0 yes
index1 NAME1 1 101 yes
index2 NAME2 2 102 no
index3 NAME3 3 101 yes
index4 NAME4 4 101 no
index5 NAME5 5 105 no
index6 NAME6 6 101 no
index7 NAME7 7 107 yes
index8 NAME8 8 108 no
index9 NAME9 9 109 no
5. 使用平均数填充缺失值
# 用平均数的值来填充NaN
df['weight'] = df['weight'].fillna(df['weight']..mean())
print(df)
完整代码:
# -*- coding: utf-8 -*-
import numpy as np
import pandas as pd
data = {
'name': ['NAME0', 'NAME1', 'NAME2', 'NAME3', 'NAME4', 'NAME5', 'NAME6', 'NAME7', 'NAME8', 'NAME9'],
'age': [0, 1, 2, 3, 4, 5, 6, 7, 8, 9],
'weight': [101, 101, 102, np.nan, np.nan, 105, np.nan, 107, 108, 109],
'is_single_dog': ['yes', 'yes', 'no', 'yes', 'no', 'no', 'no', 'yes', 'no', 'no']
}
indexs = ['index0', 'index1', 'index2', 'index3', 'index4', 'index5', 'index6', 'index7', 'index8', 'index9']
df = pd.DataFrame(data, index=indexs)
print(df)
print()
# 用平均数的值来填充NaN
df['weight'] = df['weight'].fillna(df['weight'].mean())
print(df)
控制台输出结果:
name age weight is_single_dog
index0 NAME0 0 101.0 yes
index1 NAME1 1 101.0 yes
index2 NAME2 2 102.0 no
index3 NAME3 3 NaN yes
index4 NAME4 4 NaN no
index5 NAME5 5 105.0 no
index6 NAME6 6 NaN no
index7 NAME7 7 107.0 yes
index8 NAME8 8 108.0 no
index9 NAME9 9 109.0 no
name age weight is_single_dog
index0 NAME0 0 101.000000 yes
index1 NAME1 1 101.000000 yes
index2 NAME2 2 102.000000 no
index3 NAME3 3 104.714286 yes
index4 NAME4 4 104.714286 no
index5 NAME5 5 105.000000 no
index6 NAME6 6 104.714286 no
index7 NAME7 7 107.000000 yes
index8 NAME8 8 108.000000 no
index9 NAME9 9 109.000000 no