XXL-JOB原理
XXL-JOB是一个分布式任务调度平台,其核心设计目标是开发迅速、学习简单、轻量级、易扩展。现已开放源代码并接入多家公司线上产品线,开箱即用。在众多XXL-Job平台的特征中,有如下几条需要关注的:
1、使用简单:支持通过Web页面对任务配置,降低操作任务的难度;
2、动态:支持动态修改任务状态、启动/停止任务,以及终止运行中任务,即时生效;
3、调度中心HA(中心式):调度采用中心式设计,“调度中心”自研调度组件并支持集群部署,可保证调度中心HA;
4、执行器HA(分布式):任务分布式执行,任务”执行器”支持集群部署,可保证任务执行HA;
5、注册中心: 执行器会周期性自动注册任务, 调度中心将会自动发现注册的任务并触发执行。同时,也支持手动录入执行器地址;
6、弹性扩容缩容:一旦有新执行器机器上线或者下线,下次调度时将会重新分配任务;
7、触发策略:提供丰富的任务触发策略,包括:Cron触发、固定间隔触发、固定延时触发、API(事件)触发、人工触发、父子任务触发;
其他的特性这里不赘述了,有兴趣的同学可以去官网查看。
3.XXL-Job系统组成
在XXL-Job的设计思路中将调度行为抽象形成“调度中心”公共平台,而平台自身并不承担业务逻辑,“调度中心”负责发起调度请求。将任务抽象成分散的JobHandler,交由“执行器”统一管理,“执行器”负责接收调度请求并执行对应的JobHandler中业务逻辑。因此,“调度”和“任务”两部分可以相互解耦,提高系统整体稳定性和扩展性。
如图1 所示,我们来分别描述调度中心和执行器肩负的工作:
调度中心: 负责管理调度信息,按照调度配置发出调度请求,自身不承担业务代码。调度系统与任务解耦,提高了系统可用性和稳定性,同时调度系统性能不再受限于任务模块; 支持可视化、简单且动态的管理调度信息,包括任务新建,更新,删除,任务报警等,所有上述操作都会实时生效,同时支持监控调度结果以及执行日志,支持执行器Failover
执行器: 负责接收调度请求并执行任务逻辑。任务模块专注于任务的执行等操作,开发和维护更加简单和高效; 接收“调度中心”的执行请求、终止请求和日志请求等
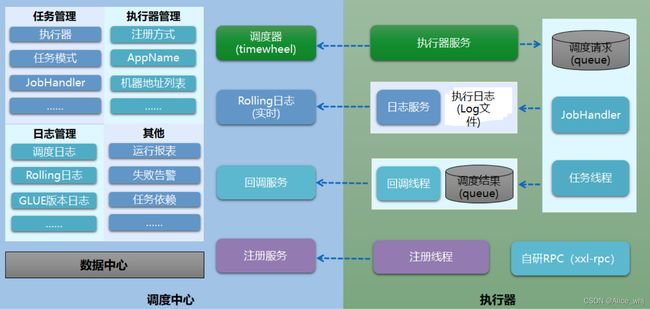
4.XXL-Job工作原理
前面说了调度中心和执行器之间是如何分工的,接下来介绍一下两者之间是如何协同工作的,这部分也是XXL-Job的工作原理,如图2所示。
任务执行器根据配置的调度中心的地址,启动注册线程向调度中心的执行器管理发起自动注册。执行器管理中保存着注册执行器,后续会根据这个注册信息给执行器下发任务。
如果此时有需要执行的任务,任务管理模块会根据执行器管理中注册的执行器信息,向任务执行器下发任务。任务执行器中的任务执行服务接受到任务以后会将任务发送到待执行任务的队列中,队列中的任务会由执行线程JobHandler依次获取并且执行。这里会维护一个任务执行的线程池,池中就是一个个JobHandler线程,它们是执行任务的主力军。
JobHandler执行器基于线程池执行任务,并把执行结果放入执行结果队列中,同时会把执行日志写入任务日志文件中,以供日志查询。然后通知毁掉线程,告知任务执行完毕,回调线程会通知调度中心的监控运维模块,任务执行完毕。
用户可以在调度中心查看任务日志,其过程是通过发送日志查询请求给任务执行器中的日志服务,然后查询任务日志文件实现的。

特性:
动态:支持动态修改任务状态、启动/停止任务,以及终止运行中任务,即时生效;
调度中心HA(中心式):调度采用中心式设计,“调度中心”自研调度组件并支持集群部署,可保证调度中心HA;
执行器HA(分布式):任务分布式执行,任务”执行器”支持集群部署,可保证任务执行HA;弹性扩容缩容:一旦有新执行器机器上线或者下线,下次调度时将会重新分配任务;
触发策略:提供丰富的任务触发策略,包括:Cron触发、固定间隔触发、固定延时触发、API(事件)触发、人工触发、父子任务触发;
调度过期策略:调度中心错过调度时间的补偿处理策略,包括:忽略、立即补偿触发一次等;
阻塞处理策略:调度过于密集执行器来不及处理时的处理策略,策略包括:单机串行(默认)、丢弃后续调度、覆盖之前调度;
任务失败重试:支持自定义任务失败重试次数,当任务失败时将会按照预设的失败重试次数主动进行重试;其中分片任务支持分片粒度的失败重试;
任务失败告警;默认提供邮件方式失败告警,同时预留扩展接口,可方便的扩展短信、钉钉等告警方式;
路由策略:执行器集群部署时提供丰富的路由策略,包括:第一个、最后一个、轮询、随机、一致性HASH、最不经常使用、最近最久未使用、故障转移、忙碌转移等;
分片广播任务:执行器集群部署时,任务路由策略选择”分片广播”情况下,一次任务调度将会广播触发集群中所有执行器执行一次任务,可根据分片参数开发分片任务;
故障转移:任务路由策略选择”故障转移”情况下,如果执行器集群中某一台机器故障,将会自动Failover切换到一台正常的执行器发送调度请求。
任务依赖:支持配置子任务依赖,当父任务执行结束且执行成功后将会主动触发一次子任务的执行, 多个子任务用逗号分隔;
运行报表:支持实时查看运行数据,如任务数量、调度次数、执行器数量等;以及调度报表,如调度日期分布图,调度成功分布图等;
集群部署
调度中心支持集群部署,提升调度系统容灾和可用性。
调度中心集群部署时,要求和建议:
DB配置保持一致;
集群机器时钟保持一致;
建议:推荐通过nginx为调度中心集群做负载均衡,分配域名。调度中心访问、执行器回调配置、调用API服务等操作均通过该域名进行。
新建任务
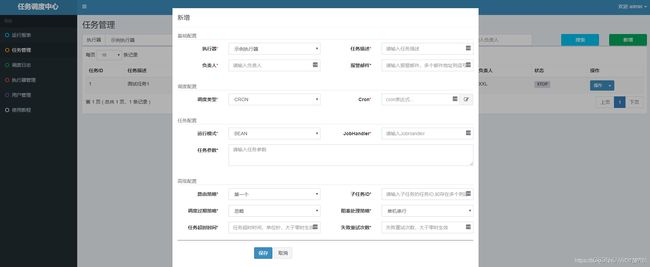
基础配置:
执行器:任务的绑定的执行器,任务触发调度时将会自动发现注册成功的执行器, 实现任务自动发现功能; 另一方面也可以方便的进行任务分组。每个任务必须绑定一个执行器, 可在 “执行器管理” 进行设置;
任务描述:任务的描述信息,便于任务管理;
负责人:任务的负责人;
报警邮件:任务调度失败时邮件通知的邮箱地址,支持配置多邮箱地址,配置多个邮箱地址时用逗号分隔;
触发配置:
调度类型:
无:该类型不会主动触发调度;
CRON:该类型将会通过CRON,触发任务调度;
固定速度:该类型将会以固定速度,触发任务调度;按照固定的间隔时间,周期性触发;
固定延迟:该类型将会以固定延迟,触发任务调度;按照固定的延迟时间,从上次调度结束后开始计算延迟时间,到达延迟时间后触发下次调度;
CRON:触发任务执行的Cron表达式;
固定速度:固件速度的时间间隔,单位为秒;
固定延迟:固件延迟的时间间隔,单位为秒;
任务配置:
运行模式:
BEAN模式:任务以JobHandler方式维护在执行器端;此时写 @XxlJob注解中的值;
GLUE模式(Shell):任务以源码方式维护在调度中心;该模式的任务实际上是一段 “shell” 脚本;
GLUE模式(Python):任务以源码方式维护在调度中心;该模式的任务实际上是一段 “python” 脚本;
GLUE模式(PowerShell):任务以源码方式维护在调度中心;该模式的任务实际上是一段 “PowerShell” 脚本;
JobHandler:运行模式为 “BEAN模式” 时生效,对应执行器中新开发的JobHandler类“@JobHandler”注解自定义的value值;
执行参数:任务执行所需的参数;
高级配置:
路由策略:当执行器集群部署时,提供丰富的路由策略,包括;
FIRST(第一个):固定选择第一个机器;
LAST(最后一个):固定选择最后一个机器;
ROUND(轮询):;
RANDOM(随机):随机选择在线的机器;
CONSISTENT_HASH(一致性HASH):每个任务按照Hash算法固定选择某一台机器,且所有任务均匀散列在不同机器上。
LEAST_FREQUENTLY_USED(最不经常使用):使用频率最低的机器优先被选举;
LEAST_RECENTLY_USED(最近最久未使用):最久未使用的机器优先被选举;
FAILOVER(故障转移):按照顺序依次进行心跳检测,第一个心跳检测成功的机器选定为目标执行器并发起调度;
BUSYOVER(忙碌转移):按照顺序依次进行空闲检测,第一个空闲检测成功的机器选定为目标执行器并发起调度;
SHARDING_BROADCAST(分片广播):广播触发对应集群中所有机器执行一次任务,同时系统自动传递分片参数;可根据分片参数开发分片任务;
子任务:每个任务都拥有一个唯一的任务ID(任务ID可以从任务列表获取),当本任务执行结束并且执行成功时,将会触发子任务ID所对应的任务的一次主动调度。
调度过期策略:
忽略:调度过期后,忽略过期的任务,从当前时间开始重新计算下次触发时间;
立即执行一次:调度过期后,立即执行一次,并从当前时间开始重新计算下次触发时间;
阻塞处理策略:调度过于密集执行器来不及处理时的处理策略;
单机串行(默认):调度请求进入单机执行器后,调度请求进入FIFO队列并以串行方式运行;
丢弃后续调度:调度请求进入单机执行器后,发现执行器存在运行的调度任务,本次请求将会被丢弃并标记为失败;
覆盖之前调度:调度请求进入单机执行器后,发现执行器存在运行的调度任务,将会终止运行中的调度任务并清空队列,然后运行本地调度任务;
任务超时时间:支持自定义任务超时时间,任务运行超时将会主动中断任务;
失败重试次数;支持自定义任务失败重试次数,当任务失败时将会按照预设的失败重试次数主动进行重试;