GPU的架构(一)
gpu的驱动框架:

1、窗口标准的实现是与操作系统强相关的,它为图形渲染提供目标内存。一般来说,只要支持的标准不变,操作系统更换/升级,对驱动的代码影响就只限在窗口这一块。
2、编译器用于编译shader或kernel,编译kernel需要用llvm预编译,编译器会大一些。低端GPU的编译器特别容易出现各种语法不支持,让写shader的人痛苦万分。
3、通用计算的实现就是把kernel编译后转成任务扔给内核去跑,相对简单。
4、图形渲染的实现则需要考虑到一帧中可能有重复渲染/过度绘制的情况,为了这方面做优化,一帧中的任务有必要做一下组织,因此要有个帧管理器模块。
5、内存管理用于管理显存,但显存不一定是在GPU芯片上(独显和集显的区别)。
6、不管上层玩得多么风生水起,到了内核都是一个个的任务,内核模块执行、调度便是。
GPU在不同平台的异构性:
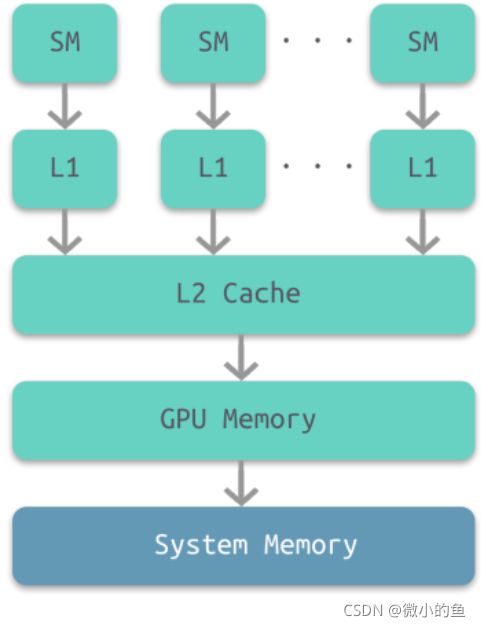
GPU也是有多级缓存结构的:寄存器、L1缓存、L2缓存、GPU显存、系统内存。它们的访问周期对应下表,我们可以看到,直接访问寄存器其实是最快的,接下来就依次是L1, L2缓存,系统内存之类的。

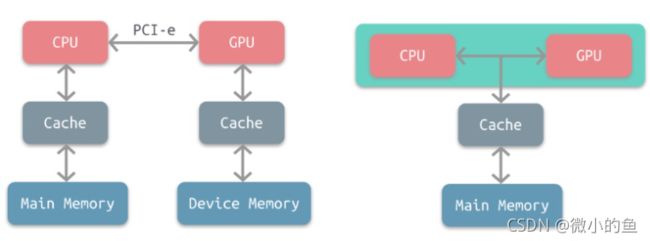
分别是 分离架构与耦合式架构
GPU在不同平台的异构性的时候,主要指的就是PC和Mobile平台,就算它们用到的都是分离式架构
用NVidia Fermi架构举例说明:

GPC(图形处理簇) TPC(Texture/Processor Cluster,纹理处理簇)SM(Stream Multiprocessor,流多处理器)每个SM包含:SP(Streaming Processor,流处理器)SFU(Special Function Unit,特殊函数单元)L1缓存、MT Issue(多线程指令获取)、C-Cache(常量缓存)、共享内存;除了TPC核心单元,还有与显存、CPU、系统内存交互的各种部件;
但是对于NVidia Fermi架构
拥有16个SM
每个SM:
- 2个Warp(线程束)
- 两组共32个Core
- 16组加载存储单元(LD/ST)
- 4个特殊函数单元(SFU)
每个Warp:
- 16个Core Warp编排器(Warp Scheduler)
- 分发单元(Dispatch Unit)
每个Core:
- 1个FPU(浮点数单元)
- 1个ALU(逻辑运算单元)
从Fermi开始NVIDIA使用类似的原理架构,使用一个Giga Thread Engine来管理所有正在进行的工作,GPU被划分成多个GPCs(Graphics Processing Cluster),每个GPC拥有多个SM(SMX、SMM)和一个光栅化引擎(Raster Engine),它们其中有很多的连接,最显著的是Crossbar,它可以连接GPCs和其它功能性模块(例如ROP或其他子系统)。
程序员编写的shader是在SM上完成的。每个SM包含许多为线程执行数学运算的Core(核心)。例如,一个线程可以是顶点或像素着色器调用。这些Core和其它单元由Warp Scheduler驱动,Warp Scheduler管理一组32个线程作为Warp(线程束)并将要执行的指令移交给Dispatch Units。 GPU中实际有多少这些单元(每个GPC有多少个SM,多少个GPC …)取决于芯片配置本身;
GPU逻辑管线:
- 1、程序通过图形API(DX、GL、WEBGL)发出drawcall指令,指令会被推送到驱动程序,驱动会检查指令的合法性,然后会把指令放到GPU可以读取的Pushbuffer中。
2、经过一段时间或者显式调用flush指令后,驱动程序把Pushbuffer的内容发送给GPU,GPU通过主机接口(Host
Interface)接受这些命令,并通过前端(Front End)处理这些命令。 3、在图元分配器(Primitive
Distributor)中开始工作分配,处理indexbuffer中的顶点产生三角形分成批次(batches),然后发送给多个PGCs。这一步的理解就是提交上来n个三角形,分配给这几个PGC同时处理。
4、在GPC中,每个SM中的Poly Morph Engine负责通过三角形索引(triangle
indices)取出三角形的数据(vertex data)。
5、在获取数据之后,在SM中以32个线程为一组的线程束(Warp)来调度,来开始处理顶点数据。Warp是典型的单指令多线程(SIMT,SIMD单指令多数据的升级)的实现,也就是32个线程同时执行的指令是一模一样的,只是线程数据不一样,这样的好处就是一个warp只需要一个套逻辑对指令进行解码和执行就可以了,芯片可以做的更小更快,之所以可以这么做是由于GPU需要处理的任务是天然并行的。
6、SM的warp调度器会按照顺序分发指令给整个warp,单个warp中的线程会锁步(lock-step)执行各自的指令,如果线程碰到不激活执行的情况也会被遮掩(be
masked
out)。被遮掩的原因有很多,例如当前的指令是if(true)的分支,但是当前线程的数据的条件是false,或者循环的次数不一样(比如for循环次数n不是常量,或被break提前终止了但是别的还在走),因此在shader中的分支会显著增加时间消耗,在一个warp中的分支除非32个线程都走到if或者else里面,否则相当于所有的分支都走了一遍,线程不能独立执行指令而是以warp为单位,而这些warp之间才是独立的。
7、warp中的指令可以被一次完成,也可能经过多次调度,例如通常SM中的LD/ST(加载存取)单元数量明显少于基础数学操作单元。
8、由于某些指令比其他指令需要更长的时间才能完成,特别是内存加载,warp调度器可能会简单地切换到另一个没有内存等待的warp,这是GPU如何克服内存读取延迟的关键,只是简单地切换活动线程组。为了使这种切换非常快,调度器管理的所有warp在寄存器文件中都有自己的寄存器。这里就会有个矛盾产生,shader需要越多的寄存器,就会给warp留下越少的空间,就会产生越少的warp,这时候在碰到内存延迟的时候就会只是等待,而没有可以运行的warp可以切换。
9、一旦warp完成了vertex-shader的所有指令,运算结果会被Viewport
Transform模块处理,三角形会被裁剪然后准备栅格化,GPU会使用L1和L2缓存来进行vertex-shader和pixel-shader的数据通信。
10、接下来这些三角形将被分割,再分配给多个GPC,三角形的范围决定着它将被分配到哪个光栅引擎(raster
engines),每个raster
engines覆盖了多个屏幕上的tile,这等于把三角形的渲染分配到多个tile上面。也就是像素阶段就把按三角形划分变成了按显示的像素划分了。
11、SM上的Attribute Setup保证了从vertex-shader来的数据经过插值后是pixel-shade是可读的。
12、GPC上的光栅引擎(raster
engines)在它接收到的三角形上工作,来负责这些这些三角形的像素信息的生成(同时会处理裁剪Clipping、背面剔除和Early-Z剔除)。
13、32个像素线程将被分成一组,或者说8个2x2的像素块,这是在像素着色器上面的最小工作单元,在这个像素线程内,如果没有被三角形覆盖就会被遮掩,SM中的warp调度器会管理像素着色器的任务。
14、接下来的阶段就和vertex-shader中的逻辑步骤完全一样,但是变成了在像素着色器线程中执行。
由于不耗费任何性能可以获取一个像素内的值,导致锁步执行非常便利,所有的线程可以保证所有的指令可以在同一点。
15、最后一步,现在像素着色器已经完成了颜色的计算还有深度值的计算,在这个点上,我们必须考虑三角形的原始api顺序,然后才将数据移交给ROP(render
output
unit,渲染输入单元),一个ROP内部有很多ROP单元,在ROP单元中处理深度测试,和framebuffer的混合,深度和颜色的设置必须是原子操作,否则两个不同的三角形在同一个像素点就会有冲突和错误。
Early-Z:
为了减少像素着色器的额外消耗,将深度测试提至像素着色器之前),这就是Early-Z技术的由来 Early-Z技术可以将很多无效的像素提前剔除,避免它们进入耗时严重的像素着色器。Early-Z剔除的最小单位不是1像素,而是像素块
以下情况会导致Early-Z失效:
-
开启Alpha Test:由于Alpha Test需要在像素着色器后面的Alpha
Test阶段比较,所以无法在像素着色器之前就决定该像素是否被剔除。 -
开启Alpha Blend:启用了Alpha混合的像素很多需要与frame
buffer做混合,无法执行深度测试,也就无法利用Early-Z技术。 -
开启Tex Kill:即在shader代码中有像素摒弃指令(DX的discard,OpenGL的clip)。
-
关闭深度测试。Early-Z是建立在深度测试看开启的条件下,如果关闭了深度测试,也就无法启用Early-Z技术。
-
开启Multi-Sampling:多采样会影响周边像素,而Early-Z阶段无法得知周边像素是否被裁剪,故无法提前剔除。
以及其它任何导致需要混合后面颜色的操作。
Shader运行机制:
Shader代码也跟传统的C++等语言类似,需要将面向人类的高级语言(GLSL、HLSL、CGSL)通过编译器转成面向机器的二进制指令,二进制指令可转译成汇编代码,以便技术人员查阅和调试。

由高级语言编译成汇编指令的过程通常是在离线阶段执行,以减轻运行时的消耗。
在执行阶段,CPU端将shader二进制指令经由PCI-e推送到GPU端,GPU在执行代码时,会用Context将指令分成若干Channel推送到各个Core的存储空间。
对现代GPU而言,可编程的阶段越来越多,包含但不限于:顶点着色器(Vertex Shader)、曲面细分控制着色器(Tessellation Control Shader)、几何着色器(Geometry Shader)、像素/片元着色器(Fragment Shader)、计算着色器(Compute Shader)
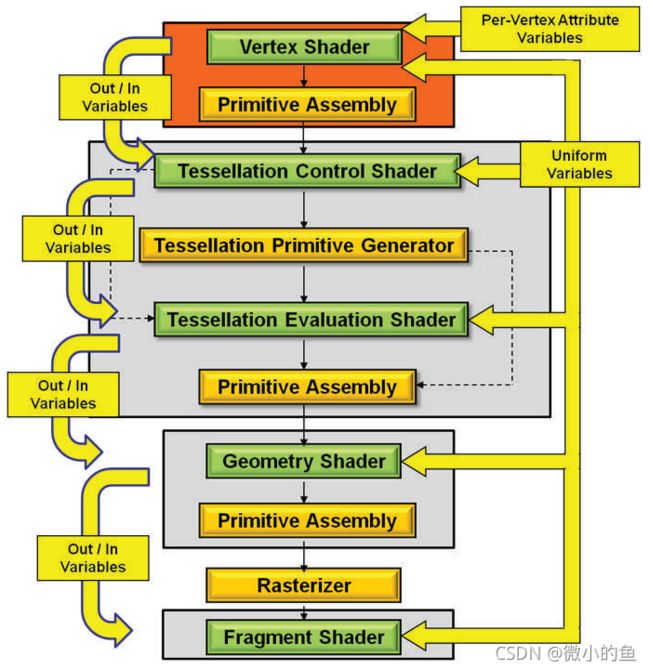
在执行阶段,以上汇编代码会被GPU推送到执行上下文(Execution Context),然后ALU会逐条获取(Detch)、解码(Decode)汇编指令,并执行它们
X11 与EGL
X11 主要功能是提供图形界面,实现架构和网络架构相同,有X Client和X Server组件,另外还有Window Manager和Display Manager组件。叫X windows system;
在类Unix系统中其中X Client是应用程序(例如gedit, firefox, terminal等),X Server负责管理硬件(例如鼠标,键盘,显示器)。
Window Manager常见的有GNOME, KDE等,负责管理所有的X Client,窗口控制参数(窗口的大小,窗口的移动等),设置背景壁纸等。
Display Manager功能是提供登录界面,并加载用户选择的Window Manager和语系等。
EGL
EGL 是渲染 API(如 OpenGL ES)和原生窗口系统之间的接口。通常来说,OpenGL 是一个操作 GPU 的 API,它通过驱动向 GPU 发送相关指令,控制图形渲染管线状态机的运行状态,但是当涉及到与本地窗口系统进行交互时,就需要这么一个中间层,且它最好是与平台无关的。因此 EGL 被设计出来,作为 OpenGL 和原生窗口系统之间的桥梁。EGL提供如下机制:
与设备的原生窗口系统通信
查询绘图表面的可用类型和配置
创建绘图表面
在OpenGL ES 和其他图形渲染API之间同步渲染
管理纹理贴图等渲染资源
为了让OpenGL ES能够绘制在当前设备上,我们需要EGL作为OpenGL ES与设备的桥梁。
EGL API 是独立于 OpenGL ES 各版本标准的独立的一套 API,其主要作用是为 OpenGL 指令 创建 Context 、绘制目标 Surface 、配置 FrameBuffer 属性、Swap 提交绘制结果 等。
EGL 中大部分函数成功时都是返回 EGL_TRUE,失败返回 EGL_FALSE
EGLint eglGetError();
创建,建立本地系统和 OpenGL ES 的连接 displayId 指定显示连接,一般使用默认的 EGL_DEFAULT_DISPLAY,即返回与默认原生窗口的连接。
NVIDIA RTX™平台
NVIDIA RTX平台融合了光线追踪,深度学习和光栅化功能,通过NVIDIA Turing GPU架构以及对行业领先工具和API的支持,从根本上改变了内容创作者和开发者的创作过程。基于RTX平台构建的应用程序具有实时真实感渲染以及AI增强的图形,视频和图像处理功能,使数百万设计师和艺术家能够以全新的方式创建令人惊叹的内容。RTX平台提供在高级硬件上运行的软件API和SDK,以提供能够加速和增强图形,照片,图像和视频处理的解决方案。 这些包括:

- 光线跟踪(OptiX,Microsoft DXR,Vulkan)
- AI加速功能(NGX)
- 光栅化(高级着色器)
- 模拟(CUDA 10,PhysX,Flex)
- 资源交换格式(来自Pixar的通用场景描述(USD)和开源NVIDIA材质定义
- 语言(MDL))
Rasterization(光栅化):
图灵体系结构的新的流水线式多处理器(SM)包括先进的着色技术,以及旨在加速图形管道的新功能。Mesh Shading
网格着色为图形流水线的顶点,细分和几何着色阶段提供了新的着色器模型,从而提高了NVIDIA的几何处理体系结构,支持更灵活,更高效的几何计算方法。 通过将对象列表处理的关键性能瓶颈移出CPU并移入高度并行的GPU网格着色程序,这种更灵活的模型使得例如每个场景支持更多数量级的对象成为可能。 网格着色还启用了用于高级几何合成和对象LOD管理的新算法。
Variable Rate Shading (VRS)
Texture-Space Shading
使用纹理空间着色,对象将在保存到内存的专用坐标空间(纹理空间)中着色,并且像素着色器将从该空间采样,而不是直接评估结果。 借助将阴影结果缓存在内存中并对其进行重用/重采样的能力,开发人员可以消除重复的阴影工作或使用不同的采样方法来提高质量。
Multi-View Rendering (MVR)
MVR强大地扩展了Pascal的Single Pass Stereo(SPS)。 尽管SPS允许渲染X偏移以外的两个常见视图,但是MVR允许一次通过渲染多个视图,即使这些视图基于完全不同的原点位置或视图方向也是如此。 访问是通过一个简单的编程模型进行的,在该模型中,编译器自动识别视图无关的代码,同时标识与视图相关的属性以实现最佳执行。
物理引擎:
当事物的外观和行为都和现实中的一样时,就会产生逼真的视觉效果。经过十多年的物理模拟发展,RTX平台采用了NVIDIA的PhysX、FleX和cuda10等api,可以精确模拟现实世界中游戏、虚拟环境和特效中的对象交互方式。
参考资料:
CPU 与 GPU 对比
深入GPU硬件架构及运行机制
EGL 介绍和使用
RTX架构
NVIDIA GPU技术和架构演进(附白皮书)