docker笔记13--面试必知的容器核心技术
docker笔记13--面试必知的容器核心技术
- 容器和虚拟机区别
- Docker 隔离技术
- Docker 限制技术
- 容器文件系统
- K8S 如何创建 pod
- K8S 如何调度 GPU pod
- Q & A
- 参考文档
最近在温习docker 的相关知识,把容器和 k8s相关的部分内容总结了一下,贴在此处,以便于后续学习。
在看这些核心内容前可以先看下如下几个问题,如果都能大致知道的话,那么可以说docker 容器技术比较熟练了,可以继续深挖或者学习其它内容了。
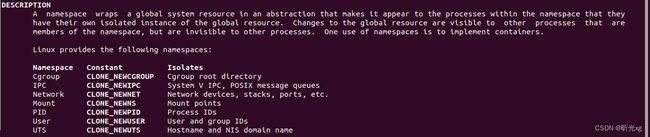
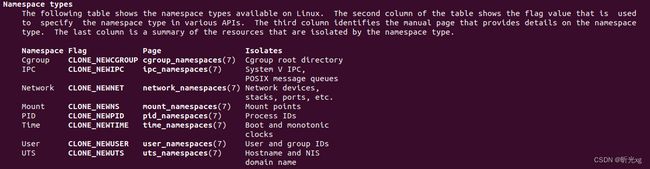
Q1 : docker 中有哪些namespace?
Q2 : 容器中哪些没有隔离?
Q3: docker exec 原理是什么?
Q4: 如何防止用户将机器资源跑满?
Q5: docker mount --bind 和 -v 区别?
Q6: docker 已经可以通过 ns和cgroup隔离限制,为何需要K8s这样的编排工具?
容器和虚拟机区别
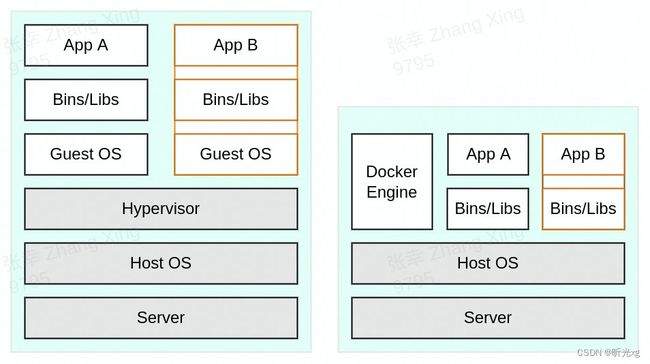
虚拟机,使用虚拟化技术模拟出CPU、内存、IO等设备,在其上安装操作系统、依赖库,运行程序;
容器,使用docker引擎(不需要虚拟硬件、额外操作系统), 直接run一个容器(本质是一个隔离、限制的进程);
占用资源少–直接复用主机资源(需要虚拟硬件、额外内存)
速度快–宿主机上拉起的一个特殊进程(不需要单独运行操作系统)
性能高–主机上的进程,基本无损耗(虚拟机要经过虚拟软件拦截、处理)
Q1 : docker 中有哪些namespace?
Docker 隔离技术
docker 使用namespace来隔离容器的视图,具体包括: ipc pid mnt net uts user time cgroup。
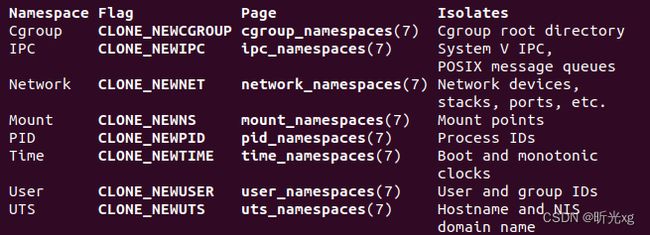
即启动容器的时,执行系统调用 clone() 函数的时候按需传入 CLONE_NEWIPC | CLONE_NEWPID | CLONE_NEWNS | CLONE_NEWNET | CLONE_NEWUTS | CLONE_NEWUSER | CLONE_NEWTIME | CLONE_NEWCGROUP 中的一个或者多个参数。
使用Namespace 作为隔离手段的容器并不需要单独的 Guest OS,这就使得容器额外的资源占用几乎可以忽略不计。
pid, 进程编号隔离,确保在容器中只能看见pid=1及其子进程id;
mnt, 文件系统挂载点隔离, 确保容器内看到的是其自己的挂载项目;
net, 网络设备、网络栈、端口等隔离,确保容器内网络和主机网络独立,ifconfig, ip 等只能看到自己的网络设备信息(默认eth0和lo)
user, 用户和用户组隔离,确保容器使用单独的用户组
ipc, 主要是用来隔离进程间通信的,IPC(信号量、消息队列、共享内存等)隔离
uts, 主机和域名隔离
cgroup, cgroup根目录隔离
time, 隔离系统时间
可以通过 lsns 查看当前系统创建的命名空间
root@xg:/home/xg# lsns
NS TYPE NPROCS PID USER COMMAND
4026531834 time 392 1 root /sbin/init splash
4026531835 cgroup 391 1 root /sbin/init splash
4026531836 pid 348 1 root /sbin/init splash
4026531837 user 348 1 root /sbin/init splash
4026531838 uts 387 1 root /sbin/init splash
4026531839 ipc 391 1 root /sbin/init splash
4026531840 net 345 1 root /sbin/init splash
4026531841 mnt 372 1 root /sbin/init splash
4026531862 mnt 1 61 root kdevtmpfs
root@xg:/home/xg# docker run -d --privileged=true --name=test-time ubuntu:20.04 sleep 3600
root@xg:/home/xg# lsns|grep sleep
4026532969 mnt 1 107079 root sleep 3600
4026533147 uts 1 107079 root sleep 3600
4026533263 ipc 1 107079 root sleep 3600
4026533265 pid 1 107079 root sleep 3600
4026533267 net 1 107079 root sleep 3600
4026533354 cgroup 1 107079 root sleep 3600
默认容器 user 和 time namespace 保持和 系统启动时候/sbin/init splash 的命名空间一致
Q2 : 容器中哪些没有隔离?
Q3: docker exec 原理是什么?
Docker 限制技术
Linux Cgroups 就是 Linux 内核中用来为进程设置资源限制的一个重要功能。
全称是 Linux Control Group。它最主要的作用,就是限制一个进程组能够使用的资源上限,包括 CPU、内存、磁盘、网络带宽等等。
k8s 能限制pod的资源其实就是通过kubelet拉起容器时候设置cgroup参数来实现。
查看容器ns 和 cgroup 信息方法:
查看pid:
docker inspect -f '{{.State.Pid}}' test-cgroup
824493
查看 ns信息:
root@xg:/sys/fs/cgroup# ls /proc/824493/ns -la
total 0
dr-x--x--x 2 root root 0 3月 2 16:11 .
dr-xr-xr-x 9 root root 0 3月 2 16:11 ..
lrwxrwxrwx 1 root root 0 3月 2 16:21 cgroup -> 'cgroup:[4026533370]'
lrwxrwxrwx 1 root root 0 3月 2 16:21 ipc -> 'ipc:[4026532664]'
lrwxrwxrwx 1 root root 0 3月 2 16:21 mnt -> 'mnt:[4026532362]'
lrwxrwxrwx 1 root root 0 3月 2 16:11 net -> 'net:[4026532862]'
lrwxrwxrwx 1 root root 0 3月 2 16:21 pid -> 'pid:[4026532861]'
lrwxrwxrwx 1 root root 0 3月 2 16:21 pid_for_children -> 'pid:[4026532861]'
lrwxrwxrwx 1 root root 0 3月 2 16:21 time -> 'time:[4026531834]'
lrwxrwxrwx 1 root root 0 3月 2 16:21 time_for_children -> 'time:[4026531834]'
lrwxrwxrwx 1 root root 0 3月 2 16:21 user -> 'user:[4026531837]'
lrwxrwxrwx 1 root root 0 3月 2 16:21 uts -> 'uts:[4026532441]'
查看 cgroup信息:
# cat /proc/824493/cgroup
0::/system.slice/docker-1db4ed7af81a1860a91ff57daf7ab3c012f0f8c947adfbc8db33aed155612af6.scope
root@xg:~# cd /sys/fs/cgroup/system.slice/docker-1db4ed7af81a1860a91ff57daf7ab3c012f0f8c947adfbc8db33aed155612af6.scope
root@xg:/sys/fs/cgroup/system.slice/docker-1db4ed7af81a1860a91ff57daf7ab3c012f0f8c947adfbc8db33aed155612af6.scope# cat cpu.max
100000 100000
root@xg:/sys/fs/cgroup/system.slice/docker-1db4ed7af81a1860a91ff57daf7ab3c012f0f8c947adfbc8db33aed155612af6.scope# cat memory.max
268435456

Q4: 如何防止用户将dev机器(例如dtp01) 资源跑满?
容器文件系统
容器镜像,也叫作rootfs。它只是一个操作系统的所有文件和目录,并不包含内核,一般最多也就几百兆。
镜像中每一个layer可以看做是一个rootfs, 多个增量rootfs通过联合挂载形成了一个完整的rootfs供容器运行。
容器镜像一旦发布,任何人都可以得到完全一样的环境–容器技术强一致性的重要体现。
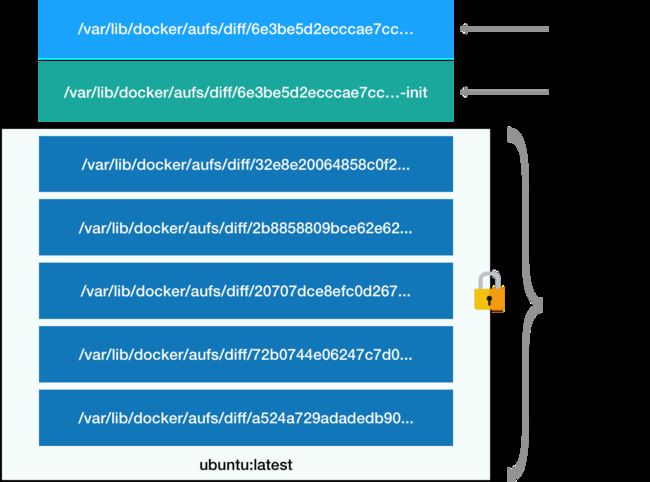
只读层:只读形式挂载,以增量形式分别包含Ubuntu操作系统的一部分;
Init层 :夹在只读层和读写层之间,层是 Docker 项目单独生成的一个内部层,专门用来存放 /etc/hosts、/etc/resolv.conf 等信息;
可读写层:专门用来存放修改 rootfs 后产生的增量,无论是增、删、改,都发生在这里;
注意: rootfs 并不包含操作系统内核,只有在系统开机的时候才会加载内核。
Q5: docker mount --bind 和 -v 区别?
K8S 如何创建 pod
Kubectl create|apply deploy|statefulset|rs 时候都会触发创建pod过程,此过程由调度器寻找最合适的节点,由kubelet拉起容器。
1)kubectl 提高创建pod信息
2)调度器通过监听(Watch)Etcd 中 Pod、Node、Service 等与调度相关的 API 对象的变化,从集群所有的节点中,根据调度算法挑选出所有可以运行该 Pod 的节点;
3) 从上一步的结果中,再根据调度算法挑选一个最符合条件的节点作为最终结果;
4) 调度器对一个 Pod 调度成功后,将它的 spec.nodeName 字段填上调度结果的节点名字;
5)kubelet 检测到节点上有pod,通过api 传递ns和cgroup信息给docker,并拉起一个或者多个容器;
Q6: docker 已经可以通过 ns和cgroup隔离限制,为何需要K8s这样的编排工具?
K8S 如何调度 GPU pod
K8S早期并没有GPU设备,为了支持各类GPU设备,K8S使用 Device Plugin来管理,它会在节点上启动一个程序定期通过grpc向 kubelet 汇报gpu信息,实际上是向节点中patch gpu相关的信息。例如,如下节点中就有nvidia.com/gpu=1 的信息。
$ kubectl get nodes cn-shanghai.172.22.1.105 -ojsonpath='{.status.capacity}'|jq
{
"cpu": "8",
"ephemeral-storage": "309505004Ki",
"hugepages-1Gi": "0",
"hugepages-2Mi": "0",
"memory": "61678836Ki",
"nvidia.com/gpu": "1",
"pods": "128"
}
集群中有GPU信息后,调度pod时候就会考虑节点上gpu数量,然后通过调度策略将pod调度到某个gpu节点上。
kubelet 会进一步向插件请求GPU信息,当被分配 GPU 对应的设备路径和驱动目录信息被返回给 kubelet 之后,kubelet 会把这些信息追加在创建该容器所对应的 CRI 请求当中。
当这个 CRI 请求发给 Docker 之后,Docker 为你创建出来的容器里,就会出现这个 GPU 设备,并把它所需要的驱动目录挂载进去。
至此, K8S 为一个pod分配了GPU资源。
基于以上内容,做一个简单的总结:
docker技术核心原理就是为待创建的用户进程;
- 启用Linux namespace配置
- 设置指定的Cgroups参数
- 切换进程的根目录
k8s 启动pod核心原理就是找到合适的节点并拉起相应容器;
- 选择出符合要求的节点
- 工具算法打分并选最优节点
- 在节点上启动一个pod所需要的容器
Q & A
Q1 : docker 中有哪些namespace?
A : ipc pid mnt net uts user cgroup
Q2 : 容器中哪些没有隔离?
时间(早期版本), 系统内核
早期(kernel 4.4.0-171), 无time 和cgroup:
4.15.0-159 中无time
当前(kernel 5.15.0-60):
测试:
关闭时间同步: timedatectl set-ntp false

Q3: docker exec 原理是什么?
docker 启动一个进程,加入到已有容器实例的namespace中(实际上底层调用sentns()系统函数),从而获取和该进程相同的命名空间,看到的文件系统、挂载项、进程等自然也相同了。
Q4: 如何防止用户将机器资源跑满?
拉起容器并设置好CPU Memory数量:
# docker run --cpus="1" --memory="256m" --name=test-cgroup -d ubuntu:20.04 sleep infinity
Q5: docker mount --bind 和 -v 区别?
–bind :
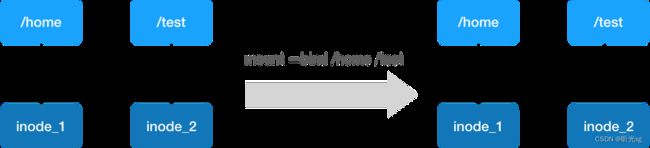
mount --bind /home /test,会将 /home 挂载到 /test 上。其实相当于将 /test 的 dentry,重定向到了 /home 的 inode。这样当我们修改 /test 目录时,实际修改的是 /home 目录的 inode。这也就是为何,一旦执行 umount 命令,/test 目录原先的内容就会恢复:因为修改真正发生在的,是 /home 目录里。
-v :
如果volume是空的而container中的目录有内容,那么docker会将container目录中的内容拷贝到volume中,但是如果volume中已经有内容,则会将container中的目录覆盖
例如:
docker run -d --name=docs -v /home/docs u20:v1 sleep 3600
会在主机上创建一个卷,并把容器中 /home/docs 的文件copy到卷的 _data 中,
当kill掉容器后该卷中的数据也存在;
Q6: docker 已经可以通过 ns和cgroup隔离限制,为何需要K8s这样的编排工具?
1)cgroup 适合限制资源的最大使用值,无法设置最小值,k8s可以通过request、limit和相关资源来计算一个节点上能放多少pod,以及优先放在哪个节点上;
2)k8s以统一的方式来定义任务之间的各种关系,并且能为将来支持更多种类的关系留有余地;
参考文档
namespaces(7) — Linux manual page
Linux namespaces
chroot,pivot_root和switch_root 区别
从docker容器时间问题探究到Namespace问题
为什么构建容器需要 Namespace
极客时间专栏–深入剖析 Kubernete