Kubernetes 笔记(09)— Service 概念、YAML 定义 Service、创建 Service、测试 Service 的负载均衡效果、以域名的方式使用 Service、对外暴露服务
Deployment 和 DaemonSet 这两个 API 对象,它们都是在线业务,只是以不同的策略部署应用:
Deployment创建任意多个实例;DaemonSet为每个节点创建一个实例;
1. Service 概念
Service是集群内部的负载均衡机制,用来解决服务发现的关键问题。
在 Kubernetes 集群里 Pod 的生命周期是比较“短暂”的,虽然 Deployment 和 DaemonSet 可以维持 Pod 总体数量的稳定,但在运行过程中,难免会有 Pod 销毁又重建,这就会导致 Pod 集合处于动态的变化之中。
这种“动态稳定”对于现在流行的微服务架构来说是非常致命的,试想一下,后台 Pod 的 IP 地址老是变来变去,客户端该怎么访问呢?如果不处理好这个问题,Deployment 和 DaemonSet 把 Pod 管理得再完善也是没有价值的。
其实,这个问题也并不是什么难事,业内早就有解决方案来针对这样“不稳定”的后端服务,那就是“负载均衡”,典型的应用有 LVS、Nginx 等等。它们在前端与后端之间加入了一个“中间层”,屏蔽后端的变化,为前端提供一个稳定的服务。
但 LVS、Nginx 毕竟不是云原生技术,所以 Kubernetes 就按照这个思路,定义了新的 API 对象:Service。
Service 的工作原理和 LVS、Nginx 差不多,Kubernetes 会给它分配一个静态 IP 地址,然后它再去自动管理、维护后面动态变化的 Pod 集合,当客户端访问 Service,它就根据某种策略,把流量转发给后面的某个 Pod。

图片来源
这里 Service 使用了 iptables 技术,每个节点上的 kube-proxy 组件自动维护 iptables 规则,客户不再关心 Pod 的具体地址,只要访问 Service 的固定 IP 地址,Service 就会根据 iptables 规则转发请求给它管理的多个 Pod,是典型的负载均衡架构。
不过 Service 并不是只能使用 iptables 来实现负载均衡,它还有另外两种实现技术:性能更差的 userspace 和性能更好的 ipvs,但这些都属于底层细节,我们不需要刻意关注。
2. 使用 YAML 描述 Service
我们还是可以用命令 kubectl api-resources 查看它的基本信息,可以知道它的简称是 svc ,apiVersion 是 v1。注意,这说明它与 Pod 一样,属于 Kubernetes 的核心对象,不关联业务应用,与 Job、Deployment 是不同的。
$ kubectl api-resources | grep services
services svc v1 true Service
可以很容易写出 Service 的 YAML 文件头
apiVersion: v1
kind: Service
metadata:
name: xxx-svc
可以使用另外一个命令 kubectl expose 为我们自动创建 Service 的 YAML 样板,也许 Kubernetes 认为 expose 能够更好地表达 Service “暴露”服务地址的意思吧。
因为在 Kubernetes 里提供服务的是 Pod,而 Pod 又可以用 Deployment/DaemonSet 对象来部署,所以 kubectl expose 支持从多种对象创建服务,Pod、Deployment、DaemonSet 都可以。
使用 kubectl expose 指令时还需要用参数 --port 和 --target-port 分别指定映射端口和容器端口,而 Service 自己的 IP 地址和后端 Pod 的 IP 地址可以自动生成,用法上和 Docker 的命令行参数 -p 很类似,只是略微麻烦一点。
比如,如果我们要为之前的 ngx-dep 对象生成 Service,命令就要这么写:
export out="--dry-run=client -o yaml"
kubectl expose deploy ngx-dep --port=80 --target-port=80 $out
生成的 Service YAML 大概是这样的:
apiVersion: v1
kind: Service
metadata:
name: ngx-svc
spec:
selector:
app: ngx-dep
ports:
- port: 80
targetPort: 80
protocol: TCP
在 spec 里只有两个关键字段,selector 和 ports。
selector和Deployment/DaemonSet里的作用是一样的,用来过滤出要代理的那些Pod。因为我们指定要代理Deployment,所以Kubernetes就为我们自动填上了ngx-dep的标签,会选择这个Deployment对象部署的所有Pod。Kubernetes的这个标签机制虽然很简单,却非常强大有效,很轻松就关联上了Deployment的Pod。ports里面的三个字段分别表示外部端口、内部端口和使用的协议,在这里就是内外部都使用80端口,协议是TCP。
为了让你看清楚 Service 与它引用的 Pod 的关系,我把这两个 YAML 对象画在了下面的这张图里,需要重点关注的是 selector、targetPort 与 Pod 的关联:

3. 在 K8s 里使用 Service
首先,我们创建一个 ConfigMap,定义一个 Nginx 的配置片段,它会输出服务器的地址、主机名、请求的 URI 等基本信息,定义的 ngx-conf.yml 内容如下:
apiVersion: v1
kind: ConfigMap
metadata:
name: ngx-conf
data:
default.conf: |
server {
listen 80;
location / {
default_type text/plain;
return 200
'srv : $server_addr:$server_port\nhost: $hostname\nuri : $request_method $host $request_uri\ndate: $time_iso8601\n';
}
}
创建 ConfigMap 对象
kubectl apply -f ngx-conf.yml
然后我们在 Deployment 的 template.volumes 里定义存储卷,再用 volumeMounts 把配置文件加载进 Nginx 容器里,定义的 ngx-dep.yml 内容如下:
apiVersion: apps/v1
kind: Deployment
metadata:
name: ngx-dep
spec:
replicas: 2
selector:
matchLabels:
app: ngx-dep
template:
metadata:
labels:
app: ngx-dep
spec:
volumes:
- name: ngx-conf-vol
configMap:
name: ngx-conf
containers:
- image: nginx:alpine
name: nginx
ports:
- containerPort: 80
volumeMounts:
- mountPath: /etc/nginx/conf.d
name: ngx-conf-vol
创建 deployment 对象
kubectl apply -f ngx-dep.yml
查看部署的 configmap 和 deployment 对象是否正常:

和前面一样,我们要为这个 ngx-dep 对象生成 Service,命令就要这么写:
export out="--dry-run=client -o yaml"
kubectl expose deploy ngx-dep --port=80 --target-port=80 $out
生成的 Service YAML 大概是这样的,我们保存该文件名为 svc.yml:
apiVersion: v1
kind: Service
metadata:
name: ngx-svc
spec:
selector:
app: ngx-dep
ports:
- port: 80
targetPort: 80
protocol: TCP
这样我们就可以创建 Service 对象了,用的还是 kubectl apply:
kubectl apply -f svc.yml
创建之后,用命令 kubectl get 就可以看到它的状态:

可以看到,Kubernetes 为 Service 对象自动分配了一个 IP 地址 “10.108.141.157”,这个地址段是独立于 Pod 地址段的( 前面讲里的 10.10.xx.xx)。而且 Service 对象的 IP 地址还有一个特点,它是一个“虚地址”,不存在实体,只能用来转发流量。
想要看 Service 代理了哪些后端的 Pod,你可以用 kubectl describe 命令:
kubectl describe svc ngx-svc

截图里显示 Service 对象管理了两个 endpoint,分别是 “10.10.1.2:80” 和 “10.10.1.3:80”,初步判断与 Service、Deployment 的定义相符,那么这两个 IP 地址是不是 Nginx Pod 的实际地址呢?
我们还是用 kubectl get pod 来看一下,加上参数 -o wide:
kubectl get pod -o wide

把 Pod 的地址与 Service 的信息做个对比,我们就能够验证 Service 确实用一个静态 IP 地址代理了两个 Pod 的动态 IP 地址。
4. 测试 Service 的负载均衡效果
因为 Service、 Pod 的 IP 地址都是 Kubernetes 集群的内部网段,所以我们需要用 kubectl exec 进入到 Pod 内部(或者 ssh 登录集群节点),再用 curl 等工具来访问 Service:
kubectl exec -ti ngx-dep-6796688696-v97ns -- sh

在 Pod 里,用 curl 访问 Service 的 IP 地址,就会看到它把数据转发给后端的 Pod,输出信息会显示具体是哪个 Pod 响应了请求,就表明 Service 确实完成了对 Pod 的负载均衡任务。
我们再试着删除一个 Pod,看看 Service 是否会更新后端 Pod 的信息,实现自动化的服务发现:

由于 Pod 被 Deployment 对象管理,删除后会自动重建,而 Service 又会通过 controller-manager 实时监控 Pod 的变化情况,所以就会立即更新它代理的 IP 地址。通过截图你就可以看到有一个 IP 地址 “10.10.1.2”消失了,换成了新的“10.10.1.4”,它就是新创建的 Pod。
也可以再尝试一下使用 ping 来测试 Service 的 IP 地址:
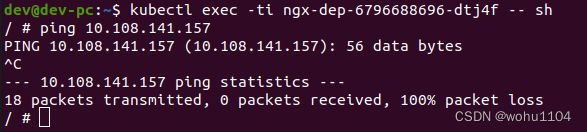
会发现根本 ping 不通,因为 Service 的 IP 地址是“虚”的,只用于转发流量,所以 ping 无法得到回应数据包,也就失败了。
4. 以域名的方式使用 Service
Service 对象的 IP 地址是静态的,保持稳定,这在微服务里确实很重要,不过数字形式的 IP 地址用起来还是不太方便。这个时候 Kubernetes 的 DNS 插件就派上了用处,它可以为 Service 创建易写易记的域名,让 Service 更容易使用。
namespace 的简写是 ns,你可以使用命令 kubectl get ns 来查看当前集群里都有哪些名字空间,也就是说 API 对象有哪些分组:

Kubernetes 有一个默认的名字空间,叫 default,如果不显式指定,API 对象都会在这个 default 名字空间里。而其他的名字空间都有各自的用途,比如 kube-system 就包含了 apiserver、etcd 等核心组件的 Pod。
因为 DNS 是一种层次结构,为了避免太多的域名导致冲突,Kubernetes 就把名字空间作为域名的一部分,减少了重名的可能性。
Service 对象的域名完全形式是 对象. 名字空间.svc.cluster.local,但很多时候也可以省略后面的部分,直接写 对象. 名字空间 甚至 对象名 就足够了,默认会使用对象所在的名字空间(比如这里就是 default)。
现在我们来试验一下 DNS 域名的用法,还是先 kubectl exec 进入 Pod,然后用 curl 访问 ngx-svc、ngx-svc.default 等域名:

可以看到,现在我们就不再关心 Service 对象的 IP 地址,只需要知道它的名字,就可以用 DNS 的方式去访问后端服务。
顺便说一下,Kubernetes 也为每个 Pod 分配了域名,形式是 IP 地址. 名字空间.pod.cluster.local,但需要把 IP 地址里的 . 改成 - 。比如地址 10.10.1.87,它对应的域名就是 10-10-1-87.default.pod。
5. 让 Service 对外暴露服务
由于 Service 是一种负载均衡技术,所以它不仅能够管理 Kubernetes 集群内部的服务,还能够担当向集群外部暴露服务的重任。
Service 对象有一个关键字段 type,表示 Service 是哪种类型的负载均衡。前面我们看到的用法都是对集群内部 Pod 的负载均衡,所以这个字段的值就是默认的 ClusterIP,Service 的静态 IP 地址只能在集群内访问。
除了 ClusterIP,Service 还支持其他三种类型,分别是 ExternalName 、LoadBalancer 、NodePort。不过前两种类型一般由云服务商提供,我们的实验环境用不到,所以接下来就重点看 NodePort 这个类型。
如果我们在使用命令 kubectl expose 的时候加上参数 --type=NodePort,或者在 YAML 里添加字段 type:NodePort,那么 Service 除了会对后端的 Pod 做负载均衡之外,还会在集群里的每个节点上创建一个独立的端口,用这个端口对外提供服务,这也正是 NodePort 这个名字的由来。
先执行命令删除之前创建的 service:
kubectl delete svc ngx-svc
让我们修改一下 Service 的 YAML 文件,加上字段 type:
apiVersion: v1
...
spec:
...
type: NodePort
然后创建对象,再查看它的状态:

就会看到 TYPE 由之前的 ClusterIP 变成了 NodePort,而在 PORT 列里的端口信息也不一样,除了集群内部使用的 80 端口,还多出了一个 31356 端口,这就是 Kubernetes 在节点上为 Service 创建的专用映射端口。
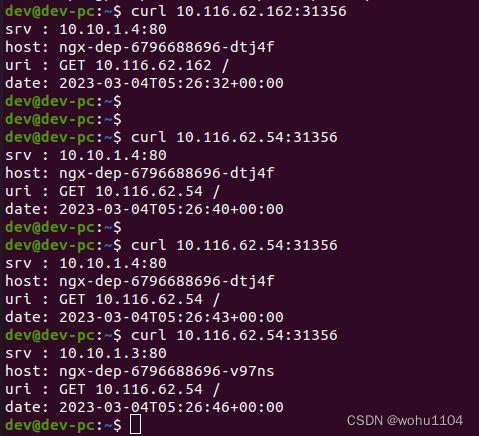
因为这个端口号属于节点,外部能够直接访问,所以现在我们就可以不用登录集群节点或者进入 Pod 内部,直接在集群外使用任意一个节点的 IP 地址,就能够访问 Service 和它代理的后端服务了。
比如我现在所在的服务器是 172.16.19.54,在这台主机上用 curl 访问 Kubernetes 集群的两个节点 10.116.62.162 和 10.116.62.54,就可以得到 Nginx Pod 的响应数据:
我把 NodePort 与 Service、Deployment 的对应关系画成了图,你看了应该就能更好地明白它的工作原理:
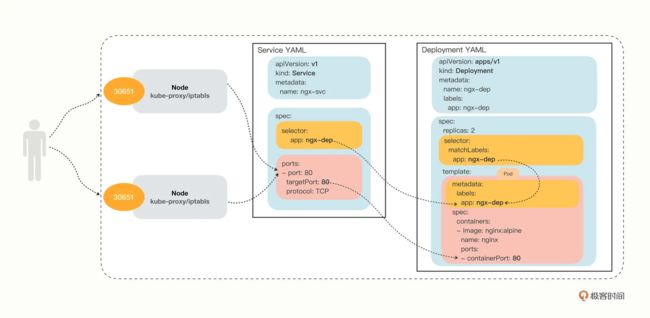 图片来源:https://time.geekbang.org/column/article/536829
图片来源:https://time.geekbang.org/column/article/536829
不过它也有一些缺点,具体如下:
-
它的端口数量很有限。
Kubernetes为了避免端口冲突,默认只在 “30000~32767” 这个范围内随机分配,只有 2000 多个,而且都不是标准端口号,这对于具有大量业务应用的系统来说根本不够用。 -
它会在每个节点上都开端口,然后使用
kube-proxy路由到真正的后端Service,这对于有很多计算节点的大集群来说就带来了一些网络通信成本,不是特别经济。 -
它要求向外界暴露节点的
IP地址,这在很多时候是不可行的,为了安全还需要在集群外再搭一个反向代理,增加了方案的复杂度。
虽然有这些缺点,但 NodePort 仍然是 Kubernetes 对外提供服务的一种简单易行的方式,在其他更好的方式出现之前,我们也只能使用它。
6. 总结
Pod的生命周期很短暂,会不停地创建销毁,所以就需要用Service来实现负载均衡,它由Kubernetes分配固定的IP地址,能够屏蔽后端的Pod变化。Service对象使用与Deployment、DaemonSet相同的selector字段,选择要代理的后端Pod,是松耦合关系。- 基于
DNS插件,我们能够以域名的方式访问Service,比静态IP地址更方便。 - 名字空间是
Kubernetes用来隔离对象的一种方式,实现了逻辑上的对象分组,Service的域名里就包含了名字空间限定。 Service的默认类型是ClusterIP,只能在集群内部访问,如果改成NodePort,就会在节点上开启一个随机端口号,让外界也能够访问内部的服务。
如果 Service 对象的映射端口和目标端口相同,比如都是 80,那么在使用命令 kubectl expose 的时候也可以省略 --target-port,只用 --port 这个参数,在创建样板时会更方便。
实际上 service 并不直接管理 Pod,而是使用代表 IP 地址的 Endpoint 对象,但我们一般不会直接使用 Endpoint,除非是检查错误。
NodePort 的默认端口范围 30000~32767 也可以通过配置 apiserver 更改,但是这样会增加节点端口冲突风险。
问题:Service代理POD后,用exec进入POD,再用curl访问。请问:为什么是进入POD,Service代理POD,按道理应该是进入Service呀。
答复:因为域名、IP地址都是在Kubernetes里的,外界访问不了,进pod就可以了。Service是个虚地址,无法进入,只有pod是实体。