数据分析3.0时代: HashData 助力企业释放数据资源价值
 近日,由LF AI基金会主办的 AICON 2022 在杭州举行。本次大会重点关注人工智能领域的行业变革与前沿技术,围绕产业赋能、发展要素、数据治理机制等热门话题进行深入探讨和交流,探索人工智能发展新模式、新路径。
近日,由LF AI基金会主办的 AICON 2022 在杭州举行。本次大会重点关注人工智能领域的行业变革与前沿技术,围绕产业赋能、发展要素、数据治理机制等热门话题进行深入探讨和交流,探索人工智能发展新模式、新路径。
在会上,HashData解决方案架构师吴昊发表了题为《面向AI应用场景的云原生数据仓库技术与开源规划》的主题演讲。
吴昊提出,随着产业数字化和数字产业化的持续推进,数据逐步成为企业核心资产,数据的衍生价值越来越大。当前,企业数据分析正由2.0阶段逐步迈入3.0,越来越多企业以数据驱动业务发展。
同时,面对日益增加的数据规模和数据类型多元化的发展趋势,企业数据分析复杂度不断提升,传统MPP数据仓库平台,在资源弹性、成本、处理能力等方面已经很难适应企业业务需求,以存算分离、湖仓一体为特点的云原生数据仓库将成为主流发展趋势。
吴昊认为,以HashData为代表的云原生数据仓库具有高性能、高可用性和可伸缩性等特性,能够大幅降低企业数据分析成本,推动人工智能技术的发展和普及,助力企业数字化转型。
数据分析迈入3.0时代
数据、算法和算力是人工智能三大核心要素,也是人工智能的三大基石。当前,AI 产业级应用已经进入大数据、大模型时代。数据量爆发式的增长,也对数据库技术发展提出了新的要求。
吴昊认为,企业对数据分析的需求,可以分为三个阶段。在数据分析1.0阶段,企业积累了大量业务数据,希望通过数据了解一段周期内的企业经营情况。因此,这一阶段企业以看到过去的描述型分析为主。
在数据分析2.0阶段,企业不仅仅要对已经发生的业务进行评估,还需要对业务进行前瞻性预测。因此,这一阶段企业以面向未来的预测型分析为主:需要建立数据科学团队,针对海量数据进行探索、研究,从数据中洞察业务趋势。
随着云计算技术的普及,企业数据分析已经进入3.0阶段。在这一阶段,企业希望提高数据分析的时效性,嵌入业务流程自动化、智能化驱动业务,进而利用预测型分析的成果,保障业务健康发展。
为满足数据分析2.0迈向3.0阶段的需求,很多企业采用多种技术路线,建立了多个异构数据平台,管理混合数据生态,提供多样化的分析能力。这样的建设思路也导致数据孤岛频发、数据冗余严重、数据时效性差、运维工作量繁重等后果,为数据平台建设带来诸多挑战。
云原生数仓助推AI技术创新
数据库自诞生以来,其技术的发展始终随着企业业务需求的变化而演进。从集中式数据库到分布式数据库,再到今天的云原生数据库,数据库产品的架构持续不断升级,也涌现出各种各样的数据库产品。尤其在云原生成为企业云化的共识的今天,云原生数据库正在成为云上数据库使用的最佳范式。
多家市场调研机构发布的报告显示,云原生数据仓库的优势大大超越传统数据仓库。预计到2023年,全球75%的数据库都会运行在云端。
在这样的背景下,国内外主流的公有云厂商,均推出了基于云原生架构的数据库产品。同时,Snowflake、Databricks等独立软件厂商也获得了市场的广泛认可。
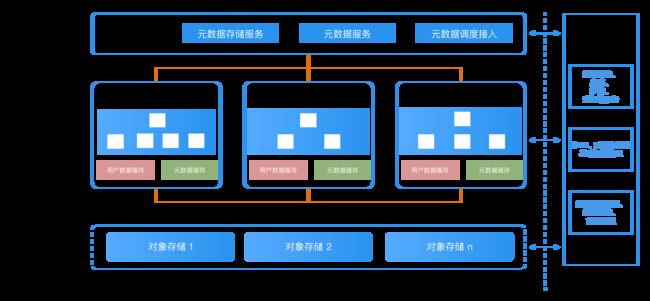 作为国内最早进军云原生数据仓库领域的企业之一,HashData采用业界领先的云原生大数据系统设计理念,围绕着对象存储和抽象服务构建,通过元数据、计算和存储三者分离、多集群共享统一数据存储层的架构,最大限度发挥云计算优势,实现快速部署、按需伸缩、不停机交付等,大幅降低企业进行大数据分析的门槛。
作为国内最早进军云原生数据仓库领域的企业之一,HashData采用业界领先的云原生大数据系统设计理念,围绕着对象存储和抽象服务构建,通过元数据、计算和存储三者分离、多集群共享统一数据存储层的架构,最大限度发挥云计算优势,实现快速部署、按需伸缩、不停机交付等,大幅降低企业进行大数据分析的门槛。
对于传统MPP数据库难以实现高并发的“痛点”,HashData通过云原生架构,实现了多个集群共享统一的元数据、统一的数据存储,集群间不竞争CPU、内存和IO资源,可以根据业务需求无限地创建集群。
为避免出现“数据孤岛”和冗余,HashData采用共享存储架构,任何一个计算集群都可以去访问同一份数据,所有集群共享同一份元数据,彻底消除“数据孤岛”和冗余,确保数据的实时性、一致性。

HashData内置了丰富库内分析模块,除了提供SQL分析以外,还有强大的并行计算的引擎,支持Python语言、R语言、MADlib库内机器学习、时空分析等主流数据分析功能。
同时,HashData还提供了自定义函数扩展分析能力,开发人员可以使用R、Python、Perl、Java、 pgsql等语言编写用户自定义函数(UDF),扩展数据库分析功能,缩短开发时间。
未来,HashData所有的这些机器学习的算法模型、算法框架都可以连接到数据平台上,为用户提供各类的分析能力。
立足开源 拥抱云原生
凭借领先的技术架构和丰富的实践经验,HashData目前已在金融、政务、交通、能源、互联网等行业实现大规模商用部署。
在开源规划和开源社区合作方面,HashData数据库内核基于开源的PostgreSQL和Greenplum Database构建,元数据采用开源的KV数据库FoundationDB提供持久化,通过ORC、Parquet等开放文件格式与其它大数据系统实现互通互联。
与此同时,HashData正在实现和完善基于Arrow的向量化执行引擎,基于Iceberg和Hudi的数据湖表格式。
除了汲取开源社区的精华外,HashData也在积极地回馈开源社区。我们的研发团队积极参与Issue提交与解决、技术问题讨论和代码贡献,将独立发现的开源组件bug和实现的功能特性代码合并到开源分支中,例如即将正式GA发布的PostgreSQL 15版本就包含了HashData工程师的代码贡献。
HashData将始终坚持云原生和开源开放路线,致力于降低大数据分析的门槛,用行业领先的技术优势消除规划、购买和运维大量基础设施给企业带来的负担,让企业重新聚焦核心业务,释放数据资源价值,为企业的数字化转型注入新动能。