RabbitMQ(python版)
RabbitMQ
1、MQ
1.1、定义
MQ(Message Quene) : 翻译为消息队列,通过典型的生产者和消费者模型,生产者不断向消息队列中生产消息,消费者不断的从队列中获取消息。
因为消息的生产和消费都是异步的,而且只关心消息的发送和接收,没有业务逻辑的侵入,轻松的实现系统间解耦。
别名为 消息中间件 通过利用高效可靠的消息传递机制进行平台无关的数据交流,并基于数据通信来进行分布式系统的集成。
1.2、MQ应用场景
1.2.1、异步处理
场景说明:用户注册后,需要发注册邮件和注册短信,传统的做法有两种
1.串行的方式 2.并行的方式
串行方式: 将注册信息写入数据库后,发送注册邮件,再发送注册短信,以上三个任务全部完成后才返回给客户端
这有一个问题是,邮件,短信并不是必须的,它只是一个通知,而这种做法让客户端等待没有必要等待的东西
并行方式: 将注册信息写入数据库后,发送邮件的同时,发送短信,
以上三个任务完成后,返回给客户端,并行的方式能提高处理的时间
1.2.2、应用解耦
场景:外卖系统中,用户下单后,订单系统需要通知配送系统、商家系统、后台系统等,传统
的做法就是依次执行订单系统、配送系统、商家系统、后代系统等
这种做法有两个缺点:
1、当这几个系统中有任何一个系统出现错误,订单就会失败
2、所有系统执行完毕,会造成用户等待时间过长,对用户不够友好
这里订单系统、配送系统、商家系统、后代系统高耦合,引入消息队列来进行系统解耦

1.2.3、流量消峰
场景: 秒杀活动,一般会因为流量过大,导致应用挂掉,为了解决这个问题,一般在应用前端加入消息队列。
作用:
1、可以控制活动人数,超过此一定阀值的订单直接丢弃,这也是为什么秒杀过程中出现秒杀失败的原因!
用户发送请求,服务器收到之后,首先写入消息队列,加入消息队列长度超过最大值,则直接抛弃用户请求或跳转到错误页面。
2、可以缓解短时间的高流量压垮应用(应用程序按自己的最大处理能力获取订单)
1.3、不同MQ特点
1.ActiveMQ
ActiveMQ 是Apache出品,最流行的,能力强劲的开源消息总线。它是一个完全支持JMS规范的的消息中间件。
丰富的API,多种集群架构模式让ActiveMQ在业界成为老牌的消息中间件,在中小型企业颇受欢迎!
2.Kafka
Kafka是LinkedIn开源的分布式发布-订阅消息系统,目前归属于Apache顶级项目。
Kafka主要特点是基于Pull的模式来处理消息消费,追求高吞吐量,一开始的目的就是用于日志收集和传输。
0.8版本开始支持复制,不支持事务,对消息的重复、丢失、错误没有严格要求,适合产生大量数据的互联网服务的数据收集业务。
3.RocketMQ
RocketMQ是阿里开源的消息中间件,它是纯Java开发,具有高吞吐量、高可用性、适合大规模分布式系统应用的特点。
RocketMQ思路起源于Kafka,但并不是Kafka的一个Copy,它对消息的可靠传输及事务性做了优化,
目前在阿里集团被广泛应用于交易、充值、流计算、消息推送、日志流式处理、binglog分发等场景。
4.RabbitMQ
RabbitMQ是使用Erlang语言开发的开源消息队列系统,基于AMQP协议来实现。
AMQP的主要特征是面向消息、队列、路由(包括点对点和发布/订阅)、可靠性、安全。
AMQP协议更多用在企业系统内对数据一致性、稳定性和可靠性要求很高的场景,对性能和吞吐量的要求还在其次。
RabbitMQ比Kafka可靠,Kafka更适合IO高吞吐的处理,一般应用在大数据日志处理或对实时性(少量延迟),可靠性(少量丢数据)
要求稍低的场景使用,比如ELK日志收集。
2、RabbitMQ
2.1、引言
基于AMQP协议,erlang语言开发,是部署最广泛的开源消息中间件,是最受欢迎的开源消息中间件之一。
官网:https://www.rabbitmq.com/
官方教程:https://www.rabbitmq.com/#getstarted
AMQP 协议
AMQP(advanced message queuing protocol)在2003年时被提出,最早用于解决金融领不同平台之间的消息传递交互问题。
顾名思义,AMQP是一种协议,更准确的说是一种binary wire-level protocol(链接协议)。
这是其和JMS的本质差别,AMQP不从API层进行限定,而是直接定义网络交换的数据格式。
这使得实现了AMQP的provider天然性就是跨平台的。
2.2、RabbitMQ安装
略
2.3、RabbitMQ配置
启动rabbitmq中的插件管理
rabbitmq-plugins enable rabbitmq_management
启动RabbitMQ的服务
systemctl start rabbitmq-server
systemctl restart rabbitmq-server
systemctl stop rabbitmq-server
查看服务状态
systemctl status rabbitmq-server
访问web管理界面
http://localhost:15672/
username: guest
password: guest
3、RabbitMQ的几种工作模式
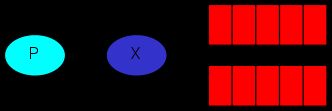
3.1、简单模式

在上图的模型中,有以下概念:
P:生产者,也就是要发送消息的程序 C:消费者:消息的接受者,会一直等待消息到来。
queue:消息队列,图中红色部分。类似一个邮箱,可以缓存消息;
生产者向其中投递消息,消费者从其中取出消息。
send.py
import pika
# 连接rabbitmq
connection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
channel = connection.channel()
# 声明队列
channel.queue_declare(queue='hello')
# 插入数据
# exchange='' 指定为简单模式
# routing_key='hello' 指定队列
# body='Hello World!' 指定内容
channel.basic_publish(exchange='', routing_key='hello', body='Hello World!')
connection.close()
receive.py
import pika
# 连接rabbitmq
connection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
channel = connection.channel()
# 声明队列
channel.queue_declare(queue='hello')
# 定义回调函数
def callback(ch, method, properties, body):
print(" [x] Received %r" % body)
# 确定监听队列
channel.basic_consume(queue='hello', auto_ack=True, on_message_callback=callback)
# 启动监听
channel.start_consuming()
3.1.1、应答参数(auto_ack)
上述案例中设置应答参数auto_ack为True,即为默认应答。
默认应答即为在rabbitmq中取走一个消息时默认给rabbitmq一个应答,rabbitmq会在接受应答后删除该消息。
在这个过程中并没有涉及到callback函数的执行过程。因此会出现以下场景:
当consumer在取走rabbitmq消息后执行过程中出现错误,导致该进程崩掉。
然后rabbitmq里又已经删除该消息,那么就会造成信息的缺失问题。
为了解决上述问题,需将应答参数auto_ack更改为False,即手动应答
receive.py
import pika
# 连接rabbitmq
connection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
channel = connection.channel()
# 声明队列
channel.queue_declare(queue='hello')
# 定义回调函数
def callback(ch, method, properties, body):
print(" [x] Received %r" % body)
# 回复应答
ch.basic_ack(delivery_tag=method.delivery_tag)
# 确定监听队列
channel.basic_consume(queue='hello', auto_ack=False, on_message_callback=callback)
# 启动监听
channel.start_consuming()
3.1.2、持久化参数(durable)
场景:当producer把数据插入rabbitmq后,此时consumer还没执行,rabbitmq由于一些原因崩溃
也会导致数据缺失问题
此时就要用到持久化参数durable
send.py
import pika
# 连接rabbitmq
connection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
channel = connection.channel()
channel.queue_declare(queue='hello1', durable=True)
channel.basic_publish(exchange='', routing_key='hello1', body='Hello World!')
connection.close()
receive.py
import pika
# 连接rabbitmq
connection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
channel = connection.channel()
# 声明队列
channel.queue_declare(queue='hello1', durable=True)
# 定义回调函数
def callback(ch, method, properties, body):
print(" [x] Received %r" % body)
# 确定监听队列
channel.basic_consume(queue='hello1', auto_ack=True, on_message_callback=callback)
# 启动监听
channel.start_consuming()
3.2、分发模式

如上图所示,会有多个消费者来消费rabbitmq中数据
当有多个消费者时,rabbitmq会默认采用轮询机制来进行消费,即按照一定顺序把消息给到consumer
除此机制外,还有一种公平分发机制,顾名思义,即谁空闲谁执行。
以下为公平分发代码:
receive.py
import pika
# 连接rabbitmq
connection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
channel = connection.channel()
# 声明队列
channel.queue_declare(queue='hello')
# 定义回调函数
def callback(ch, method, properties, body):
print(" [x] Received %r" % body)
# 公平分发
channel.basic_qos(prefetch_count=1)
# 确定监听队列
channel.basic_consume(queue='hello', auto_ack=True, on_message_callback=callback)
# 启动监听
channel.start_consuming()
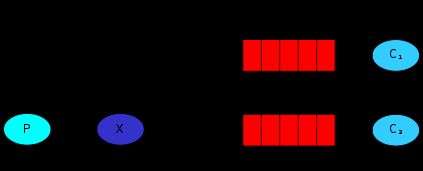
3.3、发布-订阅模式
上图中x表示交换机
该模式下场景:当有多个consumer需要同一份数据时,之前的模式只针对单独一份数据进行操作
这时需要用到发布-订阅模式。
此时生产者只需将数据交给交换机,交换机会把该数据给到所有绑定该交换机的队列,而绑定队列的消费者就会拿到这份数据
send.py
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
channel = connection.channel()
# 声明一个名为logs类型为fanout的交换机
# fanout 发布订阅模式参数
channel.exchange_declare(exchange='logs', exchange_type='fanout')
# 向交换机里插入数据
message = 'Hello World!'
channel.basic_publish(exchange='logs', routing_key='', body=message)
print(" [x] Sent %r" % message)
connection.close()
receive.py
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
channel = connection.channel()
# 声明一个名为logs类型为fanout的交换机
channel.exchange_declare(exchange='logs', exchange_type='fanout')
# 创建一个队列
result = channel.queue_declare(queue='', exclusive=True)
queue_name = result.method.queue
print(queue_name)
# 将队列绑定到交换机上
channel.queue_bind(exchange='logs', queue=queue_name)
print(' [*] Waiting for logs. To exit press CTRL+C')
def callback(ch, method, properties, body):
print(" [x] %r" % body)
channel.basic_consume(queue=queue_name, on_message_callback=callback, auto_ack=True)
channel.start_consuming()
3.4、关键字模式
此模式是在发布-订阅模式的基础上进行了增强,通过关键字使交换机的信息分发到指定的队列中
send.py
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
channel = connection.channel()
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
channel = connection.channel()
# 声明一个名为logs1类型为direct的交换机
channel.exchange_declare(exchange='logs1', exchange_type='direct')
# 向交换机里插入数据
message = 'warning : Hello World!'
# message = 'info: Hello World!'
# message = 'error: Hello World!'
channel.basic_publish(exchange='logs1', routing_key='warning', body=message)
# channel.basic_publish(exchange='logs1', routing_key='info', body=message)
# channel.basic_publish(exchange='logs1', routing_key='error', body=message)
print(" [x] Sent %r" % message)
connection.close()
receive.py
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
channel = connection.channel()
# 声明一个名为logs1类型为direct的交换机
channel.exchange_declare(exchange='logs1', exchange_type='direct')
# 创建一个队列
result = channel.queue_declare(queue='', exclusive=True)
queue_name = result.method.queue
print(queue_name)
# 将队列绑定到交换机上
channel.queue_bind(exchange='logs1', queue=queue_name, routing_key='info')
# channel.queue_bind(exchange='logs1', queue=queue_name, routing_key='warning')
# channel.queue_bind(exchange='logs1', queue=queue_name, routing_key='error')
print(' [*] Waiting for logs. To exit press CTRL+C')
def callback(ch, method, properties, body):
print(" [x] %r" % body)
channel.basic_consume(queue=queue_name, on_message_callback=callback, auto_ack=True)
channel.start_consuming()
3.5、通配符模式
关键字模式是为指定关键字匹配到对应队列,而通配符模式是通过类似正则表达式的方式来进行匹配
符号"#“匹配一个或者多个词,符号”*"仅匹配一个词
send.py
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
channel = connection.channel()
channel.exchange_declare(exchange='logs2', exchange_type='topic')
# 向交换机里插入数据
message = 'china.weather'
# message = 'usa.news'
# message = 'usa.weather'
channel.basic_publish(exchange='logs2', routing_key='china.weather', body=message)
print(" [x] Sent %r" % message)
connection.close()
receive.py
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
channel = connection.channel()
channel.exchange_declare(exchange='logs2', exchange_type='topic')
# 创建一个队列
result = channel.queue_declare(queue='', exclusive=True)
queue_name = result.method.queue
print(queue_name)
# 将队列绑定到交换机上
# channel.queue_bind(exchange='logs2', queue=queue_name, routing_key='usa.#')
# channel.queue_bind(exchange='logs2', queue=queue_name, routing_key='#.news')
channel.queue_bind(exchange='logs2', queue=queue_name, routing_key='#.weather')
def callback(ch, method, properties, body):
print(" [x] %r" % body)
channel.basic_consume(queue=queue_name, on_message_callback=callback, auto_ack=True)
channel.start_consuming()