文献翻译阅读-NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
目录
- 信息
- 简介
- 相关工作
-
- 神经3D表示
- 视角合成和基于图像的渲染
- 方法
-
- 体渲染技术(用离散形式表示连续积分)
- 优化神经场的技术
-
- 位置编码
- 分层体积抽样
- 实施细节
- 结果
- 结论
- 参考
信息
NeRF,即Neural Radiance Fields(神经辐射场)的缩写。研究员来自UCB、Google和UCSD。
Title:NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
Paper:https://arxiv.org/pdf/2003.08934.pdf
Code:https://github.com/bmild/nerf
简介
通过优化底层场景提出了一种新视角合成的方法,这种算法采用的是全连接的神经网络来映射场景向量,其中输入是连续的5D表示(位置信息 ( x , y , z ) (x,y,z) (x,y,z)+视角方向( θ , ϕ \theta,\phi θ,ϕ)),输出是体积密度 σ \sigma σ+该空间位置的视角相关的辐射(可以理解为color)。沿着相机光线查询5D表示来合成视图(使用经典的体渲染技术),该技术可微所以要求输入是一系列的已知相机姿势的照片。
前驱知识介绍:
- 体积密度 σ \sigma σ:不透明度即射线通过点 ( x , y , z ) (x,y,z) (x,y,z)累计的辐射量;
- 全程使用神经网络全连接,并未使用卷积层,用的是MLP(多层感知机)去学习神经辐射场这个函数;
- 位置编码:使得MLP可表达更高频函数-解决了分辨率低问题;
- 分层抽样:解决对高频场景需充分采样问题。
- 整体步骤:
- 使用相机光线穿过场景采样一系列3D点;
- 使用这些点和其相关的2D视角方向作为NN的输入产生 σ \sigma σ和颜色;
- 使用体渲染技术将 σ \sigma σ和颜色生成对应的2D图像;
- 用真实图像和生成图像做均方误差优化参数。
 收集上半球面的3D图像输入,即可生成各种位姿的新视角的2D图像
收集上半球面的3D图像输入,即可生成各种位姿的新视角的2D图像
nerf优势
- 将具有复杂连续场景的表示为5D神经辐射场的方法,参数化为基本的MLP网络;
- 可微的体渲染技术优化标准的RGB图像值,分层抽样策略使得MLP的容量分配给可见场景内容的空间;
- 位置编码升维输入的5D坐标使得nerf可以表征更高频的场景内容。
相关工作
神经3D表示
优化坐标映射到距离函数/占用域的深度网络,但是在真实3D场景表现很弱比如ShapeNet;之后通过可微分的渲染函数放宽了真实3D形状的要求,可以允许只用2D图像来优化;Sitzmann的工作是用不直接的神经3D表示输出特征向量和RGB值在每一个3D坐标,提出了一种由递归神经网络组成的可微分渲染函数,该网络沿着每条射线行进以确定曲面的位置。
尽管这些方法已经可以有效表达复杂场景建模,但是还限制于几何复杂度低的简单形状,导致渲染出来的图像过于平滑。
视角合成和基于图像的渲染
密集视图采样:可以通过简单的采样插值重建逼真的视图
稀疏视图采样:计算机视觉和图像社区已经有重大进展
现有的方法:
- mesh-based 表示方法-局部最小值问题,并且需要固定网格在优化之前,在不受约束的真实场景不可用;
- 体渲染:输入一堆RGB图像,既适合复杂场景又能可微优化。早期是用观察的图像直接可体素网格上色,近期是使用多场景大型数据集训练NN再预测采样的体积表示,再用alpha合成或者沿射线合成渲染新的视图。但是由于离散采样,时间和可见复杂度较差,根本限制了缩放到更高分辨率图像的能力。—文章在全连接的网络参数内编码连续体积来规避该问题(更高质量并且存储成本低)。
方法
整体训练框架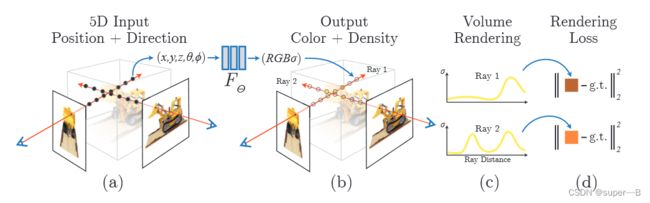
1.沿相机射线采样5D坐标( x , y , z , θ , ϕ x,y,z,\theta,\phi x,y,z,θ,ϕ),其中视角用三维笛卡尔坐标 d d d表示;
2. 将位置信息给MLP生成对应的( r , g , b , σ r,g,b,\sigma r,g,b,σ);
3. 使用体渲染技术将( r , g , b , σ r,g,b,\sigma r,g,b,σ)合成图像;
4. 体渲染函数可微,最小化合成图像和真实观测图像的残差来优化。

细节: σ \sigma σ只用位置信息 x x x预测,( r , g , b r,g,b r,g,b)用位置信息 x x x和 d d d预测—MLP先用8层全连接(使用RELU激活函数、每层256个通道),使得输入 x x x后输出 σ \sigma σ+一个256维的特征向量 v e c t o r vector vector;该 v e c t o r vector vector再和相机射线方向 d d d作为输入送入另一个全连接层(RELU+128通道),输出视角相关的RGB值。
体渲染技术(用离散形式表示连续积分)
参数说明:
- σ ( x ) \sigma(x) σ(x)—射线在 x x x处终止的概率即不透明度;
- r ( t ) = o + t d r(t)=o+td r(t)=o+td—射线 r r r的方向;
- C ( r ) C(r) C(r)—射线 r r r在时间起点到时间终点的预测颜色值;
- T ( t ) T(t) T(t)—沿 t n t_{n} tn到 t t t的射线累计透射率(即射线从 t n t_{n} tn到 t t t不撞击任何粒子的概率)可以理解为光线射到这“还剩多少光”;
- σ ( t ) \sigma(t) σ(t)—表示不透明度;
- δ i = t i + 1 − t i \delta_{i}=t_{i+1}-t_{i} δi=ti+1−ti—是相邻样本的距离;
积分形式:
公式也说明密度只与位置信息有关;颜色与位置信息和观测方向都有关系。
如何沿着射线对空间中的颜色进行积分?
- 一个点的密度越高,射线通过它之后变得越弱,密度和透光度呈反比;
- 一个点的密度越高,这点在这个射线下的颜色反应在像素上的权重越大;
分层抽样:把 [ t n , t f ] [t_{n},t_{f}] [tn,tf]均匀N等分,然后每个小区间随机抽一个样本 t i t_{i} ti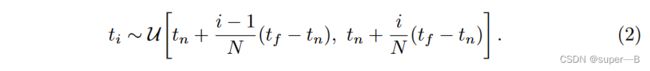 离散形式:
离散形式:
 注意:原来的积分权重是 T ( t ) σ ( r ( t ) ) T(t)\sigma(r(t)) T(t)σ(r(t)),离散的形式是 T i ( 1 − e x p ( − σ i δ i ) ) T_{i}(1-exp(-\sigma_{i}\delta_{i})) Ti(1−exp(−σiδi)),而 1 − e x p ( − σ i δ i ) 1-exp(-\sigma_{i}\delta_{i}) 1−exp(−σiδi)是和密度 σ i \sigma_{i} σi呈正比的。
注意:原来的积分权重是 T ( t ) σ ( r ( t ) ) T(t)\sigma(r(t)) T(t)σ(r(t)),离散的形式是 T i ( 1 − e x p ( − σ i δ i ) ) T_{i}(1-exp(-\sigma_{i}\delta_{i})) Ti(1−exp(−σiδi)),而 1 − e x p ( − σ i δ i ) 1-exp(-\sigma_{i}\delta_{i}) 1−exp(−σiδi)是和密度 σ i \sigma_{i} σi呈正比的。
优化神经场的技术
位置编码
问题:尽管MLP可以无限逼近真实函数,但是在颜色和几何图像的高频变化下依然存在表现很差,如红圈图像部分直接模糊—由Rahaman的工作知深度神经网络倾向于学习低频部分。
解决方案:将输入先用高频函数映射到更高维可见,可以更好拟合包含高频变化的数据。所以把神经网络函数由两个函数组成: F Θ = F Θ ′ ∘ Υ F_{\Theta}=F_{\Theta}^{'}\circ\Upsilon FΘ=FΘ′∘Υ。
其中 F Θ ′ F_{\Theta}^{'} FΘ′是常规的MLP函数, Υ \Upsilon Υ是一个映射函数-实现高维编码器作用。
 Υ ( ⋅ ) \Upsilon(\cdot) Υ(⋅)作用于每一个分量: ( x , y , z ) (x,y,z) (x,y,z)和 d d d,并且归一化到 [ − 1 , 1 ] [-1,1] [−1,1],在文章中 L L L值对于 Υ ( x ) \Upsilon(x) Υ(x)取10(相当于原来的3维增加了7维),对于 Υ ( d ) \Upsilon(d) Υ(d)取4。
Υ ( ⋅ ) \Upsilon(\cdot) Υ(⋅)作用于每一个分量: ( x , y , z ) (x,y,z) (x,y,z)和 d d d,并且归一化到 [ − 1 , 1 ] [-1,1] [−1,1],在文章中 L L L值对于 Υ ( x ) \Upsilon(x) Υ(x)取10(相当于原来的3维增加了7维),对于 Υ ( d ) \Upsilon(d) Υ(d)取4。

分层体积抽样
问题:对渲染图像没有贡献的自由空间和遮挡区域仍然被重复采样+空间的密度分布不均匀,如果射线均匀随机采样的话,渲染效率会比较低。并且从上面分析可知道,整个渲染过程就是对射线的采样点颜色进行加权求和,其中权重是 w i w_{i} wi。
解决方案:用两个网络表示场景:“粗”+“细”
对渲染公式中的颜色权重 w i w_{i} wi作为对应区间采样的概率,我们训练两个辐射场网络,一个粗糙网络(Coares)一个精细网络(Fine)。粗糙网络是在均匀采样得到比较少( N c N_{c} Nc)的点进行渲染并训练的网络,用来对输出 w i w_{i} wi进行采样概率估计。—重写了离散函数形式如下所示:
 再将结果归一化: w ^ i = w i / ∑ j = 1 N c w j \widehat{w}_{i}=w_{i}/\sum\limits_{j=1}^{N_{c}}w_{j} w i=wi/j=1∑Ncwj,以 w ^ i \widehat{w}_{i} w i为概率分布采样 N f N_{f} Nf个点,用 N c + N f N_{c}+N_{f} Nc+Nf个点来训练精细网络。
再将结果归一化: w ^ i = w i / ∑ j = 1 N c w j \widehat{w}_{i}=w_{i}/\sum\limits_{j=1}^{N_{c}}w_{j} w i=wi/j=1∑Ncwj,以 w ^ i \widehat{w}_{i} w i为概率分布采样 N f N_{f} Nf个点,用 N c + N f N_{c}+N_{f} Nc+Nf个点来训练精细网络。
实施细节
用COLMAP运动包可以估计真实摄像机姿态、参数…损失只是粗略和精细渲染的渲染颜色和真实像素颜色之间的总平方误差。
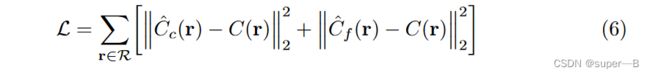 R R R是每批次中的射线集合, C ( r ) 是光线 r 的真实地面情况 C(r)是光线r的真实地面情况 C(r)是光线r的真实地面情况, C ^ c ( r ) \hat{C}_{c}(r) C^c(r)是粗略的颜色估计, C ^ f ( r ) \hat{C}_{f}(r) C^f(r)是精细的颜色估计(尽管最终的颜色来自 C ^ f ( r ) \hat{C}_{f}(r) C^f(r),本文依旧选择了最小化粗网络的损失,从而可以使得来自粗网络的权重分布来分配精细网络的样本)。
R R R是每批次中的射线集合, C ( r ) 是光线 r 的真实地面情况 C(r)是光线r的真实地面情况 C(r)是光线r的真实地面情况, C ^ c ( r ) \hat{C}_{c}(r) C^c(r)是粗略的颜色估计, C ^ f ( r ) \hat{C}_{f}(r) C^f(r)是精细的颜色估计(尽管最终的颜色来自 C ^ f ( r ) \hat{C}_{f}(r) C^f(r),本文依旧选择了最小化粗网络的损失,从而可以使得来自粗网络的权重分布来分配精细网络的样本)。
实验参数设置:
- 使用4096条射线的批量大小;
- 每条射线在粗略体积中以 N c N_{c} Nc=64个坐标采样;
- 在精细体积中以 N f N_{f} Nf=128个附加坐标采样;
- Adam优化器:lr— 5 × 1 0 − 4 5\times10^{-4} 5×10−4到 5 × 1 0 − 5 5\times10^{-5} 5×10−5, β 1 \beta_{1} β1=0.9, β 2 \beta_{2} β2=0.999, ϵ = 1 0 − 7 \epsilon=10^{-7} ϵ=10−7
结果


结论
- 直接解决了之前使用MLP将对象和场景表示为连续函数的工作的不足;
- 分层采样策略,以提高渲染样本的效率(用于训练和测试),但在研究有效优化和渲染神经辐射场的技术方面仍有更多进展;
参考
- 都2022年了,我不允许你还不懂NeRF
- NeRF 从入门到精通
- 【NeRF】原始论文解读