数据仓库建设
1. 数仓概述
数仓顾名思义,就是数据存储仓库。为什么建设数仓呢?一个事物出现多是为了解决存在的问题。公司面临什么问题?公司业务越来越复杂,数据量越来越大,不同系统业务域数据不通,而公司又需要对不同系统的数据进行整合分析挖掘。从而产生了数仓。
数仓中的数据公司一般用来解决什么问题。1.历史数据备份。2.报表展示。3.数据分析挖掘等复杂业务逻辑。
常见表类型
| data | datetime |
|---|---|
| A, B, C | 20210601 |
| A, B, C, D | 20210602 |
| A, B, C, D, E, F | 20210603 |
-
全量表(维表)
每次覆盖性的上报所有数据,丢失历史状态
20210601 查询的数据是A, B, C
20210602 查询的数据是A, B, C, D
20210603 查询的数据是A, B, C, D, E, F
-
增量表(事实表)
每次上报新增数据
20210601 上报数据是A, B, C
20210602 上报的数据是 D
20210603 上报的数据是E, F
-
快照表(维表)
每次上报当时的快照数据,记录了历史状态,构建使用方便,浪费存储空间
20210601 上报的数据是A, B, C
20210602 上报的数据是A, B, C, D
20210603 上报的数据是A, B, C, D, E, F
-
拉链表
大数据量,有缓慢变化维,需要记录历史变化状态,使用快照表浪费存储空间。构建复杂浪费时间,典型的时间换空间。注意拉链表必须具备的两个字段start_time和end_time。
-- 假设日更新
-- src_tb: 修改新增数据
-- zip_old: 拉链表历史数据
-- zip_new: 生成的新拉链表
1. 确定业务主键
2. 确定关注变化度量
3. 获取zip_old有,src_tb没有的数据,保持不表
4. 获取zip_old无,src_tb有的数据,赋值start_time为今天,end_time常取值9999-01-01
5. 获取zip_old有,src_tb有的数据,zip_old中end_time更新为昨天,新增src_tb中的数据
6. 3、4、5步骤的数据写入到zip_new
2.数仓构建
2.1 数仓架构
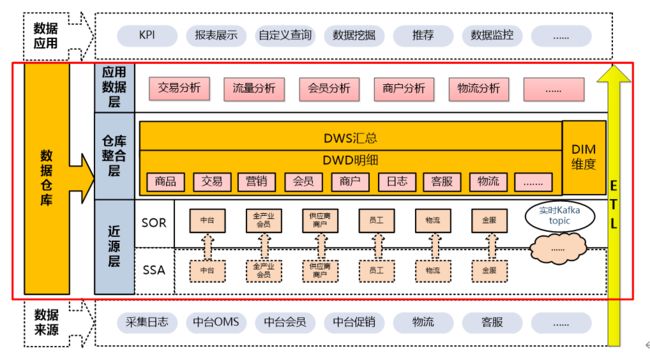
数据应用:
报表展示、KPI分析、自定义查询、数据挖掘、推荐、数据监控及其他应用。
数据仓库:
离线数仓的近源层(ODS)分为SSA层、SOR层。SSA层在上图用虚线框示意,表示数据采集时结构化数据可以直接进入SOR层,即跳过SSA层直接进入SOR层。实时数仓的近源层主要通过KAFKA组件采集,存入KAFKA TOPIC。
复制层(SSA,system-of-records-staging-area)
SSA 直接复制源系统(比如从mysql中读取所有数据导入到hive中的同结构表中,不做处理)的数据,尽量保持业务数据的原貌;与源系统数据唯一不同的是,SSA 中的数据在源系统数据的基础上加入了时间戳的信息,形成了多个版本的历史数据信息。也叫登台区。
原子层(SOR,system-of-record)
SOR 是基于模型开发的一套符合 3NF 范式规则的表结构,它存储了数据仓库内最细层次的数据,并按照不同的主题域对数据分类存储;比如高校数据统计服务平台根据目前部分需求将全校数据在 SOR 层中按人事、学生、教学、科研四大主题存储;SOR 是整个数据仓库的核心和基础,在设计过程中应具有足够的灵活性,以能应对添加更多的数据源、支持更多的分析需求,同时能够支持进一步的升级和更新。
明细数据区(DWD)、汇总数据区(DWS)和应用数据层(ADS),离线数仓和实时数仓在模型设计上保持一致,存储有差异,离线数仓一般存在HIVE表中、实时数仓的实时数据流存储在内存中。
数据来源:
采集日志数据流、爬虫数据及各业务中心业务数据。
2.2 设计原则
仓库基础数据建设的意义
1.避免底层业务变动对上层需求影响过大,保持公共层模型稳定。
2.屏蔽底层复杂的业务逻辑,尽可能简单、完整的在接口层呈现业务数据。
3.建设高内聚松耦合的数据组织,使得数据从业务角度可分割,有助于数据和团队的扩展。
4.提高明细数据表的易用性,提升公共指标的复用性,减少重复加工,减少表与表的关联。
5.提供完整、集成、统一的公共数据接口给分析层。
简单概括,提高易用性,从而提高开发效率,要求保证稳定性。
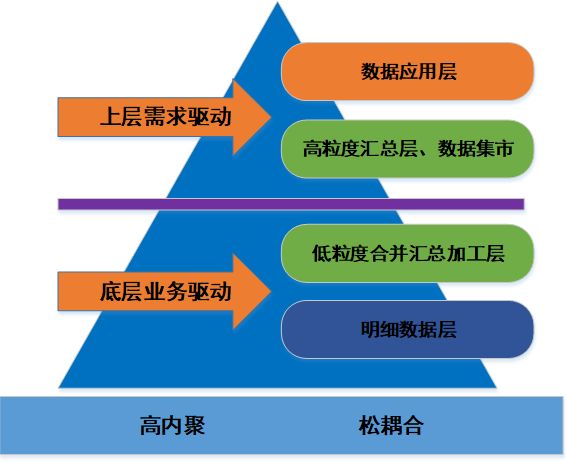
-
上层需求驱动,底层业务驱动
上层表示数据应用层、数据集市(ADS层),主要由业务方需求驱动进行模型设计。
底层的明细数据层(DWD层)和轻粒度汇总层(DWS层),主要以体现实际业务过程为主,以数据需求驱动为辅进行模型设计。
-
高内聚松耦合
主题之内数据的高内聚,主题之间数据的松耦合。
-
底层业务变动与上层需求变动对模型冲击最小化
1.底层业务系统变化影响控制在基础数据层(ODS近源层)。
2.上层需求变化影响控制在数据应用层,削弱上层需求变动对模型的影响
3.结合自上而下的建设方法。
4.数据水平层次清晰化。
2.2 构建流程
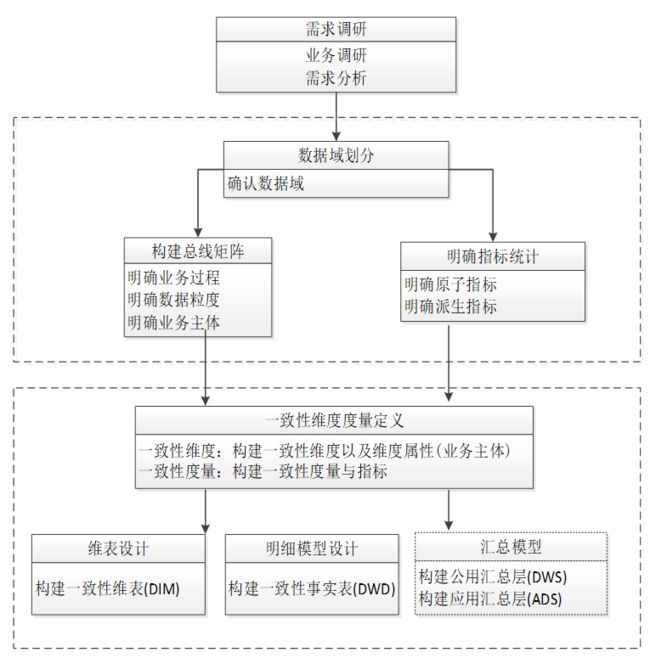
第一步:需求调研
• 业务调研:确认需求的产业板块、业务线、功能模块以及具体的业务流程;
• 需求分析:与分析师、业务运营人员确认数据需求,具体到表报形式。
第二步:确定数据域
• 确认归属的数据域(如商品域、会员域、交易域等);
• 数据域要体现出某一方面的各分析角度(维度)和统计指标(度量)之间的关系。
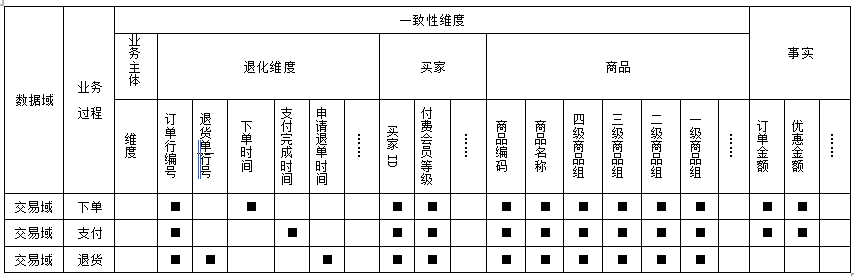
第三步:构建总线矩阵
• 确认业务过程:业务过程可以概括为一个不可拆分的行为事件或者事件的当前状态;
• 确认数据粒度:数据整合或聚合的程度,采用“最小粒度原则”,即将度量的粒度设置到最小;
• 确认业务主体:业务主体是维度的分类(如商品、店铺、买家等),以及维度的层次(Hierarchy)和级别(Level)。
第四步:明确统计指标
• 明确需求的原子指标、派生指标。
第五步:一致性维度度量定义
• 确认一致性维度:构建一致性维度、维度属性以及对应的维度编码;
• 确认一致性度量:构建一致性的原子指标和派生指标,以及对应的指标编码。
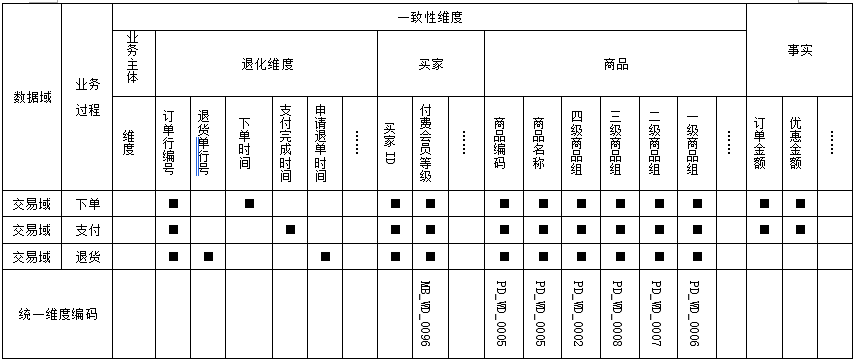
第六步:维度模型设计(DIM)
• 根据总线矩阵完成维表设计,维度及属性的规范定义。
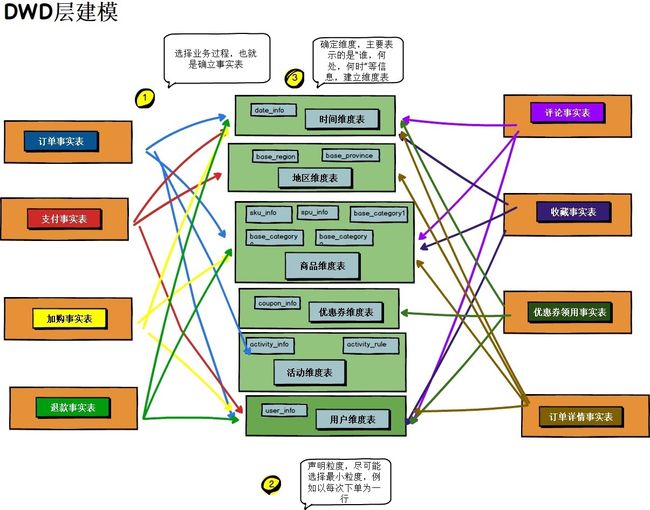
第七步:明细模型设计
• 一致性事实表设计(DWD):根据总线矩阵的业务过程完成一致性事实表设计,包含单业务过程事实表和多业务过程事实表,确认一致性维度,分解不可加性事实为可加的(如订单优惠率分解为订单原价金额和订单优惠金额)。联系维度的外键+度量值。
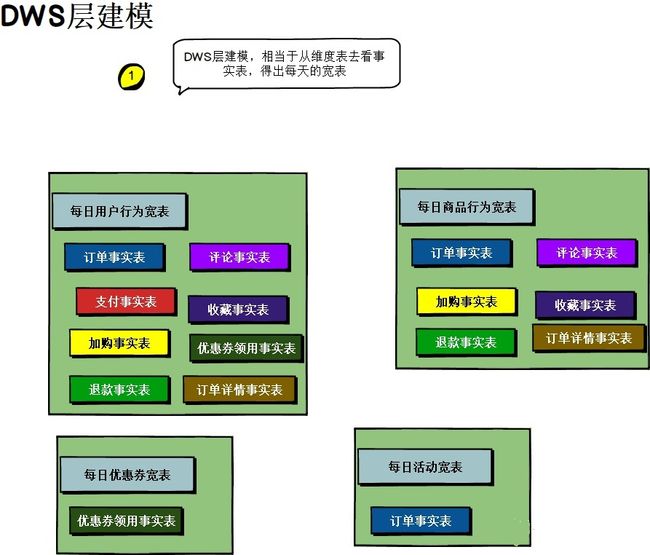
第八步:汇总模型设计
• 公用汇总层模型设计(DWS):确认业务主体和数据域,根据总线矩阵,面向业务主体建模;确认公用的指标,不可累加的衍生指标(如比率、比例等)拆成可累加的指标,建议时间修饰的派生指标(如最近7天的销售金额等)统一由ADS层处理;统计各个主题对象的当天行为。
应用汇总层设计(ADS):确认业务场景,将同主体的DWS层模型进行组装,生成应用个性化指标以及处理时间修饰的派生指标。
参考文档:
数仓建模图解