DAY24:信息搜集
DAY24:信息搜集
1、接受任务阶段
一个ip #黑盒测试
一个系统 #可能在内网
一个平台 #甚至只有名字
确定目标
2、信息搜集
当开始做信息收集之前,肯定是要先确定目标的,在红队项目或者 HW 项目中,一般目标都是一个公司的名称,然后通过这个公司的名称获取各种信息,接着开展外网打点、内网渗透等等工作。
在我们得知目标公司名称后,就可以开展信息收集的工作了。
2.1、搜索引擎(google、shodan、fofa、bing)
Google语法:
基础语法:
intext: 把网页中的正文内容中的某个字符作为搜索的条件。
intitle: 把网页标题中的某个字符作为搜索的条件。
inurl: 搜索包含指定字符的url。
site: site:thief.one将返回所有和这个站有关的URL。
Link: link:thief.one可以返回所有和thief.one做了链接的URL。
filetyp: 制定一个格式类型的文件作为搜索对象。
cache: 搜索搜索引擎里关于某些内容的缓存,可能会在过期内容中发现有价值的信息。
Index of/ 使用它可以直接进入网站首页下的所有文件和文件夹中搜索引擎中输入"index of/" 关键词。
define: 搜索某个词语的定义。
info: 查找指定站点的一些基本信息
-关键字 -不希望出现该关键字的页面
字符用法:
+ 把google可能忽略的字列如查询范围。
- 把某个字忽略,例子:新加 -坡。
~ 同意词。
. 单一的通配符。
通配符 可代表多个字母。
“” 精确查询。
不同国家:
inurl:tw 台湾
inurl:jp 日本
敏感信息搜索:
filetype:xls (内容,比如身份证)
site:xx.com intitle:管理|后台|登录
intitle:管理|登录|后台
搜索指定关键字:
inurl:php?id=
inurl:asp?id=
搜索敏感页面:
在指定站点钟寻找上传页面
site:ke xx.com inturl:load
intitle:“index of” etc
intitle:“Index of” .sh_history
intitle:“Index of” .bash_history
intitle:“index of” passwd
intitle:“index of” people.lst
intitle:“index of” pwd.db
intitle:“index of” etc/shadow
intitle:“index of” spwd
intitle:“index of” master.passwd
intitle:“index of” htpasswd
inurl:service.pwd
搜索重要文件:
例如:robots.txt 告知搜索引擎,网站中的那些目录不希望被蜘蛛爬行到。
site:xx.com inturl:robots.txt
site:xx.com inturl:txt
torrent文件类型名称,torrent 种子文件,可以写任意拓展名
site:xx.com filetype:mdb
site:xx.com filetype:ini
xxxx filetype:torrent
intext:user.sql intitle:index.of 技巧
intext:user.sql查询包含user.sql 用户数据信息的页面
intitle:index.of 表示网站目录是开放状态
查找同类型网站:
related:www.sxu.edu.cn 将返回与 www.llhc.edu.cn 相似的页面
查看服务器使用的程序:
site:xx.com filetype:php
site:xx.com filetype:asp
site:xx.com filetype:jsp
site:xx.com filetype:aspx
可判断网站用的什么语言编写
搜索c段:
site:218.87.21.*
拓展:
allinurl/inurl、allintitle/intitle的区别
allinurl、allintitle会比inurl、intitle的搜索范围小
allinurl、allintitle搜索到的结果大多数会匹配到内部网页
inurl、intitle的搜索会包含内网内容与url。
filetype:pdf +"身份证号" +site:"edu.cn"
inurl:login|admin|manage|member|admin_login|login_admin|system|login|user|main|cms +site:"edu.cn"
site:"edu.cn" filetype:conf
site:"edu.cn" filetype:properties -Repository
site:edu.cn inurl:log
site:edu.cn +inurl:/fckeditor/
site: edu.cn intitle:”index of /”
site: edu.cn inurl:admin(login、manage、system、console)
site:edu.cn intext:管理|后台|登陆|用户名|密码|验证码|系统|帐号|admin|login|sys|managetem|password|username
存在的数据库:site:域名 filetype:mdb|asp|#
查看脚本类型:site:域名 filetype:asp/aspx/php/jsp
迂回策略入侵:inurl:cms/data/templates/images/index/
在线google dork
https://pentest-tools.com/information-gathering/google-hacking#
bing:
大致相同
inbody
intitle//不好用
language//指定语言
url://搜索url
filetype
3、空间搜索引擎
3.1、fofa
| type=service | 搜索所有协议资产,支持subdomain和service两种 | |
| os=“centos” | 搜索CentOS资产。 | |
| server==“Microsoft-IIS/10” | 搜索IIS 10服务器。 | |
| title=“beijing” | 网页标题 | |
| header=“elastic” | 从http头中搜索“elastic” | |
| body=“网络空间测绘” | 网页返回的内容 | |
| fid=“kIlUsGZ8pT6AtgKSKD63iw==” | 查找相同的网站指纹 | |
| domain=“qq.com” | ||
| icp=“京ICP证030173号” | 网络服务提供商 | |
| js_name=“js/jquery.js” | js的名字 | |
| js_md5=“82ac3f14327a8b7ba49baa208d4eaa15” | js的md5 | |
| icon_hash=“-247388890” | iconhash | |
| host=“.gov.cn” | 从url中搜索”.gov.cn” | |
| port=“6379” | 端口 | |
| ip=“1.1.1.1” | 具体某个ip | |
| ip=“220.181.111.1/24” | ip支持无分类 | |
| status_code=“402” | 服务器状态 | |
| protocol=“quic” | 协议 | |
| region=“Xinjiang” | 区域 | |
| city=“Ürümqi” | 城市 | |
| cert.subject=“Oracle Corporation” | 搜索证书持有者是Oracle Corporation的资产 | |
| cert.issuer=“DigiCert” | 搜索证书颁发者为DigiCert Inc的资产 | |
| cert.is_valid=true | 证书是否有效 | |
| cert=“baidu” | 域名证书 | |
| country=“CN” | 国家 | |
| banner=users && protocol=ftp | 搜索FTP协议中带有users文本的资产。 | |
| app=“Microsoft-Exchange” | 应用,https://fofa.so/library 应用表 | |
| after=“2017” && before=“2017-10-01” | 日期 | |
| base_protocol=“udp” | 指定UDP协议 | |
| org=“LLC Baxet” | 搜索组织 |
3.2、zoomeyes
优点:会有现有漏洞分类
工具 kunyu
https://www.zoomeye.org/
白嫖关键字:
https://www.zoomeye.org/component
| filehash:“0b5ce08db7fb8fffe4e14d05588d49d9” |
|---|
| 通过上传方式进行查询,根据解析的文件数据搜索相关内容的资产 |
| 搜索包含“Gitlab”解析的相关资产 |
| iconhash:“f3418a443e7d841097c714d69ec4bcb8” |
| 通过 md5 方式对目标数据进行解析,根据图标搜索相关内容的资产 |
| 搜索包含“google”图标的相关资产 |
| iconhash:“1941681276” |
| 通过 mmh3 方式对目标数据进行解析,根据图标搜索相关内容的资产 |
| 搜索包含“amazon”图标的相关资产 |
| after:“2020-01-01” |
| 搜索更新时间为"2020-01-01"以后的资产 |
| after与before常常配合使用 |
| before:“2020-01-01” |
| 搜索更新时间在"2020-01-01"以前的资产 |
| after与before常常配合使用 |
| org:“北京大学” 或者organization:“北京大学” |
| 搜索相关组织(Organization)的资产 |
| 常常用来定位大学、结构、大型互联网公司对应IP资产 |
| [isp:“China Mobile”](https://www.zoomeye.org/searchResult?q=isp:“China Mobile”) |
| 搜索相关网络服务提供商的资产 |
| 可结合org数据相互补充 |
| asn:42893 |
| 搜索对应ASN(Autonomous system number)自治系统编号相关IP资产 |
| port:80 |
| 搜索相关端口资产 |
| 目前不支持同时开放多端口目标搜索 |
| hostname:google.com |
| 搜索相关IP"主机名"的资产 |
| site:baidu.com |
| 搜索域名相关的资产 |
| 常常使用来搜索子域名匹配 |
| cidr:52.2.254.36/24 |
| 搜索IP的C段资产 |
| cidr:52.2.254.36/16 为IP的B段资产 cidr:52.2.254.36/8 为IP的A段资产,如cidr:52.2.254.36/16cidr:52.2.254.36/8 |
| ssl:“google” |
| 搜索ssl证书存在"google"字符串的资产 |
| hostname:google.com |
| 搜索相关IP"主机名"的资产 |
| site:baidu.com |
| 搜索域名相关的资产 |
| 常常使用来搜索子域名匹配 |
| title:“Cisco” |
| 搜索html内容里标题中存在"Cisco"的数据 |
举例
site:"*.edu.cn" +org:"China Education and Research Network Center"
hostname:"edu.cn.*" +isp:"CHINAEDU"
organization:"* University"
organization:"CERNET2 IX at Southeast University"
organization:"*CERNET"
organization:"北京大学"
3.3、shodan
优点:搜索网络硬件比较方便
缺点:不支持无分类子网
shodan filter 官网
https://beta.shodan.io/search/filters
http.component
http.component_category
常用http.favicon.hash
http.html
http.html_hash
http.robots_hash
http.securitytxt
http.status
http.title
http.waf
证书
ssl
ssl.alpn
ssl.cert.alg
ssl.cert.expired
ssl.cert.extension
ssl.cert.fingerprint
ssl.cert.issuer.cn
ssl.cert.pubkey.bits
ssl.cert.pubkey.type
ssl.cert.serial
ssl.cert.subject.cn
ssl.chain_count
ssl.cipher.bits
ssl.cipher.name
ssl.cipher.version
ssl.ja3s
ssl.jarm
ssl.version
常用
all
asn
city
country
cpe
device
geo
has_ipv6
has_screenshot
has_ssl
has_vuln
hash
hostname
ip
isp
link
net
org
os
port
postal
product
region
scan
shodan.module
state
version
org:"China Education and Research Network"
jenkins
"X-Jenkins" "Set-Cookie: JSESSIONID" http.title:"Dashboard"
docker api
"Docker Containers:" port:2375
匿名FTP
220" "230 Login successful." port:21
4、外网信息收集
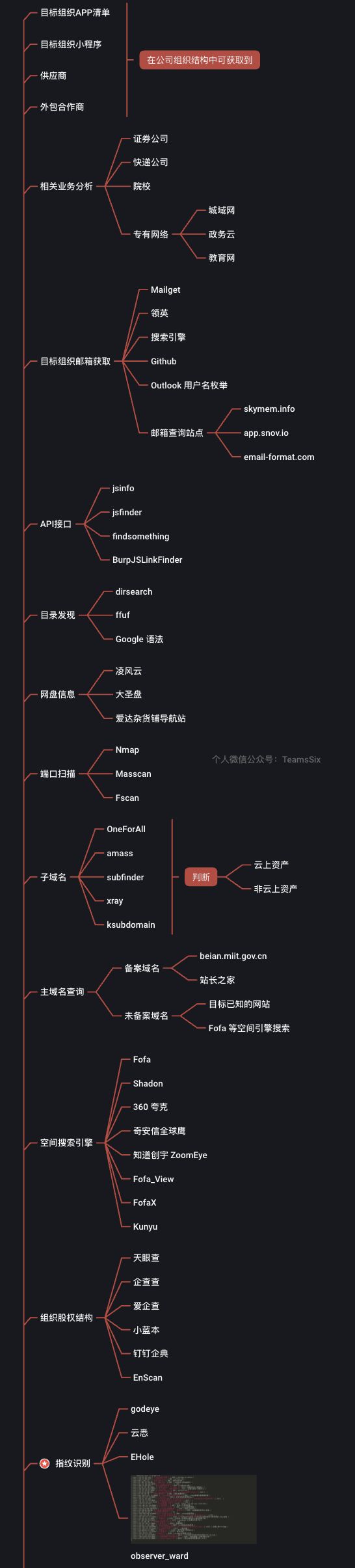
对于攻击目标的信息搜集,一般是先进行资产收集
资产收集有两种主动搜集和被动搜集
主动搜集就是自己使用扫描器来进行扫描,但是作为防守方肯定会进行ip的封禁,当你的流量过大时就会进行ip封禁。
这里就需要使用被动搜集,被动搜集就是利用网络资产测绘来进行资产搜集。
下面是一些能够用到的方法
子域名探测:OneForAll,Layer,在线子域名扫描。
网络资产测绘:鹰图,FOFA,360QUEKE。
在线工具:站长工具,爱站王,天眼查,企查查 。
第三方查询:文库,WiKi,微信公众号,校园APP
这里说一下第三方查询,第三方查询是能够作为突破口的,通过文库来获取一些重要的信息,比如测试账号,还可以把微信公众号作为突破口来进行渗透。
在线Google Hacking小工具:https://ght.se7ensec.cn/
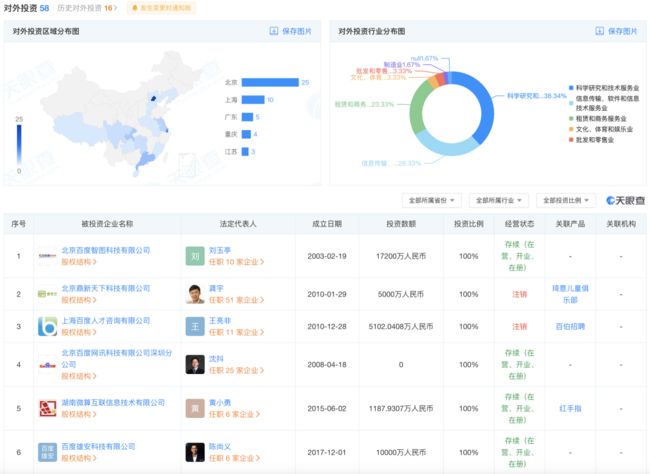
1、组织股权结构
拿到公司名称后,先不用急着查备案、找域名,而是先看看这家公司的股权构成,因为一般一家公司的子公司也是可以作为目标去打的,不过有时是要求 50% 持股或者 100% 持股,这个就要看具体实际情况了。
比较常见的查询公司组织股权结构的网站有天眼查、企查查、爱企查、小蓝本、钉钉企典等等。
ENScanGo:
ENScanGo 是现有开源项目 ENScan 的升级版本
工具地址:https://github.com/wgpsec/ENScan_GO
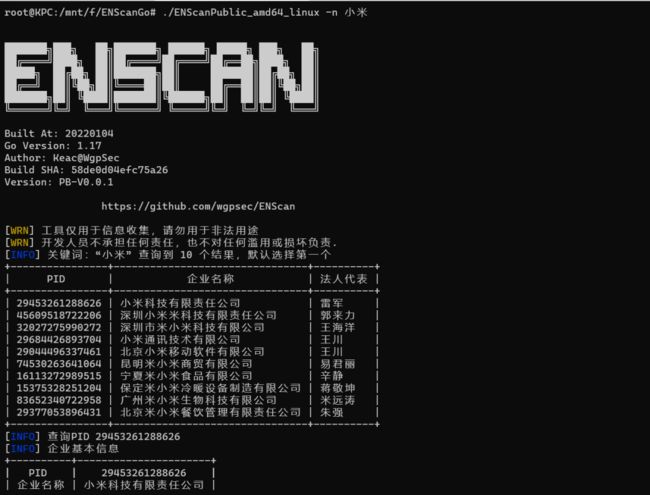
这是一款由狼组安全团队的 Keac 师傅写的专门用来解决企业信息收集难的问题的工具,可以一键收集目标及其控股公司的 ICP 备案、APP、小程序、微信公众号等信息然后聚合导出。
enscan -n 北京百度网讯科技有限公司 -invest-num 50
3、子域获取
比较常见的工具就是 OneForAll,除此之外还有 amass、subfinder、xray、ksubdomain 等等。
如果提前知道目标,还可以提前收集一波子域,然后项目快开始的时候,再收集一波子域,将两次收集的结果做下对比,优先打新增子域。
4、端口扫描
一般比较常见的可能就是 nmap 和 masscan 了,这里分享一个 nmap 快速扫描全部端口的命令。
nmap -sS -Pn -n --open --min-hostgroup 4 --min-parallelism 1024 --host-timeout 30 -T4 -v -p 1-65535 -iL ip.txt -oX output.xml
不过除了这些方法外,fscan 其实也可以拿来做外网的端口扫描,而且速度更快。
比如用 fscan 只扫描端口,不做漏洞扫描
fscan -hf hosts.txt --nopoc -t 100
fscan 默认线程是 600,因为是外网扫描 600 的线程就比较大了,所以这里设置了 100,如果感觉扫描结果不理想,线程还可以设置的再小点。
端口扫描可以结合空间搜索引擎的结果,如果通过空间搜索引擎发现目标存在很多的高位端口,那么在进行端口扫描的时候就要记得也把这些高位端口加上。
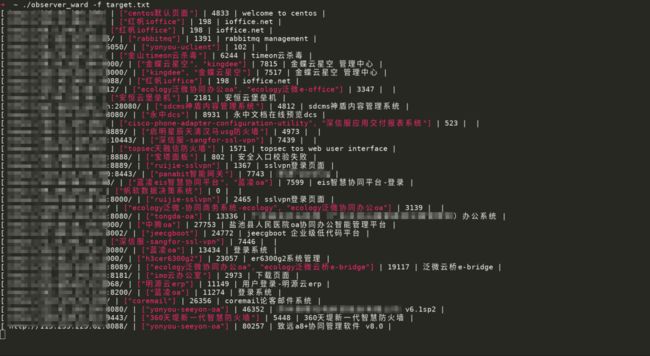
5、指纹识别
指纹识别是我个人觉着非常重要的一点,因为指纹识别的结果对打点的帮助是很大的,可以让打点更有针对性,同时也会节省很多时间。
比较常见的在线指纹查询网站有 godeye 和云悉等,工具有 observer_ward 和 Ehole 等。
6、空间搜索引擎
擅用空间搜索引擎,有时可以在最初刚拿确定目标的时候就发现目标弱点。
目前比较常见的空间搜索引擎有 Fofa、Shodan、360 夸克、奇安信全球鹰、知道创宇 ZoomEye 等等。
常见的工具有 Fofa_Viewer、FofaX、Kunyu,其中 Fofa_Viewer 为图形化界面,使用友好。
下载地址:
https://github.com/wgpsec/fofa_viewer
FofaX 为命令行界面,FofaX 可以结合其他工具联动使用,除了这两个工具调用 Fofa 接口外,上面提到的 Ehole 也可以调用 Fofa 查询。
Kunyu 调用的是 ZoomEye 的接口,工具下载地址:
https://github.com/knownsec/Kunyu

7、api 接口
获取 api 接口常用的工具有 jsinfo、findsomething、jsfinder、BurpJSLinkFinder 等等。
如果找到了一些未授权接口,也许就可以搞到一些高价值信息,比如大量敏感信息泄露之类的。
另外在翻 js 文件的时候,可以关注下有没有以 runtime 命名的 js 文件,因为在这种 js 文件中会包含其他 js 文件的名称(包括当前页面没有加载的 js 文件),这样利用 runtime js 文件就发现了更多的 js 文件,使得找到 api 接口的概率又大了些。
8、目录获取
目录扫描比较常用的工具有 dirsearch、ffuf
ffuf 更侧重于 FFUZ,不过不管是目录扫描还是 FFUZ ,扫描的结果都在于字典,Github 上 4k 多个 star 的字典:
https://github.com/TheKingOfDuck/fuzzDicts
9、邮箱地址获取
邮箱地址比较常用的方法有直接通过搜索引擎找网上公开的邮箱信息,这种往往会指向目标的网站中,比如目标某个网页的附件中包含有邮箱等信息。
之外还可以使用 Github 搜索目标公司开发者在代码中注释的邮箱信息,其实不太明白为什么开发者都喜欢把自己的邮箱注释到代码里。
也可以通过领英找到目标公司的员工姓名,通过「拼音+@公司域名」的方法去构造员工邮箱。
也有一些网站可以查询邮箱,这种比较方便,比如以下网站:
https://www.skymem.info/
https://app.snov.io/domain-search
https://www.email-format.com/i/search/
另外如果收集到了目标的 outlook 站点,也可以尝试去爆破邮箱用户名。
10、网盘信息
网盘信息里有时也会发现不少好东西,这类网站也很多,可以在爱达杂货铺导航站里找到很多网盘搜索类站点
11、其他信息
其他的信息比如 app、小程序、供应商、外包合作商、公众号等,或多或少都可以从上面的组织股权架构类网站中查询到,或者使用 ENScan 也可以。
其中比较值得注意是的供应商和外包合作商,如果拿下供应商也许可以直接进入目标内网,如果拿下外包合作商则可以借助这一层关系进行社工或者尝试进入目标内网等操作。

CrackMinApp
/data/data/com.tencent.mm/MicroMsg/.../appbrand/pkg/
小程序路径
小程序渗透-修炼五脉
https://cloud.tencent.com/developer/column/90188
4.1、github
https://github.com/dongfangyuxiao/github_dis
可能包含一些密钥,以及相关的测试域名
topics:>=5 标签数量大于等于5的
size:<5000 文件小于5KB的
stars:10..50 star大于10小于50的
pushed:<2020-02-02 搜索在2020年2月2日前
pushed:2020-01-01..2020-02-02 搜索在此区间
created:>=2020-02-02 创建时间
pushed:2020-02-02 -language:java 搜索在2020年2月2日前push代码且排除java语言
in:file 搜索文件中包含的代码
in:path 搜索路径中包含的代码
in:path,file 搜索路径、文件中包含的代码
path:aiyou/bucuo language:javascript 搜索关键字,且语言为JavaScript,路径在aiyou/bucuo下的代码
filename:config.php language:php 搜索文件名为config.php,且语言为php
in:name 关键词 仓库名称包含Xx的仓库
in:descripton 关键词 查找描述的内容
in:readme 关键词 查README文件包含特定关键词
4.2、google配合github
Google
site:Github.com smtp
site:Github.com smtp @qq.com
site:Github.com smtp @163.com
site:Github.com smtp password
site:Github.com String password smtp
...
我们也可以锁定域名搜索结合厂商域名 灵活运用例如搜百度的
site:Github.com smtp @baidu.com
site:Github.com svn
site:Github.com svn username
site:Github.com svn password
site:Github.com svn username password
...
site:Github.com sa password
site:Github.com root password
site:Github.com User ID=’sa’;Password
5、渗透测试
5.1、0day 和 nday
这些年来比较常见的 0day 与 nday 相关服务有 Shiro、Fastjson 为代表的中间件,泛微、致远、通达为代表的 OA 系统,之外还有用友、各类安全设备、VPN 等等。
在上文中提到了指纹识别,这里就能派上用场了,比如如果最近爆出来了某某 cms 存在 0day,那么通过指纹识别的结果找到存在这个 cms 的资产,直接就能打到点,但如果指纹识别的不准确或者漏识别,也许就会比别人少了一个点。
另外可以预见的是未来关于 log4j2 的利用肯定会越来越多。
同时结合目前的国内情况来看,关于这些 0day 和 nday 的详情以及相应的利用工具也会越来越小范围得被传播,即使有些会被大范围传播,但一些内部版、增强版的工具还是会小范围的传播。
5.2、合法账号
合法账号也是目前比较常见的方式,比如通过字典爆破、社工字典爆破、弱密码猜解或者钓鱼获得目标的 VPN、SSH、RDP、Citrix 可用账号等等。
但这类打点方式有时不如利用 0day 和 nday 来得快,只要对方没有什么弱密码就比较难进了,不过也会经常遇到弱密码 yyds 的情况。
不过在内网中,利用合法账号就比利用 0day 和 nday 来得快了,因为在内网中常常会有通用密码,拿到这个通用密码,或许就能拿下一大批 Linux、Windows。
同时在进入系统后,往往还会发现密码本或者浏览器存储密码等等,这样利用合法账号又能拿下不少系统的权限,不过这就偏离本文打点的主题了,就不再展开了。
5.3、钓鱼邮件
其次就是邮件内容的问题,一般会使用一些近期的热点事件、节假日通知等等作为话术的主题,比如《关于离开本市返乡过年需要报备的通知》《关于春节放假时间安排的通知》等等这类吸引人们查看的话术。
5.4、近源攻击
WIFI 钓鱼,比如大菠萝等设备
通过 NFC 设备复制目标员工门禁卡,方便接下来进入到目标办公区
通过 bad usb 钓鱼
直接连接墙上的网卡(风险有些高)
在目标建筑附近连接对方的访客 WIFI,比如利用无人机、雷达型无线网卡等,或者将一个带有远控功能的 4G 无线路由器放到目标附近
5.5、masscan(最快的扫描一个端口看看有没有业务)
ubuntu编译
$ sudo apt-get install git gcc make libpcap-dev
$ git clone https://github.com/robertdavidgraham/masscan
$ cd masscan
$ make
$ cp bin/masscan /bin/
centos编译
git clone https://github.com.cnpmjs.org/robertdavidgraham/masscan
yum install clang
cd /masscan && make
cd /masscan/bin && ./masscan --ping 8.8.8.0/24
5.6、xray
https://github.com/chaitin/xray
爬虫:rad
被动扫描
https://docs.xray.cool/#/tutorial/introduce
xray_windows_amd64.exe webscan --listen 127.0.0.1:7777 --html-output 123.html
5.7、战法
战法一:声东击西
通过大规模的漏扫去进行大流量攻击。
然后小流量进行攻击主要目标,让蓝队无法抽身。
大流量攻击使用的是AWVS,GOBY,XRAY等扫描工具进行
大规模的漏洞扫描。让蓝队的精力放在这边。
然后剩余队员利用0day或者Nday进入内网渗透。
前期通过漏洞检测,获取到目标单位的多个入口点,而利用代理穿透的方式进行内网渗透总是被安全设备识别并拉黑ip
使用多个入口点同时进行攻击的方式,扰乱蓝方视线,最终使用VPN顺利完成内网渗透。
战法二:剑走偏锋
正面对目标单位进行攻击时,由于防护过高,无法突破。
重新整合信息,对目标单位进行分析是查看是否使用了第三方系统。
通过对第三方系统进行查看得到具体的软件供应商,并发现全国多所高校都使用了该系统。
对软件供应商进行社工,得到其系统的说明文档及演示视频。在演示视屏中由于人员意识不足,泄露多个系统密码。
进一步分析后,最终通过供应链攻击,获取到软件供应商的全国后台控制系统,进而夺得了目标单位系统权限,并控制很多高校系统。
战法三:利用平行垂直越权。
从我们运维经验看,是各类系统普遍存在问题。
尤其是平行越权。
API越权风险可能更高。
战法四:利用暴露在外网的设备建立通道。
存在对设备的错误认识。
使用默认密码,弱密码,成为攻击内网跳板。
战法五:利用VPN进入校园网
各个高校普遍为师生提供VPN,WebVPN。
VPN账号泄露普遍存在,基本没有访问控制,可进入各类系统。
战法六:内网横向渗透
缺乏必要隔离,可以通过横向访问,绕过安全设备。
要建立纵深防御,至少根据业务重要性分级隔离,东西向可能隔离。
6、内网探测(反溯源)
6.1、主机加固术
理想条件可以准备一个虚拟机来专门进行攻击操作。虚拟机中只装渗透需要工具,并设置快照,每次攻击前重置攻击机。其他通用加固手段如下
1、攻击机中不要保存任何可以用来分析个人或公司身份的特征的文件;
如条件有限可以将具备个人或个人特征的数据放在加密磁盘内,加大溯源难度,当然前提你自己不要用弱密码管理磁盘加密软件。常用加密软件如VeraCrypt,EasyFileLocker。
2、打全补丁,只对外开放必要端口,危险服务或软件,并安装有效杀毒软件;
最好设置补丁自动更新,避免人工打补丁造成疏漏
3、不连接特征明显的热点,如以公司命名的wifi,个人名字的热点;
电脑会记录WiFi连接记录,记录中具备特征的记录一定要进行删除
4、电脑用户名不要使用可能识别特征的用户名;
5、不登录任何社交软件与社交平台;
6、保持浏览器中不会储存任何个人相关信息;
细节操作有:开启无痕模式(或开启退出清空Cookie),关闭⾃动填充功能,控制网站操作权限。
7、停用mic与摄像头等设备;
如笔记本可以卸载其驱动,并使用不透明贴纸覆盖覆盖摄像头
6.2、特征隐藏术
工具特征隐藏
1、扫描器、Payload以及其他工具要去除特征,不要带有任何id,git,博客连接等;
2、DNSLOG、XSS等平台不要使用网上在线版本,在线版本特征过于明现容易被流量设备识别;
3、尽量减少文件的落地,落地的文件需要注意隐藏,
与目标其他文件名称和时间属性进行同化,并设置隐藏;
4、植⼊Webshell⼀句话脚本时,尽量选择⾸⻚index⾥被包含的⽂件;
5、拿到shell后,开启命令⽆痕模式;
6、c2,内网穿透等工具不要使用默认端口,并定期修改密码
6.3、交互特征隐藏
1、渗透过程中任何需要交互认证的地⽅,都不要⽤个⼈、公司有关的名词 ;
涉及手机号和邮箱接时,可以考虑使⽤匿名接收平台 。
2、社⼯过程中不要使用自己的真实社交账号,有条件的情况最好每次注册或购买新的账号;
3、漏扫自动打点时,尽量使用动态随机UA头,避免被浏览设备识别并拦截 ;
4、域名或服务器在创建时不要使用自己名字;
6.4、流量特征隐藏
1、攻击机的出口IP,不要使⽤个⼈、公司IP, 尽量使用物联⽹卡、或代理池IP ;
2、C2或其他工具的流量特征需要进行对应的去除或者修改 ;
3、各种攻击资源尽量不要放在一套服务器上,最好使用短期或定时重置ip以预防危险情报标记;
4、尽量不要直接暴露c2的ip,要使用隐藏技术保障c2的安全性;
比较常用的隐藏技术如云函数,域前置,cdn等技术。
5、在服务器上开启⽂件服务,需⽤完即关,严禁开启各种⽆⽤的⾼危端⼝;
6、尽量使用加密协议传输请求
6.5、溯源反制术
蜜罐简单识别
1、网站是否存在大量请求其他域资源;
2、网站是否对于各大社交网站发送请求;
3、网站是否存在大量请求资源报错,克隆其他站时没有修改完成;
4、存在⾮常多漏洞的站点,拿到shell后处于docker等虚拟环境,开放⼤量⾼危端⼝的;
5、获取到PC机器后,PC机器⽤户⻓时间划⽔摸⻥;
6、从目标获取的文件需要在沙箱或断网虚拟机运行,避免被反制;
6.6、溯源反制思路与手段
攻防的过程本为一体两面,上文介绍了反溯源的基本思路,溯源的反制其实也是溯源技术的一种另类应用,所谓溯源反制大体可以分为两类;
1、通过伪造特征,导致溯源到其他人身上,达到祸水东引的效果;
如将电脑名称或是工具文件名称伪造为其他单位或者是人员的名称
2、通过追查溯源方的特性,反向溯源出对方;
特殊情况下也可以诱导溯源方在本地执行木马文件,从而控制对方主机
知识点总结
1.未授权访问
2.SQL Server xp_cmdshell提权
3.Procdump+mimikatz配合抓取密码
4.木马文件执行时提示缺少某个dll文件
5.CobaltStrike从内存加载.NET程序集
6.CobaltStrike与Metasploit之间的会话传递
搭建资产信息收集
系统信息:Unix linux windows ios
可以通过ping命令来获取TTL值判断,根据TTL值跟哪一个更近则是哪个操作系统
WINDOWS NT/2000 TTL:128
WINDOWS 95/98 TTL:32
UNIX TTL:255
LINUX TTL:64
WIN7 TTL:64
通过改变网址链接大小写来判断操作系统是Windows还是Linux是不完全正确的,因为和他的中间键会有关系。不要在网址后的参数上改变大小写(问号后的值),要在登录性文件上去改变(比如index.php)
组合对应:
通过中间件,数据库,语言等判断操作系统(比如asp,aspx等等语言数据库的一般都是windows系统,因为asp,aspx不支持linux系统上运行)
aspx mssql windows iis
php mysql windows/linux apache
jsp mssql/oracle windows/linux tomcat
javaee mysql/oracle windows/linux weblogic/jboos/tomcat
中间件:
apache(80) weblogic(7001) jboos(8080) tomcat(8080) iis(80) nginx(80)
返回包:
f12查看,或者抓包查看,端口扫描查看
数据库:
关系型数据库:
access(文件型数据库,没有端口号)
mysql(3306)
mssql=SQL Server(1433)
oracle(1521)
db2(5000)
postgresql(5432)
非关系型数据库:
redis(6379)
mongodb(27017)
语言:
(1)通过url获取。通过组合猜解。(通常php配合mysql使用)
(2)通过盲猜是否报错来判断语言(比如默认首页文件都是index,default,main.py,admin,login等等,通过输入不同类型语言的首页文件判断网站是啥语言)
IP类站点:直接利用返回IP进行测试访问
目录类站点:利用目录爬行(awvs)或者目录扫描(御剑)进行获取
端口类站点:利用端口扫描进行服务探针进行获取
子域名站点:利用子域名查询工具进行获取
源码的获取
源码获取:
CMS识别: 尝试获取源码(开源,售卖,自研,未公开):云溪指纹识别网站。
通过url中特有文件进行关键字搜索,或者通过github等平台进行搜索
备份文件泄露,敏感文件css等可能存在特征:
使用子域名扫描可能存在特殊的备份文件被开发者将源码打包(目录扫描:御剑,7kbscan),扫描到是否有备份文件,敏感文件。
资产监控: github,gitee
git信息泄露:
访问 xxx/.git 文件 403或存在即可尝试获取源码
工具:githack.py(后台获取)
svn信息泄露:
访问xxx/.svn/entries 内容存在即可尝试获取源码
工具:svnhack.py(后台获取)
DS_Store泄露:
该文件为mac下的数据文件,访问存在即可尝试获取源码
工具:ds_dore.py(后台获取)
php特性配置说明文件composer.json泄露:
访问composer.json存在即可尝试获取源码相关信息
WEB-INF/web.xml 泄露:
域名信息的获取
子域名挖掘机。
在线子域名平台。
网站备案信息查询:获取备案号,网站名称,公司名称等等。
域名注册页面查看该网站注册的域名信息。
whois查询
信息收集的目标
基础信息:
源码信息,组件等
系统信息:
windows/linux(大小敏感判断,ttl值参考判断)
应用信息:
网站的功能类型等信息
防护信息:
面板,waf等
人员信息:
账户弱口令等
「技术点」:
cms/框架识别,端口扫描,cdn绕过,源码获取,子域名扫描,子域名信息查询,waf识别,负载均衡识别(lbd)等
源码类型的判断:
文件后缀,请求头信息等
中间件:
请求头参考
数据库判断:
常见的脚本搭配(php+mysql aspx+mssql等),默认端口的参考,扫描器(nmap,appscan,网页在线扫描)
WAF的识别:
(1)通过页面的报错来判断WAF的类型。
(2)通过工具进行识别(wafw00f)
旁注,C段,IP反查
旁注:同服务器下的不同站点(旁注在线查询平台)
C段:同网段不同服务器下的不同站点
IP反查:利用IP获取服务器解析域名(在线ip反查平台)
**CDN绕过 **
多地ping,nslookup解析查询
获取网站真实地址:子域名,去掉www,邮件服务器,国外访问,抓包
思路总览
1、信息搜集:
学校网站域名
泄露VPN
Github源码
进源途径
2、寻找突破口:
边缘资产域名
VPN
WiFi接入口
模拟校园卡
邮件钓鱼
3、内网权限获取:
业务逻辑漏洞
设备直连
圈存机注入
弱口令
人员意识漏洞
中间件漏洞
操作系统漏洞
4、权限提升:
提权漏洞
权限维持
远控软件
VPN越权
5、横向漫游:
内网扫描
漏洞指纹识别
特权隐匿
拓扑获取
已连接IP
6、获取目标:
敏感信息
主机权限
r.json存在即可尝试获取源码相关信息
### WEB-INF/web.xml 泄露:
域名信息的获取
子域名挖掘机。
在线子域名平台。
网站备案信息查询:获取备案号,网站名称,公司名称等等。
域名注册页面查看该网站注册的域名信息。
whois查询
## 信息收集的目标
基础信息:
源码信息,组件等
系统信息:
windows/linux(大小敏感判断,ttl值参考判断)
应用信息:
网站的功能类型等信息
防护信息:
面板,waf等
人员信息:
账户弱口令等
**「技术点」**:
cms/框架识别,端口扫描,cdn绕过,源码获取,子域名扫描,子域名信息查询,waf识别,负载均衡识别(lbd)等
**源码类型的判断:**
文件后缀,请求头信息等
**中间件:**
请求头参考
**数据库判断:**
常见的脚本搭配(php+mysql aspx+mssql等),默认端口的参考,扫描器(nmap,appscan,网页在线扫描)
### WAF的识别:
(1)通过页面的报错来判断WAF的类型。
(2)通过工具进行识别(wafw00f)
**旁注,C段,IP反查**
旁注:同服务器下的不同站点(旁注在线查询平台)
C段:同网段不同服务器下的不同站点
IP反查:利用IP获取服务器解析域名(在线ip反查平台)
**CDN绕过 **
多地ping,nslookup解析查询
获取网站真实地址:子域名,去掉www,邮件服务器,国外访问,抓包
## 思路总览
### 1、信息搜集:
学校网站域名
泄露VPN
Github源码
进源途径
### 2、寻找突破口:
边缘资产域名
VPN
WiFi接入口
模拟校园卡
邮件钓鱼
### 3、内网权限获取:
业务逻辑漏洞
设备直连
圈存机注入
弱口令
人员意识漏洞
中间件漏洞
操作系统漏洞
### 4、权限提升:
提权漏洞
权限维持
远控软件
VPN越权
### 5、横向漫游:
内网扫描
漏洞指纹识别
特权隐匿
拓扑获取
已连接IP
### 6、获取目标:
敏感信息
主机权限
痕迹擦除