极客时间 Kafka核心技术与实战 学习笔记02
11 | 无消息丢失配置怎么实现
那 Kafka 到底在什么情况下才能保证消息不丢失呢?
一句话概括,Kafka 只对“已提交”的消息(committed message)做有限度的持久化保证。
第一个核心要素是“已提交的消息”。什么是已提交的消息?当 Kafka 的若干个 Broker 成功地接收到一条消息并写入到日志文件后,它们会告诉生产者程序这条消息已成功提交。此时,这条消息在 Kafka 看来就正式变为“已提交”消息了
那为什么是若干个 Broker 呢?这取决于你对“已提交”的定义。你可以选择只要有一个 Broker 成功保存该消息就算是已提交,也可以是令所有 Broker 都成功保存该消息才算是已提交。不论哪种情况,Kafka 只对已提交的消息做持久化保证这件事情是不变的
第二个核心要素就是“有限度的持久化保证”,也就是说 Kafka 不可能保证在任何情况下都做到不丢失消息。举个极端点的例子,如果地球都不存在了,Kafka 还能保存任何消息吗?显然不能!倘若这种情况下你依然还想要 Kafka 不丢消息,那么只能在别的星球部署 Kafka Broker 服务器了
Producer 永远要使用带有回调通知的发送 API,也就是说不要使用 producer.send(msg),而要使用 producer.send(msg, callback)。不要小瞧这里的 callback(回调),它能准确地告诉你消息是否真的提交成功了。一旦出现消息提交失败的情况,你就可以有针对性地进行处理
举例来说,如果是因为那些瞬时错误,那么仅仅让 Producer 重试就可以了;如果是消息不合格造成的,那么可以调整消息格式后再次发送。总之,处理发送失败的责任在 Producer 端而非 Broker 端
案例 2:消费者程序丢失数据Consumer 端丢失数据主要体现在 Consumer 端要消费的消息不见了。Consumer 程序有个“位移”的概念,表示的是这个 Consumer 当前消费到的 Topic 分区的位置。下面这张图来自于官网,它清晰地展示了 Consumer 端的位移数据。
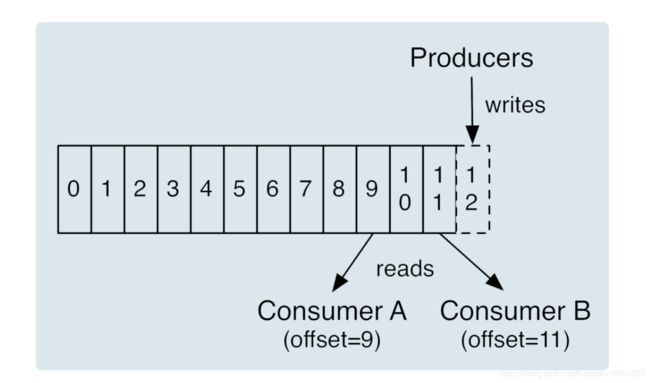
同理,Kafka 中 Consumer 端的消息丢失就是这么一回事。要对抗这种消息丢失,办法很简单:维持先消费消息(阅读),再更新位移(书签)的顺序即可。这样就能最大限度地保证消息不丢失



14 | 幂等生产者和事务生产者是一回事吗?

目前,Kafka 默认提供的交付可靠性保障是第二种,即至少一次
我们说过消息“已提交”的含义,即只有 Broker 成功“提交”消息且 Producer 接到 Broker 的应答才会认为该消息成功发送。不过倘若消息成功“提交”,但 Broker 的应答没有成功发送回 Producer 端(比如网络出现瞬时抖动),那么 Producer 就无法确定消息是否真的提交成功了。因此,它只能选择重试,也就是再次发送相同的消息。这就是 Kafka 默认提供至少一次可靠性保障的原因,不过这会导致消息重复发送。
Kafka 是怎么做到精确一次的呢?简单来说,这是通过两种机制:幂等性(Idempotence)和事务(Transaction)。它们分别是什么机制?两者是一回事吗?要回答这些问题,我们首先来说说什么是幂等性。
enable.idempotence 被设置成 true 后,Producer 自动升级成幂等性 Producer,其他所有的代码逻辑都不需要改变。Kafka 自动帮你做消息的重复去重。底层具体的原理很简单,就是经典的用空间去换时间的优化思路,即在 Broker 端多保存一些字段。当 Producer 发送了具有相同字段值的消息后,Broker 能够自动知晓这些消息已经重复了,于是可以在后台默默地把它们“丢弃”掉。当然,实际的实现原理并没有这么简单,但你大致可以这么理解。
首先,它只能保证单分区上的幂等性,即一个幂等性 Producer 能够保证某个主题的一个分区上不出现重复消息,它无法实现多个分区的幂等性。其次,它只能实现单会话上的幂等性,不能实现跨会话的幂等性。这里的会话,你可以理解为 Producer 进程的一次运行。当你重启了 Producer 进程之后,这种幂等性保证就丧失了。
那么你可能会问,如果我想实现多分区以及多会话上的消息无重复,应该怎么做呢?答案就是事务(transaction)或者依赖事务型 Producer。这也是幂等性 Producer 和事务型 Producer 的最大区别!
Kafka 自 0.11 版本开始也提供了对事务的支持,目前主要是在 read committed 隔离级别上做事情。它能保证多条消息原子性地写入到目标分区,同时也能保证 Consumer 只能看到事务成功提交的消息。下面我们就来看看 Kafka 中的事务型 Producer。
事务型 Producer
事务型 Producer 能够保证将消息原子性地写入到多个分区中。这批消息要么全部写入成功,要么全部失败。另外,事务型 Producer 也不惧进程的重启。Producer 重启回来后,Kafka 依然保证它们发送消息的精确一次处理。设置事务型 Producer 的方法也很简单,满足两个要求即可:
和幂等性 Producer 一样,开启 enable.idempotence = true。
设置 Producer 端参数 transactional. id。最好为其设置一个有意义的名字

幂等性 Producer 只能保证单分区、单会话上的消息幂等性;而事务能够保证跨分区、跨会话间的幂等性。从交付语义上来看,自然是事务型 Producer 能做的更多。
比起幂等性 Producer,事务型 Producer 的性能要更差,在实际使用过程中,我们需要仔细评估引入事务的开销,切不可无脑地启用事务。
15 | 消费者组到底是什么?



老版本的 Consumer Group 把位移保存在 ZooKeeper 中。Apache ZooKeeper 是一个分布式的协调服务框架,Kafka 重度依赖它实现各种各样的协调管理。将位移保存在 ZooKeeper 外部系统的做法,最显而易见的好处就是减少了 Kafka Broker 端的状态保存开销。现在比较流行的提法是将服务器节点做成无状态的,这样可以自由地扩缩容,实现超强的伸缩性。Kafka 最开始也是基于这样的考虑,才将 Consumer Group 位移保存在独立于 Kafka 集群之外的框架中。
不过,慢慢地人们发现了一个问题,即 ZooKeeper 这类元框架其实并不适合进行频繁的写更新,而 Consumer Group 的位移更新却是一个非常频繁的操作。这种大吞吐量的写操作会极大地拖慢 ZooKeeper 集群的性能,因此 Kafka 社区渐渐有了这样的共识:将 Consumer 位移保存在 ZooKeeper 中是不合适的做法
于是,在新版本的 Consumer Group 中,Kafka 社区重新设计了 Consumer Group 的位移管理方式,采用了将位移保存在 Kafka 内部主题的方法。这个内部主题就是让人既爱又恨的 __consumer_offsets。我会在专栏后面的内容中专门介绍这个神秘的主题。不过,现在你需要记住新版本的 Consumer Group 将位移保存在 Broker 端的内部主题中

讲完了 Rebalance,现在我来说说它“遭人恨”的地方。
首先,Rebalance 过程对 Consumer Group 消费过程有极大的影响。如果你了解 JVM 的垃圾回收机制,你一定听过万物静止的收集方式,即著名的 stop the world,简称 STW。在 STW 期间,所有应用线程都会停止工作,表现为整个应用程序僵在那边一动不动。Rebalance 过程也和这个类似,在 Rebalance 过程中,所有 Consumer 实例都会停止消费,等待 Rebalance 完成。这是 Rebalance 为人诟病的一个方面。
其次,目前 Rebalance 的设计是所有 Consumer 实例共同参与,全部重新分配所有分区。其实更高效的做法是尽量减少分配方案的变动。例如实例 A 之前负责消费分区 1、2、3,那么 Rebalance 之后,如果可能的话,最好还是让实例 A 继续消费分区 1、2、3,而不是被重新分配其他的分区。这样的话,实例 A 连接这些分区所在 Broker 的 TCP 连接就可以继续用,不用重新创建连接其他 Broker 的 Socket 资源。
最后,Rebalance 实在是太慢了。曾经,有个国外用户的 Group 内有几百个 Consumer 实例,成功 Rebalance 一次要几个小时!这完全是不能忍受的。最悲剧的是,目前社区对此无能为力,至少现在还没有特别好的解决方案。所谓“本事大不如不摊上”,也许最好的解决方案就是避免 Rebalance 的发生吧。