Linux之强大的gawk
awk介绍
awk是Linux文本处理工具三剑客之一,它是一种报表生成器,用于对文件内容进行各种"排版",然后进行格式化显示。
在Linux上,我们使用的是GNU awk 简称gawk,其实,gawk就是awk的链接文件,因此,在系统上使用awk和gawk是一样的
gawk是一种过程式编程语言,它支持条件判断,数组,循环等各种编程语言中所有可以使用的功能,因此,我们还可以把gawk称为一种脚本语言解释器
awk是模式扫描和处理语言,该程序通常由: BEGIN语句块、能够使用模式匹配的通用语句块 、END语句块,共3部分组成
awk的三种运行方式:
(1) awk 命令行
awk(2) awk 程序文件
awk -f /path/from/awk_script(3) awk 脚本
#!/bin/awk -fawk 的基本用法
awk [options] 'program' var=value file ...
awk [options] -f programfile var=value file ...
awk [options] 'BEGIN{ action;...} pattern{ action;...} END{ action;... }' file ... awk [options] 'program' FILE1 FILE2 ...
program : PATTERN {ACTION STATEMENT}
program : 编程语言,通常是被单引号或双引号引中
PATTERN : 模式,决定动作语句何时触发及触发事件 (BEGIN,END)
ACTION STATEMENT :动作语句,可以是由多个语句组成,各语句之间使用分号分割,,放在{}内指明 (print, printf)
options :
-F :指明输入字段的分隔符,默认为空白字符
-v var=value : 自定义变量
分隔符,域和记录:
awk执行时,由分隔符分割的字段(域)标记 $1,$2,...$n 称为域标识。$0表示所有域,注意,和shell变量中的$符号含义不同
文件的每一行称为记录
省略action,则默认执行 print $0 的操作
awk工作原理
第一步 : 执行BEGIN{ACTION;...}语句块中的语句
第二步 : 从文件或标准输入(stdin)读取一行,然后执行 pattern{action;...}语句块,它逐行扫描文件,从第一行到最后一行重复这个过程,直到文件全部被读取完毕
第三步 : 当读取至输入流末尾时,执行END{ACTION;...}语句块
BEGIN 语句块在awk开始从输入流中读取之前被执行,这是一个可选的语句块,比如变量初始化,打印输出表格的表头等语句通常可以写在BEGIN语句块中
END 语句块在awk从输入流中读取完所有的行之后即被执行,比如打印所有行的分析结果这类信息汇总都是在END语句块中完成,它也是一个可选语句块
pattren 语句块中的通用命令是最重要的部分,也是可选的。如果没有提供pattern语句块,则默认执行{print},既打印每一个读取到的行,awk读取的每一行都会执行该语句块
awk命令
1, print
用法: print item1,item2,...
item : 字符串,用引号引用
变量 : 显示变量的值,可以直接使用变量的名进行引用
数值 : 无须加引号
要点:
(1) : 逗号分隔符
(2) : 输出的各item可以是字符串,也可以是数值,当前记录的字段,变量或awk的表达式
(3) : print后面的item省略时,相当于运行 print $0 ,用于输出整行
示例:
awk '{print "hello awk"}' /etc/fstab
awk -F: '{print $1,$3}' /etc/passwd
awk -F: '{print $1"\t"$3}' /etc/passwd
2, 变量
变量分为内建变量和自定义变量
2.1 内建变量
FS : 输入字段分隔符,默认为空白字符
awk -v FS=":" '{print $1,$3}' /etc/passwd
awk -F: '{print $1,$3}' /etc/passwd
OFS : 输出字段分隔符,默认为空白字符
awk -v FS=":" -v OFS="---" '{print $1,$3}' /etc/passwd
RS : 输入记录分隔符,指定输入时的换行符,原换行符仍有效
awk -v RS=':' '{print}' /etc/passwd
ORS : 输出记录分隔符,输出时用指定符号代替换行符
awk -v ORS='####' '{print}' /etc/passwd
NF : 字段的数量
awk -F: '{print NF}' /etc/passwd
awk -F: '{print $(NF-1)}' /etc/passwd
NR : 行号
awk '{print NR}' /etc/fstab
awk 'END{print NR}' /etc/fstabFNR : 分别统计各文件的行号
awk '{print FNR}' /etc/fstab /etc/passwdFILENAME : 当前文件名
awk 'END{print FILENAME}' /etc/fstab
ARGC : 命令行参数的个数,awk也算一个参数
awk '{print ARGC}' /etc/fstab /etc/passwd ARGV : 数组,保存的是命令行所给定的各参数
awk 'BEGIN{print ARGV[0]}' /etc/fstab 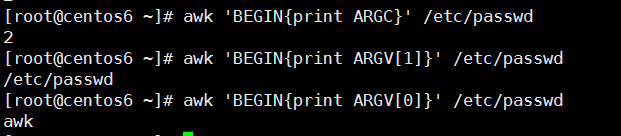
2.2 自定义变量
(1) -v var=vaule 变量名区分字符大小写
(2) 在program中直接定义
示例:
awk -v test='hello awk' 'BEGIN{print test}'
awk 'BEGIN{test="hellp";print test}'
3, printf 命令
格式化输出 : printf "FORMAT", item1.item2,...
(1) 必须指定FORMAT
(2) 不会自动换行,需要显示给出换行控制符,\n
(3) FORMAT 中需要分别为后面每个item指定格式符
格式符: 与 item 一一对应
%c : 显示字符的ascii码
%d,%i : 显示十进制整数
%e,%E : 科学计数法数值显示
%f : 显示为浮点数
%g,%G : 以科学计数法或浮点形式显示数值
%s : 显示字符串
%u : 无符号整形
%% : 显示%自身修饰符:
#[.#] : 第一个数字控制显示的宽度,第二个#表示小数点后的精度 %3.1f
- : 左对齐 (默认右对齐) %-15s
+ : 显示数值的符号 %+d
示例:
awk -F: '{printf "%-15s%d\n",$1,$3}' /etc/passwd
awk -F: '{printf "ername: %s,UID:%d\n",$1,$3}' /etc/passwd
4,awk的操作符
操作符:
算术操作符:
+;-;*;/;^;%
-x :转换正负
+x :把字符串转换为数值字符串操作符:没有符号的操作符表示字符串连接
赋值操作符:
=,+=,-=,*=,/=,%=,^=,--,++比较操作符:
>,>=,<=,!=,==模式匹配符:
~ : 是否匹配
!~ : 不能够匹配
# awk –F: '$0 ~ /root/{print $1}' /etc/passwd
# awk '$0 !~ /root/' /etc/passwd逻辑操作符:
&&;||;!示例:
awk -F: '$3>=500{print $1,$3}' /etc/passwd

awk -F: '$3==0 || $3>=1000 {print $1}' /etc/passwd
awk -F: '!($3==0) {print $1}' /etc/passwd
awk -F: '!($3>=500) {print $3}}' /etc/passwd 函数调用: function_name(arg1,arg2,...)
条件表达式(三目表达式)
selector?if-true-expression:if-false-expression示例:
tail -4 /etc/passwd|awk -F: '{$3>=500?usertype="common users":usertype="system users";printf "%-15s%s\n",$1,usertype}'
5,PATTERN 模式
pattern : 根据pattern条件,过滤匹配的行,在做处理
(1) 如果未指定,空模式,匹配文本的每一行
(2) [!]/regular expression/ : 仅处理能够模式匹配到的行,需要用 / /括起来
awk '/^UUID/{print $1}' /etc/fstab
awk '!/^UUID/{print $1}' /etc/fstab(3) relational expression : 关系表达式,结果有'真'有'假',结果为真时才会被处理
真 : 结果为非0值,非空字符串
假 : 结果为空字符串或0值
示例:
awk '!0' /etc/passwd ; awk '!1' /etc/passwd
awk –F: '$3>=1000{print $1,$3}' /etc/passwd
awk -F: '$3<1000{print $1,$3}' /etc/passwd
awk -F: '$NF=="/bin/bash"{print $1,$NF}' /etc/passwd
awk -F: '$NF~/bash$/{print $1,$NF}' /etc/passwd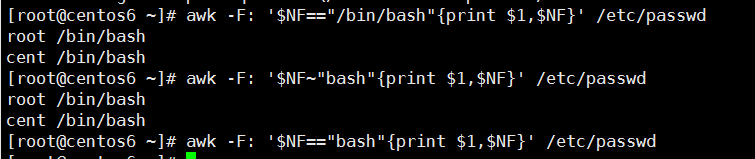
(4) line ranges : 行范围
startline,endline : /part1/,/part2/ 不支持直接给出数字格式:
awk -F: '/^root/,/^nobody/{print}' /etc/passwd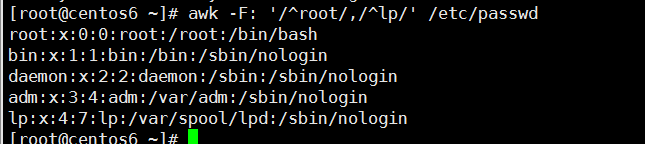
awk -F: 'NR>10&&NR<=15{print}' /etc/passwd
(5) BEGIN/END 模式
BEGIN{} : 仅在开始处理文件中的文本之前执行一次
END{} : 仅在文本处理完成之后执行一次示例:
awk -F: 'BEGIN {print "USER USERID"} {print $1":"$3} END{print "end file"}' /etc/passwd
awk -F: '{print "USER USERID“;print $1":"$3} END{print "end file"}' /etc/passwd
awk -F: 'BEGIN{print " USER UID \n --------------"}{print $1,$3}' /etc/passwd
seq 10 |awk 'i=0'
seq 10 |awk 'i=1'
seq 10 | awk 'i=!i'
seq 10 | awk '{i=!i;print i}'
seq 10 | awk '!(i=!i)'
seq 10 |awk -v i=1 'i=!i'


6,常用action
(1) Expression :算术,比较表达式等
(2) Control statements : if,while等
(3) Compound statements : 组合语句
(4) input statements
(5) output statements : print等
7,控制语句
if(condition){statements;...}
if(condition){statements;...}else{statements;...}
while(condition) {statements;...}
do{statements;...} while(condition)
for(expr1;expr2;expr3){statements;...}
break
continue
delete array[index]
delete array
exit
{statements;...} 组合语句7.1 if-else:
语法:
if(condition)statement [else statement]
if(condition1){statement1}else if(condition2){statement2} else{statement3} awk -F: '{if($3>=500)print $1,$3}' /etc/passwd
awk -F: '{if($3>=300) {printf "ok:%s\n",$1} else printf "no:%s\n",$1}' /etc/passwd
df -h | awk -F'%' '/^\/dev/{print $1}'|awk '{if($NF>4)print $1}'使用场景:对awk取得的整行或某个字段做条件判断

awk -F: '{if($3>=1000)print $1,$3}' /etc/passwd
awk -F: '{if($NF=="/bin/bash") print $1}' /etc/passwd
awk '{if(NF>5) print $0}' /etc/fstab
df -h|awk -F% '/^\/dev/{print $1}'|awk '$NF>=80{print $1,$5}'7.2 while 循环:
语法: while(condition)statement
条件为真,进入循环,条件为假,退出循环
使用场景:对一行内多个字段逐一类似处理时使用:对数组中的各元素逐一处理时使用
length() 字段长度
awk '/^[[:space:]]*linux/{i=1;while(i<=NF){print $i,length($i);i++}}' /etc/grub2.cfg #centos 7
awk '/^[[:space:]]*linux/{i=1;while(i<=NF){if(length($i)>10)print $i,length($i);i++}}' /etc/grub2.cfg #centos 77.3 do-while 循环:
语法: do {statement;...} while(condition)
意义:无论真假,至少执行一次循环体
示例:
[root@centos6 ~]# awk 'BEGIN{sum=0;i=0;do{sum+=i;i++}while(i<=100)print sum}'
5050
7.4 for 循环:
语法: for(expr1;expr2;expr3) {statement;...}
awk '/^[[:space:]]*linux/{for(i=1;i<=NF;i++){print $i,length($i)}}' /etc/grub2.cfg特殊用法:
可以遍历数组中的每一个元素
语法: for(var in array){condition}
性能比较(awk 和 shell 中for循环所需的时间)
time (sum=0;for i in {1..10000};do let sum+=i;done;echo $sum)
time (awk 'BEGIN{sum=0;i=0;do{sum+=i;i++}while(i<=10000)print sum}')
time (sum=0;for((i=0;i<=10000;i++));do let sum+=i;done;echo $sum)
7.5 switch语句
语法: switch(expression){case VALUE or /REGEXP/:statement;...;default:statement}
7.6 break和continue


7.7 next
提前结束对本行的处理而直接进入下一行
awk -F: '{if($3%2!=0) next;print $1,$3}' /etc/passwd8,数组
关联数组: array[index-expression]
index-expression :
(1) : 可使用任意字符串,字符串要使用双引号括起来
(2) : 如果某数组元素事先不存在,在引用时,awk会自动创建此元素,并将其值初始化为"空串"
若要判断数组中是否存在某元素,要使用"index in array"格式进行遍历
awk 'BEGIN{weekdays["mon"]="Monday"; weekdays["tue"]="Tuesday";print weekdays["mon"]}'
awk '!a[$0]++' dupfile
若要遍历数组中的每个元素,要使用for循环
for(var in array){for-body}
注意: var 会遍历array的每个索引
awk 'BEGIN{k["a"]="aaa";k["b"]="bbb";for(i in k)print k[i]}'
netstat -tan | awk 'NR>2{k[$NF]++;}END{for(i in k)print k[i],i}'
9,函数
数值处理:
rand();返回0和1之间一个随机数,这个产生的随机数是不变的

如果要产生随机数,需要srand() 函数
awk 'BEGIN{srand() ;print int(rand()*1000000)}' #有点问题

字符串处理:
length([s]) : 返回指定字符串的长度
sub(r,s,[t]) : 对t字符串进行搜索r表示的模式匹配的内容,并将第一次匹配的内容替换为s
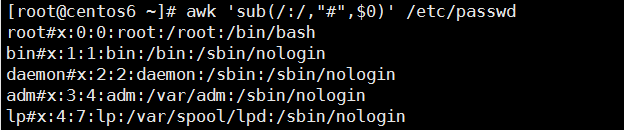
gsub(r,s,[t]) : 对t字符串进行搜索r表示的模式匹配的内容,并将匹配的所有内容都替换为s

split(s,array,[r]) : 以r为分隔符,切割字符s,并将切割后的结果保存到array所表示的数组中,第一个索引值为1,不是0;第二个索引值为2;...
netstat -ant | awk '/^tcp\>/{split($5,ip,":");count[ip[1]]++ }END{for(i in count){print i,count[i]}}'
自定义函数:
函数:
function name (parameter,parameter,...){
statements
return expression
}示例:
#cat fun.awk
function max(a,b){
a>b?var=a:var=b
return var
}
BEGIN{a=3;b=2;print max(a,b)}awk -f fun.awk

awk中调用shell命令
system 命令
空格是 awk 中的字符串连接符,如果 system 中需要使用 awk 中的变量可以使用空格分隔,或者说除了awk的变量外其他一律用""引起来

awk脚本
将awk程序写成脚本,直接调用或执行
比如:


向awk脚本参数
格式: awkfile var=value var2=value2 ... InputFile
示例:

练习
1、统计/etc/fstab文件中每个文件系统类型出现的次数

2、统计/etc/fstab文件中每个单词出现的次数

3,求每班总成绩和平均成绩,成绩表格式如下
name class score
wang 1 100
zhang 2 90
li 1 80
awk 'BEGIN{print "班级 总成绩 平均成绩"}{if($2==1){sum1+=$3;count1++}else if($2==2) {sum2+=$3;count2++}}END{printf " 1 %7d %3.2f\n",sum1 ,sum1/count1;printf " 2 %7d %3.2f\n",sum2 ,sum2/count2}' test