python内建函数的概念_Python中的内建函数
Python中的内建函数
HIKAI
24 AUG 2017
0 Comments
zip()
zip()函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表。如果各个迭代器的元素个数不一致,则返回列表长度与最短的对象相同。利用*号操作符,可以将元祖解压为列表。
zip语法: zip(iterable1,iterable2,...) 返回值:返回元组列表。
a = [1,2,3]
b = [4,5,6]
c = [4,5,6,7,8]
zipped = zip(a,b) #打包为元组的列表
print zipped
print zip(a,c)
print zip(a,b,c)
print zip(*zipped) #与zip相反,可理解为解压,返回二维矩阵
[(1, 4), (2, 5), (3, 6)]
[(1, 4), (2, 5), (3, 6)]
[(1, 4, 4), (2, 5, 5), (3, 6, 6)]
[(1, 2, 3), (4, 5, 6)]
In [31]: zip([[1,2,3]])
Out[31]: [([1, 2, 3],)]
In [32]: zip([[1,2,3],[4,5,6]])
Out[32]: [([1, 2, 3],), ([4, 5, 6],)]
In [33]: l = [[1,2,3],[4,5,6],[7,8,9]]
In [34]: len(l)
Out[34]: 3
In [35]: zip(l)
Out[35]: [([1, 2, 3],), ([4, 5, 6],), ([7, 8, 9],)]
In [36]: len(zip(l))
Out[36]: 3
In [37]: zip(*l)
Out[37]: [(1, 4, 7), (2, 5, 8), (3, 6, 9)]
In [38]: len(zip(*l))
Out[38]: 3
map()
格式:map(func, seq1[, seq2 ...])
Python函数是编程中的map()函数接收两个参数,一个是函数,一个是序列,将func作用于seq中的每一个元素,并用一个列表给出返回值。如果func为None,作用同zip()。
当只有一个seq时,将func函数作用于这个seq的每个元素上,得到一个新的seq。下图说明了只有一个seq的时候,map()函数是如何工作的。

可以看出,seq中的每个元素都经过了func函数的作用,得到了func(seq[n])组成的列表。
下面举一个例子进行说明。假设我们想要得到一个列表中数字%3的余数,那么可以写成下面的代码:
print map(lambda x: x%3, range(6))
[0, 1, 2, 0, 1, 2]
print [x%3 for x in range(6)]
[0, 1, 2, 0, 1, 2]
这里使用了列表解析的方法代替map执行。那么,什么时候是列表解析无法代替map的呢?
当seq多于一个时,map可以并行地对么每个seq执行如下图所示的过程:
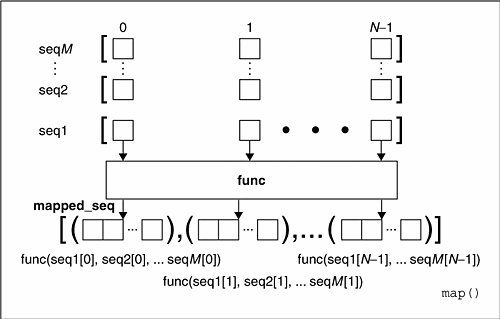
也就是说,每个seq的同一位置的元素在执行过一个多元的func函数之后,得到一个返回值,这些返回值放在一个结果列表中。
下面的例子是求两个列表对应元素的乘积,可以想象,这是一种可能会经常出现的状况。如果不用map的话,就要使用一个for循环,依次对每个位置执行函数。
print map(lambda x,y:(x*y),[1,2,3],[4,5,6])
[4, 10, 18]
上面是返回值是一个值的情况,实际上也可以是一个元组。
下面的代码不止实现了乘法,也实现了加法,并把乘积与和放在一个元组中。
print map(lambda x,y:(x*y,x+y),[1,2,3],[4,5,6])
[(4, 5), (10, 7), (18, 9)]
还有就是上面说的func是None的情况,它的目的是将多个列表相同位置的元素归并到一个元组。现在已经有了专用的函数zip()了。
print map( None, [1, 2, 3], [4, 5, 6] )
[(1, 4), (2, 5), (3, 6)]
print zip( [1, 2, 3], [4, 5, 6] )
[(1, 4), (2, 5), (3, 6)]
注意:不同长度的多个seq是无法执行map函数的,会出现类型错误。
print map(lambda x,y:(x*y),[1,2,3],[4,5,6,7])
TypeErrorTraceback (most recent call last)
in ()
----> 1 print map(lambda x,y:(x*y),[1,2,3],[4,5,6,7])
in (x, y)
----> 1 print map(lambda x,y:(x*y),[1,2,3],[4,5,6,7])
TypeError: unsupported operand type(s) for *: 'NoneType' and 'int'
更多的例子,比如我们有一个函数f(x)=x2,要把这个函数作用在一个list[1,2,3,4,5,6,7,8,9]上,就可以用map()实现如下:

现在,我们用Python代码实现:
>>> def f(x):
... return x * x
...
>>> map(f, [1, 2, 3, 4, 5, 6, 7, 8, 9])
[1, 4, 9, 16, 25, 36, 49, 64, 81]
map()传入的第一个参数是f,即函数对象本身。
reduce()
格式:reduce(func,seq,[,init])
reduce函数即为化简,第二个参数可以是任何可迭代的对象(实现了__iter__()方法的对象),它是这样一个过程:每次迭代,将上一次的迭代结果(第一次时为init的元素,如没有init则为seq的第一个元素)与下一个元素一同执行一个二元的func函数。在reduce函数中,init是可选的,如果使用,则作为第一次迭代的第一个元素使用。
简单来说,可以用这样一个形象化的例子来说明:
reduce(func,[1,2,3])=func(func(1,2),3)
下面是reduce函数的工作过程图:

举个例子来说,阶乘是一个常见的数学方法,Python中并没有给出一个阶乘的内建函数,我们可以使用reduce实现一个阶乘的代码。
n = 5
print reduce(lambda x, y: x * y, range(1, n + 1))
120
那么,如果我们希望得到2倍阶乘的值呢?这就可以用到init这个可选参数了。
m = 2
n = 5
print reduce( lambda x, y: x * y, range( 1, n + 1 ), m )
240
如果不指定第三个参数init,则第一次调用function将使用iterable的前两个元素作为参数。
reduce把一个函数作用在一个序列[x1,x2,x3...]上,这个函数必须接收两个参数,reduce把结果继续和序列的下一个元素做运算,其效果就是:
reduce(f, [x1, x2, x3, x4]) = f(f(f(x1, x2), x3), x4)
比方说对一个序列求和,就可以用reduce实现:
>>> def add(x, y):
return x + y
>>> reduce(add, [1, 3, 5, 7, 9])
25
当然求和运算可以直接用Python内建函数sum(),没必要动用reduce。
filter()
Python内建的filter()函数用于过滤序列,接收一个函数和一个序列,把传入的函数依次作用于每个元素,然后根据返回值是True还是False,决定保留还是丢弃该元素,返回True的元素放到新列表中,返回由符合条件的元素组成的新列表。
语法:filter(function,iterable)
例如,在一个list中,删掉偶数,只保留奇数,可以这么写:
def is_odd(n):
return n % 2 == 1
filter(is_odd, [1,2,4,5,6,9,10,15])
#结果:[1,5,9,15]
把一个序列中的空字符串删掉,可以这么写:
def not_empty(s):
return s and s.strip()
filer(not_empty, ['A', '', 'B', None, 'C', ' '])
# 结果: ['A', 'B', 'C']
sorted()
排序也是在程序中经常用到的算法,无论使用冒泡排序还是快速排序,排序的核心是比较两个元素的大小。如果是数字,我们可以直接比较,但如果是字符串或者两个dict呢?直接比较数学上的大小是没有意义的,因此,比较的过程必须通过函数抽象出来。通常规定,对于两个元素x和y,如果xy,则返回1。这样,排序算法就不用关心具体的比较过程,而是根据比较结果直接排序。
Python内置的sorted()函数就可以对list进行排序,调用形式:sorted(data, key=None, cmp=None, reverse=False)。
data是待排序数据,可以是list或者iterator等可迭代类型。key和cmp都是函数,这两个函数作用于data的元素上产生一个结果,sorted方法根据这个结果来排序。
key是一个带参数的函数,这个函数只接受一个元素,用来为每个元素提取比较值。默认为None,即直接比较每个元素。
cmp(e1,e2)是带两个参数的比较函数,返回值:若e1 e2,则为整数。默认为 None,即用内建的比较函数。
通常,key和reverse比cmp快很多,因为对每个元素它们只处理一次,而 cmp 会处理多次。
一般来说,cmp和key可以使用lambda表达式。
sorted说明如下,
help(sorted)
Help on built-in function sorted in module builtin:
sorted(…)
sorted(iterable, cmp=None, key=None, reverse=False) –> new sorted list
>>> sorted([36, 5, 12, 9, 21])
[5, 9, 12, 21, 36]
此外,sorted()函数可以接收一个比较函数来实现自定义的排序。比如,如果要倒序排序,我们就可以自定义一个reversed_cmp函数:
def reversed_cmp(x, y):
if x > y:
return -1
if x < y:
return 1
return 0
传入自定义的比较函数reversed_cmp,就可以实现倒序排序:
>>> sorted([36, 5, 12, 9, 21], reversed_cmp)
[36, 21, 12, 9, 5]
我们再看一个字符串排序的例子:
>>> sorted(['bob', 'about', 'Zoo', 'Credit'])
['Credit', 'Zoo', 'about', 'bob']
默认情况下,对字符串排序,是按照ASCII的大小比较的,由于'Z' < 'a',结果,大写字母Z会排在小写字母a的前面。
sort()
sort说明如下,
help(list.sort)
Help on method_descriptor:
sort(…)
L.sort(cmp=None, key=None, reverse=False) – stable sort IN PLACE;
cmp(x, y) -> -1, 0, 1
sort()与sorted()的不同在于,sort是在原位重新排列列表,而sorted()是产生一个新的列表。
apply()
函数格式为:apply(func,*args,**kwargs)
当一个函数的参数存在于一个元组或者一个字典中时,用来间接的调用这个函数,并将元组或字典中的参数按照顺序传递给函数。
args是一个包含按照函数func所需参数传递的位置参数的一个元组。如果省略了args,任何参数都不会被传递。
kwargs是一个包含关键字参数的字典,而其中args如果不传递,kwargs需要传递,则必须在args的位置留空。
apply的返回值就是func()的返回值。
>>> def function(a,b):
print a,b
>>> apply(function,('good','morning'))
good morning
>>> function(b='morning',a='good')
good morning
>>> apply(function,(b='morning',a='good'))
SyntaxError: invalid syntax
>>> apply(function,{'a':'caiquan','b':'Tom'})
Traceback (most recent call last):
File "", line 1, in
apply(function,{'a':'caiquan','b':'Tom'})
TypeError: apply() arg 2 expected sequence, found dict
>>> apply(function,,{'a':'caiquan','b':'Tom'})
SyntaxError: invalid syntax
>>> apply(function,(),{'a':'caiquan','b':'Tom'})
caiquan Tom
参考