创建音乐下载器-代码实现
VIP音乐下载,播放
在我们听歌的时候,总是被各种会员的限制,导致无法听到完整的音乐。当然有的人单单喜欢通过软件去听歌,这里面有很多优质评论可以看。但是当我们想下载一首歌的时候,不是会员就没有办法实现了。在这里给大家介绍一下如何通过python来实现软件vip音乐的下载。。
一、分析网址
(1)搜索音乐网址分析
如下,我们以检索“周深”为例:通过Fetch/XHR找到网址为http://www.xxxx.cn/api/www/search/searchMusicBykeyWord?key=%E5%91%A8%E6%B7%B1&pn=1&rn=20&httpsStatus=1&reqId=8d9c7880-b12d-11ed-ae17-a1e6fcda1289,这里key后面写的就是搜索的名称,pn代表页数,rn代表每页显示的音乐条数。后面的可以不考虑,最后分析搜索的网址为http://www.xxxx.cn/api/www/search/searchMusicBykeyWord?key={}&pn={}&rn=20

(2)音乐的源址
点击播放一首歌曲,然后点击network->media,可以查看播放歌曲的源码,如下:
源码地址为:https://ls-sycdn.xxxx.cn/44e4a52eb5fc53900864a5d0620fa57c/63f38b19/resource/n3/32/21/2372595038.mp3。
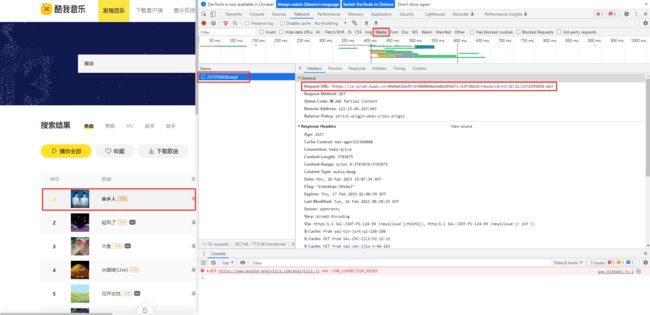
记住这个源码的格式,Ctrl+F去寻找这个源码,发现在PlayUrl这个地址中包含了这个源码从而确定信息交互时采用的地址。

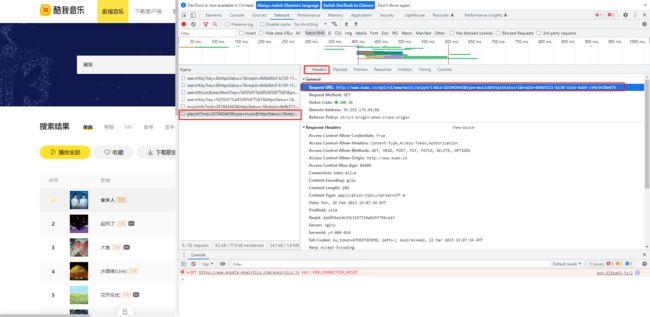
这个地址为:http://www.xxxx.cn/api/v1/www/music/playUrl?mid=261942443&type=music&httpsStatus=1&reqId=4b9b5111-b130-11ed-8a64-c94e3438e075。通过分析这个地址,我们可以得出这个网址中的关键字段mid,如果获取到它,他们所有音乐的源码地址我们都将可以获取到,从而实现VIP音乐的下载。
二、代码分析
(1)伪造用户登录界面
很多网站都是带有反爬机制,当你使用自动化一直访问一个网址,那么他就会检测出来,并做出相应处理,因此我们通过带用户表示去访问一个网址。
首先分析头headers,通过上述我们搜索界面进行分析。
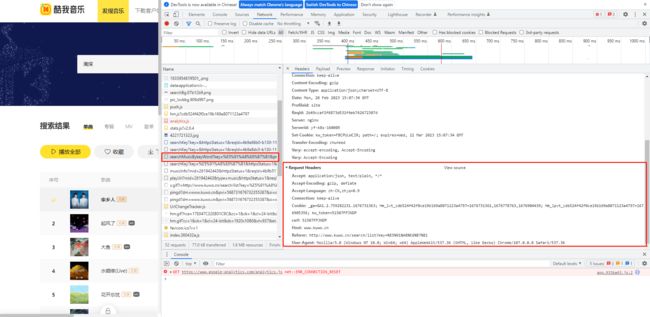
因此在这里构建一个请求头:
User-Agent:表示浏览器的版本信息。当服务器收到浏览器的这个请求后,会经过一系列处理,返回一个数据包给浏览器,而响应头里就会描述这个数据包的基本信息。
Host:请求的主机地址
Referer:表示当前页面是通过此来源页面里的链接进入的。
Cookie:很多和用户相关的信息都存在 Cookie 里,用户在向服务器发送请求数据时会带上。
csrf':跨站点请求伪造信息
header = {'User-Agent': 'Chrome/107.0.0.0 Safari/537.36',
'Host': 'www.xxxx.cn',
'Referer': 'http://www.xxxx.cn/search/list?key=%E5%91%A8%E6%9D%B0%E4%BC%A6',
'Cookie': '_ga=GA1.2.759282231.1676731363; _gid=GA1.2.81167573.1676731363; Hm_lvt_cdb524f42f0ce19b169a8071123a4797=1676731361,1676778763; Hm_lpvt_cdb524f42f0ce19b169a8071123a4797=1676786566; kw_token=Q3XXTYYVGYK',
'csrf': 'Q3XXTYYVGYK'
}
(2)返回检索音乐信息
综上分析的检索音乐网址,构造代码如下:
import requests
import re
import urllib
# 1.伪装浏览器构造
# User-Agent:
header = {'User-Agent': 'Chrome/107.0.0.0 Safari/537.36',
'Host': 'www.xxxx.cn',
'Referer': 'http://www.xxxx.cn/search/list?key=%E5%91%A8%E6%9D%B0%E4%BC%A6',
'Cookie': '_ga=GA1.2.759282231.1676731363; _gid=GA1.2.81167573.1676731363; Hm_lvt_cdb524f42f0ce19b169a8071123a4797=1676731361,1676778763; Hm_lpvt_cdb524f42f0ce19b169a8071123a4797=1676786566; kw_token=Q3XXTYYVGYK',
'csrf': 'Q3XXTYYVGYK'
}
key = '邓紫棋'
page = 1
# 1.向接口发送请求,从获取json数据中获取音乐id(rid)/歌曲名字/歌手 key:搜索歌手名字、page:爬取的第几页
url = 'http://www.xxxx.cn/api/www/search/searchMusicBykeyWord?key={}&pn={}&rn=1'.format(str(key), str(page))
# 将请求的数据转为json格式,方便我们通过字典的形式提取数据。
music_data = requests.get(url, headers=header).json()
print(music_data)
执行结果为,里面包含了检索到的歌曲信息:
D:\WorkPlace\venv\Scripts\python.exe D:\WorkPlace\Music\kuwo_test.py
{'code': 200, 'curTime': 1676907553761, 'data': {'total': '305', 'list': [{'musicrid': 'MUSIC_39515638', 'barrage': '0', 'artist': 'G.E.M.邓紫棋', 'mvpayinfo': {'play': '0', 'vid': '7593309', 'download': '0'}, 'pic': 'https://img4.kuwo.cn/star/albumcover/120/36/57/1029628864.jpg', 'isstar': 0, 'rid': 39515638, 'duration': 219, 'score100': '95', 'content_type': '0', 'track': 0, 'hasLossless': False, 'hasmv': 1, 'album': '上古情歌 电视剧原声带', 'albumid': '3668654', 'pay': '16515324', 'artistid': 5371, 'albumpic': 'https://img4.kuwo.cn/star/albumcover/120/36/57/1029628864.jpg', 'originalsongtype': 1, 'songTimeMinutes': '03:39', 'isListenFee': False, 'pic120': 'https://img4.kuwo.cn/star/albumcover/120/36/57/1029628864.jpg', 'name': '桃花诺-《上古情歌》电视剧片尾曲', 'online': 1, 'payInfo': {'nplay': '001111', 'play': '1100', 'overseas_nplay': '001111', 'local_encrypt': '1', 'limitfree': '0', 'refrain_start': '73975', 'feeType': {'song': '1', 'album': '0', 'vip': '1', 'bookvip': '0'}, 'ndown': '111111', 'download': '1111', 'cannotDownload': '0', 'overseas_ndown': '111111', 'cannotOnlinePlay': '0', 'listen_fragment': '0', 'refrain_end': '101975', 'tips_intercept': '0'}}]}, 'msg': 'success', 'profileId': 'site', 'reqId': '6452deca1f87b5dc8689d526d9af39e5', 'tId': ''}
Process finished with exit code 0
(3)提取mid,歌曲名称,歌手名称
我们的主要是提取mid值也就是上面获取的vid值,同时获取歌曲名称以及歌手来协助我们进行音乐的存储。代码如下,歌曲遍历:
for id in music_data['data']['list']:
rid = id['rid']
singer = id['artist']
song_name = id['name']
print(rid, singer, song_name)
执行结果为:
D:\WorkPlace\venv\Scripts\python.exe D:\WorkPlace\Music\xxxx_test.py
39515638 G.E.M.邓紫棋 桃花诺-《上古情歌》电视剧片尾曲
Process finished with exit code 0
(4)根据获取到的mid值,套入分析过的地址中获取音乐源码网址
base_url = 'https://www.xxxx.cn/api/v1/www/music/playUrl?mid={}&type=convert_url'.format(str(rid))
response = requests.get(base_url, headers=header).json()
print(response)
此时执行结果为,包括歌曲源码地址https://nn01-sycdn.xxxx.cn/dc9b8e825e5c8f1896cf005de164492d/63f3961f/resource/n3/22/32/2480823959.mp3,这样我们就可以进行下一步音乐下载了:
D:\WorkPlace\venv\Scripts\python.exe D:\WorkPlace\Music\xxxx_test.py
{'code': 200, 'msg': 'success', 'reqId': '1fe4ff0c0c6e3aa8ba0a2766d0de77a6', 'tId': '', 'data': {'url': 'https://nn01-sycdn.xxxx.cn/dc9b8e825e5c8f1896cf005de164492d/63f3961f/resource/n3/22/32/2480823959.mp3'}, 'profileId': 'site', 'curTime': 1676908063429, 'success': True}
Process finished with exit code 0
(5)在下载之前,我们首先对获取到的歌手名称及歌曲名称格式进行一个处理,以免保存失败。
#提取源码
song_url = response['data']['url']
# 对音乐播放地址再次发送请求获取二进制内容数据
song_content = requests.get(song_url).content
# 将歌名或者作者名当中的奇怪符号去掉,防止保存
singer1 = re.sub('[\\/:?*<>"|]', '', singer)
song_name1 = re.sub('[\\/:?*<>"|]', '', song_name)
(6)处理后,编写下载语句urllib
urllib.request.urlretrieve:URL 中的网络资源拷贝到本地(网址,拷贝到本地地址)
try:
print('正在下载', song_name)
urllib.request.urlretrieve(song_url, './网易歌单/%s.mp3' % song_name)
print('下载成功....')
except:
pass
三、完整代码
代码
import requests
import re
import urllib
# 1.伪装浏览器构造
# User-Agent:
header = {'User-Agent': 'Chrome/107.0.0.0 Safari/537.36',
'Host': 'www.xxxx.cn',
'Referer': 'http://www.xxxx.cn/search/list?key=%E5%91%A8%E6%9D%B0%E4%BC%A6',
'Cookie': '_ga=GA1.2.759282231.1676731363; _gid=GA1.2.81167573.1676731363; Hm_lvt_cdb524f42f0ce19b169a8071123a4797=1676731361,1676778763; Hm_lpvt_cdb524f42f0ce19b169a8071123a4797=1676786566; kw_token=Q3XXTYYVGYK',
'csrf': 'Q3XXTYYVGYK'
}
key = '邓紫棋'
page = 1
# 1.向接口发送请求,从获取json数据中获取音乐id(rid)/歌曲名字/歌手 key:搜索歌手名字、page:爬取的第几页
url = 'http://www.xxxx.cn/api/www/search/searchMusicBykeyWord?key={}&pn={}&rn=5'.format(str(key), str(page))
# 将请求的数据转为json格式
music_data = requests.get(url, headers=header).json()
for id in music_data['data']['list']:
rid = id['rid']
singer = id['artist']
song_name = id['name']
# 根据音乐id拼接音乐地址,发送请求返回json并获取音乐播放地址
base_url = 'https://www.xxxx.cn/api/v1/www/music/playUrl?mid={}&type=convert_url'.format(str(rid))
response = requests.get(base_url, headers=header).json()
song_url = response['data']['url']
# 对音乐播放地址再次发送请求获取二进制内容数据
song_content = requests.get(song_url).content
# 将歌名或者作者名当中的奇怪符号去掉,防止保存
singer1 = re.sub('[\\/:?*<>"|]', '', singer)
song_name1 = re.sub('[\\/:?*<>"|]', '', song_name)
try:
print('正在下载', song_name)
urllib.request.urlretrieve(song_url, './歌单/%s.mp3' % song_name)
print('下载成功....')
except:
pass
执行测试
测试结果:
D:\WorkPlace\venv\Scripts\python.exe D:\WorkPlace\Music\xxxx_test.py
正在下载 桃花诺-《上古情歌》电视剧片尾曲
下载成功....
正在下载 倒数-好好的爱你
下载成功....
正在下载 多远都要在一起
下载成功....
正在下载 喜欢你
下载成功....
正在下载 泡沫
下载成功....
Process finished with exit code 0

可以点击播放。
总结
之前一直在搞网易云歌曲,但是网易云反爬设置很强,导致一直不能实现VIP歌曲的下载,我在这里可以把普通歌曲下载的方式放在这里,如果有小伙伴搞定也分享一下给我。谢谢!下一节,我们创建一个下载音乐的小工具,做到真正的学以致用。