【极客时间】《Java并发编程实战》学习笔记
目录:

开篇词 | 你为什么需要学习并发编程?
内容来源:开篇词 | 你为什么需要学习并发编程?-极客时间
例如,Java 里 synchronized、wait()/notify() 相关的知识很琐碎,看懂难,会用更难。但实际上 synchronized、wait()、notify() 不过是操作系统领域里管程模型的一种实现而已,Java SDK 并发包里的条件变量 Condition 也是管程里的概念,synchronized、wait()/notify()、条件变量这些知识如果单独理解,自然是管中窥豹。但是如果站在管程这个理论模型的高度,你就会发现这些知识原来这么简单,同时用起来也就得心应手了。
管程作为一种解决并发问题的模型,是继信号量模型之后的一项重大创新,它与信号量在逻辑上是等价的(可以用管程实现信号量,也可以用信号量实现管程),但是相比之下,管程更易用。而且,很多编程语言都支持管程,搞懂管程,对学习其他很多语言的并发编程有很大帮助。然而,很多人急于学习 Java 并发编程技术,却忽略了技术背后的理论和模型,而理论和模型却往往比具体的技术更为重要。
其实并发编程可以总结为三个核心问题:分工、同步、互斥。
所谓分工指的是如何高效地拆解任务并分配给线程,而同步指的是线程之间如何协作,互斥则是保证同一时刻只允许一个线程访问共享资源。Java SDK 并发包很大部分内容都是按照这三个维度组织的,例如 Fork/Join 框架就是一种分工模式,CountDownLatch 就是一种典型的同步方式,而可重入锁则是一种互斥手段。
而且,这三个核心问题是跨语言的,你如果要学习其他语言的并发编程类库,完全可以顺着这三个问题按图索骥。Java SDK 并发包其余的一部分则是并发容器和原子类,这些比较容易理解,属于辅助工具,其他语言里基本都能找到对应的。
并发编程并不是 Java 特有的语言特性,它是一个通用且早已成熟的领域。Java 只是根据自身情况做了实现罢了,当你理解或学习并发编程的时候,如果能够站在较高层面,系统且有体系地思考问题,那就会容易很多。
操作系统相关书籍:
如果学原理的话,可以参考:
-
计算机的心智-操作系统之哲学原理
-
操作系统精髓与设计原理 《操作系统原理》 William Stallings(威廉.斯托林斯)
如果想深入学,可以看:
-
unix操作系统设计
还可以看看linux 0.11的源代码:
-
《Java并发编程实战》作者阵容可谓大师云集,也包括Doug Lea
-
《Java并发编程的艺术》讲解并发包内部实现原理,能读明白,内功大增
-
《图解Java多线程设计模式》并发编程设计模式方面的经典书籍
-
《操作系统:精髓与设计原理》经典操作系统教材
-
并发编程网 – ifeve.com | 让天下没有难学的技术 国内专业并发编程网站
-
The Java Memory Model
学习攻略 | 如何才能学好并发编程?
内容来源:学习攻略 | 如何才能学好并发编程?-极客时间
如何才能学习好并发编程呢?其实很简单,只要你能从两个方面突破一下就可以了。一个是“跳出来,看全景”,另一个是“钻进去,看本质”。
跳出来,看全景
学习最忌讳的就是“盲人摸象”,只看到局部,而没有看到全局。所以,你需要从一个个单一的知识和技术中“跳出来”,高屋建瓴地看并发编程。当然,这首要之事就是你建立起一张全景图。
在我看来,并发编程领域可以抽象成三个核心问题:分工、同步和互斥。
1. 分工
所谓分工,类似于现实中一个组织完成一个项目,项目经理要拆分任务,安排合适的成员去完成。在并发编程领域,你就是项目经理,线程就是项目组成员。任务分解和分工对于项目成败非常关键,不过在并发领域里,分工更重要,它直接决定了并发程序的性能。在现实世界里,分工是很复杂的,著名数学家华罗庚曾用“烧水泡茶”的例子通俗地讲解了统筹方法(一种安排工作进程的数学方法),“烧水泡茶”这么简单的事情都这么多说道,更何况是并发编程里的工程问题呢。
既然分工很重要又很复杂,那一定有前辈努力尝试解决过,并且也一定有成果。的确,在并发编程领域这方面的成果还是很丰硕的。Java SDK 并发包里的 Executor、Fork/Join、Future 本质上都是一种分工方法。除此之外,并发编程领域还总结了一些设计模式,基本上都是和分工方法相关的,例如生产者 - 消费者、Thread-Per-Message、Worker Thread 模式等都是用来指导你如何分工的。
学习这部分内容,最佳的方式就是和现实世界做对比。例如生产者 - 消费者模式,可以类比一下餐馆里的大厨和服务员,大厨就是生产者,负责做菜,做完放到出菜口,而服务员就是消费者,把做好的菜给你端过来。不过,我们经常会发现,出菜口有时候一下子出了好几个菜,服务员是可以把这一批菜同时端给你的。其实这就是生产者 - 消费者模式的一个优点,生产者一个一个地生产数据,而消费者可以批处理,这样就提高了性能。
2. 同步
分好工之后,就是具体执行了。在项目执行过程中,任务之间是有依赖的,一个任务结束后,依赖它的后续任务就可以开工了,后续工作怎么知道可以开工了呢?这个就是靠沟通协作了,这是一项很重要的工作。
在并发编程领域里的同步,主要指的就是线程间的协作,本质上和现实生活中的协作没区别,不过是一个线程执行完了一个任务,如何通知执行后续任务的线程开工而已。协作一般是和分工相关的。Java SDK 并发包里的 Executor、Fork/Join、Future 本质上都是分工方法,但同时也能解决线程协作的问题。例如,用 Future 可以发起一个异步调用,当主线程通过 get() 方法取结果时,主线程就会等待,当异步执行的结果返回时,get() 方法就自动返回了。主线程和异步线程之间的协作,Future 工具类已经帮我们解决了。除此之外,Java SDK 里提供的 CountDownLatch、CyclicBarrier、Phaser、Exchanger 也都是用来解决线程协作问题的。不过还有很多场景,是需要你自己来处理线程之间的协作的。
工作中遇到的线程协作问题,基本上都可以描述为这样的一个问题:当某个条件不满足时,线程需要等待,当某个条件满足时,线程需要被唤醒执行。例如,在生产者 - 消费者模型里,也有类似的描述,“当队列满时,生产者线程等待,当队列不满时,生产者线程需要被唤醒执行;当队列空时,消费者线程等待,当队列不空时,消费者线程需要被唤醒执行。”在 Java 并发编程领域,解决协作问题的核心技术是管程,上面提到的所有线程协作技术底层都是利用管程解决的。管程是一种解决并发问题的通用模型,除了能解决线程协作问题,还能解决下面我们将要介绍的互斥问题。可以这么说,管程是解决并发问题的万能钥匙。
所以说,这部分内容的学习,关键是理解管程模型,学好它就可以解决所有问题。其次是了解 Java SDK 并发包提供的几个线程协作的工具类的应用场景,用好它们可以妥妥地提高你的工作效率。
3. 互斥
分工、同步主要强调的是性能,但并发程序里还有一部分是关于正确性的,用专业术语叫“线程安全”。并发程序里,当多个线程同时访问同一个共享变量的时候,结果是不确定的。不确定,则意味着可能正确,也可能错误,事先是不知道的。而导致不确定的主要源头是可见性问题、有序性问题和原子性问题,为了解决这三个问题,Java 语言引入了内存模型,内存模型提供了一系列的规则,利用这些规则,我们可以避免可见性问题、有序性问题,但是还不足以完全解决线程安全问题。解决线程安全问题的核心方案还是互斥。
所谓互斥,指的是同一时刻,只允许一个线程访问共享变量。
实现互斥的核心技术就是锁,Java 语言里 synchronized、SDK 里的各种 Lock 都能解决互斥问题。虽说锁解决了安全性问题,但同时也带来了性能问题,那如何保证安全性的同时又尽量提高性能呢?可以分场景优化,Java SDK 里提供的 ReadWriteLock、StampedLock 就可以优化读多写少场景下锁的性能。还可以使用无锁的数据结构,例如 Java SDK 里提供的原子类都是基于无锁技术实现的。
除此之外,还有一些其他的方案,原理是不共享变量或者变量只允许读。这方面,Java 提供了 Thread Local 和 final 关键字,还有一种 Copy-on-write 的模式。
使用锁除了要注意性能问题外,还需要注意死锁问题。这部分内容比较复杂,往往还是跨领域的,例如要理解可见性,就需要了解一些 CPU 和缓存的知识;要理解原子性,就需要理解一些操作系统的知识;很多无锁算法的实现往往也需要理解 CPU 缓存。这部分内容的学习,需要博览群书,在大脑里建立起 CPU、内存、I/O 执行的模拟器。这样遇到问题就能得心应手了。
跳出来,看全景,可以让你的知识成体系,所学知识也融汇贯通起来,由点成线,由线及面,画出自己的知识全景图。

钻进去,看本质
但是光跳出来还不够,还需要下一步,就是在某个问题上钻进去,深入理解,找到本质。
就拿我个人来说,我已经烦透了去讲述或被讲述一堆概念和结论,而不分析这些概念和结论是怎么来的,以及它们是用来解决什么问题的。在大学里,这样的教材很流行,直接导致了芸芸学子成绩很高,但解决问题的能力很差。其实,知其然知其所以然,才算真的学明白了。
我属于理论派,我认为工程上的解决方案,一定要有理论做基础。所以在学习并发编程的过程中,我都会探索它背后的理论是什么。比如,当看到 Java SDK 里面的条件变量 Condition 的时候,我会下意识地问,“它是从哪儿来的?是 Java 的特有概念,还是一个通用的编程概念?”当我知道它来自管程的时候,我又会问,“管程被提出的背景和解决的问题是什么?”这样一路探索下来,我发现 Java 语言里的并发技术基本都是有理论基础的,并且这些理论在其他编程语言里也有类似的实现。所以我认为,技术的本质是背后的理论模型。
总结
当初我学习 Java 并发编程的时候,试图上来就看 Java SDK 的并发包,但是很快就放弃了。原因是我觉得东西太多,眼花缭乱的,虽然借助网络上的技术文章,感觉都看懂了,但是很快就又忘了。实际应用的时候大脑也一片空白,根本不知道从哪里下手,有时候好不容易解决了个问题,也不知道这个方案是不是合适的。
我知道根本原因是,我的并发知识还没有成体系。
我想,要让自己的知识成体系,一定要挖掘 Java SDK 并发包背后的设计理念。Java SDK 并发包是并发大师 Doug Lea 设计的,他一定不是随意设计的,一定是深思熟虑的,其背后是 Doug Lea 对并发问题的深刻认识。可惜这个设计的思想目前并没有相关的论文,所以只能自己琢磨了。
分工、同步和互斥的全景图,是我对并发问题的个人总结,不一定正确,但是可以帮助我快速建立解决并发问题的思路,梳理并发编程的知识,加深认识。
对于某个具体的技术,我建议你探索它背后的理论本质,理论的应用面更宽,一项优秀的理论往往在多个语言中都有体现,在多个不同领域都有应用。所以探求理论本质,既能加深对技术本身的理解,也能拓展知识深度和广度,这是个一举多得的方法。
第一部分:并发理论基础 (13讲)
01 | 可见性、原子性和有序性问题:并发编程Bug的源头
内容来源:01 | 可见性、原子性和有序性问题:并发编程Bug的源头-极客时间
并发程序幕后的故事
这些年,我们的 CPU、内存、I/O 设备都在不断迭代,不断朝着更快的方向努力。但是,在这个快速发展的过程中,有一个核心矛盾一直存在,就是这三者的速度差异。CPU 和内存的速度差异可以形象地描述为:CPU 是天上一天,内存是地上一年(假设 CPU 执行一条普通指令需要一天,那么 CPU 读写内存得等待一年的时间)。内存和 I/O 设备的速度差异就更大了,内存是天上一天,I/O 设备是地上十年(读写速度:CPU>>内存>>I/O设备)。
程序里大部分语句都要访问内存,有些还要访问 I/O,根据木桶理论(一只水桶能装多少水取决于它最短的那块木板),程序整体的性能取决于最慢的操作——读写 I/O 设备,也就是说单方面提高 CPU 性能是无效的。
为了合理利用 CPU 的高性能,平衡这三者的速度差异,计算机体系结构、操作系统、编译程序都做出了贡献,主要体现为:
-
CPU 增加了缓存,以均衡与内存的速度差异;
-
操作系统增加了进程、线程,以分时复用 CPU,进而均衡 CPU 与 I/O 设备的速度差异;
-
编译程序优化指令执行次序,使得缓存能够得到更加合理地利用。
现在我们几乎所有的程序都默默地享受着这些成果,但是天下没有免费的午餐,并发程序很多诡异问题的根源也在这里。
源头之一:缓存导致的可见性问题
在单核时代,所有的线程都是在一颗 CPU 上执行,CPU 缓存与内存的数据一致性容易解决。因为所有线程都是操作同一个 CPU 的缓存,一个线程对缓存的写,对另外一个线程来说一定是可见的。例如在下面的图中,线程 A 和线程 B 都是操作同一个 CPU 里面的缓存,所以线程 A 更新了变量 V 的值,那么线程 B 之后再访问变量 V,得到的一定是 V 的最新值(线程 A 写过的值)。

一个线程对共享变量的修改,另外一个线程能够立刻看到,我们称为可见性。
多核时代,每颗 CPU 都有自己的缓存,这时 CPU 缓存与内存的数据一致性就没那么容易解决了,当多个线程在不同的 CPU 上执行时,这些线程操作的是不同的 CPU 缓存。比如下图中,线程 A 操作的是 CPU-1 上的缓存,而线程 B 操作的是 CPU-2 上的缓存,很明显,这个时候线程 A 对变量 V 的操作对于线程 B 而言就不具备可见性了。这个就属于硬件程序员给软件程序员挖的“坑”。

下面我们再用一段代码来验证一下多核场景下的可见性问题。下面的代码,每执行一次 add() 方法,都会循环 10000 次 count+=1 操作。在 calc() 方法中我们创建了两个线程,每个线程调用一次 add() 方法,我们来想一想执行 calc() 方法得到的结果应该是多少呢?
public class Test {
private int count = 0;
private void add() {
int idx = 0;
while(idx++ < 10000) {
count += 1;
}
}
public static int calc() throws Exception {
final Test test = new Test();
Thread th1 = new Thread(()->{
test.add();
});
Thread th2 = new Thread(()->{
test.add();
});
th1.start();
th2.start();
th1.join();
th2.join();
return test.count;
}
public static void main(String[] args) throws Exception {
long c =calc();
System.out.println(c);
}
}
直觉告诉我们应该是 20000,因为在单线程里调用两次 add() 方法,count 的值就是 20000,但实际上 calc() 的执行结果是个 10000 到 20000 之间的随机数。为什么呢?我们假设线程 A 和线程 B 同时开始执行,那么第一次都会将 count=0 读到各自的 CPU 缓存里,执行完 count+=1 之后,各自 CPU 缓存里的值都是 1,同时写入内存后,我们会发现内存中是 1,而不是我们期望的 2。之后由于各自的 CPU 缓存里都有了 count 的值,两个线程都是基于 CPU 缓存里的 count 值来计算,所以导致最终 count 的值都是小于 20000 的。这就是缓存的可见性问题。

循环 10000 次 count+=1 操作如果改为循环 1 亿次,你会发现效果更明显,最终 count 的值接近 1 亿,而不是 2 亿。如果循环 10000 次,count 的值接近 20000,原因是两个线程不是同时启动的,有一个时差。
循环10000次随机10次测试结果:
16062 15343 19322 19910 18221 16693 16306 20000 18380 16091
循环100000000次随机10次测试结果:
100005515 100010463 100007964 100078690 100022544 100022242 100792891 100055873 100093928 100031027
源头之二:线程切换带来的原子性问题
由于 IO 太慢,早期的操作系统就发明了多进程,即便在单核的 CPU 上我们也可以一边听着歌,一边写 Bug,这个就是多进程的功劳。操作系统允许某个进程执行一小段时间,例如 50 毫秒,过了 50 毫秒操作系统就会重新选择一个进程来执行(我们称为“任务切换”),这个 50 毫秒称为“时间片”。

在一个时间片内,如果一个进程进行一个 IO 操作,例如读个文件,这个时候该进程可以把自己标记为“休眠状态”并出让 CPU 的使用权,待文件读进内存,操作系统会把这个休眠的进程唤醒,唤醒后的进程就有机会重新获得 CPU 的使用权了。
这里的进程在等待 IO 时之所以会释放 CPU 使用权,是为了让 CPU 在这段等待时间里可以做别的事情,这样一来 CPU 的使用率就上来了;此外,如果这时有另外一个进程也读文件,读文件的操作就会排队,磁盘驱动在完成一个进程的读操作后,发现有排队的任务,就会立即启动下一个读操作,这样 IO 的使用率也上来了。
是不是很简单的逻辑?是不是很简单的逻辑?但是,虽然看似简单,支持多进程分时复用在操作系统的发展史上却具有里程碑意义,Unix 就是因为解决了这个问题而名噪天下的。
早期的操作系统基于进程来调度 CPU,不同进程间是不共享内存空间的,所以进程要做任务切换就要切换内存映射地址,而一个进程创建的所有线程,都是共享一个内存空间的,所以线程做任务切换成本就很低了。现代的操作系统都基于更轻量的线程来调度,现在我们提到的“任务切换”都是指“线程切换”。
Java 并发程序都是基于多线程的,自然也会涉及到任务切换,也许你想不到,任务切换竟然也是并发编程里诡异 Bug 的源头之一。任务切换的时机大多数是在时间片结束的时候,我们现在基本都使用高级语言编程,高级语言里一条语句往往需要多条 CPU 指令完成,例如上面代码中的count += 1,至少需要三条 CPU 指令。
-
指令 1:首先,需要把变量 count 从内存加载到 CPU 的寄存器;
-
指令 2:之后,在寄存器中执行 +1 操作;
-
指令 3:最后,将结果写入内存(缓存机制导致可能写入的是 CPU 缓存而不是内存)。
操作系统做任务切换,可以发生在任何一条 CPU 指令执行完,是的,是 CPU 指令,而不是高级语言里的一条语句。对于上面的三条指令来说,我们假设 count=0,如果线程 A 在指令 1 执行完后做线程切换,线程 A 和线程 B 按照下图的序列执行,那么我们会发现两个线程都执行了 count+=1 的操作,但是得到的结果不是我们期望的 2,而是 1。

我们潜意识里面觉得 count+=1 这个操作是一个不可分割的整体,就像一个原子一样,线程的切换可以发生在 count+=1 之前,也可以发生在 count+=1 之后,但就是不会发生在中间。我们把一个或者多个操作在 CPU 执行的过程中不被中断的特性称为原子性。CPU 能保证的原子操作是 CPU 指令级别的,而不是高级语言的操作符,这是违背我们直觉的地方。因此,很多时候我们需要在高级语言层面保证操作的原子性。
源头之三:编译优化带来的有序性问题
那并发编程里还有没有其他有违直觉容易导致诡异 Bug 的技术呢?有的,就是有序性。顾名思义,有序性指的是程序按照代码的先后顺序执行。编译器为了优化性能,有时候会改变程序中语句的先后顺序,例如程序中:“a=6;b=7;” 编译器优化后可能变成“b=7;a=6;”,在这个例子中,编译器调整了语句的顺序,但是不影响程序的最终结果。不过有时候编译器及解释器的优化可能导致意想不到的 Bug。
在 Java 领域一个经典的案例就是利用双重检查创建单例对象,例如下面的代码:在获取实例 getInstance() 的方法中,我们首先判断 instance 是否为空,如果为空,则锁定 Singleton.class 并再次检查 instance 是否为空,如果还为空则创建 Singleton 的一个实例。
public class Singleton {
static Singleton instance;
static Singleton getInstance(){
if (instance == null) {
synchronized(Singleton.class) {
if (instance == null)
instance = new Singleton();
}
}
return instance;
}
}
假设有两个线程 A、B 同时调用 getInstance() 方法,他们会同时发现 instance == null ,于是同时对 Singleton.class 加锁,此时 JVM 保证只有一个线程能够加锁成功(假设是线程 A),另外一个线程则会处于等待状态(假设是线程 B);线程 A 会创建一个 Singleton 实例,之后释放锁,锁释放后,线程 B 被唤醒,线程 B 再次尝试加锁,此时是可以加锁成功的,加锁成功后,线程 B 检查 instance == null 时会发现,已经创建过 Singleton 实例了,所以线程 B 不会再创建一个 Singleton 实例。
这看上去一切都很完美,无懈可击,但实际上这个 getInstance() 方法并不完美。问题出在哪里呢?出在 new 操作上,我们以为的 new 操作应该是:
-
分配一块内存 M;
-
在内存 M 上初始化 Singleton 对象;
-
然后 M 的地址赋值给 instance 变量。
但是实际上优化后的执行路径却是这样的:
-
分配一块内存 M;
-
将 M 的地址赋值给 instance 变量;
-
最后在内存 M 上初始化 Singleton 对象。
优化后会导致什么问题呢?我们假设线程 A 先执行 getInstance() 方法,当执行完指令 2 时恰好发生了线程切换,切换到了线程 B 上;如果此时线程 B 也执行 getInstance() 方法,那么线程 B 在执行第一个判断时会发现 instance != null ,所以直接返回 instance,而此时的 instance 是没有初始化过的,如果我们这个时候访问 instance 的成员变量就可能触发空指针异常。

总结
要写好并发程序,首先要知道并发程序的问题在哪里,只有确定了“靶子”,才有可能把问题解决,毕竟所有的解决方案都是针对问题的。并发程序经常出现的诡异问题看上去非常无厘头,但是深究的话,无外乎就是直觉欺骗了我们,只要我们能够深刻理解可见性、原子性、有序性在并发场景下的原理,很多并发 Bug 都是可以理解、可以诊断的。
在介绍可见性、原子性、有序性的时候,特意提到缓存导致的可见性问题,线程切换带来的原子性问题,编译优化带来的有序性问题,其实缓存、线程、编译优化的目的和我们写并发程序的目的是相同的,都是提高程序性能。但是技术在解决一个问题的同时,必然会带来另外一个问题,所以在采用一项技术的同时,一定要清楚它带来的问题是什么,以及如何规避。
我们这个专栏在讲解每项技术的时候,都会尽量将每项技术解决的问题以及产生的问题讲清楚,也希望你能够在这方面多思考、多总结。
课后思考
常听人说,在 32 位的机器上对 long 型变量进行加减操作存在并发隐患,到底是不是这样呢?
答案:
因为long类型64位,所以在32位的机器上,对long类型的数据操作通常需要多条指令组合出来,无法保证原子性,所以并发的时候会出问题。
02 | Java内存模型:看Java如何解决可见性和有序性问题
内容来源:02 | Java内存模型:看Java如何解决可见性和有序性问题-极客时间
上一期我们讲到在并发场景中,因可见性、原子性、有序性导致的问题常常会违背我们的直觉,从而成为并发编程的 Bug 之源。这三者在编程领域属于共性问题,所有的编程语言都会遇到,Java 在诞生之初就支持多线程,自然也有针对这三者的技术方案,而且在编程语言领域处于领先地位。理解 Java 解决并发问题的解决方案,对于理解其他语言的解决方案有触类旁通的效果。
Java 内存模型这个概念,在职场的很多面试中都会考核到,是一个热门的考点,也是一个人并发水平的具体体现。原因是当并发程序出问题时,需要一行一行地检查代码,这个时候,只有掌握 Java 内存模型,才能慧眼如炬地发现问题。
什么是 Java 内存模型?
你已经知道,导致可见性的原因是缓存,导致有序性的原因是编译优化,那解决可见性、有序性最直接的办法就是禁用缓存和禁用编译优化,但是这样问题虽然解决了,我们程序的性能可就堪忧了。
合理的方案应该是按需禁用缓存以及按需禁用编译优化。那么,如何做到“按需禁用”呢?对于并发程序,何时禁用缓存以及何时禁用编译优化只有程序员知道,那所谓“按需禁用”其实就是指按照程序员的要求来禁用。所以,为了解决可见性和有序性问题,只需要提供给程序员按需禁用缓存和编译优化的方法即可。
Java 内存模型是个很复杂的规范,可以从不同的视角来解读,站在我们这些程序员的视角,本质上可以理解为,Java 内存模型规范了 JVM 如何提供按需禁用缓存和按需禁用编译优化的方法。具体来说,这些方法包括 volatile、synchronized 和 final 三个关键字,以及六项 Happens-Before 规则,这也正是本期的重点内容。
使用 volatile 的困惑
volatile 关键字并不是 Java 语言的特产,古老的 C 语言里也有,它最原始的意义就是禁用 CPU 缓存。例如,我们声明一个 volatile 变量 volatile int x = 0,它表达的是:告诉编译器,对这个变量的读写,不能使用 CPU 缓存,必须从内存中读取或者写入。
这个语义看上去相当明确,但是在实际使用的时候却会带来困惑。例如下面的示例代码,假设线程 A 执行 writer() 方法,按照 volatile 语义,会把变量 “v=true” 写入内存;假设线程 B 执行 reader() 方法,同样按照 volatile 语义,线程 B 会从内存中读取变量 v,如果线程 B 看到 “v == true” 时,那么线程 B 看到的变量 x 是多少呢?直觉上看,应该是 42,那实际应该是多少呢?这个要看 Java 的版本,如果在低于 1.5 版本上运行,x 可能是 42,也有可能是 0;如果在 1.5 以上的版本上运行,x 就是等于 42。
// 以下代码来源于【参考1】
class VolatileExample {
int x = 0;
volatile boolean v = false;
public void writer() {
x = 42;
v = true;
}
public void reader() {
if (v == true) {
// 这里x会是多少呢?
}
}
}
JDK1.8实际测试结果:42
public class VolatileTest {
int x = 0;
volatile boolean v = false;
public void writer() {
x = 42;
v = true;
}
public void reader() {
if (v == true) {
System.out.println(x);
}
}
public static void main(String[] args) {
VolatileTest volatileTest = new VolatileTest();
Thread t1 = new Thread(()->{
volatileTest.writer();
});
Thread t2 = new Thread(()->{
volatileTest.reader();
});
t1.start();
t2.start();
}
}
分析一下,为什么 1.5 以前的版本会出现 x = 0 的情况呢?我相信你一定想到了,变量 x 可能被 CPU 缓存而导致可见性问题。这个问题在 1.5 版本已经被圆满解决了。Java 内存模型在 1.5 版本对 volatile 语义进行了增强。怎么增强的呢?答案是一项 Happens-Before 规则。
Happens-Before 规则
如何理解 Happens-Before 呢?如果望文生义(很多网文也都爱按字面意思翻译成“先行发生”),那就南辕北辙了,Happens-Before 并不是说前面一个操作发生在后续操作的前面,它真正要表达的是:前面一个操作的结果对后续操作是可见的。就像有心灵感应的两个人,虽然远隔千里,一个人心之所想,另一个人都看得到。Happens-Before 规则就是要保证线程之间的这种“心灵感应”。所以比较正式的说法是:Happens-Before 约束了编译器的优化行为,虽允许编译器优化,但是要求编译器优化后一定遵守 Happens-Before 规则。Happens-Before 规则应该是 Java 内存模型里面最晦涩的内容了,和程序员相关的规则一共有如下六项,都是关于可见性的。恰好前面示例代码涉及到这六项规则中的前三项,为便于你理解,我也会分析上面的示例代码,来看看规则 1、2 和 3 到底该如何理解。至于其他三项,我也会结合其他例子作以说明。
---1.程序的顺序性规则
这条规则是指在一个线程中,按照程序顺序,前面的操作 Happens-Before 于后续的任意操作。这还是比较容易理解的,比如刚才那段示例代码,按照程序的顺序,第 6 行代码 “x = 42;” Happens-Before 于第 7 行代码 “v = true;”,这就是规则 1 的内容,也比较符合单线程里面的思维:程序前面对某个变量的修改一定是对后续操作可见的。
// 以下代码来源于【参考1】
class VolatileExample {
int x = 0;
volatile boolean v = false;
public void writer() {
x = 42;
v = true;
}
public void reader() {
if (v == true) {
// 这里x会是多少呢?
}
}
}
测试代码同上。
---2. volatile 变量规则
这条规则是指对一个 volatile 变量的写操作, Happens-Before 于后续对这个 volatile 变量的读操作。这个就有点费解了,对一个 volatile 变量的写操作相对于后续对这个 volatile 变量的读操作可见,这怎么看都是禁用缓存的意思啊,貌似和 1.5 版本以前的语义没有变化啊?如果单看这个规则,的确是这样,但是如果我们关联一下规则 3,就有点不一样的感觉了。
---3. 传递性
这条规则是指如果 A Happens-Before B,且 B Happens-Before C,那么 A Happens-Before C。我们将规则 3 的传递性应用到我们的例子中,会发生什么呢?可以看下面这幅图:

从图中,我们可以看到:
-
“x=42” Happens-Before 写变量 “v=true” ,这是规则 1 的内容;
-
写变量“v=true” Happens-Before 读变量 “v=true”,这是规则 2 的内容 。
再根据这个传递性规则,我们得到结果:“x=42” Happens-Before 读变量“v=true”。这意味着什么呢?如果线程 B 读到了“v=true”,那么线程 A 设置的“x=42”对线程 B 是可见的。也就是说,线程 B 能看到 “x == 42” ,有没有一种恍然大悟的感觉?这就是 1.5 版本对 volatile 语义的增强,这个增强意义重大,1.5 版本的并发工具包(java.util.concurrent)就是靠 volatile 语义来搞定可见性的,这个在后面的内容中会详细介绍。
---4. 管程中锁的规则
这条规则是指对一个锁的解锁 Happens-Before 于后续对这个锁的加锁。要理解这个规则,就首先要了解“管程指的是什么”。管程是一种通用的同步原语,在 Java 中指的就是 synchronized,synchronized 是 Java 里对管程的实现。管程中的锁在 Java 里是隐式实现的,例如下面的代码:
synchronized (this) { //此处自动加锁
// x是共享变量,初始值=10
if (this.x < 12) {
this.x = 12;
}
} //此处自动解锁
在进入同步块之前,会自动加锁,而在代码块执行完会自动释放锁,加锁以及释放锁都是编译器帮我们实现的。所以结合规则 4---管程中锁的规则,可以这样理解:假设 x 的初始值是 10,线程 A 执行完代码块后 x 的值会变成 12(执行完自动释放锁),线程 B 进入代码块时,能够看到线程 A 对 x 的写操作,也就是线程 B 能够看到 x==12。这个也是符合我们直觉的,应该不难理解。
---5. 线程 start() 规则
这条是关于线程启动的。它是指主线程 A 启动子线程 B 后,子线程 B 能够看到主线程在启动子线程 B 前的操作。换句话说就是,如果线程 A 调用线程 B 的 start() 方法(即在线程 A 中启动线程 B),那么该 start() 操作 Happens-Before 于线程 B 中的任意操作。具体可参考下面示例代码:
Thread B = new Thread(()->{
// 主线程调用B.start()之前
// 所有对共享变量的修改,此处皆可见
// 此例中,var==77
});
// 此处对共享变量var修改
var = 77;
// 主线程启动子线程
B.start();
---6. 线程 join() 规则
这条是关于线程等待的。它是指主线程 A 等待子线程 B 完成(主线程 A 通过调用子线程 B 的 join() 方法实现),当子线程 B 完成后(主线程 A 中 join() 方法返回),主线程能够看到子线程的操作。当然所谓的“看到”,指的是对共享变量的操作。换句话说就是,如果在线程 A 中,调用线程 B 的 join() 并成功返回,那么线程 B 中的任意操作 Happens-Before 于该 join() 操作的返回。具体可参考下面示例代码:
Thread B = new Thread(()->{
// 此处对共享变量var修改
var = 66;
});
// 例如此处对共享变量修改,
// 则这个修改结果对线程B可见
// 主线程启动子线程
B.start();
B.join()
// 子线程所有对共享变量的修改
// 在主线程调用B.join()之后皆可见
// 此例中,var==66
被我们忽视的 final
前面我们讲 volatile 为的是禁用缓存以及编译优化,我们再从另外一个方面来看,有没有办法告诉编译器优化得更好一点呢?这个可以有,就是 final 关键字。
final 修饰变量时,初衷是告诉编译器:这个变量生而不变,可以可劲儿优化。Java 编译器在 1.5 以前的版本的确优化得很努力,以至于都优化错了。问题类似于上一期提到的利用双重检查方法创建单例,构造函数的错误重排导致线程可能看到 final 变量的值会变化。详细的案例可以参考这个文档:http://www.cs.umd.edu/~pugh/java/memoryModel/jsr-133-faq.html#finalWrong。当然了,在 1.5 以后 Java 内存模型对 final 类型变量的重排进行了约束。现在只要我们提供正确构造函数没有“逸出”,就不会出问题了。“逸出”有点抽象,我们还是举个例子吧:
// 以下代码来源于【参考1】
final int x;
// 错误的构造函数
public FinalFieldExample() {
x = 3;
y = 4;
// 此处就是讲this逸出,
global.obj = this;
}
在构造函数里面将 this 赋值给了全局变量 global.obj,这就是“逸出”,线程通过 global.obj 读取 x 是有可能读到 0 的,因此我们一定要避免“逸出”。在构造方法中将this 复制给别的变量,意味着,构造方法还没结束,对象this 就给别人使用了。对象还没初始化完成,别人就使用,类似双层校验创建单例的例子。 逸出要避免,要避免这种写法。 同时,如果在构造方法中对成员变量赋初始值,比如this.x = x,这样的代码在编译的时候,也会被重排序,将赋值操作重排序到构造方法之外,那么也就是,构造方法结束了,初始化完成了,这时候,别的线程先后可能会读取到俩个不同的值,一个没初始化的,一个初始化后的值。要避免这种情况的发送,就要用fianl,final修饰的变量,可以保证,不会被抽排序到构造方法之外,那么就保证了,只要别的线程拿到该对象的引用,那么改对象的fianl修饰的变量,别的线程一定是能读到在构造方法中初始化的值的,避免了上面同一变量,读取值两次不一样的问题。
总结
Java 的内存模型是并发编程领域的一次重要创新,之后 C++、C#、Golang 等高级语言都开始支持内存模型。Java 内存模型里面,最晦涩的部分就是 Happens-Before 规则了,Happens-Before 规则最初是在一篇叫做 Time, Clocks, and the Ordering of Events in a Distributed System 的论文中提出来的,在这篇论文中,Happens-Before 的语义是一种因果关系。在现实世界里,如果 A 事件是导致 B 事件的起因,那么 A 事件一定是先于(Happens-Before)B 事件发生的,这个就是 Happens-Before 语义的现实理解。在 Java 语言里面,Happens-Before 的语义本质上是一种可见性,A Happens-Before B 意味着 A 事件对 B 事件来说是可见的,无论 A 事件和 B 事件是否发生在同一个线程里。例如 A 事件发生在线程 1 上,B 事件发生在线程 2 上,Happens-Before 规则保证线程 2 上也能看到 A 事件的发生。Java 内存模型主要分为两部分,一部分面向你我这种编写并发程序的应用开发人员,另一部分是面向 JVM 的实现人员的,我们可以重点关注前者,也就是和编写并发程序相关的部分,这部分内容的核心就是 Happens-Before 规则。相信经过本章的介绍,你应该对这部分内容已经有了深入的认识。
参考链接:
-
http://www.cs.umd.edu/~pugh/java/memoryModel/jsr-133-faq.html
-
Java内存模型FAQ | 并发编程网 – ifeve.com
-
https://www.cs.umd.edu/~pugh/java/memoryModel/jsr133.pdf
课后思考
有一个共享变量 abc,在一个线程里设置了 abc 的值 abc=3,你思考一下,有哪些办法可以让其他线程能够看到abc==3?
答案:
-
声明共享变量abc,并使用volatile关键字修饰abc
-
声明共享变量abc,在synchronized关键字对abc的赋值代码块加锁,由于Happen-before管程锁的规则,可以使得后续的线程可以看到abc的值。
-
A线程启动后,使用A.JOIN()方法来完成运行,后续线程再启动,则一定可以看到abc==3
-
在abc赋值后对一个volatile变量A进行赋值操作,然后在其他线程读取abc之前读取A的值,通过volatile的可见性和happen-before的传递性实现abc修改后对其他线程立即可见。
-
使用原子变量,例如:AtomicInteger等
-
不是办法的办法:保证多个线程是串行执行
补充:
1. 为什么定义Java内存模型?
现代计算机体系大多是采用的对称多处理器的体系架构。每个处理器均有独立的寄存器组和缓存,多个处理器可同时执行同一进程中的不同线程,这里称为处理器的乱序执行。在Java中,不同的线程可能访问同一个共享或共享变量。如果任由编译器或处理器对这些访问进行优化的话,很有可能出现无法想象的问题,这里称为编译器的重排序。除了处理器的乱序执行、编译器的重排序,还有内存系统的重排序。因此Java语言规范引入了Java内存模型,通过定义多项规则对编译器和处理器进行限制,主要是针对可见性和有序性。
2. 三个基本原则:原子性、可见性、有序性。
3. Java内存模型涉及的几个关键词:锁、volatile字段、final修饰符与对象的安全发布。其中:
-
第一是锁,锁操作是具备happens-before关系的,解锁操作happens-before之后对同一把锁的加锁操作。实际上,在解锁的时候,JVM需要强制刷新缓存,使得当前线程所修改的内存对其他线程可见。
-
第二是volatile字段,volatile字段可以看成是一种不保证原子性的同步但保证可见性的特性,其性能往往是优于锁操作的。但是,频繁地访问 volatile字段也会出现因为不断地强制刷新缓存而影响程序的性能的问题。
-
第三是final修饰符,final修饰的实例字段则是涉及到新建对象的发布问题。当一个对象包含final修饰的实例字段时,其他线程能够看到已经初始化的final实例字段,这是安全的。
4.Happens-Before的7个规则:
-
(1).程序次序规则:在一个线程内,按照程序代码顺序,书写在前面的操作先行发生于书写在后面的操作。准确地说,应该是控制流顺序而不是程序代码顺序,因为要考虑分支、循环等结构。
-
(2).管程锁定规则:一个unlock操作先行发生于后面对同一个锁的lock操作。这里必须强调的是同一个锁,而"后面"是指时间上的先后顺序。
-
(3).volatile变量规则:对一个volatile变量的写操作先行发生于后面对这个变量的读操作,这里的"后面"同样是指时间上的先后顺序。
-
(4).线程启动规则:Thread对象的start()方法先行发生于此线程的每一个动作。
-
(5).线程终止规则:线程中的所有操作都先行发生于对此线程的终止检测,我们可以通过Thread.join()方法结束、Thread.isAlive()的返回值等手段检测到线程已经终止执行。
-
(6).线程中断规则:对线程interrupt()方法的调用先行发生于被中断线程的代码检测到中断事件的发生,可以通过Thread.interrupted()方法检测到是否有中断发生。
-
interrupt() 用于中断另一个线程
-
isInterrupted(),用来判断当前线程的中断状态(true or false)
-
interrupted()是个Thread的static方法,用来恢复中断状态。
-
-
(7).对象终结规则:一个对象的初始化完成(构造函数执行结束)先行发生于它的finalize()方法的开始。
5. Happens-Before的1个特性:传递性。
6. Java内存模型底层怎么实现的?
主要是通过内存屏障(memory barrier)禁止重排序的,即时编译器根据具体的底层体系架构,将这些内存屏障替换成具体的 CPU 指令。对于编译器而言,内存屏障将限制它所能做的重排序优化。而对于处理器而言,内存屏障将会导致缓存的刷新操作。比如,对于volatile,编译器将在volatile字段的读写操作前后各插入一些内存屏障。
03 | 互斥锁(上):解决原子性问题
内容来源:03 | 互斥锁(上):解决原子性问题-极客时间
在第一篇文章中我们提到,一个或者多个操作在 CPU 执行的过程中不被中断的特性,称为“原子性”。理解这个特性有助于你分析并发编程 Bug 出现的原因,例如利用它可以分析出 long 型变量在 32 位机器上读写可能出现的诡异 Bug,明明已经把变量成功写入内存,重新读出来却不是自己写入的。
那原子性问题到底该如何解决呢?你已经知道,原子性问题的源头是线程切换,如果能够禁用线程切换那不就能解决这个问题了吗?而操作系统做线程切换是依赖 CPU 中断的,所以禁止 CPU 发生中断就能够禁止线程切换。在早期单核 CPU 时代,这个方案的确是可行的,而且也有很多应用案例,但是并不适合多核场景。这里我们以 32 位 CPU 上执行 long 型变量的写操作为例来说明这个问题,long 型变量是 64 位,在 32 位 CPU 上执行写操作会被拆分成两次写操作(写高 32 位和写低 32 位,如下图所示):

在单核 CPU 场景下,同一时刻只有一个线程执行,禁止 CPU 中断,意味着操作系统不会重新调度线程,也就是禁止了线程切换,获得 CPU 使用权的线程就可以不间断地执行,所以两次写操作一定是:要么都被执行,要么都没有被执行,具有原子性。
但是在多核场景下,同一时刻,有可能有两个线程同时在执行,一个线程执行在 CPU-1 上,一个线程执行在 CPU-2 上,此时禁止 CPU 中断,只能保证 CPU 上的线程连续执行,并不能保证同一时刻只有一个线程执行,如果这两个线程同时写 long 型变量高 32 位的话,那就有可能出现我们开头提及的诡异 Bug 了。“同一时刻只有一个线程执行”这个条件非常重要,我们称之为互斥。如果我们能够保证对共享变量的修改是互斥的,那么,无论是单核 CPU 还是多核 CPU,就都能保证原子性了。
简易锁模型
当谈到互斥,相信聪明的你一定想到了那个杀手级解决方案:锁。同时大脑中还会出现以下模型:

我们把一段需要互斥执行的代码称为临界区。线程在进入临界区之前,首先尝试加锁 lock(),如果成功,则进入临界区,此时我们称这个线程持有锁;否则呢就等待,直到持有锁的线程解锁;持有锁的线程执行完临界区的代码后,执行解锁 unlock()。这个过程非常像办公室里高峰期抢占坑位,每个人都是进坑锁门(加锁),出坑开门(解锁),如厕这个事就是临界区。很长时间里,我也是这么理解的。这样理解本身没有问题,但却很容易让我们忽视两个非常非常重要的点:我们锁的是什么?我们保护的又是什么?
改进后的锁模型
我们知道在现实世界里,锁和锁要保护的资源是有对应关系的,比如你用你家的锁保护你家的东西,我用我家的锁保护我家的东西。在并发编程世界里,锁和资源也应该有这个关系,但这个关系在我们上面的模型中是没有体现的,所以我们需要完善一下我们的模型。

首先,我们要把临界区要保护的资源标注出来,如图中临界区里增加了一个元素:受保护的资源 R;其次,我们要保护资源 R 就得为它创建一把锁 LR;最后,针对这把锁 LR,我们还需在进出临界区时添上加锁操作和解锁操作。另外,在锁 LR 和受保护资源之间,我特地用一条线做了关联,这个关联关系非常重要。很多并发 Bug 的出现都是因为把它忽略了,然后就出现了类似锁自家门来保护他家资产的事情,这样的 Bug 非常不好诊断,因为潜意识里我们认为已经正确加锁了。
Java 语言提供的锁技术:synchronized
锁是一种通用的技术方案,Java 语言提供的 synchronized 关键字,就是锁的一种实现。synchronized 关键字可以用来修饰方法,也可以用来修饰代码块,它的使用示例基本上都是下面这个样子:
class X {
// 修饰非静态方法
synchronized void foo() {
// 临界区
}
// 修饰静态方法
synchronized static void bar() {
// 临界区
}
// 修饰代码块
Object obj = new Object();
void baz() {
synchronized(obj) {
// 临界区
}
}
}
看完之后你可能会觉得有点奇怪,这个和我们上面提到的模型有点对不上号啊,加锁 lock() 和解锁 unlock() 在哪里呢?其实这两个操作都是有的,只是这两个操作是被 Java 默默加上的,Java 编译器会在 synchronized 修饰的方法或代码块前后自动加上加锁 lock() 和解锁 unlock(),这样做的好处就是加锁 lock() 和解锁 unlock() 一定是成对出现的,毕竟忘记解锁 unlock() 可是个致命的 Bug(意味着其他线程只能死等下去了)。
那 synchronized 里的加锁 lock() 和解锁 unlock() 锁定的对象在哪里呢?上面的代码我们看到只有修饰代码块的时候,锁定了一个 obj 对象,那修饰方法的时候锁定的是什么呢?这个也是 Java 的一条隐式规则:当修饰静态方法的时候,锁定的是当前类的 Class 对象,在上面的例子中就是 Class X;当修饰非静态方法的时候,锁定的是当前实例对象 this。对于上面的例子,synchronized 修饰静态方法相当于:
class X {
// 修饰静态方法
synchronized(X.class) static void bar() {
// 临界区
}
}
修饰非静态方法,相当于:
class X {
// 修饰非静态方法
synchronized(this) void foo() {
// 临界区
}
}
用 synchronized 解决 count+=1 问题
相信你一定记得我们前面文章中提到过的 count+=1 存在的并发问题,现在我们可以尝试用 synchronized 来小试牛刀一把,代码如下所示。SafeCalc 这个类有两个方法:一个是 get() 方法,用来获得 value 的值;另一个是 addOne() 方法,用来给 value 加 1,并且 addOne() 方法我们用 synchronized 修饰。那么我们使用的这两个方法有没有并发问题呢?
class SafeCalc {
long value = 0L;
long get() {
return value;
}
synchronized void addOne() {
value += 1;
}
}
我们先来看看 addOne() 方法,首先可以肯定,被 synchronized 修饰后,无论是单核 CPU 还是多核 CPU,只有一个线程能够执行 addOne() 方法,所以一定能保证原子操作,那是否有可见性问题呢?要回答这问题,就要重温一下上一篇文章中提到的管程中锁的规则。管程中锁的规则:对一个锁的解锁 Happens-Before 于后续对这个锁的加锁。
管程,就是我们这里的 synchronized(至于为什么叫管程,我们后面介绍),我们知道 synchronized 修饰的临界区是互斥的,也就是说同一时刻只有一个线程执行临界区的代码;而所谓“对一个锁解锁 Happens-Before 后续对这个锁的加锁”,指的是前一个线程的解锁操作对后一个线程的加锁操作可见,综合 Happens-Before 的传递性原则,我们就能得出前一个线程在临界区修改的共享变量(该操作在解锁之前),对后续进入临界区(该操作在加锁之后)的线程是可见的。按照这个规则,如果多个线程同时执行 addOne() 方法,可见性是可以保证的,也就说如果有 1000 个线程执行 addOne() 方法,最终结果一定是 value 的值增加了 1000。看到这个结果,我们长出一口气,问题终于解决了。但也许,你一不小心就忽视了 get() 方法。执行 addOne() 方法后,value 的值对 get() 方法是可见的吗?这个可见性是没法保证的。管程中锁的规则,是只保证后续对这个锁的加锁的可见性,而 get() 方法并没有加锁操作,所以可见性没法保证。那如何解决呢?很简单,就是 get() 方法也 synchronized 一下,完整的代码如下所示。
class SafeCalc {
long value = 0L;
synchronized long get() {
return value;
}
synchronized void addOne() {
value += 1;
}
}
上面的代码转换为我们提到的锁模型,就是下面图示这个样子。get() 方法和 addOne() 方法都需要访问 value 这个受保护的资源,这个资源用 this 这把锁来保护。线程要进入临界区 get() 和 addOne(),必须先获得 this 这把锁,这样 get() 和 addOne() 也是互斥的。

这个模型更像现实世界里面球赛门票的管理,一个座位只允许一个人使用,这个座位就是“受保护资源”,球场的入口就是 Java 类里的方法,而门票就是用来保护资源的“锁”,Java 里的检票工作是由 synchronized 解决的。
锁和受保护资源的关系
我们前面提到,受保护资源和锁之间的关联关系非常重要,他们的关系是怎样的呢?一个合理的关系是:受保护资源和锁之间的关联关系是 N:1 的关系。还拿前面球赛门票的管理来类比,就是一个座位,我们只能用一张票来保护,如果多发了重复的票,那就要打架了。现实世界里,我们可以用多把锁来保护同一个资源,但在并发领域是不行的,并发领域的锁和现实世界的锁不是完全匹配的。不过倒是可以用同一把锁来保护多个资源,这个对应到现实世界就是我们所谓的“包场”了。上面那个例子我稍作改动,把 value 改成静态变量,把 addOne() 方法改成静态方法,此时 get() 方法和 addOne() 方法是否存在并发问题呢?
class SafeCalc {
static long value = 0L;
synchronized long get() {
return value;
}
synchronized static void addOne() {
value += 1;
}
}
如果你仔细观察,就会发现改动后的代码是用两个锁保护一个资源。这个受保护的资源就是静态变量 value,两个锁分别是 this 和 SafeCalc.class。我们可以用下面这幅图来形象描述这个关系。

由于临界区 get() 和 addOne() 是用两个锁保护的,因此这两个临界区没有互斥关系,临界区 addOne() 对 value 的修改对临界区 get() 也没有可见性保证,这就导致并发问题了。
总结
互斥锁,在并发领域的知名度极高,只要有了并发问题,大家首先容易想到的就是加锁,因为大家都知道,加锁能够保证执行临界区代码的互斥性。这样理解虽然正确,但是却不能够指导你真正用好互斥锁。临界区的代码是操作受保护资源的路径,类似于球场的入口,入口一定要检票,也就是要加锁,但不是随便一把锁都能有效。所以必须深入分析锁定的对象和受保护资源的关系,综合考虑受保护资源的访问路径,多方面考量才能用好互斥锁。synchronized 是 Java 在语言层面提供的互斥原语,其实 Java 里面还有很多其他类型的锁,但作为互斥锁,原理都是相通的:锁,一定有一个要锁定的对象,至于这个锁定的对象要保护的资源以及在哪里加锁 / 解锁,就属于设计层面的事情了。
课后思考
下面的代码用 synchronized 修饰代码块来尝试解决并发问题,你觉得这个使用方式正确吗?有哪些问题呢?能解决可见性和原子性问题吗?
class SafeCalc {
long value = 0L;
long get() {
synchronized (new Object()) {
return value;
}
}
void addOne() {
synchronized (new Object()) {
value += 1;
}
}
}
答案:不能解决可见性和原子性问题,因为new Object()最终得到的是两个对象,加锁本质就是在锁对象的对象头中写入当前线程id,由于最终会得到两把不同的锁,所以不能对临近资源进行保护,加锁无效。而且这种new出来只在一个地方使用的对象,其它线程不能对它解锁,这个锁会被编译器优化掉,和没有syncronized代码块效果是相同的。
另外,get方法不用synchronized也能保证可见性,这是对的。但如果真的这么做了,原子性就可能会被打破。synchronized并不保证线程不被中断。如果在写高低两个位的中间写线程被中断,而读线程被调度执行,因为读没有尝试加锁,所以可以读到写了一半的结果。这种情况都不用考虑多核,单核都会出现原子性问题。所以谨慎起见还是给get加上synchronized保险点。
04 | 互斥锁(下):如何用一把锁保护多个资源?
内容来源:04 | 互斥锁(下):如何用一把锁保护多个资源?-极客时间
在上一篇文章中,我们提到受保护资源和锁之间合理的关联关系应该是 N:1 的关系,也就是说可以用一把锁来保护多个资源,但是不能用多把锁来保护一个资源,并且结合文中示例,我们也重点强调了“不能用多把锁来保护一个资源”这个问题。当我们要保护多个资源时,首先要区分这些资源是否存在关联关系。
保护没有关联关系的多个资源
在现实世界里,球场的座位和电影院的座位就是没有关联关系的,这种场景非常容易解决,那就是球赛有球赛的门票,电影院有电影院的门票,各自管理各自的。同样这对应到编程领域,也很容易解决。例如,银行业务中有针对账户余额(余额是一种资源)的取款操作,也有针对账户密码(密码也是一种资源)的更改操作,我们可以为账户余额和账户密码分配不同的锁来解决并发问题,这个还是很简单的。相关的示例代码如下,账户类 Account 有两个成员变量,分别是账户余额 balance 和账户密码 password。取款 withdraw() 和查看余额 getBalance() 操作会访问账户余额 balance,我们创建一个 final 对象 balLock 作为锁(类比球赛门票);而更改密码 updatePassword() 和查看密码 getPassword() 操作会修改账户密码 password,我们创建一个 final 对象 pwLock 作为锁(类比电影票)。不同的资源用不同的锁保护,各自管各自的,很简单。
class Account {
// 锁:保护账户余额
private final Object balLock
= new Object();
// 账户余额
private Integer balance;
// 锁:保护账户密码
private final Object pwLock
= new Object();
// 账户密码
private String password;
// 取款
void withdraw(Integer amt) {
synchronized(balLock) {
if (this.balance > amt){
this.balance -= amt;
}
}
}
// 查看余额
Integer getBalance() {
synchronized(balLock) {
return balance;
}
}
// 更改密码
void updatePassword(String pw){
synchronized(pwLock) {
this.password = pw;
}
}
// 查看密码
String getPassword() {
synchronized(pwLock) {
return password;
}
}
}
当然,我们也可以用一把互斥锁来保护多个资源,例如我们可以用 this 这一把锁来管理账户类里所有的资源:账户余额和用户密码。具体实现很简单,示例程序中所有的方法都增加同步关键字 synchronized 就可以了,这里我就不一一展示了。但是用一把锁有个问题,就是性能太差,会导致取款、查看余额、修改密码、查看密码这四个操作都是串行的。而我们用两把锁,取款和修改密码是可以并行的。用不同的锁对受保护资源进行精细化管理,能够提升性能。这种锁还有个名字,叫细粒度锁。
保护有关联关系的多个资源
如果多个资源是有关联关系的,那这个问题就有点复杂了。例如银行业务里面的转账操作,账户 A 减少 100 元,账户 B 增加 100 元。这两个账户就是有关联关系的。那对于像转账这种有关联关系的操作,我们应该怎么去解决呢?先把这个问题代码化。我们声明了个账户类:Account,该类有一个成员变量余额:balance,还有一个用于转账的方法:transfer(),然后怎么保证转账操作 transfer() 没有并发问题呢?
class Account {
private int balance;
// 转账
void transfer(
Account target, int amt){
if (this.balance > amt) {
this.balance -= amt;
target.balance += amt;
}
}
}
相信你的直觉会告诉你这样的解决方案:用户 synchronized 关键字修饰一下 transfer() 方法就可以了,于是你很快就完成了相关的代码,如下所示。
class Account {
private int balance;
// 转账
synchronized void transfer(
Account target, int amt){
if (this.balance > amt) {
this.balance -= amt;
target.balance += amt;
}
}
}
在这段代码中,临界区内有两个资源,分别是转出账户的余额 this.balance 和转入账户的余额 target.balance,并且用的是一把锁 this,符合我们前面提到的,多个资源可以用一把锁来保护,这看上去完全正确呀。真的是这样吗?可惜,这个方案仅仅是看似正确,为什么呢?问题就出在 this 这把锁上,this 这把锁可以保护自己的余额 this.balance,却保护不了别人的余额 target.balance,就像你不能用自家的锁来保护别人家的资产,也不能用自己的票来保护别人的座位一样。

下面我们具体分析一下,假设有 A、B、C 三个账户,余额都是 200 元,我们用两个线程分别执行两个转账操作:账户 A 转给账户 B 100 元,账户 B 转给账户 C 100 元,最后我们期望的结果应该是账户 A 的余额是 100 元,账户 B 的余额是 200 元, 账户 C 的余额是 300 元。我们假设线程 1 执行账户 A 转账户 B 的操作,线程 2 执行账户 B 转账户 C 的操作。这两个线程分别在两颗 CPU 上同时执行,那它们是互斥的吗?我们期望是,但实际上并不是。因为线程 1 锁定的是账户 A 的实例(A.this),而线程 2 锁定的是账户 B 的实例(B.this),所以这两个线程可以同时进入临界区 transfer()。同时进入临界区的结果是什么呢?线程 1 和线程 2 都会读到账户 B 的余额为 200,导致最终账户 B 的余额可能是 300(线程 1 后于线程 2 写 B.balance,线程 2 写的 B.balance 值被线程 1 覆盖),可能是 100(线程 1 先于线程 2 写 B.balance,线程 1 写的 B.balance 值被线程 2 覆盖),就是不可能是 200。

使用锁的正确姿势
在上一篇文章中,我们提到用同一把锁来保护多个资源,也就是现实世界的“包场”,那在编程领域应该怎么“包场”呢?很简单,只要我们的锁能覆盖所有受保护资源就可以了。在上面的例子中,this 是对象级别的锁,所以 A 对象和 B 对象都有自己的锁,如何让 A 对象和 B 对象共享一把锁呢?稍微开动脑筋,你会发现其实方案还挺多的,比如可以让所有对象都持有一个唯一性的对象,这个对象在创建 Account 时传入。方案有了,完成代码就简单了。示例代码如下,我们把 Account 默认构造函数变为 private,同时增加一个带 Object lock 参数的构造函数,创建 Account 对象时,传入相同的 lock,这样所有的 Account 对象都会共享这个 lock 了。
class Account {
private Object lock;
private int balance;
private Account();
// 创建Account时传入同一个lock对象
public Account(Object lock) {
this.lock = lock;
}
// 转账
void transfer(Account target, int amt){
// 此处检查所有对象共享的锁
synchronized(lock) {
if (this.balance > amt) {
this.balance -= amt;
target.balance += amt;
}
}
}
}
这个办法确实能解决问题,但是有点小瑕疵,它要求在创建 Account 对象的时候必须传入同一个对象,如果创建 Account 对象时,传入的 lock 不是同一个对象,那可就惨了,会出现锁自家门来保护他家资产的荒唐事。在真实的项目场景中,创建 Account 对象的代码很可能分散在多个工程中,传入共享的 lock 真的很难。所以,上面的方案缺乏实践的可行性,我们需要更好的方案。还真有,就是用 Account.class 作为共享的锁。Account.class 是所有 Account 对象共享的,而且这个对象是 Java 虚拟机在加载 Account 类的时候创建的,所以我们不用担心它的唯一性。使用 Account.class 作为共享的锁,我们就无需在创建 Account 对象时传入了,代码更简单。
class Account {
private int balance;
// 转账
void transfer(Account target, int amt){
synchronized(Account.class) {
if (this.balance > amt) {
this.balance -= amt;
target.balance += amt;
}
}
}
}
下面这幅图很直观地展示了我们是如何使用共享的锁 Account.class 来保护不同对象的临界区的。
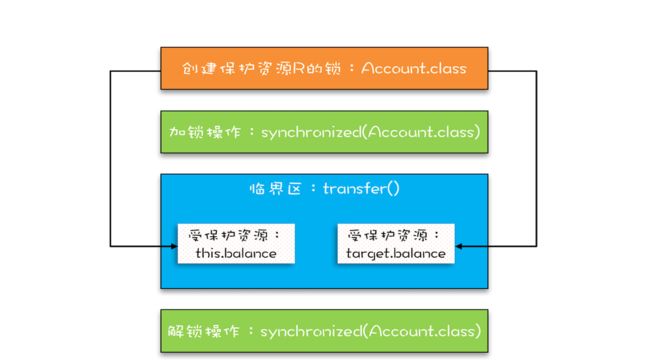
总结
相信你看完这篇文章后,对如何保护多个资源已经很有心得了,关键是要分析多个资源之间的关系。如果资源之间没有关系,很好处理,每个资源一把锁就可以了。如果资源之间有关联关系,就要选择一个粒度更大的锁,这个锁应该能够覆盖所有相关的资源。除此之外,还要梳理出有哪些访问路径,所有的访问路径都要设置合适的锁,这个过程可以类比一下门票管理。
我们再引申一下上面提到的关联关系,关联关系如果用更具体、更专业的语言来描述的话,其实是一种“原子性”特征,在前面的文章中,我们提到的原子性,主要是面向 CPU 指令的,转账操作的原子性则是属于是面向高级语言的,不过它们本质上是一样的。“原子性”的本质是什么?其实不是不可分割,不可分割只是外在表现,其本质是多个资源间有一致性的要求,操作的中间状态对外不可见。例如,在 32 位的机器上写 long 型变量有中间状态(只写了 64 位中的 32 位),在银行转账的操作中也有中间状态(账户 A 减少了 100,账户 B 还没来得及发生变化)。所以解决原子性问题,是要保证中间状态对外不可见。
课后思考
在第一个示例程序里,我们用了两把不同的锁来分别保护账户余额、账户密码,创建锁的时候,我们用的是:private final Object xxxLock = new Object();,如果账户余额用 this.balance 作为互斥锁,账户密码用 this.password 作为互斥锁,你觉得是否可以呢?
答案:不可以,因为每次修改时balance和password的值都会发生变化,当值被修改时相当于换锁,每次使用的锁都不一样,所以不能用来保护资源。切记:不能用可变对象来做锁。
05 | 一不小心就死锁了,怎么办?
内容来源:05 | 一不小心就死锁了,怎么办?-极客时间
在上一篇文章中,我们用 Account.class 作为互斥锁,来解决银行业务里面的转账问题,虽然这个方案不存在并发问题,但是所有账户的转账操作都是串行的,例如账户 A 转账户 B、账户 C 转账户 D 这两个转账操作现实世界里是可以并行的,但是在这个方案里却被串行化了,这样的话,性能太差。试想互联网支付盛行的当下,8 亿网民每人每天一笔交易,每天就是 8 亿笔交易;每笔交易都对应着一次转账操作,8 亿笔交易就是 8 亿次转账操作,也就是说平均到每秒就是近 1 万次转账操作,若所有的转账操作都串行,性能完全不能接受。那下面我们就尝试着把性能提升一下。
向现实世界要答案
现实世界里,账户转账操作是支持并发的,而且绝对是真正的并行,银行所有的窗口都可以做转账操作。只要我们能仿照现实世界做转账操作,串行的问题就解决了。我们试想在古代,没有信息化,账户的存在形式真的就是一个账本,而且每个账户都有一个账本,这些账本都统一存放在文件架上。银行柜员在给我们做转账时,要去文件架上把转出账本和转入账本都拿到手,然后做转账。这个柜员在拿账本的时候可能遇到以下三种情况:
-
文件架上恰好有转出账本和转入账本,那就同时拿走;
-
如果文件架上只有转出账本和转入账本之一,那这个柜员就先把文件架上有的账本拿到手,同时等着其他柜员把另外一个账本送回来;
-
转出账本和转入账本都没有,那这个柜员就等着两个账本都被送回来。
上面这个过程在编程的世界里怎么实现呢?其实用两把锁就实现了,转出账本一把,转入账本另一把。在 transfer() 方法内部,我们首先尝试锁定转出账户 this(先把转出账本拿到手),然后尝试锁定转入账户 target(再把转入账本拿到手),只有当两者都成功时,才执行转账操作。这个逻辑可以图形化为下图这个样子。

而至于详细的代码实现,如下所示。经过这样的优化后,账户 A 转账户 B 和账户 C 转账户 D 这两个转账操作就可以并行了。
class Account {
private int balance;
// 转账
void transfer(Account target, int amt){
// 锁定转出账户
synchronized(this) {
// 锁定转入账户
synchronized(target) {
if (this.balance > amt) {
this.balance -= amt;
target.balance += amt;
}
}
}
}
}
没有免费的午餐
上面的实现看上去很完美,并且也算是将锁用得出神入化了。相对于用 Account.class 作为互斥锁,锁定的范围太大,而我们锁定两个账户范围就小多了,这样的锁,上一章我们介绍过,叫细粒度锁。使用细粒度锁可以提高并行度,是性能优化的一个重要手段。这个时候可能你已经开始警觉了,使用细粒度锁这么简单,有这样的好事,是不是也要付出点什么代价啊?编写并发程序就需要这样时时刻刻保持谨慎。的确,使用细粒度锁是有代价的,这个代价就是可能会导致死锁。
在详细介绍死锁之前,我们先看看现实世界里的一种特殊场景。如果有客户找柜员张三做个转账业务:账户 A 转账户 B 100 元,此时另一个客户找柜员李四也做个转账业务:账户 B 转账户 A 100 元,于是张三和李四同时都去文件架上拿账本,这时候有可能凑巧张三拿到了账本 A,李四拿到了账本 B。张三拿到账本 A 后就等着账本 B(账本 B 已经被李四拿走),而李四拿到账本 B 后就等着账本 A(账本 A 已经被张三拿走),他们要等多久呢?他们会永远等待下去…因为张三不会把账本 A 送回去,李四也不会把账本 B 送回去。我们姑且称为死等吧。

现实世界里的死等,就是编程领域的死锁了。死锁的一个比较专业的定义是:一组互相竞争资源的线程因互相等待,导致“永久”阻塞的现象。上面转账的代码是怎么发生死锁的呢?我们假设线程 T1 执行账户 A 转账户 B 的操作,账户 A.transfer(账户 B);同时线程 T2 执行账户 B 转账户 A 的操作,账户 B.transfer(账户 A)。当 T1 和 T2 同时执行完①处的代码时,T1 获得了账户 A 的锁(对于 T1,this 是账户 A),而 T2 获得了账户 B 的锁(对于 T2,this 是账户 B)。之后 T1 和 T2 在执行②处的代码时,T1 试图获取账户 B 的锁时,发现账户 B 已经被锁定(被 T2 锁定),所以 T1 开始等待;T2 则试图获取账户 A 的锁时,发现账户 A 已经被锁定(被 T1 锁定),所以 T2 也开始等待。于是 T1 和 T2 会无期限地等待下去,也就是我们所说的死锁了。
class Account {
private int balance;
// 转账
void transfer(Account target, int amt){
// 锁定转出账户
synchronized(this){ ①
// 锁定转入账户
synchronized(target){ ②
if (this.balance > amt) {
this.balance -= amt;
target.balance += amt;
}
}
}
}
}
关于这种现象,我们还可以借助资源分配图来可视化锁的占用情况(资源分配图是个有向图,它可以描述资源和线程的状态)。其中,资源用方形节点表示,线程用圆形节点表示;资源中的点指向线程的边表示线程已经获得该资源,线程指向资源的边则表示线程请求资源,但尚未得到。转账发生死锁时的资源分配图就如下图所示,一个“各据山头死等”的尴尬局面。

如何预防死锁
并发程序一旦死锁,一般没有特别好的方法,很多时候我们只能重启应用。因此,解决死锁问题最好的办法还是规避死锁。那如何避免死锁呢?要避免死锁就需要分析死锁发生的条件,有个叫 Coffman 的牛人早就总结过了,只有以下这四个条件都发生时才会出现死锁:
-
互斥,共享资源 X 和 Y 只能被一个线程占用;
-
占有且等待,线程 T1 已经取得共享资源 X,在等待共享资源 Y 的时候,不释放共享资源 X;
-
不可抢占,其他线程不能强行抢占线程 T1 占有的资源;
-
循环等待,线程 T1 等待线程 T2 占有的资源,线程 T2 等待线程 T1 占有的资源,就是循环等待。
反过来分析,也就是说只要我们破坏其中一个,就可以成功避免死锁的发生。其中,互斥这个条件我们没有办法破坏,因为我们用锁为的就是互斥。不过其他三个条件都是有办法破坏掉的,到底如何做呢?
-
对于“占用且等待”这个条件,我们可以一次性申请所有的资源,这样就不存在等待了。
-
对于“不可抢占”这个条件,占用部分资源的线程进一步申请其他资源时,如果申请不到,可以主动释放它占有的资源,这样不可抢占这个条件就破坏掉了。
-
对于“循环等待”这个条件,可以靠按序申请资源来预防。所谓按序申请,是指资源是有线性顺序的,申请的时候可以先申请资源序号小的,再申请资源序号大的,这样线性化后自然就不存在循环了。
我们已经从理论上解决了如何预防死锁,那具体如何体现在代码上呢?下面我们就来尝试用代码实践一下这些理论。
1. 破坏占用且等待条件
从理论上讲,要破坏这个条件,可以一次性申请所有资源。在现实世界里,就拿前面我们提到的转账操作来讲,它需要的资源有两个,一个是转出账户,另一个是转入账户,当这两个账户同时被申请时,我们该怎么解决这个问题呢?可以增加一个账本管理员,然后只允许账本管理员从文件架上拿账本,也就是说柜员不能直接在文件架上拿账本,必须通过账本管理员才能拿到想要的账本。例如,张三同时申请账本 A 和 B,账本管理员如果发现文件架上只有账本 A,这个时候账本管理员是不会把账本 A 拿下来给张三的,只有账本 A 和 B 都在的时候才会给张三。这样就保证了“一次性申请所有资源”。

对应到编程领域,“同时申请”这个操作是一个临界区,我们也需要一个角色(Java 里面的类)来管理这个临界区,我们就把这个角色定为 Allocator。它有两个重要功能,分别是:同时申请资源 apply() 和同时释放资源 free()。账户 Account 类里面持有一个 Allocator 的单例(必须是单例,只能由一个人来分配资源)。当账户 Account 在执行转账操作的时候,首先向 Allocator 同时申请转出账户和转入账户这两个资源,成功后再锁定这两个资源;当转账操作执行完,释放锁之后,我们需通知 Allocator 同时释放转出账户和转入账户这两个资源。具体的代码实现如下。
class Allocator {
private List
2. 破坏不可抢占条件
破坏不可抢占条件看上去很简单,核心是要能够主动释放它占有的资源,这一点 synchronized 是做不到的。原因是 synchronized 申请资源的时候,如果申请不到,线程直接进入阻塞状态了,而线程进入阻塞状态,啥都干不了,也释放不了线程已经占有的资源。你可能会质疑,“Java 作为排行榜第一的语言,这都解决不了?”你的怀疑很有道理,Java 在语言层次确实没有解决这个问题,不过在 SDK 层面还是解决了的,java.util.concurrent 这个包下面提供的 Lock 是可以轻松解决这个问题的。关于这个话题,咱们后面会详细讲。
3. 破坏循环等待条件
破坏这个条件,需要对资源进行排序,然后按序申请资源。这个实现非常简单,我们假设每个账户都有不同的属性 id,这个 id 可以作为排序字段,申请的时候,我们可以按照从小到大的顺序来申请。比如下面代码中,①~⑥处的代码对转出账户(this)和转入账户(target)排序,然后按照序号从小到大的顺序锁定账户。这样就不存在“循环”等待了。
class Account {
private int id;
private int balance;
// 转账
void transfer(Account target, int amt){
Account left = this ①
Account right = target; ②
if (this.id > target.id) { ③
left = target; ④
right = this; ⑤
} ⑥
// 锁定序号小的账户
synchronized(left){
// 锁定序号大的账户
synchronized(right){
if (this.balance > amt){
this.balance -= amt;
target.balance += amt;
}
}
}
}
}
总结
当我们在编程世界里遇到问题时,应不局限于当下,可以换个思路,向现实世界要答案,利用现实世界的模型来构思解决方案,这样往往能够让我们的方案更容易理解,也更能够看清楚问题的本质。但是现实世界的模型有些细节往往会被我们忽视。因为在现实世界里,人太智能了,以致有些细节实在是显得太不重要了。在转账的模型中,我们为什么会忽视死锁问题呢?原因主要是在现实世界,我们会交流,并且会很智能地交流。而编程世界里,两个线程是不会智能地交流的。所以在利用现实模型建模的时候,我们还要仔细对比现实世界和编程世界里的各角色之间的差异。
我们今天这一篇文章主要讲了用细粒度锁来锁定多个资源时,要注意死锁的问题。这个就需要你能把它强化为一个思维定势,遇到这种场景,马上想到可能存在死锁问题。当你知道风险之后,才有机会谈如何预防和避免,因此,识别出风险很重要。预防死锁主要是破坏三个条件中的一个,有了这个思路后,实现就简单了。但仍需注意的是,有时候预防死锁成本也是很高的。例如上面转账那个例子,我们破坏占用且等待条件的成本就比破坏循环等待条件的成本高,破坏占用且等待条件,我们也是锁了所有的账户,而且还是用了死循环 while(!actr.apply(this, target));方法,不过好在 apply() 这个方法基本不耗时。 在转账这个例子中,破坏循环等待条件就是成本最低的一个方案。所以我们在选择具体方案的时候,还需要评估一下操作成本,从中选择一个成本最低的方案。
课后思考
我们上面提到:破坏占用且等待条件,我们也是锁了所有的账户,而且还是用了死循环 while(!actr.apply(this, target));这个方法,那它比 synchronized(Account.class) 有没有性能优势呢?
答案:synchronized(Account.class) 锁了Account类相关的所有操作,相当于文中说的包场,只要与Account有关联,通通需要等待当前线程操作完成;而while死循环的方式只锁定了当前操作的两个相关的对象,两种影响到的范围不同。
06 | 用“等待-通知”机制优化循环等待
内容来源:06 | 用“等待-通知”机制优化循环等待-极客时间
由上一篇文章你应该已经知道,在破坏占用且等待条件的时候,如果转出账本和转入账本不满足同时在文件架上这个条件,就用死循环的方式来循环等待,核心代码如下:
// 一次性申请转出账户和转入账户,直到成功 while(!actr.apply(this, target)) ;
如果 apply() 操作耗时非常短,而且并发冲突量也不大时,这个方案还挺不错的,因为这种场景下,循环上几次或者几十次就能一次性获取转出账户和转入账户了。但是如果 apply() 操作耗时长,或者并发冲突量大的时候,循环等待这种方案就不适用了,因为在这种场景下,可能要循环上万次才能获取到锁,太消耗 CPU 了。
其实在这种场景下,最好的方案应该是:如果线程要求的条件(转出账本和转入账本同在文件架上)不满足,则线程阻塞自己,进入等待状态;当线程要求的条件(转出账本和转入账本同在文件架上)满足后,通知等待的线程重新执行。其中,使用线程阻塞的方式就能避免循环等待消耗 CPU 的问题。那 Java 语言是否支持这种等待 - 通知机制呢?答案是:一定支持(毕竟占据排行榜第一那么久)。下面我们就来看看 Java 语言是如何支持等待 - 通知机制的。
完美的就医流程
在介绍 Java 语言如何支持等待 - 通知机制之前,我们先看一个现实世界里面的就医流程,因为它有着完善的等待 - 通知机制,所以对比就医流程,我们就能更好地理解和应用并发编程中的等待 - 通知机制。就医流程基本上是这样:
-
患者先去挂号,然后到就诊门口分诊,等待叫号;
-
当叫到自己的号时,患者就可以找大夫就诊了;
-
就诊过程中,大夫可能会让患者去做检查,同时叫下一位患者;
-
当患者做完检查后,拿检测报告重新分诊,等待叫号;
-
当大夫再次叫到自己的号时,患者再去找大夫就诊。
或许你已经发现了,这个有着完美等待 - 通知机制的就医流程,不仅能够保证同一时刻大夫只为一个患者服务,而且还能够保证大夫和患者的效率。与此同时你可能也会有疑问,“这个就医流程很复杂呀,我们前面描述的等待 - 通知机制相较而言是不是太简单了?”那这个复杂度是否是必须的呢?这个是必须的,我们不能忽视等待 - 通知机制中的一些细节。下面我们来对比看一下前面都忽视了哪些细节。
-
患者到就诊门口分诊,类似于线程要去获取互斥锁;当患者被叫到时,类似线程已经获取到锁了。
-
大夫让患者去做检查(缺乏检测报告不能诊断病因),类似于线程要求的条件没有满足。
-
患者去做检查,类似于线程进入等待状态;然后大夫叫下一个患者,这个步骤我们在前面的等待 - 通知机制中忽视了,这个步骤对应到程序里,本质是线程释放持有的互斥锁。
-
患者做完检查,类似于线程要求的条件已经满足;患者拿检测报告重新分诊,类似于线程需要重新获取互斥锁,这个步骤我们在前面的等待 - 通知机制中也忽视了。
所以加上这些至关重要的细节,综合一下,就可以得出一个完整的等待 - 通知机制:线程首先获取互斥锁,当线程要求的条件不满足时,释放互斥锁,进入等待状态;当要求的条件满足时,通知等待的线程,重新获取互斥锁。
用 synchronized 实现等待 - 通知机制
在 Java 语言里,等待 - 通知机制可以有多种实现方式,比如 Java 语言内置的 synchronized 配合 wait()、notify()、notifyAll() 这三个方法就能轻松实现。如何用 synchronized 实现互斥锁,你应该已经很熟悉了。在下面这个图里,左边有一个等待队列,同一时刻,只允许一个线程进入 synchronized 保护的临界区(这个临界区可以看作大夫的诊室),当有一个线程进入临界区后,其他线程就只能进入图中左边的等待队列里等待(相当于患者分诊等待)。这个等待队列和互斥锁是一对一的关系,每个互斥锁都有自己独立的等待队列。

在并发程序中,当一个线程进入临界区后,由于某些条件不满足,需要进入等待状态,Java 对象的 wait() 方法就能够满足这种需求。如上图所示,当调用 wait() 方法后,当前线程就会被阻塞,并且进入到右边的等待队列中,这个等待队列也是互斥锁的等待队列。 线程在进入等待队列的同时,会释放持有的互斥锁,线程释放锁后,其他线程就有机会获得锁,并进入临界区了。那线程要求的条件满足时,该怎么通知这个等待的线程呢?很简单,就是 Java 对象的 notify() 和 notifyAll() 方法。我在下面这个图里为你大致描述了这个过程,当条件满足时调用 notify(),会通知等待队列(互斥锁的等待队列)中的线程,告诉它条件曾经满足过。

为什么说是曾经满足过呢?因为 notify() 只能保证在通知时间点,条件是满足的。而被通知线程的执行时间点和通知的时间点基本上不会重合,所以当线程执行的时候,很可能条件已经不满足了(保不齐有其他线程插队)。这一点你需要格外注意。除此之外,还有一个需要注意的点,被通知的线程要想重新执行,仍然需要获取到互斥锁(因为曾经获取的锁在调用 wait() 时已经释放了)。
上面我们一直强调 wait()、notify()、notifyAll() 方法操作的等待队列是互斥锁的等待队列,所以如果 synchronized 锁定的是 this,那么对应的一定是 this.wait()、this.notify()、this.notifyAll();如果 synchronized 锁定的是 target,那么对应的一定是 target.wait()、target.notify()、target.notifyAll() 。而且 wait()、notify()、notifyAll() 这三个方法能够被调用的前提是已经获取了相应的互斥锁,所以我们会发现 wait()、notify()、notifyAll() 都是在 synchronized{}内部被调用的。如果在 synchronized{}外部调用,或者锁定的 this,而用 target.wait() 调用的话,JVM 会抛出一个运行时异常:java.lang.IllegalMonitorStateException。
小试牛刀:一个更好地资源分配器
等待 - 通知机制的基本原理搞清楚后,我们就来看看它如何解决一次性申请转出账户和转入账户的问题吧。在这个等待 - 通知机制中,我们需要考虑以下四个要素:
-
互斥锁:上一篇文章我们提到 Allocator 需要是单例的,所以我们可以用 this 作为互斥锁。
-
线程要求的条件:转出账户和转入账户都没有被分配过。
-
何时等待:线程要求的条件不满足就等待。
-
何时通知:当有线程释放账户时就通知。
将上面几个问题考虑清楚,可以快速完成下面的代码。需要注意的是我们使用了:
while(条件不满足) {
wait();
}
利用这种范式可以解决上面提到的条件曾经满足过这个问题。因为当 wait() 返回时,有可能条件已经发生变化了,曾经条件满足,但是现在已经不满足了,所以要重新检验条件是否满足。范式,意味着是经典做法,所以没有特殊理由不要尝试换个写法。后面在介绍“管程”的时候,我会详细介绍这个经典做法的前世今生。
class Allocator {
private List
尽量使用 notifyAll()
在上面的代码中,我用的是 notifyAll() 来实现通知机制,为什么不使用 notify() 呢?这二者是有区别的,notify() 是会随机地通知等待队列中的一个线程,而 notifyAll() 会通知等待队列中的所有线程。从感觉上来讲,应该是 notify() 更好一些,因为即便通知所有线程,也只有一个线程能够进入临界区。但那所谓的感觉往往都蕴藏着风险,实际上使用 notify() 也很有风险,它的风险在于可能导致某些线程永远不会被通知到。
假设我们有资源 A、B、C、D,线程 1 申请到了 AB,线程 2 申请到了 CD,此时线程 3 申请 AB,会进入等待队列(AB 分配给线程 1,线程 3 要求的条件不满足),线程 4 申请 CD 也会进入等待队列。我们再假设之后线程 1 归还了资源 AB,如果使用 notify() 来通知等待队列中的线程,有可能被通知的是线程 4,但线程 4 申请的是 CD,所以此时线程 4 还是会继续等待,而真正该唤醒的线程 3 就再也没有机会被唤醒了。所以除非经过深思熟虑,否则尽量使用 notifyAll()。
总结
等待 - 通知机制是一种非常普遍的线程间协作的方式。工作中经常看到有同学使用轮询的方式来等待某个状态,其实很多情况下都可以用今天我们介绍的等待 - 通知机制来优化。Java 语言内置的 synchronized 配合 wait()、notify()、notifyAll() 这三个方法可以快速实现这种机制,但是它们的使用看上去还是有点复杂,所以你需要认真理解等待队列和 wait()、notify()、notifyAll() 的关系。最好用现实世界做个类比,这样有助于你的理解。Java 语言的这种实现,背后的理论模型其实是管程,这个很重要,不过你不用担心,后面会有专门的一章来介绍管程。现在你只需要能够熟练使用就可以了。
课后思考
很多面试都会问到,wait() 方法和 sleep() 方法都能让当前线程挂起一段时间,那它们的区别是什么?现在你也试着回答一下吧。
答案:wait()方法与sleep()方法的不同之处在于,wait()方法会释放对象的“锁标志”。当调用某一对象的wait()方法后,会使当前线程暂停执行,并将当前线程放入对象等待池中,直到调用了notify()方法后,将从对象等待池中移出任意一个线程并放入锁标志等待池中,只有锁标志等待池中的线程可以获取锁标志,它们随时准备争夺锁的拥有权。当调用了某个对象的notifyAll()方法,会将对象等待池中的所有线程都移动到该对象的锁标志等待池。
sleep()方法需要指定等待的时间,它可以让当前正在执行的线程在指定的时间内暂停执行,进入阻塞状态,该方法既可以让其他同优先级或者高优先级的线程得到执行的机会,也可以让低优先级的线程得到执行机会。但是sleep()方法不会释放“锁标志”,也就是说如果有synchronized同步块,其他线程仍然不能访问共享数据。
简单理解:
-
相同点:都会让出CPU执行时间,等待再次调度!
-
不同点:
-
wait会释放锁资源,而sleep不会释放锁资源.
-
wait只能在同步方法和同步块中使用,而sleep任何地方都可以.
-
wait无需捕捉异常,而sleep需要.
-
wait是Object类的方法,而sleep是Thread的方法;
-
sleep方法调用的时候必须指定时间。
07 | 安全性、活跃性以及性能问题
内容来源:07 | 安全性、活跃性以及性能问题-极客时间
并发编程中我们需要注意的问题有很多,很庆幸前人已经帮我们总结过了,主要有三个方面,分别是:安全性问题、活跃性问题和性能问题。下面我就来一一介绍这些问题。
安全性问题
相信你一定听说过类似这样的描述:这个方法不是线程安全的,这个类不是线程安全的,等等。那什么是线程安全呢?其实本质上就是正确性,而正确性的含义就是程序按照我们期望的执行,不要让我们感到意外。在第一篇《可见性、原子性和有序性问题:并发编程 Bug 的源头》中,我们已经见识过很多诡异的 Bug,都是出乎我们预料的,它们都没有按照我们期望的执行。
那如何才能写出线程安全的程序呢?第一篇文章中已经介绍了并发 Bug 的三个主要源头:原子性问题、可见性问题和有序性问题。也就是说,理论上线程安全的程序,就要避免出现原子性问题、可见性问题和有序性问题。那是不是所有的代码都需要认真分析一遍是否存在这三个问题呢?当然不是,其实只有一种情况需要:存在共享数据并且该数据会发生变化,通俗地讲就是有多个线程会同时读写同一数据。那如果能够做到不共享数据或者数据状态不发生变化,不就能够保证线程的安全性了嘛。有不少技术方案都是基于这个理论的,例如线程本地存储(Thread Local Storage,TLS)、不变模式等等,后面我会详细介绍相关的技术方案是如何在 Java 语言中实现的。
但是,现实生活中,必须共享会发生变化的数据,这样的应用场景还是很多的。当多个线程同时访问同一数据,并且至少有一个线程会写这个数据的时候,如果我们不采取防护措施,那么就会导致并发 Bug,对此还有一个专业的术语,叫做数据竞争(Data Race)。比如,前面第一篇文章里有个 add10K() 的方法,当多个线程调用时候就会发生数据竞争,如下所示。
public class Test {
private long count = 0;
void add10K() {
int idx = 0;
while(idx++ < 10000) {
count += 1;
}
}
}
那是不是在访问数据的地方,我们加个锁保护一下就能解决所有的并发问题了呢?显然没有这么简单。例如,对于上面示例,我们稍作修改,增加两个被 synchronized 修饰的 get() 和 set() 方法, add10K() 方法里面通过 get() 和 set() 方法来访问 value 变量,修改后的代码如下所示。对于修改后的代码,所有访问共享变量 value 的地方,我们都增加了互斥锁,此时是不存在数据竞争的。但很显然修改后的 add10K() 方法并不是线程安全的。
public class Test {
private long count = 0;
synchronized long get(){
return count;
}
synchronized void set(long v){
count = v;
}
void add10K() {
int idx = 0;
while(idx++ < 10000) {
set(get()+1)
}
}
}
假设 count=0,当两个线程同时执行 get() 方法时,get() 方法会返回相同的值 0,两个线程执行 get()+1 操作,结果都是 1,之后两个线程再将结果 1 写入了内存。你本来期望的是 2,而结果却是 1。这种问题,有个官方的称呼,叫竞态条件(Race Condition)。所谓竞态条件,指的是程序的执行结果依赖线程执行的顺序。例如上面的例子,如果两个线程完全同时执行,那么结果是 1;如果两个线程是前后执行,那么结果就是 2。在并发环境里,线程的执行顺序是不确定的,如果程序存在竞态条件问题,那就意味着程序执行的结果是不确定的,而执行结果不确定这可是个大 Bug。
下面再结合一个例子来说明下竞态条件,就是前面文章中提到的转账操作。转账操作里面有个判断条件---转出金额不能大于账户余额,但在并发环境里面,如果不加控制,当多个线程同时对一个账号执行转出操作时,就有可能出现超额转出问题。假设账户 A 有余额 200,线程 1 和线程 2 都要从账户 A 转出 150,在下面的代码里,有可能线程 1 和线程 2 同时执行到第 6 行,这样线程 1 和线程 2 都会发现转出金额 150 小于账户余额 200,于是就会发生超额转出的情况。
class Account {
private int balance;
// 转账
void transfer(
Account target, int amt){
if (this.balance > amt) {
this.balance -= amt;
target.balance += amt;
}
}
}
所以你也可以按照下面这样来理解竞态条件。在并发场景中,程序的执行依赖于某个状态变量,也就是类似于下面这样:
if (状态变量 满足 执行条件) {
执行操作
}
当某个线程发现状态变量满足执行条件后,开始执行操作;可是就在这个线程执行操作的时候,其他线程同时修改了状态变量,导致状态变量不满足执行条件了。当然很多场景下,这个条件不是显式的,例如前面 addOne 的例子中,set(get()+1) 这个复合操作,其实就隐式依赖 get() 的结果。那面对数据竞争和竞态条件问题,又该如何保证线程的安全性呢?其实这两类问题,都可以用互斥这个技术方案,而实现互斥的方案有很多,CPU 提供了相关的互斥指令,操作系统、编程语言也会提供相关的 API。从逻辑上来看,我们可以统一归为:锁。前面几章我们也粗略地介绍了如何使用锁,相信你已经胸中有丘壑了,这里就不再赘述了,你可以结合前面的文章温故知新。
活跃性问题
所谓活跃性问题,指的是某个操作无法执行下去。我们常见的“死锁”就是一种典型的活跃性问题,当然除了死锁外,还有两种情况,分别是“活锁”和“饥饿”。
通过前面的学习你已经知道,发生“死锁”后线程会互相等待,而且会一直等待下去,在技术上的表现形式是线程永久地“阻塞”了。但有时线程虽然没有发生阻塞,但仍然会存在执行不下去的情况,这就是所谓的“活锁”。可以类比现实世界里的例子,路人甲从左手边出门,路人乙从右手边进门,两人为了不相撞,互相谦让,路人甲让路走右手边,路人乙也让路走左手边,结果是两人又相撞了。这种情况,基本上谦让几次就解决了,因为人会交流啊。可是如果这种情况发生在编程世界了,就有可能会一直没完没了地“谦让”下去,成为没有发生阻塞但依然执行不下去的“活锁”。
解决“活锁”的方案很简单,谦让时,尝试等待一个随机的时间就可以了。例如上面的那个例子,路人甲走左手边发现前面有人,并不是立刻换到右手边,而是等待一个随机的时间后,再换到右手边;同样,路人乙也不是立刻切换路线,也是等待一个随机的时间再切换。由于路人甲和路人乙等待的时间是随机的,所以同时相撞后再次相撞的概率就很低了。“等待一个随机时间”的方案虽然很简单,却非常有效,Raft 这样知名的分布式一致性算法中也用到了它。
那“饥饿”该怎么去理解呢?所谓“饥饿”指的是线程因无法访问所需资源而无法执行下去的情况。“不患寡,而患不均”,如果线程优先级“不均”,在 CPU 繁忙的情况下,优先级低的线程得到执行的机会很小,就可能发生线程“饥饿”;持有锁的线程,如果执行的时间过长,也可能导致“饥饿”问题。
解决“饥饿”问题的方案很简单,有三种方案:一是保证资源充足,二是公平地分配资源,三就是避免持有锁的线程长时间执行。这三个方案中,方案一和方案三的适用场景比较有限,因为很多场景下,资源的稀缺性是没办法解决的,持有锁的线程执行的时间也很难缩短。倒是方案二的适用场景相对来说更多一些。那如何公平地分配资源呢?在并发编程里,主要是使用公平锁。所谓公平锁,是一种先来后到的方案,线程的等待是有顺序的,排在等待队列前面的线程会优先获得资源。
性能问题
使用“锁”要非常小心,但是如果小心过度,也可能出“性能问题”。“锁”的过度使用可能导致串行化的范围过大,这样就不能够发挥多线程的优势了,而我们之所以使用多线程搞并发程序,为的就是提升性能。所以我们要尽量减少串行,那串行对性能的影响是怎么样的呢?假设串行百分比是 5%,我们用多核多线程相比单核单线程能提速多少呢?有个阿姆达尔(Amdahl)定律,代表了处理器并行运算之后效率提升的能力,它正好可以解决这个问题,具体公式如下:
S=1/[(1−p)+p/n]
公式里的 n 可以理解为 CPU 的核数,p 可以理解为并行百分比,那(1-p)就是串行百分比了,也就是我们假设的 5%。我们再假设 CPU 的核数(也就是 n)无穷大,那加速比 S 的极限就是 20。也就是说,如果我们的串行率是 5%,那么我们无论采用什么技术,最高也就只能提高 20 倍的性能。所以使用锁的时候一定要关注对性能的影响。 那怎么才能避免锁带来的性能问题呢?这个问题很复杂,Java SDK 并发包里之所以有那么多东西,有很大一部分原因就是要提升在某个特定领域的性能。
不过从方案层面,我们可以这样来解决这个问题。
第一,既然使用锁会带来性能问题,那最好的方案自然就是使用无锁的算法和数据结构了。在这方面有很多相关的技术,例如线程本地存储 (Thread Local Storage, TLS)、写入时复制 (Copy-on-write)、乐观锁等;Java 并发包里面的原子类也是一种无锁的数据结构;Disruptor 则是一个无锁的内存队列,性能都非常好……
第二,减少锁持有的时间。互斥锁本质上是将并行的程序串行化,所以要增加并行度,一定要减少持有锁的时间。这个方案具体的实现技术也有很多,例如使用细粒度的锁,一个典型的例子就是 Java 并发包里的 ConcurrentHashMap,它使用了所谓分段锁的技术(这个技术后面我们会详细介绍);还可以使用读写锁,也就是读是无锁的,只有写的时候才会互斥。性能方面的度量指标有很多,我觉得有三个指标非常重要,就是:吞吐量、延迟和并发量。
-
吞吐量:指的是单位时间内能处理的请求数量。吞吐量越高,说明性能越好。
-
延迟:指的是从发出请求到收到响应的时间。延迟越小,说明性能越好。
-
并发量:指的是能同时处理的请求数量,一般来说随着并发量的增加、延迟也会增加。所以延迟这个指标,一般都会是基于并发量来说的。例如并发量是 1000 的时候,延迟是 50 毫秒。
总结
并发编程是一个复杂的技术领域,微观上涉及到原子性问题、可见性问题和有序性问题,宏观则表现为安全性、活跃性以及性能问题。我们在设计并发程序的时候,主要是从宏观出发,也就是要重点关注它的安全性、活跃性以及性能。安全性方面要注意数据竞争和竞态条件,活跃性方面需要注意死锁、活锁、饥饿等问题,性能方面我们虽然介绍了两个方案,但是遇到具体问题,你还是要具体分析,根据特定的场景选择合适的数据结构和算法。
要解决问题,首先要把问题分析清楚。同样,要写好并发程序,首先要了解并发程序相关的问题,经过这 7 章的内容,相信你一定对并发程序相关的问题有了深入的理解,同时对并发程序也一定心存敬畏,因为一不小心就出问题了。不过这恰恰也是一个很好的开始,因为你已经学会了分析并发问题,然后解决并发问题也就不远了。
课后思考
Java 语言提供的 Vector 是一个线程安全的容器,有同学写了下面的代码,你看看是否存在并发问题呢?
void addIfNotExist(Vector v, Object o){
if(!v.contains(o)) {
v.add(o);
}
}
答案:Vector实现线程安全是通过给主要的写方法加了synchronized,类似contains这样的读方法并没有synchronized,该题的问题就出在不是线程安全的contains方法,两个线程如果同时执行到if(!v.contains(o)) 是可以都通过的,这时就会执行两次add方法,重复添加。也就是老师说的竞态条件。就算contains方法加锁了也会有问题 , 第一个线程去判断是否满足 , 满足通过,刚准备add,cup切换线程执行,第二个线程也去判断也满足,然后一个add了,另外一个也跟着add了,要保证判断和执行是一个原子操作。
补充:串行百分比一般怎么得出来呢(依据是什么)
可以这么理解:临界区都是串行的,非临界区都是并行的,用单线程执行临界区的时间/用单线程执行(临界区+非临界区)的时间就是串行百分比。
08 | 管程:并发编程的万能钥匙
内容来源:08 | 管程:并发编程的万能钥匙-极客时间
Java 语言在 1.5 之前,提供的唯一的并发原语就是管程,而且 1.5 之后提供的 SDK 并发包,也是以管程技术为基础的。除此之外,C/C++、C# 等高级语言也都支持管程。可以这么说,管程就是一把解决并发问题的万能钥匙。
什么是管程
不知道你是否曾思考过这个问题:为什么 Java 在 1.5 之前仅仅提供了 synchronized 关键字及 wait()、notify()、notifyAll() 这三个看似从天而降的方法?在刚接触 Java 的时候,我以为它会提供信号量这种编程原语,因为操作系统原理课程告诉我,用信号量能解决所有并发问题,结果我发现不是。后来我找到了原因:Java 采用的是管程技术,synchronized 关键字及 wait()、notify()、notifyAll() 这三个方法都是管程的组成部分。而管程和信号量是等价的,所谓等价指的是用管程能够实现信号量,也能用信号量实现管程。但是管程更容易使用,所以 Java 选择了管程。
管程,对应的英文是 Monitor,很多 Java 领域的同学都喜欢将其翻译成“监视器”,这是直译。操作系统领域一般都翻译成“管程”,这个是意译,而我自己也更倾向于使用“管程”。所谓管程,指的是管理共享变量以及对共享变量的操作过程,让他们支持并发。翻译为 Java 领域的语言,就是管理类的成员变量和成员方法,让这个类是线程安全的。那管程是怎么管的呢?
MESA 模型
在管程的发展史上,先后出现过三种不同的管程模型,分别是:Hasen 模型、Hoare 模型和 MESA 模型。其中,现在广泛应用的是 MESA 模型,并且 Java 管程的实现参考的也是 MESA 模型。所以今天我们重点介绍一下 MESA 模型。
在并发编程领域,有两大核心问题:一个是互斥,即同一时刻只允许一个线程访问共享资源;另一个是同步,即线程之间如何通信、协作。这两大问题,管程都是能够解决的。我们先来看看管程是如何解决互斥问题的。
管程解决互斥问题的思路很简单,就是将共享变量及其对共享变量的操作统一封装起来。假如我们要实现一个线程安全的阻塞队列,一个最直观的想法就是:将线程不安全的队列封装起来,对外提供线程安全的操作方法,例如入队操作和出队操作。
利用管程,可以快速实现这个直观的想法。在下图中,管程 X 将共享变量 queue 这个线程不安全的队列和相关的操作入队操作 enq()、出队操作 deq() 都封装起来了;线程 A 和线程 B 如果想访问共享变量 queue,只能通过调用管程提供的 enq()、deq() 方法来实现;enq()、deq() 保证互斥性,只允许一个线程进入管程。
不知你有没有发现,管程模型和面向对象高度契合的。估计这也是 Java 选择管程的原因吧。而我在前面章节介绍的互斥锁用法,其背后的模型其实就是它。

那管程如何解决线程间的同步问题呢?这个就比较复杂了,不过你可以借鉴一下我们曾经提到过的就医流程,它可以帮助你快速地理解这个问题。为进一步便于你理解,在下面,我展示了一幅 MESA 管程模型示意图,它详细描述了 MESA 模型的主要组成部分。
在管程模型里,共享变量和对共享变量的操作是被封装起来的,图中最外层的框就代表封装的意思。框的上面只有一个入口,并且在入口旁边还有一个入口等待队列。当多个线程同时试图进入管程内部时,只允许一个线程进入,其他线程则在入口等待队列中等待。这个过程类似就医流程的分诊,只允许一个患者就诊,其他患者都在门口等待。管程里还引入了条件变量的概念,而且每个条件变量都对应有一个等待队列,如下图,条件变量 A 和条件变量 B 分别都有自己的等待队列。

那条件变量和条件变量等待队列的作用是什么呢?其实就是解决线程同步问题。你可以结合上面提到的阻塞队列的例子加深一下理解(阻塞队列的例子,是用管程来实现线程安全的阻塞队列,这个阻塞队列和管程内部的等待队列没有关系,本文中一定要注意阻塞队列和等待队列是不同的)。
假设有个线程 T1 执行阻塞队列的出队操作,执行出队操作,需要注意有个前提条件,就是阻塞队列不能是空的(空队列只能出 Null 值,是不允许的),阻塞队列不空这个前提条件对应的就是管程里的条件变量。 如果线程 T1 进入管程后恰好发现阻塞队列是空的,那怎么办呢?等待啊,去哪里等呢?就去条件变量对应的等待队列里面等。此时线程 T1 就去“队列不空”这个条件变量的等待队列中等待。这个过程类似于大夫发现你要去验个血,于是给你开了个验血的单子,你呢就去验血的队伍里排队。线程 T1 进入条件变量的等待队列后,是允许其他线程进入管程的。这和你去验血的时候,医生可以给其他患者诊治,道理都是一样的。再假设之后另外一个线程 T2 执行阻塞队列的入队操作,入队操作执行成功之后,“阻塞队列不空”这个条件对于线程 T1 来说已经满足了,此时线程 T2 要通知 T1,告诉它需要的条件已经满足了。当线程 T1 得到通知后,会从等待队列里面出来,但是出来之后不是马上执行,而是重新进入到入口等待队列里面。这个过程类似你验血完,回来找大夫,需要重新分诊。
条件变量及其等待队列我们讲清楚了,下面再说说 wait()、notify()、notifyAll() 这三个操作。前面提到线程 T1 发现“阻塞队列不空”这个条件不满足,需要进到对应的等待队列里等待。这个过程就是通过调用 wait() 来实现的。如果我们用对象 A 代表“阻塞队列不空”这个条件,那么线程 T1 需要调用 A.wait()。同理当“阻塞队列不空”这个条件满足时,线程 T2 需要调用 A.notify() 来通知 A 等待队列中的一个线程,此时这个等待队列里面只有线程 T1。至于 notifyAll() 这个方法,它可以通知等待队列中的所有线程。这里我还是来一段代码再次说明一下吧。下面的代码用管程实现了一个线程安全的阻塞队列(再次强调:这个阻塞队列和管程内部的等待队列没关系,示例代码只是用管程来实现阻塞队列,而不是解释管程内部等待队列的实现原理)。阻塞队列有两个操作分别是入队和出队,这两个方法都是先获取互斥锁,类比管程模型中的入口。
-
对于阻塞队列的入队操作,如果阻塞队列已满,就需要等待直到阻塞队列不满,所以这里用了notFull.await();
-
对于阻塞出队操作,如果阻塞队列为空,就需要等待直到阻塞队列不空,所以就用了notEmpty.await();
-
如果入队成功,那么阻塞队列就不空了,就需要通知条件变量:阻塞队列不空notEmpty对应的等待队列。
-
如果出队成功,那就阻塞队列就不满了,就需要通知条件变量:阻塞队列不满notFull对应的等待队列。
public class BlockedQueue{ final Lock lock = new ReentrantLock(); // 条件变量:队列不满 final Condition notFull = lock.newCondition(); // 条件变量:队列不空 final Condition notEmpty = lock.newCondition(); // 入队 void enq(T x) { lock.lock(); try { while (队列已满){ // 等待队列不满 notFull.await(); } // 省略入队操作... //入队后,通知可出队 notEmpty.signal(); }finally { lock.unlock(); } } // 出队 void deq(){ lock.lock(); try { while (队列已空){ // 等待队列不空 notEmpty.await(); } // 省略出队操作... //出队后,通知可入队 notFull.signal(); }finally { lock.unlock(); } } }
在这段示例代码中,我们用了 Java 并发包里面的 Lock 和 Condition,如果你看着吃力,也没关系,后面我们还会详细介绍,这个例子只是先让你明白条件变量及其等待队列是怎么回事。需要注意的是:await() 和前面我们提到的 wait() 语义是一样的;signal() 和前面我们提到的 notify() 语义是一样的。
wait() 的正确姿势
但是有一点,需要再次提醒,对于 MESA 管程来说,有一个编程范式,就是需要在一个 while 循环里面调用 wait()。这个是 MESA 管程特有的。
while(条件不满足) {
wait();
}
Hasen 模型、Hoare 模型和 MESA 模型的一个核心区别就是当条件满足后,如何通知相关线程。管程要求同一时刻只允许一个线程执行,那当线程 T2 的操作使线程 T1 等待的条件满足时,T1 和 T2 究竟谁可以执行呢?
-
Hasen 模型里面,要求 notify() 放在代码的最后,这样 T2 通知完 T1 后,T2 就结束了,然后 T1 再执行,这样就能保证同一时刻只有一个线程执行。
-
Hoare 模型里面,T2 通知完 T1 后,T2 阻塞,T1 马上执行;等 T1 执行完,再唤醒 T2,也能保证同一时刻只有一个线程执行。但是相比 Hasen 模型,T2 多了一次阻塞唤醒操作。
-
MESA 管程里面,T2 通知完 T1 后,T2 还是会接着执行,T1 并不立即执行,仅仅是从条件变量的等待队列进到入口等待队列里面。这样做的好处是 notify() 不用放到代码的最后,T2 也没有多余的阻塞唤醒操作。但是也有个副作用,就是当 T1 再次执行的时候,可能曾经满足的条件,现在已经不满足了,所以需要以循环方式检验条件变量。
notify() 何时可以使用
还有一个需要注意的地方,就是 notify() 和 notifyAll() 的使用,前面章节,我曾经介绍过,除非经过深思熟虑,否则尽量使用 notifyAll()。那什么时候可以使用 notify() 呢?需要满足以下三个条件:
-
所有等待线程拥有相同的等待条件;
-
所有等待线程被唤醒后,执行相同的操作;
-
只需要唤醒一个线程。
比如上面阻塞队列的例子中,对于“阻塞队列不满”这个条件变量,其等待线程都是在等待“阻塞队列不满”这个条件,反映在代码里就是下面这 3 行代码。对所有等待线程来说,都是执行这 3 行代码,重点是 while 里面的等待条件是完全相同的。
while (阻塞队列已满){
// 等待队列不满
notFull.await();
}
所有等待线程被唤醒后执行的操作也是相同的,都是下面这几行:
// 省略入队操作... // 入队后,通知可出队 notEmpty.signal();
同时也满足第 3 条,只需要唤醒一个线程。所以上面阻塞队列的代码,使用 signal() 是可以的。
总结
管程是一个解决并发问题的模型,你可以参考医院就医的流程来加深理解。理解这个模型的重点在于理解条件变量及其等待队列的工作原理。Java 参考了 MESA 模型,语言内置的管程(synchronized)对 MESA 模型进行了精简。MESA 模型中,条件变量可以有多个,Java 语言内置的管程里只有一个条件变量。具体如下图所示。

Java 内置的管程方案(synchronized)使用简单,synchronized 关键字修饰的代码块,在编译期会自动生成相关加锁和解锁的代码,但是仅支持一个条件变量;而 Java SDK 并发包实现的管程支持多个条件变量,不过并发包里的锁,需要开发人员自己进行加锁和解锁操作。
课后思考
wait() 方法,在 Hasen 模型和 Hoare 模型里面,都是没有参数的,而在 MESA 模型里面,增加了超时参数,你觉得这个参数有必要吗?
答案:有必要,在MESA 模型中,条件等待队列的线程如果是在notify()通知时,由于其只能唤醒一个线程,有可能永远不会处理一些低优先级的线程,所以可能造成线程“饥饿”。但是也注意一下wait如果传参数为零的话,不代表着立即唤醒进入入口队列,而是一直等待被唤醒,没有超时设置。线程wait超时后,会重新被放入入口队列,去争取锁。
网友的总结:
-
本节说的可能并不好。该篇我看了三遍也没能完全看懂,于是自己搜索java管程相关的技术文章,才大致对管程有了个认知,总结如下:
-
1.管程是一种概念,任何语言都可以通用。
-
2.在java中,每个加锁的对象都绑定着一个管程(监视器)
-
3.线程访问加锁对象,就是去拥有一个监视器的过程。如一个病人去门诊室看医生,医生是共享资源,门锁锁定医生,病人去看医生,就是访问医生这个共享资源,门诊室其实是监视器(管程)。
-
4.所有线程访问共享资源,都需要先拥有监视器。就像所有病人看病都需要先拥有进入门诊室的资格。
-
5.监视器至少有两个等待队列。一个是进入监视器的等待队列一个是条件变量对应的等待队列。后者可以有多个。就像一个病人进入门诊室诊断后,需要去验血,那么它需要去抽血室排队等待。另外一个病人心脏不舒服,需要去拍胸片,去拍摄室等待。
-
6.监视器要求的条件满足后,位于条件变量下等待的线程需要重新在门诊室门外排队,等待进入监视器。就像抽血的那位,抽完后,拿到了化验单,然后,重新回到门诊室等待,然后进入看病,然后退出,医生通知下一位进入。
-
总结起来就是,管程就是一个对象监视器。任何线程想要访问该资源,就要排队进入监控范围。进入之后,接受检查,不符合条件,则要继续等待,直到被通知,然后继续进入监视器。
-
-
为什么用while? 当线程被唤醒后,是从wait命令后开始执行的(不是从头开始执行该方法,这点上老师的示意图容易让人产生歧义),而执行时间点往往跟唤醒时间点不一致,所以条件变量此时不一定满足了,所以通过while循环可以再验证,而if条件却做不到,它只能从wait命令后开始执行,所以要用while。
-
三种模型总结:
-
hasen是执行完,再去唤醒另外一个线程,能够保证线程的执行。
-
hoare是中断当前线程,唤醒另外一个线程,执行完再去唤醒,也能够保证完成。
-
mesa是进入等待队列,不一定有机会能够执行。
-
-
老师,针对条件变量的while循环,还是不太理解,您说是范式,那它一定是为了解决特定的场景而强烈推荐的,也有评论说是为了解决虚假唤醒,但唤醒后,不也是从条件的等待队列进入到入口的等待队列,抢到锁后,重新进行条件变量的判断,用if完全可以啊,为什么必须是while,并且是范式?
-
code1;
if (条件不满足)
wait()
code2;
当调用wait()时,阻塞。被唤醒时,就直接执行code2了,没机会重新判断。
-
-
管程的组成锁和0或者多个条件变量,java用两种方式实现了管程①synchronized+wait、notify、notifyAll②lock+内部的condition,第一种只支持一个条件变量,即wait,调用wait时会将其加到等待队列中,被notify时,会随机通知一个线程加到获取锁的等待队列中,第二种相对第一种condition支持中断和增加了时间的等待,lock需要自己进行加锁解锁,更加灵活,两个都是可重入锁,但是lock支持公平和非公平锁,synchronized支持非公平锁。
09 | Java线程(上):Java线程的生命周期
内容来源:09 | Java线程(上):Java线程的生命周期 (geekbang.org)
在 Java 领域,实现并发程序的主要手段就是多线程。线程是操作系统里的一个概念,虽然各种不同的开发语言如 Java、C# 等都对其进行了封装,但是万变不离操作系统。Java 语言里的线程本质上就是操作系统的线程,它们是一一对应的。
在操作系统层面,线程也有“生老病死”,专业的说法叫有生命周期。对于有生命周期的事物,要学好它,思路非常简单,只要能搞懂生命周期中各个节点的状态转换机制就可以了。
虽然不同的开发语言对于操作系统线程进行了不同的封装,但是对于线程的生命周期这部分,基本上是雷同的。所以,我们可以先来了解一下通用的线程生命周期模型,这部分内容也适用于很多其他编程语言;然后再详细有针对性地学习一下 Java 中线程的生命周期。
通用的线程生命周期
通用的线程生命周期基本上可以用下图这个“五态模型”来描述。这五态分别是:初始状态、可运行状态、运行状态、休眠状态和终止状态。

这“五态模型”的详细情况如下所示。
-
初始状态,指的是线程已经被创建,但是还不允许分配 CPU 执行。这个状态属于编程语言特有的,不过这里所谓的被创建,仅仅是在编程语言层面被创建,而在操作系统层面,真正的线程还没有创建。
-
可运行状态,指的是线程可以分配 CPU 执行。在这种状态下,真正的操作系统线程已经被成功创建了,所以可以分配 CPU 执行。
-
当有空闲的 CPU 时,操作系统会将其分配给一个处于可运行状态的线程,被分配到 CPU 的线程的状态就转换成了运行状态。
-
运行状态的线程如果调用一个阻塞的 API(例如以阻塞方式读文件)或者等待某个事件(例如条件变量),那么线程的状态就会转换到休眠状态,同时释放 CPU 使用权,休眠状态的线程永远没有机会获得 CPU 使用权。当等待的事件出现了,线程就会从休眠状态转换到可运行状态。
-
线程执行完或者出现异常就会进入终止状态,终止状态的线程不会切换到其他任何状态,进入终止状态也就意味着线程的生命周期结束了。
这五种状态在不同编程语言里会有简化合并。例如,C 语言的 POSIX Threads 规范,就把初始状态和可运行状态合并了;Java 语言里则把可运行状态和运行状态合并了,这两个状态在操作系统调度层面有用,而 JVM 层面不关心这两个状态,因为 JVM 把线程调度交给操作系统处理了。除了简化合并,这五种状态也有可能被细化,比如,Java 语言里就细化了休眠状态(这个下面我们会详细讲解)。
Java中线程的生命周期
介绍完通用的线程生命周期模型,想必你已经对线程的“生老病死”有了一个大致的了解。那接下来我们就来详细看看 Java 语言里的线程生命周期是什么样的。Java 语言中线程共有六种状态,分别是:
-
NEW(初始化状态)
-
RUNNABLE(可运行 / 运行状态)
-
BLOCKED(阻塞状态)
-
WAITING(无时限等待)
-
TIMED_WAITING(有时限等待)
-
TERMINATED(终止状态)
这看上去挺复杂的,状态类型也比较多。但其实在操作系统层面,Java 线程中的 BLOCKED、WAITING、TIMED_WAITING 是一种状态,即前面我们提到的休眠状态。也就是说只要 Java 线程处于这三种状态之一,那么这个线程就永远没有 CPU 的使用权。所以 Java 线程的生命周期可以简化为下图:

其中,BLOCKED、WAITING、TIMED_WAITING 可以理解为线程导致休眠状态的三种原因。那具体是哪些情形会导致线程从 RUNNABLE 状态转换到这三种状态呢?而这三种状态又是何时转换回 RUNNABLE 的呢?以及 NEW、TERMINATED 和 RUNNABLE 状态是如何转换的?
1. RUNNABLE 与 BLOCKED 的状态转换
只有一种场景会触发这种转换,就是线程等待 synchronized 的隐式锁。synchronized 修饰的方法、代码块同一时刻只允许一个线程执行,其他线程只能等待,这种情况下,等待的线程就会从 RUNNABLE 转换到 BLOCKED 状态。而当等待的线程获得 synchronized 隐式锁时,就又会从 BLOCKED 转换到 RUNNABLE 状态。
如果你熟悉操作系统线程的生命周期的话,可能会有个疑问:线程调用阻塞式 API 时,是否会转换到 BLOCKED 状态呢?在操作系统层面,线程是会转换到休眠状态的,但是在 JVM 层面,Java 线程的状态不会发生变化,也就是说 Java 线程的状态会依然保持 RUNNABLE 状态。JVM 层面并不关心操作系统调度相关的状态,因为在 JVM 看来,等待 CPU 使用权(操作系统层面此时处于可执行状态)与等待 I/O(操作系统层面此时处于休眠状态)没有区别,都是在等待某个资源,所以都归入了 RUNNABLE 状态。而我们平时所谓的 Java 在调用阻塞式 API 时,线程会阻塞,指的是操作系统线程的状态,并不是 Java 线程的状态。
2. RUNNABLE 与 WAITING 的状态转换
总体来说,有三种场景会触发这种转换:
第一种场景,获得 synchronized 隐式锁的线程,调用无参数的 Object.wait() 方法。其中,wait() 方法我们在上一篇讲解管程的时候已经深入介绍过了,这里就不再赘述。
第二种场景,调用无参数的 Thread.join() 方法。其中的 join() 是一种线程同步方法,例如有一个线程对象 thread A,当调用 A.join() 的时候,执行这条语句的线程会等待 thread A 执行完,而等待中的这个线程,其状态会从 RUNNABLE 转换到 WAITING。当线程 thread A 执行完,原来等待它的线程又会从 WAITING 状态转换到 RUNNABLE。
第三种场景,调用 LockSupport.park() 方法。其中的 LockSupport 对象,也许你有点陌生,其实 Java 并发包中的锁,都是基于它实现的。调用 LockSupport.park() 方法,当前线程会阻塞,线程的状态会从 RUNNABLE 转换到 WAITING。调用 LockSupport.unpark(Thread thread) 可唤醒目标线程,目标线程的状态又会从 WAITING 状态转换到 RUNNABLE。
3. RUNNABLE 与 TIMED_WAITING 的状态转换
有五种场景会触发这种转换:
-
调用带超时参数的 Thread.sleep(long millis) 方法;
-
获得 synchronized 隐式锁的线程,调用带超时参数的 Object.wait(long timeout) 方法;
-
调用带超时参数的 Thread.join(long millis) 方法;
-
调用带超时参数的 LockSupport.parkNanos(Object blocker, long deadline) 方法;
-
调用带超时参数的 LockSupport.parkUntil(long deadline) 方法。
这里你会发现 TIMED_WAITING 和 WAITING 状态的区别,仅仅是触发条件多了超时参数。
4. 从 NEW 到 RUNNABLE 状态
Java 刚创建出来的 Thread 对象就是 NEW 状态,而创建 Thread 对象主要有两种方法。一种是继承 Thread 对象,重写 run() 方法。示例代码如下:
// 自定义线程对象
class MyThread extends Thread {
public void run() {
// 线程需要执行的代码
......
}
}
// 创建线程对象
MyThread myThread = new MyThread();
另一种是实现 Runnable 接口,重写 run() 方法,并将该实现类作为创建 Thread 对象的参数。示例代码如下:
// 实现Runnable接口
class Runner implements Runnable {
@Override
public void run() {
// 线程需要执行的代码
......
}
}
// 创建线程对象
Thread thread = new Thread(new Runner());
NEW 状态的线程,不会被操作系统调度,因此不会执行。Java 线程要执行,就必须转换到 RUNNABLE 状态。从 NEW 状态转换到 RUNNABLE 状态很简单,只要调用线程对象的 start() 方法就可以了,示例代码如下:
MyThread myThread = new MyThread(); // 从NEW状态转换到RUNNABLE状态 myThread.start();
5. 从 RUNNABLE 到 TERMINATED 状态
线程执行完 run() 方法后,会自动转换到 TERMINATED 状态,当然如果执行 run() 方法的时候异常抛出,也会导致线程终止。有时候我们需要强制中断 run() 方法的执行,例如 run() 方法访问一个很慢的网络,我们等不下去了,想终止怎么办呢?Java 的 Thread 类里面倒是有个 stop() 方法,不过已经标记为 @Deprecated,所以不建议使用了。正确的姿势其实是调用 interrupt() 方法。
那 stop() 和 interrupt() 方法的主要区别是什么呢?
-
stop() 方法会真的杀死线程,不给线程喘息的机会,如果线程持有 ReentrantLock 锁,被 stop() 的线程并不会自动调用 ReentrantLock 的 unlock() 去释放锁,那其他线程就再也没机会获得 ReentrantLock 锁,这实在是太危险了。所以该方法就不建议使用了,类似的方法还有 suspend() 和 resume() 方法,这两个方法同样也都不建议使用了,所以这里也就不多介绍了。
-
而 interrupt() 方法就温柔多了,interrupt() 方法仅仅是通知线程,线程有机会执行一些后续操作,同时也可以无视这个通知。被 interrupt 的线程,是怎么收到通知的呢?一种是异常,另一种是主动检测。
-
当线程 A 处于 WAITING、TIMED_WAITING 状态时,如果其他线程调用线程 A 的 interrupt() 方法,会使线程 A 返回到 RUNNABLE 状态,同时线程 A 的代码会触发 InterruptedException 异常。上面我们提到转换到 WAITING、TIMED_WAITING 状态的触发条件,都是调用了类似 wait()、join()、sleep() 这样的方法,我们看这些方法的签名,发现都会 throws InterruptedException 这个异常。这个异常的触发条件就是:其他线程调用了该线程的 interrupt() 方法。
-
当线程 A 处于 RUNNABLE 状态时,并且阻塞在 java.nio.channels.InterruptibleChannel 上时,如果其他线程调用线程 A 的 interrupt() 方法,线程 A 会触发 java.nio.channels.ClosedByInterruptException 这个异常;而阻塞在 java.nio.channels.Selector 上时,如果其他线程调用线程 A 的 interrupt() 方法,线程 A 的 java.nio.channels.Selector 会立即返回。
上面这两种情况属于被中断的线程通过异常的方式获得了通知。还有一种是主动检测,如果线程处于 RUNNABLE 状态,并且没有阻塞在某个 I/O 操作上,例如中断计算圆周率的线程 A,这时就得依赖线程 A 主动检测中断状态了。如果其他线程调用线程 A 的 interrupt() 方法,那么线程 A 可以通过 isInterrupted() 方法,检测是不是自己被中断了。
总结
理解 Java 线程的各种状态以及生命周期对于诊断多线程 Bug 非常有帮助,多线程程序很难调试,出了 Bug 基本上都是靠日志,靠线程 dump 来跟踪问题,分析线程 dump 的一个基本功就是分析线程状态,大部分的死锁、饥饿、活锁问题都需要跟踪分析线程的状态。同时,本文介绍的线程生命周期具备很强的通用性,对于学习其他语言的多线程编程也有很大的帮助。
你可以通过 jstack 命令或者Java VisualVM这个可视化工具将 JVM 所有的线程栈信息导出来,完整的线程栈信息不仅包括线程的当前状态、调用栈,还包括了锁的信息。例如,我曾经写过一个死锁的程序,导出的线程栈明确告诉我发生了死锁,并且将死锁线程的调用栈信息清晰地显示出来了(如下图)。导出线程栈,分析线程状态是诊断并发问题的一个重要工具。

课后思考
下面代码的本意是当前线程被中断之后,退出while(true),你觉得这段代码是否正确呢?
Thread th = Thread.currentThread();
while(true) {
if(th.isInterrupted()) {
break;
}
// 省略业务代码无数
try {
Thread.sleep(100);
}catch (InterruptedException e){
e.printStackTrace();
}
}
答案:不正确,可能出现无限循环,不能中断循环。当发起中断之后,Thread.sleep(100)会抛出一个InterruptedException异常,try catch捕捉此异常,而抛出这个异常会清除当前线程的中断标识,导致th.isInterrupted()一直都是返回false的,所以应该重置一下中断标示。也可以将异常捕获放在while循环外面。
Thread th = Thread.currentThread();
while(true) {
if(th.isInterrupted()) {
break;
}
// 省略业务代码无数
try {
Thread.sleep(100);
}catch (InterruptedException e){
Thread.currentThread().interrupt();
e.printStackTrace();
}
}
10 | Java线程(中):创建多少线程才是合适的?
内容来源:10 | Java线程(中):创建多少线程才是合适的?-极客时间 (geekbang.org)
在 Java 领域,实现并发程序的主要手段就是多线程,使用多线程还是比较简单的,但是使用多少个线程却是个困难的问题。工作中,经常有人问,“各种线程池的线程数量调整成多少是合适的?”或者“Tomcat 的线程数、Jdbc 连接池的连接数是多少?”等等。那我们应该如何设置合适的线程数呢?要解决这个问题,首先要分析以下两个问题:
-
为什么要使用多线程?
-
多线程的应用场景有哪些?
为什么要使用多线程?
使用多线程,本质上就是提升程序性能。不过此刻谈到的性能,可能在你脑海里还是比较笼统的,基本上就是快、快、快,这种无法度量的感性认识很不科学,所以在提升性能之前,首要问题是:如何度量性能。
度量性能的指标有很多,但是有两个指标是最核心的,它们就是延迟和吞吐量。
延迟指的是发出请求到收到响应这个过程的时间;延迟越短,意味着程序执行得越快,性能也就越好。
吞吐量指的是在单位时间内能处理请求的数量;吞吐量越大,意味着程序能处理的请求越多,性能也就越好。
这两个指标内部有一定的联系(同等条件下,延迟越短,吞吐量越大),但是由于它们隶属不同的维度(一个是时间维度,一个是空间维度),并不能互相转换。我们所谓提升性能,从度量的角度,主要是降低延迟,提高吞吐量。这也是我们使用多线程的主要目的。那我们该怎么降低延迟,提高吞吐量呢?这个就要从多线程的应用场景说起了。
多线程的应用场景
要想“降低延迟,提高吞吐量”,对应的方法呢,基本上有两个方向,一个方向是优化算法,另一个方向是将硬件的性能发挥到极致。前者属于算法范畴,后者则是和并发编程息息相关了。那计算机主要有哪些硬件呢?主要是两类:一个是 I/O,一个是 CPU。简言之,在并发编程领域,提升性能本质上就是提升硬件的利用率,再具体点来说,就是提升 I/O 的利用率和 CPU 的利用率。估计这个时候你会有个疑问,操作系统不是已经解决了硬件的利用率问题了吗?的确是这样,例如操作系统已经解决了磁盘和网卡的利用率问题,利用中断机制还能避免 CPU 轮询 I/O 状态,也提升了 CPU 的利用率。但是操作系统解决硬件利用率问题的对象往往是单一的硬件设备,而我们的并发程序,往往需要 CPU 和 I/O 设备相互配合工作,也就是说,我们需要解决 CPU 和 I/O 设备综合利用率的问题。关于这个综合利用率的问题,操作系统虽然没有办法完美解决,但是却给我们提供了方案,那就是:多线程。
下面我们用一个简单的示例来说明:如何利用多线程来提升 CPU 和 I/O 设备的利用率?假设程序按照 CPU 计算和 I/O 操作交叉执行的方式运行,而且 CPU 计算和 I/O 操作的耗时是 1:1。如下图所示,如果只有一个线程,执行 CPU 计算的时候,I/O 设备空闲;执行 I/O 操作的时候,CPU 空闲,所以 CPU 的利用率和 I/O 设备的利用率都是 50%。

如果有两个线程,如下图所示,当线程 A 执行 CPU 计算的时候,线程 B 执行 I/O 操作;当线程 A 执行 I/O 操作的时候,线程 B 执行 CPU 计算,这样 CPU 的利用率和 I/O 设备的利用率就都达到了 100%。

我们将 CPU 的利用率和 I/O 设备的利用率都提升到了 100%,会对性能产生了哪些影响呢?通过上面的图示,很容易看出:单位时间处理的请求数量翻了一番,也就是说吞吐量提高了 1 倍。此时可以逆向思维一下,如果 CPU 和 I/O 设备的利用率都很低,那么可以尝试通过增加线程来提高吞吐量。
在单核时代,多线程主要就是用来平衡 CPU 和 I/O 设备的。如果程序只有 CPU 计算,而没有 I/O 操作的话,多线程不但不会提升性能,还会使性能变得更差,原因是增加了线程切换的成本。但是在多核时代,这种纯计算型的程序也可以利用多线程来提升性能。为什么呢?因为利用多核可以降低响应时间。为便于你理解,这里我举个简单的例子说明一下:计算 1+2+… … +100 亿的值,如果在 4 核的 CPU 上利用 4 个线程执行,线程 A 计算[1,25 亿),线程 B 计算[25 亿,50 亿),线程 C 计算[50,75 亿),线程 D 计算[75 亿,100 亿],之后汇总,那么理论上应该比一个线程计算[1,100 亿]快将近 4 倍,响应时间能够降到 25%。一个线程,对于 4 核的 CPU,CPU 的利用率只有 25%,而 4 个线程,则能够将 CPU 的利用率提高到 100%。

创建多少线程合适?
创建多少线程合适,要看多线程具体的应用场景。我们的程序一般都是 CPU 计算和 I/O 操作交叉执行的,由于 I/O 设备的速度相对于 CPU 来说都很慢,所以大部分情况下,I/O 操作执行的时间相对于 CPU 计算来说都非常长,这种场景我们一般都称为 I/O 密集型计算;和 I/O 密集型计算相对的就是 CPU 密集型计算了,CPU 密集型计算大部分场景下都是纯 CPU 计算。I/O 密集型程序和 CPU 密集型程序,计算最佳线程数的方法是不同的。下面我们对这两个场景分别说明。对于 CPU 密集型计算,多线程本质上是提升多核 CPU 的利用率,所以对于一个 4 核的 CPU,每个核一个线程,理论上创建 4 个线程就可以了,再多创建线程也只是增加线程切换的成本。所以,对于 CPU 密集型的计算场景,理论上“线程的数量 =CPU 核数”就是最合适的。不过在工程上,线程的数量一般会设置为“CPU 核数 +1”,这样的话,当线程因为偶尔的内存页失效或其他原因导致阻塞时,这个额外的线程可以顶上,从而保证 CPU 的利用率。对于 I/O 密集型的计算场景,比如前面我们的例子中,如果 CPU 计算和 I/O 操作的耗时是 1:1,那么 2 个线程是最合适的。如果 CPU 计算和 I/O 操作的耗时是 1:2,那多少个线程合适呢?是 3 个线程,如下图所示:CPU 在 A、B、C 三个线程之间切换,对于线程 A,当 CPU 从 B、C 切换回来时,线程 A 正好执行完 I/O 操作。这样 CPU 和 I/O 设备的利用率都达到了 100%。

通过上面这个例子,我们会发现,对于 I/O 密集型计算场景,最佳的线程数是与程序中 CPU 计算和 I/O 操作的耗时比相关的,我们可以总结出这样一个公式:最佳线程数 =1 +(I/O 耗时 / CPU 耗时)。我们令 R=I/O 耗时 / CPU 耗时,综合上图,可以这样理解:当线程 A 执行 IO 操作时,另外 R 个线程正好执行完各自的 CPU 计算。这样 CPU 的利用率就达到了 100%。不过上面这个公式是针对单核 CPU 的,至于多核 CPU,也很简单,只需要等比扩大就可以了,计算公式如下:最佳线程数 =CPU 核数 * [ 1 +(I/O 耗时 / CPU 耗时)]。
总结
很多人都知道线程数不是越多越好,但是设置多少是合适的,却又拿不定主意。其实只要把握住一条原则就可以了,这条原则就是将硬件的性能发挥到极致。上面我们针对 CPU 密集型和 I/O 密集型计算场景都给出了理论上的最佳公式,这些公式背后的目标其实就是将硬件的性能发挥到极致。对于 I/O 密集型计算场景,I/O 耗时和 CPU 耗时的比值是一个关键参数,不幸的是这个参数是未知的,而且是动态变化的,所以工程上,我们要估算这个参数,然后做各种不同场景下的压测来验证我们的估计。不过工程上,原则还是将硬件的性能发挥到极致,所以压测时,我们需要重点关注 CPU、I/O 设备的利用率和性能指标(响应时间、吞吐量)之间的关系。
课后思考
有些同学对于最佳线程数的设置积累了一些经验值,认为对于 I/O 密集型应用,最佳线程数应该为:2 * CPU 的核数 + 1,你觉得这个经验值合理吗?
网友答案:个人认为这个经验值有一定的合理性,如果是程序首次运行,可以将线程数设置为这个经验值,以得到比较好的运行效果;不过运行一段时间后,能够根据工具(如apm等)分析得出I/O耗时/CPU耗时的比值,则应该采用更优化的线程数设置(最佳线程数 =CPU 核数 * [ 1 +(I/O 耗时 / CPU 耗时)])。实际工作中都是按照逻辑核数设置,最终还是要根据压测数据调整。
11 | Java线程(下):为什么局部变量是线程安全的?
内容来源:11 | Java线程(下):为什么局部变量是线程安全的? (geekbang.org)
内容待完善......