虎牙一面:请详细介绍一下内核缓冲区
写这篇文章的起因主要是最近复习计网滑动窗口中看到的一句话 “窗口的本质是内核缓冲区”,之前一直没有仔细去理解,以为就是缓存,很多博客写得也是缓存…,But 缓冲和缓存在概念上其实是有区别的,本文就来详细介绍一下内核缓冲区
内核态和用户态
先来回顾下内核态和用户态:
众所周知,CPU 上会运行两种程序,一种是操作系统的内核程序(也称为系统程序),一种是应用程序。前者完成系统任务,后者实现应用任务。两者之间有控制和被控制的关系,前者有权管理和分配资源,而后者只能向系统申请使用资源。
显然,我们应该把在 CPU 上运行的这两类程序加以区分,这就是内核态和用户态出现的原因。
- 内核态(kernel mode):当 CPU 处于内核态势,这是操作系统管理程序(也就是内核)运行时所处的状态。运行在内核态的程序可以访问计算机的任何资源,不受限制,为所欲为,例如协调 CPU 资源,分配内存资源,提供稳定的环境供应用程序运行等。
- 用户态(user mode):应用程序基本都是运行在用户态的,或者说用户态就是提供应用程序运行的空间。运行在用户态的程序只能访问当前 CPU 上执行程序所在的地址空间,这样有效地防止了操作系统程序受到应用程序的侵害。

对操作系统来说,什么样的程序应该放在内核态呢?
这取决于对资源的需求、时间的紧迫和效率的高低等因素。比如 CPU、内存、设备等资源管理器程序应该在内核态运行,否则安全性没有保证。对于文件系统和数据来说,文件系统数据和管理必须放在内核态,但是用户的数据和管理可以放在用户态。
应用程序如果想要访问系统资源,可以通过系统调用 or 中断(外中断、内中断)从而使得 CPU 从用户态转向内核态
所谓系统调用,其实就是一些函数,操作系统直接提供了这些函数用于对文件和设备进行访问和控制。
最常见的就是 read 和 write 这俩
简单介绍下:
- read:从文件中读取内容
- write:往文件中写入内容
内核缓冲区
根据内核态和用户态的定义,我们不难理解内核空间和用户空间的定义
- 用户操作系统内核能够访问的内存区域呢,就称为内核空间,它独立于普通的应用程序,是受保护的内存空间
- 而普通应用程序可访问的内存区域呢,就是用户空间
当我们说一个应用程序从磁盘上读取文件时,通常分两步走:

操作系统(内核)先从磁盘上读取数据存到内核空间,再把数据从内核空间拷贝到用户空间。此后,用户应用程序才可以操作此数据。在此我向大家推荐一个架构学习交流圈。交流学习指导伪鑫:1253431195(里面有大量的面试题及答案)里面会分享一些资深架构师录制的视频录像:有Spring,MyBatis,Netty源码分析,高并发、高性能、分布式、微服务架构的原理,JVM性能优化、分布式架构等这些成为架构师必备的知识体系。还能领取免费的学习资源,目前受益良多
所以,在这个过程中有两次数据读取操作:
- 第一步:从磁盘上读取
- 第二步:从内存中读取
众所周知,访问磁盘的速度要远远低于访问内存的速度,完全不是一个量级的,所以理论上 read 磁盘的速度要远远慢于 read 内存。
那么整个文件读取过程的最大时间瓶颈就出现在了对磁盘的读取上。
要解决这个问题,内核缓冲区(Kernel Buffer Cache)就应运而生了。
本质上其实就是内核空间的一块内存区域罢了
从 Buffer Cache(缓冲区缓存)这个名字上能看出来,内核缓冲区(准确的说,应该是内核缓冲区缓存),其实有两个作用,缓冲(Buffer) + 缓存(Cache)
小牛肉 PS:实话实说,各种各样的翻译很容易让我们的学习曲线陡峭起来,记住 Buffer Cache比记住内核缓冲区或者用户缓冲区这俩名词要好得多,这俩容易让人摸不着头脑。
先来看看它是怎么充当 Cache 的:
⭐ 数据预读
数据预读指的是,当程序发起 read() 系统调用时,内核会比请求更多地读取磁盘上的数据,保存在缓冲区,以备程序后续使用。这种数据的预取策略其实就是基于局部性原理
因此当我们向内核请求读取数据时,内核会先到内核缓冲区中去寻找,如果命中数据,则不需要进行真正的磁盘 I/O,直接从缓冲区中返回数据就行了;如果缓存未命中,则内核会从磁盘中读取请求的 page,并同时读取紧随其后的几个 page(比如三个),如果文件是顺序访问的,那么下一个读取请求就会命中之前预读的缓存(当然了,预读算法非常复杂,这里只是一个简化的逻辑)。
再来看看内核缓冲区是怎么充当 Buffer 的:
⭐ 延时回写
回写指的是,当程序发起 write() 系统调用时,内核并不会直接把数据写入到磁盘文件中,而仅仅是写入到缓冲区中,几秒后(或者说等数据堆积了一些后)才会真正将数据刷新到磁盘中。对于系统调用来说,数据写入缓冲区后,就返回了。
延迟往磁盘写入数据的最大一个好处就是,可以合并更多的数据一次性写入磁盘,把小块的 I/O 变成大块 I/O,减少磁盘处理命令次数,从而提高提盘性能。
另一个好处是,当其它进程紧接着访问该文件时,内核可以从直接从缓冲区中提供更新的文件数据(这里又是充当 Cache 了)。
说起来一大堆,其实很简单,把握缓冲和缓存的定义就行了,如果你是读,我就会拿多一点放在内核缓冲区,这样你下次读的时候大概率就不需要访问磁盘了,直接从内核缓冲区拿就行;如果你是写,我就会等内核缓冲区中的数据堆积得多了再写磁盘,而不是来一点数据就写一次磁盘
无论是读操作还是写操作,无论是充当缓存还是缓冲,究其根本,内核缓冲区的作用都是为了减少磁盘 IO 的次数
用户缓冲区
上面提到,read 磁盘的速度要远远慢于 read 内存,不过事实上,read 内存这个操作也挺费时的,因为应用程序想要访问系统资源的话,就要通过系统调用 or 中断(外中断、内中断)使得 CPU 从用户态转向内核态,这个状态的改变需要涉及堆栈的环境和数据变化,还是挺需要时间的。在此我向大家推荐一个架构学习交流圈。交流学习指导伪鑫:1253431195(里面有大量的面试题及答案)里面会分享一些资深架构师录制的视频录像:有Spring,MyBatis,Netty源码分析,高并发、高性能、分布式、微服务架构的原理,JVM性能优化、分布式架构等这些成为架构师必备的知识体系。还能领取免费的学习资源,目前受益良多
那为了减少系统调用的发生呢(或者说,减少用户态和内核态的转换次数),就设计了用户缓冲区。
作用和内核缓冲区一样,数据阅读 + 延时回写,既充当 Cache 又充当 Buffer。
不同的就是,内核缓冲区处理的是内核空间和磁盘之间的数据传递,目的是减少访问磁盘的次数;而用户缓冲区处理的是用户空间和内核空间的数据传递,目的是减少系统调用的次数(感觉这句话总结得不错,给自己点个赞)
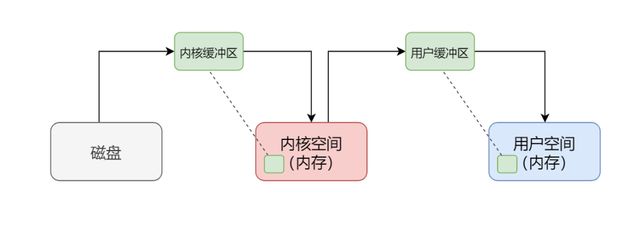
另外,从上面的分析我们可以看出,read() 和 write() 都并非真正执行 I/O 操作(或者说,都并不直接和磁盘进行交互),它只代表数据在用户空间 / 内核空间传递的完成,read 是把数据从内核缓冲区复制到用户缓冲区,write 是把用户缓冲区复制到内核缓冲区