Kotlin进阶学习—第五篇
Kotlin进阶学习—第五篇
Kotlin系列已更新:
Kotlin基础学习-入门篇
Kotlin基础学习-第二篇
Kotlin进阶学习-第三篇
Kotlin进阶学习-第四篇
Kotlin进阶学习-第五篇
文章目录
- Kotlin进阶学习—第五篇
-
- 泛型高级特性
-
- 泛型实化
- 泛型的协变与逆变
-
- Java中的协变与逆变
- 上下界问题
- 协变
- 逆变
- 协程
-
- 定义
- GlobalScope.launch
- runBlocking
- launch
- 挂起函数suspend
-
- 当前线程干啥去了?
- 协程去哪了?
- 为什么只能在协程中或者另一个挂起函数中调用挂起函数?
- 为什么自定义的挂起函数中必须调用其他挂起函数?
- suspend的作用
- 笔者的总结
- withContext
- coroutineScope
- async
- suspendCoroutine 简化回调
- 总结:
泛型高级特性
Kotlin的泛型有一些区别于Java
泛型实化
Java泛型的原理使用类型擦除,在编译时都变成了Object,此种机制下调用instanceof和获取class对象是一定会出错的,如下:
public static void main(String[] args) {
Main.<String>test();
}
public static <T> void test() {
if (T instanceof String) {
System.out.println(T.class);
}
}
Kotlin的泛型原理与Java一样,但是在某种情况下可以调用上述不能调用的方法和属性。因为Kotlin存在内联函数,关于内联函数请查看Kotlin进阶学习-第四篇 ,在编译时就直接将代码替换了,也就不存在类型擦除的问题了。
需要借助两个关键字inline,reified
inline修饰方法,reified修饰泛型
如下:
fun main() {
println(test<String>())
}
inline fun <reified T> test() = T::class.java
反编译的java代码为下:
public static final void main() {
int $i$f$test = false;
Class var2 = String.class;
boolean var1 = false;
System.out.println(var2);
}
// $FF: synthetic method
public static void main(String[] var0) {
main();
}
// $FF: synthetic method
public static final Class test() {
int $i$f$test = 0;
Intrinsics.reifiedOperationMarker(4, "T");
return Object.class;
}
上述代码并没有再调用test,而是直接被内联替换成test的内部实现,也正是内联函数的存在才使得Kotlin支持泛型的实化。
泛型的协变与逆变
Java中的协变与逆变
第四篇文章中只讲述了泛型最基础的使用,并没有讲解java中对应泛型通配符?,Kotlin协变与逆变就对应通配符的extends和super
本篇文章不对java泛型、进行详解,详情请看笔者的全网最详细泛型解析
这里对通配符进行解析:
//class Fruit
//class Orange extend Fruit
//class Apple extend Fruit
public static void print(GenericType<Fruit> p){
System.out.println(p.getData().getColor());
}
public class GenericType<T> {
private T data;
public T getData() {
return data;
}
public void setData(T data) {
this.data = data;
}
}
GenericType<Fruit> a = new GenericType<>();
print(a);
GenericType<Orange> b = new GenericType<>();
//print(b);报错
GenericType<Apple> c = new GenericType<>();
//print(c);报错
上述代码中三个类Fruit,Orange,Apple,Fruit是其他两个类的父类
声明一个GenericType类接收一个T泛型,再声明一个print函数,需要传入GenericType类型
声明三个GenericType对象a,b,c传入的泛型分别是分别是Fruit,Orange,Apple
print(a)不报错,print(b),print(c)出错,因为上述print方法中需要的是GenericType,java不认泛型的子类,他认为GenericType和GenericType不是同一种类型,此时就需要借助通配符?
上述问题中只要修改print中传入的参数即可,修改如下:
public static void print(GenericType<? extends Fruit> p){
System.out.println(p.getData().getColor());
}
super的使用与extends相反,上述使用extends,使得p可以传入泛型的子类,若改为super则可以传父类
举例:
public static void print(GenericType<? super Apple> p){
System.out.println(p.getData().getColor());
}
GenericType<Fruit> a = new GenericType<>();
print(a);
GenericType<Orange> b = new GenericType<>();
//print(b);报错
GenericType<Apple> c = new GenericType<>();
print(c);报错
上下界问题
由于通配符规定了上下界,此机制也会出现一些问题
看下述代码:
public static void main(String[] args) {
List<Apple> list = new ArrayList<>();
add(list);
}
public static void add(List<? extends Fruit> list) {
list.add(new Orange());//报错
}
上面代码为何报错呢,因为add函数的参数list的来源不能确切的知道其泛型的真实类型,假设说上述可以运行,那么本来规定为Apple的实参list则有了一个Orange实例,这肯定违背了泛型的安全,因此只要是容器使用配合extends使用了?通配符,一律不可add,但是可以get,可以get是因为上界是规定了的,get直接返回上界即可。
同样的若改为super,将不知道参数的具体的泛型上界来源,get方法只会返回Object,但是却可以调用add方法,要注意的是add会被限制为只可以传入super类的子类对象。
比如:
public static void add(List<? super Apple> list) {
list.add(new Fruit()); //报错
list.add(new HongFushi()); //编译通过
}
下面对Kotlin的协变和逆变进行分析,在分析之前先约定一个规则

接收数据的称之为in,输出的位置称为out
协变
协变则对应上述中的extends
Kotlin中提供out关键字实现协变,只能在out位置使用泛型,in位置不能使用泛型,上述我们知道通配符?和extends配合是无法add的,拒绝类似add的操作就是在in位置上不允许使用泛型
有两种特殊情况:
构造中如果是val修饰可以在in位置传入编译通过,因为val已经指明不可修改,因此可以在in位置传入,若用var和private修饰说明对外部修改封闭,其也是可以编译通过的
class SimpleData<out T>(val data: T?) {
fun get(): T? {
return data
}
}
class SimpleData<out T>(private var data: T?) {
fun get(): T? {
return data
}
}
Kotlin的很多内置API是天生支持协变的,举个例子:List的contains方法
public interface List<out E> : Collection<E> {
...
override fun contains(element: @UnsafeVariance E): Boolean
...
}
其也在in位置使用了泛型,contains肯定不会调用set方法,但是为了编译通过必须使用UnsafeVariance注解
逆变
逆变则对应上述中的super
Kotlin中提供in关键字实现逆变,只能在in位置使用泛型,out位置不能使用泛型,上述我们知道通配符?和super配合调用get方法永远返回Object,拒绝类似get的操作就是在out位置上不允许使用泛型
具体内容在Java的super已经分析完毕了,本小节不再分析。
举一个逆变的例子(Comparable的比较方法):
interface Comparable<in T> {
operator fun compareTo(other: T): Int
}
若Comparable能够比较两个Person的大小,那一定也能够比较Comparable的大小,因此需要借助逆变来实现
协程
本篇文章只学习对协程的使用,对于协程的原理等笔者研究透彻再来续写
定义
首先对Kotlin的协程进行定义,一个使用线程池实现的线程框架,能帮助我们更高效的使用线程。
一个线程框架,一个线程框架,一个线程框架,就比如AsyncTask,并不是许多博客说的那么邪乎。
其最大的优点就是并发代码看起来像是在单线程写的,其封装了强大的切换线程的功能,能很好的编写并发回调代码,平时我们都是启动线程请求网络操作,拿到数据触发回调更新ui,这种写法使得代码的顺序结构和完整性被打破了,而利用协程编写就不会断,看起来就像同步调用一样,因此总结一句话Kotlin最大的优点就是用非阻塞式的代码写出阻塞式的效果,可能仅仅是文字很难理解,举个例子:
使用原生线程写法:
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
setContentView(R.layout.activity_main)
Thread {
val data = ""
//网络操作获取data
...
//结果返回,切换到ui线程更新ui
runOnUiThread {
//更新ui
textView.text = data
}
}.start()
}
使用协程:
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
setContentView(R.layout.activity_main)
val job = Job()
val coroutineScope = CoroutineScope(job)
coroutineScope.launch {
val data = getData()
textView.text = data
}
}
suspend fun getData() = withContext(Dispatchers.IO) {
...
}
不需要理解上述代码,只需要知道程序员不需要在切换线程,就像是在一个线程里调用了两个方法一样,也就是上述所说的协程的优点用非阻塞式的代码写出阻塞式的效果
使用Kotlin需要导入以下依赖:
implementation "org.jetbrains.kotlinx:kotlinx-coroutines-core:1.3.2"
implementation "org.jetbrains.kotlinx:kotlinx-coroutines-android:1.3.2"
GlobalScope.launch
GlobalScope.launch函数可以创建一个协程作用域,此时传递的Lambda则可在协程中运行
fun main() {
GlobalScope.launch {
println("hello")
}
GlobalScope.launch {
println("world")
}
}
上述代码将开启两个协程,这两个协程是异步的,运行发现两行代码并没有执行,是因为GlobalScope.launch创建的为顶层协程,当应用程序结束也会跟着一起结束,若想让上述代码生效需要下面写法:
fun main() {
GlobalScope.launch {
println("hello")
}
GlobalScope.launch {
println("world")
}
Thread.sleep(1000)
}
因为异步执行,上述代码的打印结果是无序的。
若协程中代码比较耗时,上述写法也不成立,此时需要使用新的函数runBlocking
runBlocking
runBlocking也会创建一个协程作用域,但是调用它的线程会被阻塞,直到其自己内部的代码和子协程完全执行完毕才会继续执行调用线程
fun main() {
runBlocking {
println("hello")
delay(1000)
launch {
println("world")
}
}
}
launch
launch可以在任何协程作用域中调用,作用是创建子协程,和GlobalScope.launch没有什么不同,只不过GlobalScope作用域是顶层作用域,launch()方法创建的协程属于顶层协程。
只要外部协程作用域结束则会结束launch函数产生的子协程,这也是上述GlobalScope.launch例子中没有执行结果的原因,GlobalScope作用域跟随程序,程序结束作用域失效,出结果没有打印。
launch使用如下:
在runBlocking函数产生的协程作用域中调用:
runBlocking {
launch {
println("hello1")
delay(1000)
println("world1")
}
launch {
println("hello2")
delay(1000)
println("world2")
}
}
两个launch的也是异步执行,其执行顺序也是无序的,打印如下:
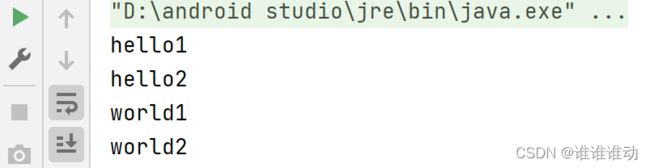
除了launch这种异步执行,有没有同步执行的呢,同步执行就是需要当前执行完毕才能继续往下执行,这也就涉及到了suspend,挂起函数的概念。
挂起函数suspend
挂起函数的作用是执行耗时操作,耗时操作也就意味着需要切换线程。
比如下载照片并显示就需要借助挂起函数实现:
//主线程中执行
coroutineScope.launch(Dispatchers.Main) {
//指定Lambda在IO线程执行,withContext方法就是一个挂起函数
val img = withContext(Dispatchers.IO) {
//网络操作获取照片
}
//返回主线程
imageView.setImageBitmap(img)
}
withContext()方法需要指定一个线程参数,调用withContext()方法会阻塞当前协程并立即执行Lambda,直到Lambda返回,但是它并不会阻塞线程。
上述功能如果使用launch绝对是实现不了的,如果使用launch取获取照片,当set图片时,数据一定为null导致设置失败。这是因为获取图片和设置图片是异步同时执行的。必须借助挂起函数实现,如 withContext()方法,声明挂起函数使用suspend修饰。
public suspend fun <T> withContext(...) {...}
当执行到挂起函数时,当前协程则会在当前执行它线程上脱离,并不是暂停执行,只是当前线程不再运行当前协程。此时兵分两路。
当前线程干啥去了?
正常来说遇到挂起函数后,线程直接跳过当前协程,继续往后执行,该干啥干啥,跟java线程池中的线程一样,要么回收,要么继续利用。
拿安卓主线程举例,若在安卓主线程中创建了一个协程,就相当于往主线程post了一个Runnable,若协程中调用了挂起函数,对于安卓主线程来讲就是runnable执行结束了,此时就继续在消息队列中取下一个消息,继续自己的工作,上一个Runnable并不是真的结束,只是给了别的线程。
协程去哪了?
挂起函数会指定新的执行线程,此时整个协程将交给新的线程,但是,并不是此协程的全部代码都在新的线程中执行,只是挂起函数中的那一部分阻塞代码比如说withContext()传入的Lambda。当挂起函数执行完毕,会把剩余的代码post回原来线程。当然由于分发器的不同,程序员可以选择是否恢复,但这是你的操作并不是挂起函数的定位。
若上述不理解可以看下面例子
对上述的例子的过程进行解析:
//主线程中执行
coroutineScope.launch(Dispatchers.Main) {
//切换IO线程
val img = withContext(Dispatchers.IO) {
//网络操作获取照片
}
//返回主线程
imageView.setImageBitmap(img)
}
上述的执行流程是当执行到挂起函数,整个协程将脱离当时的运行线程,对应到上述功能则是下面两行代码脱离当前线程运行
val img = getImg()
imageView.setImageBitmap(img)
此时上面的代码将交给挂起函数中指定的线程,对应到上述代码就是IO操作的线程,此时主线程就继续去做自己的事,当IO线程执行完getImg()也就是withContext()方法执行完毕,会把剩余的代码在post回原先线程,也就是**imageView.setImageBitmap(img)**这行代码会再返回Main线程执行。
为什么只能在协程中或者另一个挂起函数中调用挂起函数?
若下述使用则编译不过:
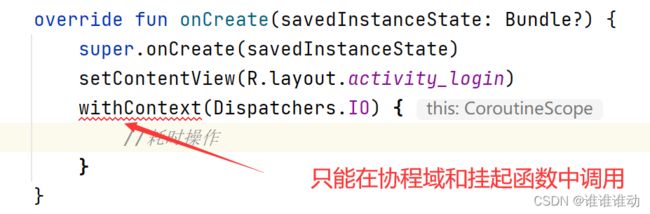
挂起是需要切回来,恢复线程的,而恢复是协程才有的功能,因此只能在协程中调用挂起函数。无论在哪个挂起函数中调用挂起函数,最顶层的挂起函数一定是在一个协程中调用的。
为什么自定义的挂起函数中必须调用其他挂起函数?
Kotlin中灰色代表可以去掉

挂起的作用是执行耗时操作,切换线程并切换回来,不调用挂起函数意味着操作不是耗时操作,也就没有使用suspend关键字的必要。
suspend的作用
suspend中必须执行耗时操作,也就是必须执行其他挂起函数,比如内置的delay()函数,withContext()函数。
其必须执行其他挂起函数也就意味着真正的阻塞不是suspend关键字实现的,而是调用的切换线程的挂起函数实现的,他仅仅只是规范程序员的代码编写。引用扔老师的话就是函数的创建者对函数的使用者的一种提醒,提醒使用者我是一个耗时操作,需要在后台运行,请在协程中调用。
笔者的总结
笔者理解的挂起就是Runnable在一堆线程里来回传递,也并不是说挂起函数就一定要切换线程,虽然挂起的设计初衷是需要切换线程的,但是最最准确的理解是当前执行的Runnable脱离当前线程,脱离线程有两种情况
- 一种是把当前
Runnable交给其他线程执行(最常见的情况也是绝大多数情况),执行完毕再恢复,切换可能是某个内置挂起函数的功能,恢复是协程的功能。 - 另一种是调用
delay(),delay()并不会切线程,也不会恢复线程,调用delay()其实就是取消当前执行,再往Handler中发送一个延时Runnable,等待一段时间再执行。
还是上面所说,第一种情况才是挂起函数的正统使用,程序员可以选择第二种,但这是你的操作并不是挂起函数的定位。
withContext
上述已经讲过,这里重复一遍
withContext是一个挂起函数,只能在协程或者挂起函数中调用。
withContext()方法需要指定分发器,调用立即阻塞当前协程并立即执行Lambda,只到Lambda返回,其并不会阻塞线程。
需要指定分发器,分发器会决定运行的线程,分发器常用的有三种:
- Dispatchers.Main 安卓主线程
- Dispatchers.Io
IO流,网络,文件读取操作线程 - Dispatchers.Default
CPU计算密集型线程
使用如下:
coroutineScope.launch(Dispatchers.Main) {
val img = getImg()
imageView.setImageBitmap(img)
}
suspend fun geImg() = withContext(Dispatchers.IO) {
//网络操作获取照片
}
上述代码就是withContext()函数最常用的场景,在suspend函数中用于切换线程。
coroutineScope
coroutineScope()和withContext()类似,只是coroutineScope()不需要指定分发器。
coroutineScope ≡ withContext(this.coroutineContext)
coroutineScope()也和withContext()使用场景类似,都是在suspend函数中用于切换线程,coroutineScope()适用于创建子协程分割任务,让子协程去切换线程,而withContext()一般不创建子协程,自己去切换上下文,切换线程。
使用如下:
suspend fun getData() = coroutineScope {
//运行在调用getData()的线程中
launch {
//耗时任务一
}
//运行在IO线程中
launch(Dispatchers.IO) {
//耗时任务二
}
}
coroutineScope()和withContext()的区别:
coroutineScope 是关于几个子协程的作用域生命周期.它用于将一个任务分解为几个并发的子任务.您不能使用它更改上下文,因此它从当前上下文继承分发器,如果需要,每个子协程都会指定不同的 Dispatcher.
withContext 通常不用于启动子协程,而是临时切换当前协程的上下文,它应该在其代码块完成后立即完成。它的主要作用是将耗时操作运行在自己指定的线程上。
async
async()方法创建一个子协程,传入一个Lambda,调用则立即执行Lambda
async()是创建有返回值的子协程,与launch不同的是launch永远返回Job类型,返回值调用await()方法获得,调用await()会立即阻塞当前协程。
使用如下:
GlobalScope.launch {
printData()
}
suspend fun printData() = coroutineScope {
//Dispatchers.IO不传则沿用调用协程的
val value1 = async(Dispatchers.IO) {
//耗时任务一
delay(1000)
"value1"
}.await()
val value2 =async(Dispatchers.IO) {
//耗时任务二
delay(1000)
"value2"
}.await()
Log.e("Value", "$value1 $value2")
}
上述使用就是不当的,使用了双倍的时间,因为await()会阻塞当前协程,两个耗时任务互不影响的话则可以缓调await()
正确使用如下:
GlobalScope.launch {
printData()
}
suspend fun printData() = coroutineScope {
val value1 = async(Dispatchers.IO) {
//耗时任务一
delay(1000)
"value1"
}
val value2 = async(Dispatchers.IO) {
//耗时任务二
delay(1000)
"value2"
}
Log.e("Value", "${value1.await()} ${value2.await()}")
}
综上可以发现:
withContext() = async().await()
suspendCoroutine 简化回调
suspendCoroutine()函数也是一个挂起函数,需要在协程或者挂起函数中调用,其接收一个Lambda,Lambda会传入一个Continuation参数,调用resume()方法或者resumeWithException()方法可以让协程恢复执行。
用其简化Retrofit回调,使用如下:
suspend fun <T> Call<T>.await(): T {
return suspendCoroutine { continuation ->
enqueue(object : Callback<T> {
override fun onResponse(call: Call<T>, response: Response<T>) {
val body = response.body()
if (body != null) continuation.resume(body)
else continuation.resumeWithException(RuntimeException("response body is null"))
}
override fun onFailure(call: Call<T>, t: Throwable) {
continuation.resumeWithException(t)
}
})
}
}
调用如下:
suspend fun getAppData() {
try {
//此处省略retrofit的创建过程
val appList = ServiceCreator.create<AppService>().getAppData().await()
println(appList)
// 对服务器响应的数据进行处理
} catch (e: Exception) {
// 对异常情况进行处理
e.printStackTrace()
}
}
Kotlin第五篇到这就结束了。
总结:
泛型还是很简单的,跟Java中的区别不大,只是换了个名字,可能笔者的理解也有错误,也欢迎大家即时纠正。
协程是真正太好理解的,全新的名词,Java中根本不存在。笔者因为时间有限,也没有阅读协程的源码,浅看之下只知道它是个线程池,配合类似于Handler的机制来实现的,细节也没有深入研究,若上述文章有错误的话一定要私信我纠正。
✨ 原 创 不 易 , 还 希 望 各 位 大 佬 支 持 一 下 \textcolor{blue}{原创不易,还希望各位大佬支持一下} 原创不易,还希望各位大佬支持一下
点 赞 , 你 的 认 可 是 我 创 作 的 动 力 ! \textcolor{green}{点赞,你的认可是我创作的动力!} 点赞,你的认可是我创作的动力!
⭐️ 收 藏 , 你 的 青 睐 是 我 努 力 的 方 向 ! \textcolor{green}{收藏,你的青睐是我努力的方向!} 收藏,你的青睐是我努力的方向!
✏️ 评 论 , 你 的 意 见 是 我 进 步 的 财 富 ! \textcolor{green}{评论,你的意见是我进步的财富!} 评论,你的意见是我进步的财富!