驱动 | Linux | NVMe - 1. 内核驱动
本文总结 NVMe 的 Linux 驱动是如何实现的。
Update: 2022 / 11 / 2
系列文章
驱动 | Linux | NVMe - 1. 内核驱动
- 系列文章
- 总览
- NVMe 命令
- PCI 总线
- 注册和初始化驱动
- 创建 NVMe 块设备
-
- 硬件层面
- 软件层面
- NVMe 设备的 IO 流程
- DMA
- 参考链接
总览
NVMe (Non-VolatileMemory express),是一种建立在 M.2 接口上的类似 AHCI 的一种协议,是专门为闪存类存储设计的协议。
NVMe 具体优势包括:
- 性能有数倍的提升;
- 可降低延迟超过50%;
NVMe PCIe SSD可提供的IOPs十倍于高端企业级SATA SSD;- 自动功耗状态切换和动态能耗管理功能大大降低功耗;
- 支持未来十年技术发展的可扩展能力。
码农该怎么理解?——
- 问:它是一个存储协议,既然是存储协议是不是需要快速的读写?
答:对。 -
PCIe才是最快的协议啊,为啥不用PCIe呢?
答:PCIe很复杂的。 - 问:那我们给
PCIe穿个马甲,就可以?
答:NVMe就是给PCIe穿个马甲。 - 问:
NVMe是怎么做到的?
答:PCIe是作文题,NVMe是选词填空,最后的结果却一样。 - 问:怎么填?填什么?
答:按照这个表格填写,发什么就填什么,总共64字节,不需要的填0就行了。
IO Command |
|||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| appmask | apptag | reftag | dsmgmt | slba | addr | metadata | rsvd | nblocks | control | Flags | Opcode |
Admin Command |
|||||||||||
| rsvd11 | numd | offset | lid | prp2 | prp1 | rsvd1 | command_id | flags | Opcode |
NVMe 是一种 Host 与 SSD 之间通讯的协议,制定了 Host 与 SSD 之间通讯的命令,以及命令如何执行的,它在协议栈中隶属高层,

NVMe 离不开 PCIe,NVMe SSD 是 PCIe 的 endpoint。PCIe 是 x86 平台上一种流行的 bus 总线,由于其 Plug and Play 的特性,目前很多外设都通过 PCI Bus 与 Host 通信,甚至不少 CPU 的集成外设都通过 PCI Bus 连接,如 APIC等。
NVMe SSD 在 PCIe 接口上使用新的标准协议 NVMe ,由大厂 Intel 推出并交由 nvmexpress 组织推广,现在被全球大部分存储企业采纳 1。
NVMe SSD 本身是一个块设备,因此 NVMe 的驱动也是遵循块设备的驱动架构。
本文基于 Linux 4.1.12 版本的内核( 其它版本的内核代码可能略有不同,但不影响理解)通过两部分介绍 NVMe 的驱动程序 2:
- 操作系统如何创建
NVMe块设备 NVMe的主要流程,包括读写流程和管理流程等
NVMe 命令
参考这里 1’ 3
NVMe Host 和 NVMe Controller 通过 NVMe Command 进行信息交互。
NVMe Command 是 Host 与 SSD Controller 交流的基本单元,应用的 I/O 请求也要转化成 NVMe Command。
NVMe Spec 中定义了 NVMe Command 的格式,占用 64 字节。
NVMe Command 分为 Admin Command 和 IO Command 两大类,前者主要是 Host 用于管理和控制 SSD,后者用于 Host 和 SSD 之间的数据传输。
发送的太快我来不及执行咋办?——
搞两个缓冲区吧:
- 发送缓冲区
SubmissionQueue(SQ) - 完成缓冲区
CompletionQueue(CQ)
处理完了,我该怎么告诉你呢?——
- 写
Doorbell Register(DB)
这个系统结构可以下图表示,
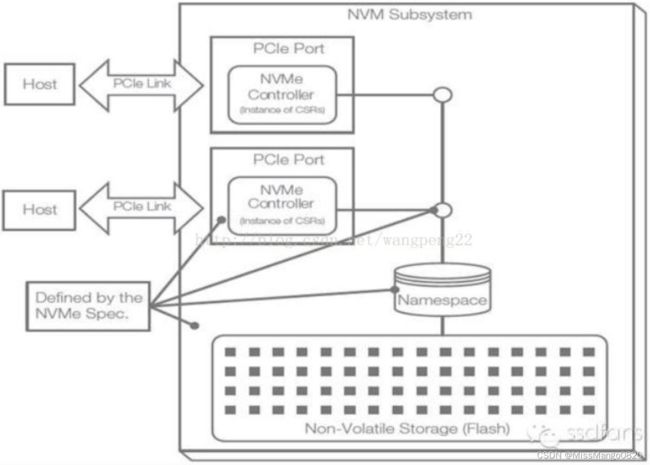
这个 namespace 是什么?——
每个 flash 块就是一个 namaspce,它有个 id ,叫 namaspce ID。
NVMe 到 SDD 是怎么玩的?——
举例 Host 需要从 flash 地址 0x02000000 上读取 nblock = 2 的数据,PRP1 给出内存地址是0x10000000,该怎么操作?
首先我们得组包 nvme_cmd,这个包为读命令,它包含我们读地址( 0x02000000 )、长度( nblock = 2 )、和读到什么地方( PRP ),然后把这个包扔给 SQ,写 doorbell 通知控制器来取命令,控制器取出命令来转换为 TLP 包通过 PCIe Memory 方式把 0x02000000 的数据写入到0x10000000 中,然后在 CQ 的尾部写入完成标志,再写 doorbell 告诉控制器我的事干完了。
-
- 这个命令放在
SQ里;
- 这个命令放在
-
Host通过写SQ的Tail DB,通知SSD来取命令;
-
SSD收到通知,去Host端的SQ中取指。PCIe是通过发一个Memory Read TLP到Host的SQ中取命令的;
-
SSD执行读命令,把数据从闪存中读到缓存中,然后把数据传给Host;
-
SSD往Host的CQ中返回状态;
-
SSD采用中断的方式告诉Host去处理CQ;
-
Host处理相应的CQ
PCI 总线
参考这里 1
在系统启动时,BIOS 会枚举整个 PCI 的总线,之后将扫描到的设备通过 ACPI tables 传给操作系统。当操作系统加载时,PCI Bus 驱动则会根据此信息读取各个 PCI 设备的 Header Config 空间,从 class code 寄存器获得一个特征值。
class code 是 PCI bus 用来选择哪个驱动加载设备的唯一根据。NVMe Spec 定义的 class code 是 010802h。NVMe SSD 内部的 Controller PCIe Header 中 class code 都会设置成 010802h。

所以,需要在驱动中指定 class code 为 010802h,将 010802h 放入 pci_driver nvme_driver 的 id_table。之后当nvme_driver 注册到 PCI Bus 后,PCI Bus 就知道这个驱动是给 class code=010802h 的设备使用的。nvme_driver 中有一个 probe 函数,nvme_probe(),这个函数才是真正加载设备的处理函数。
#define PCI_CLASS_STORAGE_EXPRESS 0x010802
static const struct pci_device_id nvme_id_table[] = {
……
{ PCI_DEVICE_CLASS(PCI_CLASS_STORAGE_EXPRESS, 0xffffff) },
……
};
注册和初始化驱动
参考这里 1
我们知道首先是驱动需要注册到PCI总线。那么nvme_driver是如何注册的呢?
当驱动被加载时就会调用 nvme_init ( drivers/nvme/host/pci.c 4 ) 函数,如下所示,
static int __init nvme_init(void)
{
BUILD_BUG_ON(sizeof(struct nvme_create_cq) != 64);
BUILD_BUG_ON(sizeof(struct nvme_create_sq) != 64);
BUILD_BUG_ON(sizeof(struct nvme_delete_queue) != 64);
BUILD_BUG_ON(IRQ_AFFINITY_MAX_SETS < 2);
BUILD_BUG_ON(DIV_ROUND_UP(nvme_pci_npages_prp(), NVME_CTRL_PAGE_SIZE) >
S8_MAX);
return pci_register_driver(&nvme_driver);
}
在这个函数中,调用了 kernel 的函数 pci_register_driver,注册 nvme_driver。这样 PCI bus 上就多了一个 pci_driver nvme_driver。
static struct pci_driver nvme_driver = {
.name = "nvme",
.id_table = nvme_id_table,
.probe = nvme_probe,
.remove = nvme_remove,
.shutdown = nvme_shutdown,
#ifdef CONFIG_PM_SLEEP
.driver = {
.pm = &nvme_dev_pm_ops,
},
#endif
.sriov_configure = pci_sriov_configure_simple,
.err_handler = &nvme_err_handler,
};
当读到一个设备的 class code 是 010802h 时,就会调用这个 nvme_driver 结构体的 probe 函数, 也就是说当设备和驱动匹配了之后,驱动的 probe 函数就会被调用,来实现驱动的加载。
Probe 函数主要完成四个工作:
- 映射设备的
BAR空间到内存虚拟地址空间; - 设置
admin queue; - 添加
nvme namespace设备; - 添加
nvme Controller,提供ioctl接口。
PCIe 的 Header 空间和 BAR 空间是 PCIe 的关键特性。Header 空间是 PCIe 设备的通有属性,所有的 PCIe Spec 功能和规范都在这里实现;BAR 空间则是设备差异化的具体体现,BAR 空间的定义决定了这个设备是网卡,SSD 还是虚拟设备。BAR 空间是 Host 和 PCIe 设备进行信息交互的重要介质,BAR 空间的数据实际存储在 PCIe 设备上。Host 这边给 PCIe 设备分配的地址资源,并不占用 Host 的内存资源。当读写 BAR 空间时,都需要通过 PCIe 接口(通过PCI TLP 消息)进行实际的数据传输。
接着来看下 nvme_driver 结构体中的 .probe 函数 nvme_probe,
static int nvme_probe(struct pci_dev *pdev, const struct pci_device_id *id)
{
int node, result = -ENOMEM;
struct nvme_dev *dev;
unsigned long quirks = id->driver_data;
size_t alloc_size;
node = dev_to_node(&pdev->dev);
if (node == NUMA_NO_NODE)
set_dev_node(&pdev->dev, first_memory_node);
dev = kzalloc_node(sizeof(*dev), GFP_KERNEL, node);
if (!dev)
return -ENOMEM;
dev->nr_write_queues = write_queues;
dev->nr_poll_queues = poll_queues;
dev->nr_allocated_queues = nvme_max_io_queues(dev) + 1;
dev->queues = kcalloc_node(dev->nr_allocated_queues,
sizeof(struct nvme_queue), GFP_KERNEL, node);
if (!dev->queues)
goto free;
dev->dev = get_device(&pdev->dev);
pci_set_drvdata(pdev, dev);
result = nvme_dev_map(dev);
if (result)
goto put_pci;
INIT_WORK(&dev->ctrl.reset_work, nvme_reset_work);
INIT_WORK(&dev->remove_work, nvme_remove_dead_ctrl_work);
mutex_init(&dev->shutdown_lock);
result = nvme_setup_prp_pools(dev);
if (result)
goto unmap;
quirks |= check_vendor_combination_bug(pdev);
if (!noacpi && acpi_storage_d3(&pdev->dev)) {
/*
* Some systems use a bios work around to ask for D3 on
* platforms that support kernel managed suspend.
*/
dev_info(&pdev->dev,
"platform quirk: setting simple suspend\n");
quirks |= NVME_QUIRK_SIMPLE_SUSPEND;
}
/*
* Double check that our mempool alloc size will cover the biggest
* command we support.
*/
alloc_size = nvme_pci_iod_alloc_size();
WARN_ON_ONCE(alloc_size > PAGE_SIZE);
dev->iod_mempool = mempool_create_node(1, mempool_kmalloc,
mempool_kfree,
(void *) alloc_size,
GFP_KERNEL, node);
if (!dev->iod_mempool) {
result = -ENOMEM;
goto release_pools;
}
result = nvme_init_ctrl(&dev->ctrl, &pdev->dev, &nvme_pci_ctrl_ops,
quirks);
if (result)
goto release_mempool;
dev_info(dev->ctrl.device, "pci function %s\n", dev_name(&pdev->dev));
nvme_reset_ctrl(&dev->ctrl);
async_schedule(nvme_async_probe, dev);
return 0;
nvme_probe 函数会通过 nvme_dev_map 函数 (层层调用之后) 映射设备的 BAR 空间到内核的虚拟地址空间当中, PCI 协议里规定了 PCI 设备的配置空间里有 6 个 32 位的 BAR 寄存器,代表了 PCI 设备上的一段内存空间,可以通过writel,readl 这类函数直接读写寄存器,并分配设备数据结构 nvme_dev,队列 nvme_queue 等。
nvme_dev 结构体如下,
/*
* Represents an NVM Express device. Each nvme_dev is a PCI function.
*/
struct nvme_dev {
struct nvme_queue *queues;
struct blk_mq_tag_set tagset;
struct blk_mq_tag_set admin_tagset;
u32 __iomem *dbs;
struct device *dev;
struct dma_pool *prp_page_pool;
struct dma_pool *prp_small_pool;
unsigned online_queues;
unsigned max_qid;
unsigned io_queues[HCTX_MAX_TYPES];
unsigned int num_vecs;
u32 q_depth;
int io_sqes;
u32 db_stride;
void __iomem *bar;
unsigned long bar_mapped_size;
struct work_struct remove_work;
struct mutex shutdown_lock;
bool subsystem;
u64 cmb_size;
bool cmb_use_sqes;
u32 cmbsz;
u32 cmbloc;
struct nvme_ctrl ctrl;
u32 last_ps;
bool hmb;
mempool_t *iod_mempool;
/* shadow doorbell buffer support: */
u32 *dbbuf_dbs;
dma_addr_t dbbuf_dbs_dma_addr;
u32 *dbbuf_eis;
dma_addr_t dbbuf_eis_dma_addr;
/* host memory buffer support: */
u64 host_mem_size;
u32 nr_host_mem_descs;
dma_addr_t host_mem_descs_dma;
struct nvme_host_mem_buf_desc *host_mem_descs;
void **host_mem_desc_bufs;
unsigned int nr_allocated_queues;
unsigned int nr_write_queues;
unsigned int nr_poll_queues;
bool attrs_added;
};
每个设备至少两个队列,一个是 admin 管理命令,一个是给 I / O 命令,这个队列概念和之前介绍块驱动中的磁盘队列一个道理,只是那个驱动比较基础,所以命令和IO并不区分队列,nvme_queue 具体结构体如下,
/*
* An NVM Express queue. Each device has at least two (one for admin
* commands and one for I/O commands).
*/
struct nvme_queue {
struct nvme_dev *dev;
spinlock_t sq_lock;
void *sq_cmds;
/* only used for poll queues: */
spinlock_t cq_poll_lock ____cacheline_aligned_in_smp;
struct nvme_completion *cqes;
dma_addr_t sq_dma_addr;
dma_addr_t cq_dma_addr;
u32 __iomem *q_db;
u32 q_depth;
u16 cq_vector;
u16 sq_tail;
u16 last_sq_tail;
u16 cq_head;
u16 qid;
u8 cq_phase;
u8 sqes;
unsigned long flags;
#define NVMEQ_ENABLED 0
#define NVMEQ_SQ_CMB 1
#define NVMEQ_DELETE_ERROR 2
#define NVMEQ_POLLED 3
u32 *dbbuf_sq_db;
u32 *dbbuf_cq_db;
u32 *dbbuf_sq_ei;
u32 *dbbuf_cq_ei;
struct completion delete_done;
};
继续说 nvme_probe 函数,nvme_setup_prp_pools 主要是创建 dma pool,后面可以通过 dma 函数从 dma pool 中获得memory。主要是为了给 4k 和 128k 的不同 IO 来做优化。
nvme_init_ctrl 函数会创建 NVMe 控制器结构体,这样在后后续 probe 阶段时候用初始化过的结构,其传入的操作函数集是 nvme_pci_ctrl_ops,如下所示,
static const struct nvme_ctrl_ops nvme_pci_ctrl_ops = {
.name = "pcie",
.module = THIS_MODULE,
.flags = NVME_F_METADATA_SUPPORTED,
.reg_read32 = nvme_pci_reg_read32,
.reg_write32 = nvme_pci_reg_write32,
.reg_read64 = nvme_pci_reg_read64,
.free_ctrl = nvme_pci_free_ctrl,
.submit_async_event = nvme_pci_submit_async_event,
.get_address = nvme_pci_get_address,
.print_device_info = nvme_pci_print_device_info,
.supports_pci_p2pdma = nvme_pci_supports_pci_p2pdma,
};
另外 NVMe 磁盘的操作函数集,例如打开,释放等属于 block_device_operations ( drivers/nvme/host/core.c 5 ),其结构体如下,
static const struct block_device_operations nvme_bdev_ops = {
.owner = THIS_MODULE,
.ioctl = nvme_ioctl,
.compat_ioctl = blkdev_compat_ptr_ioctl,
.open = nvme_open,
.release = nvme_release,
.getgeo = nvme_getgeo,
.report_zones = nvme_report_zones,
.pr_ops = &nvme_pr_ops,
};
创建 NVMe 块设备
参考这里 3
对于 Linux 的块设备来说,其主要的是通过调用 device_add_disk 或者 add_disk 函数(后者是对前者的简单包装)在 /dev 目录下创建块设备,来实现向操作系统添加一个设备实例。
NVMe 本身也是块设备,自然也不会跳出这个大框架。
NVMe 块设备文件操作集合会在 add_disk 时通过 block_device_operations ( drivers/nvme/host/multipath.c 6 ) 进行声明,代码如下:
const struct block_device_operations nvme_ns_head_ops = {
.owner = THIS_MODULE,
.submit_bio = nvme_ns_head_submit_bio,
.open = nvme_ns_head_open,
.release = nvme_ns_head_release,
.ioctl = nvme_ns_head_ioctl,
.compat_ioctl = blkdev_compat_ptr_ioctl,
.getgeo = nvme_getgeo,
.report_zones = nvme_ns_head_report_zones,
.pr_ops = &nvme_pr_ops,
};
其中 ownder 表示该 nvme_ns_head_ops 的所有者是 NVMe 块设备驱动,而 ioctl 和 compat_ioctl 分别是用户调用 ioctl 的两种方式。
进入 nvme_ns_head_ioctl (如下所示)接口,
int nvme_ns_head_ioctl(struct block_device *bdev, fmode_t mode,
unsigned int cmd, unsigned long arg)
{
struct nvme_ns_head *head = bdev->bd_disk->private_data;
void __user *argp = (void __user *)arg;
struct nvme_ns *ns;
int srcu_idx, ret = -EWOULDBLOCK;
srcu_idx = srcu_read_lock(&head->srcu);
ns = nvme_find_path(head);
if (!ns)
goto out_unlock;
/*
* Handle ioctls that apply to the controller instead of the namespace
* seperately and drop the ns SRCU reference early. This avoids a
* deadlock when deleting namespaces using the passthrough interface.
*/
if (is_ctrl_ioctl(cmd))
return nvme_ns_head_ctrl_ioctl(ns, cmd, argp, head, srcu_idx);
ret = nvme_ns_ioctl(ns, cmd, argp);
out_unlock:
srcu_read_unlock(&head->srcu, srcu_idx);
return ret;
}
硬件层面
首先从硬件层面上,我们知道任何设备必须通过某个总线与 CPU 向连接,NVMe 则正是通过PCIe 总线与 CPU 相连,如下所示:

当然,目前 NVMe 除了可以通过 PCIe 总线与 CPU 相连外,还可以通过其它通道连接,比如FC 或者 IB。后者则是一种将 NVMe 设备从计算节点独立出来的方式,也就是此时 NVMe 就不再是一个卡设备,而是一个独立机箱的设备。无论何种方式相连接,其本质是一样的。
软件层面
硬件的连通性是基础,当硬件已经连通后,就可以在 Linux 内核层面发现设备,并进行初始化了。
软件层面的初始化有两种情况:
- 计算机启动的时候,操作系统会扫描总线上的设备,并完成初始化;
- 设备在系统启动后连接的,此时需要手动触发扫描的过程。
无论是系统启动也好,还是手动触发扫描也好,NVMe 发现设备的核心流程是一样的,如下所示:

与其它块设备类似,NVMe 设备初始化完成后会在 /dev 目录下出现一个文件。NVMe 设备会出现一个形如 nvmeXnY 的设备文件。
如下图所示,红色方框中的为一个 NVMe 块设备,
上面我们简要的介绍了初始化的主流程。
在上面初始化流程中需要重点关注的是 nvme_alloc_ns 函数的流程。该函数完成了块设备创建基本信息填充和块设备注册到内核等工作。
在整个初始化流程中比较关键的是对请求队列( request_queue )中请求处理函数指针(make_request_fn)的初始化及多队列函数集( mq_ops )的初始化。因为,这里的函数正是NVMe 区别于 SCSI 等类型设备数据处理流程的地方。
NVMe 设备的 IO 流程
参考这里 1’ 2
机械硬盘时代,由于其随机访问性能差,内核开发者主要放在缓存 I / O、合并 I / O 等方面,并没有考虑多队列的设计。
而 Flash 的出现,性能出现了戏剧性的反转,因为单个 CPU 每秒发出 IO 请求数量是有限的,所以促进了 IO 多队列开发。
驱动中的队列创建,通过函数 kcalloc_node ( drivers/nvme/host/pci.c 4 ) 如下,
dev->queues = kcalloc_node(dev->nr_allocated_queues,
sizeof(struct nvme_queue), GFP_KERNEL, node);
if (!dev->queues)
goto free;
Queue 有的概念,那就是队列深度,表示其能够放多少个成员。在 NVMe 中,这个队列深度是由 NVMe SSD 决定的,存储在 NVMe 设备的 BAR 空间里。
队列用来存放 NVMe Command,NVMe Command 是主机与 SSD 控制器交流的基本单元,应用的 I/O 请求也要转化成NVMe Command。
不过需要注意的是,就算有很多 CPU 发送请求,但是 Block 层并不能保证都能处理完,将来可能要绕过 IO 栈的块层,不然瓶颈就是操作系统本身了。
当前 Linux 内核提供了 blk_queue_make_request 函数,调用这个函数注册自定义的队列处理方法,可以绕过 IO 调度和 io 队列,从而缩短 io 延时。Block 层收到上层发送的 IO 请求,就会选择该方法处理。
为了便于理解 NVMe 的处理流程,我们给出了传统 SCSI 及 NVMe 数据处理的对比流程,如下图所示,
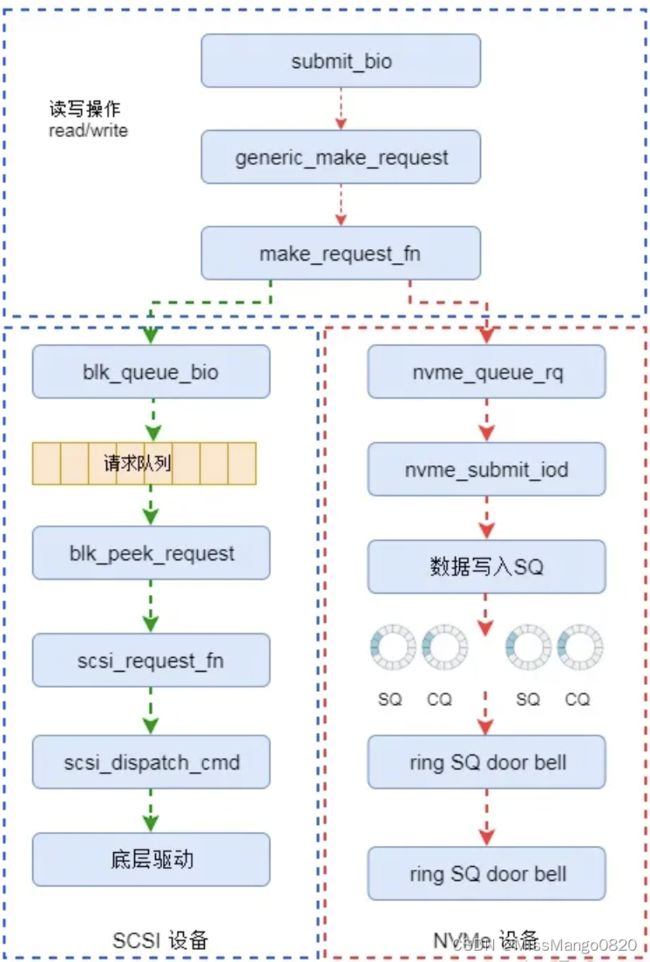
整个流程是从通用块层的接口( submit_bio )开始的。
对于 NVMe 设备来说,在初始化的时候初始化函数指针 make_request_fn 为 nvme_queue_rq,该函数就是 NVMe 驱动程序的请求处理接口。该函数最终会将请求写入 NVMe 中的 SQ 队列当中,并通知控制器处理请求。
相对于 SCSI 设备来说,NVMe 设备的驱动还是非常简单的。
DMA
参考这里 1
PCIe 有个寄存器位 Bus Master Enable,这个 bit 置 1 后,PCIe 设备就可以向 Host 发送 DMA Read Memory 和 DMA Write Memory 请求。
当 Host 的 driver 需要跟 PCIe 设备传输数据的时候,只需要告诉 PCIe 设备存放数据的地址就可以。
NVMe Command 占用 64 个字节,另外其 PCIe BAR 空间被映射到虚拟内存空间(其中包括用来通知 NVMe SSD Controller 读取 Command 的 Doorbell 寄存器)。
NVMe 数据传输都是通过 NVMe Command,而 NVMe Command 则存放在 NVMe Queue 中,其配置如下图,
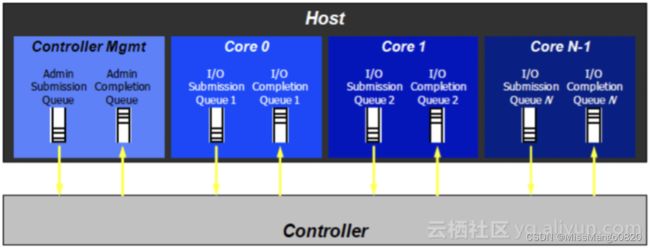
其中队列中有 Submission Queue,Completion Queue 两个。
参考链接
#TODO
nvme驱动分析
Linux中nvme驱动详解 ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
NVMe的Linux内核驱动分析 ↩︎ ↩︎
linux NVMe驱动总结 ↩︎ ↩︎
linux/drivers/nvme/host/pci.c ↩︎ ↩︎
linux/drivers/nvme/host/core.c ↩︎
linux/drivers/nvme/host/multipath.c ↩︎