模拟tcmalloc的小型高并发内存池项目
前言
本项目仅为了学习并提升代码能力,不作为实际运用。
项目完整代码地址:gitee仓库地址

文章目录
-
- 前言
- 1.项目介绍
- 2.什么是内存池
-
- 2.1 池化技术
- 2.2 内存池
- 2.3 内存池主要解决的问题
- 2.4 malloc
- 3. 先设计一个定长的内存池
- 4.高并发内存池整体框架设计
- 5.`thread cache`整体设计
- 6.哈希桶映射对齐规则
- 7. TLS -- thread local storage
- 8.`central cache`的整体设计
- 9.`central cache`结构设计
- 10.`central cache`核心实现
- 11. `page cache`的整体设计
- 12 `page cache`中获取`Span`上
- 13`page cache`中获取`Span`中
- 14. threadcache回收内存
- 15. central cache回收内存
- 16. pagecache回收内存
- 17. 大于256KB的大块内存申请问题
- 18. 释放对象时优化为不传对象大小
- 19. 多线程环境对比malloc测试
- 20. 性能瓶颈分析
- 21. 针对性能瓶颈使用基数树优化
- 22. 使用基数树进行优化代码实现
1.项目介绍
项目原型是google的开源项目tcmalloc。即线程缓存的malloc,实现了高效的多线程内存管理,用于替代系统的内存分配相关的函数malloc和free。
项目特点:1.比较难 2.知名度高(很多的大厂程序员都知道这个项目,并且go语言的内存分配器就是这个)所以面试官可能会问的很细。
知识点:C/C++,数据结构(链表,哈希桶),操作系统内存管理,单例模式,多线程,互斥锁
2.什么是内存池
2.1 池化技术
“池化技术”就是程序向系统先申请过量资源,然后自己管理,以备不是之需。因为每一次申请资源都需要较大的开销,所以提前申请好了资源,这样在使用的时候,就会大大提高程序运行的效率。
除了内存池,还有连接池,线程池,对象池等等。以线程池为例,它的主要思想就是:先启动若干数量的线程,让它们先处于睡眠状态,当接收客户端的请求的时候,唤醒线程池中的某个睡眠的线程来处于客户端的请求,当处理完这个请求后,该线程再进入睡眠状态。
2.2 内存池
原理和线程池类似
2.3 内存池主要解决的问题
内存池主要可以解决两个方面的问题:
- 效率问题
- 内存碎片问题
内存碎片分两种
- 外碎片
- 内碎片
例子: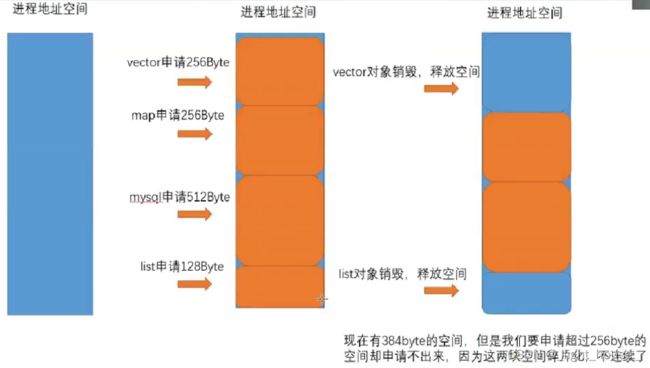
(外碎片)
2.4 malloc
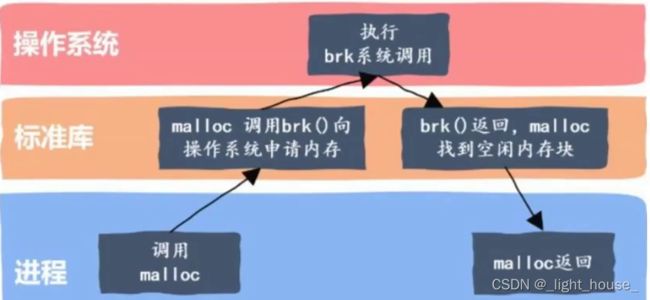
malloc实际就是一个内存池,malloc相当于向操作系统“批发”了一块较大的内存空间,然后“零售”给不同的进程。
但是malloc的实现方式有很多种。windows中有自己vs系列的一套,linux中有ptmalloc。
有很多的文章讲到了malloc的实现方式可以看看malloc的实现。
tcmalloc比普通的malloc要快,并且在多线程高发可以很快
3. 先设计一个定长的内存池
先做一个定长的内存池,一方面可以先熟悉一下内存池,另一方面可以作为后面项目的一个基础组件。
定长内存池的功能:
- 定长的内存池可以解决,固定大小的内存申请释放需求。这里为了后面可以方便当成组件使用。所以这里需要传入一个对象,根据对象的大小可以分配内存。
项目特点:
- 性能达到极值
- 不考虑内存碎片的问题
设计思想:
- 特点在于使用自由链表来管理归还后的资源。每一次申请T对象大小的内存的时候先去链表中找,如果链表中没有资源了,再直接去向系统申请。
问题1:不采用
void* _memory,而是采用char* _memory?
使用char*方便后面可以方便切内存使用
问题2:如何处理归归还之后的内存呢?
采用自由链表的方式。使用void* freeList存储第一个归还的内存块的地址,然后第二个内存块(32位下必须大于4字节)的头4字节去存储第二个内存块的地址,最后一个在freeList中的内存块指向nullptr即可。也就是freeList中的节点就是一个个归还回来的内存块 。

问题3:如何知道何时再分配资源?
引入成员变量_leftBytes,统计当前内存池还剩下可用的内存块的字节数。当剩余空间小于一个申请对象的时候,这个时候就说明当前的内存块不够用了,所以就需要重新的申请空间。而当前剩下的一些内存就不要了。
问题4:如何将第一个内存块放入一个空的
_freeList中?
我们只需要将_freeList指向第一块内存即可。但是又有一个问题,此时这个内存块既是第一个内存块也是最后一个内存块,所以需要将内存块的前部分指向nullptr,而空指针是4个字节,因为需要将头4个字节填上nullptr。这里有一个技巧取用头4个字节:可以先将obj强转成(int*),然后再解引用就可以拿到4个字节了。(使用不同类型的指针访问内存是一个技巧)。
问题5:32位上程序是没有问题的,但是64位上程序就不对了。
因为32位下的指针大小是4字节,64位下的指针是8字节,那么为了保证开辟的空间大小正确,可以开辟一个指针的大小同时也可以转成一个指针,所以就可以强转成(void**)(解释:将void*看成一个整体,那么我们就需要开辟一个void*大小的空间,此时指针void*就可以随着平台的不同而产生变化也就可以满足我们的需求),然后再解引用,即*(void**)obj = nullptr。当然如果麻烦一点的话,就可以直接判断当前平台下一个指针的大小,根据一个指针的大小使用if判断开多大的空间。
问题6:删除操作的简便写法。
我们在处理归还的费第一个节点时,采用头插法的效率最高。那么其实就可以直接所有的插入操作都写成头插,这样也不用特殊处理第一个节点了。
问题7:在分配空间的最开始,应该考虑
_freeList是否有可用的空间
在分配空间的时候,需要先考虑回收的自由链表中是否存在可用的内存。如果自由链表中存在可用的内存,那么就不用向系统再申请内存空间了。
问题8:如果归还的内存块不满4/8个字节也就是不能存放一个指针的大小,也就无法保存下一个空间的地址,怎么办?
为了让一个内存块一定可以保存一个指针,所以在分配内存空间的时候,我们需要判断一个内存块的大小,如果大于一个指针的大小,那么可以直接分配;如果小于一个指针的大小,就可以分配一个指针的大小。这样就可以保证每一个内存块都一定可以保存一个指针的大小。
问题9:需要主动处理内存块中对象的内容
当分配空间的时候,需要使用定位new去主动的调用T对象的构造函数。在将内存块回收的时候,需要主动调用T对象的析构函数。
- placement new 有两个作用
- 1.在使用
operator new分配好内存空间后,可以使用定位去驱主动的调用构造函数 - 2.使用定位new可以返回指向这个对象的地址
- 1.在使用
问题10:如果我们想要使得我们制作的内存池更加纯粹的话,那么申请空间的时候就不使用
malloc而是直接向系统申请内存。
malloc是一个内存池,所以为了使得申请内存资源的操作更加纯粹的话,可以直接使用相关的系统接口,以页为单位向系统直接申请系统内存。
如果想要直接向系统申请内存的话,在windows下可以使用VirtualAlloc,在linux下可以使用brk()或者mmap()。
mmap可以将文件的内容映射进进程的虚拟地址空间,这样就可以不用read和write对文件进行操作。brk是将数据段的最高地址指针_edata指针往高地址推
#include - 作用
- 将
brk指针指向addr的位置上
- 将
- 参数
addr:将brk推到addr的位置上
- 返回值
- 成功返回0,失败返回-1
#include - 作用
- 推动
brk指针,增加increment大小的内存
- 推动
- 参数
increment:增加的内存大小
- 返回值
- 返回旧的
brk指向的位置
- 返回旧的
**使用技巧:**使用sbrk可以更方便地分配指定的内存空间,因为在释放空间的时候必须要重新定位指针的位置。使用brk可以更方便地释放内存,因为不能确定brk指针的位置。
所以设置一个brk指针的锚点,使用sbrk动态分配内存,而brk可以以锚点为基础回收内存。

#pragma once
#include 4.高并发内存池整体框架设计
malloc本身已经很优秀了,但是本项目中tcmalloc在多线程高并发的场景下更胜一筹,所以实现的内存池需要考虑一下问题:
- 性能问题
- 多线程环境下,锁竞争问题
- 内存碎片问题
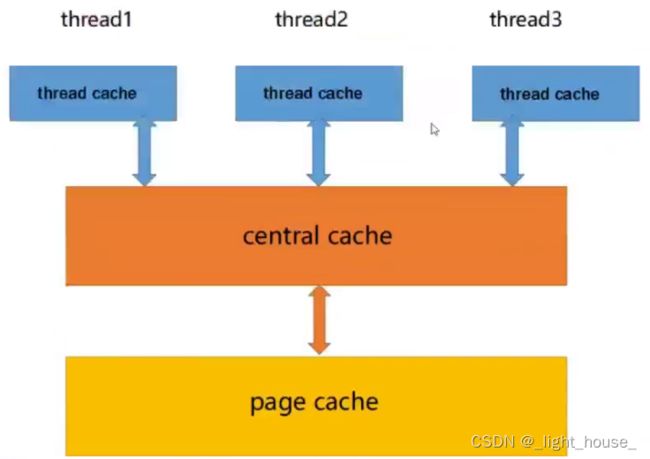
ConcurrentMemoryPool主要有以下的3个部分组成:
thread cache:线程缓存是每个线程独有(后面会讲实现) 的,用于小于256KB的内存分配,线程从这个申请内存是不需要加锁的,每一个线程独享一个cache,这就是并发线程池高效的问题。central cache:中心缓存是所有线程共享的。thread cache按需从central cache中获取对象的。central cache在适合的时机(后面会讲实现) 回收thread cache中的对象,避免一个线程会占用太多的资源,而其他的线程会资源紧缺,达到了内存分配在多个线程中更均衡的按需调度的目的。central cache在资源调度的时候,是存在资源竞争的,所以 取内存对象的时候需要加锁。但是这个采用的时候桶锁,所以只要当多个线程竞争同一个桶中的资源的时候才会加锁,而且是由threal cache没有内存对象的时候才会申请资源,所以这个内存申请资源不会很激烈。page cache:页缓存是在central cache缓存上面的一层缓存,存储的内存是以页为单位存储以及分配的。 当central没有缓存的时候,从page cache中分配出一定数量的page并且并且切割成定长大小的小块内存,分配给central cache。当central cache中一个span的几个跨度页的对象都回收回来之后,page cache会回收central cache中满足条件的span对象并且会合并成相邻的页,组成更大的页,缓解了内存碎片的问题。
5.thread cache整体设计
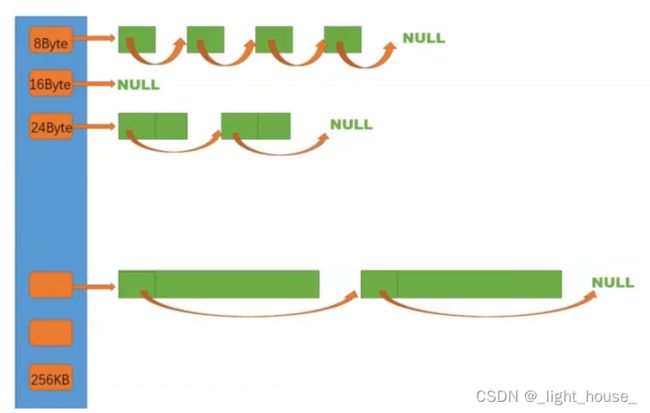
前面定长内存池使用自由链表的结构来分配内存,但是链表中的节点都是定长的。为了适应不同长度的内存块分配情况,可以使用多个连接着不同字节大小的内存块的链表。
但是thread cache中最大的内存块是256KB,如果我们为了精确分配的内存的话,需要使用256*1024个链表(256KB=256×1024B)的话就太浪费了。所以我们可以使用8B,16B,24B…256KB这样粗略地分一下即可,在申请资源的时候是要去大于等于当前申请内存的最小内存块即可 (按照一定大小进行内存对齐)。
这样设计缺点在于可能会有很多的空间浪费,造成内存碎片,并且是内碎片。
- 外碎片:分配空间在归还之后,导致内存空间不连续,不能连续分配。
- 内碎片:在分配内存给对象之后,由于内存对齐等缘故导致内存块中有一个空间不可能使用到,但是已经分配过内存了。
另外thread cache采用哈希桶结构,每一个桶中是按桶的大小去映射的,即桶中的自由链表的内存块对象大小等于桶大小,使用哈希映射可以快速得到线程星想要得到的内存块的大小。这样设计使得每一个线程都有一个一个thread cache对象,每一个线程获取对象和释放对象时是无锁的。
问题1:处理哈希桶中自由链表问题。
由于每一个哈表桶中都需要挂一个自由链表,所以可以将自由链表封装成一个类专门管理小内存块。
// 统一写法,取出一块内存头部的4/8个字节存放下一个内存块的地址
void*& NextObj(void* obj)
{
return *(void**)obj;
}
// 管理切好的小块内存的自由链表
class FreeList
{
public:
// 采用头插
void Push(void* obj)
{
// 如果obj为nullptr则不能插入
assert(obj);
// 头插内存块
//*(void**)obj = _freeList;
NextObj(obj) = _freeList;
_freeList = obj;
}
// 采用头删
void* Pop()
{
// 如果_freeList为nullptr则不能删除
assert(_freeList);
// 头删内存块
void* obj = _freeList;
_freeList = NextObj(_freeList);
return obj;
}
private:
void* _freeList;
};
class ThreadCache
{
public:
void* Allocate(size_t size);
void Deallocate(void* ptr, size_t size);
private:
// 问题1
};
6.哈希桶映射对齐规则
问题1:给一个需要内存块的大小
size,怎么将这个内存块对齐呢?
使用一个类专门来管理和计算对象大小的内存对齐的映射规则。其中至少要按8字节对齐,因为64平台下一个指针都8字节。但是如果256KB都按8字节对齐的话,需要3万多个哈希桶,所以可以进一步的改造一下,每一个字节范围内按一个字节数来对齐。
- [1, 128]字节按8bytes对齐
- freeList(桶位置)[0, 16)
- [128 + 1, 1024]字节按16bytes对齐
- freeList(桶位置)[16, 72)
- [1024 + 1, 1024 * 8]字节按128bytes对齐
- freeList(桶位置)[72, 128)
- [8 * 1024 + 1, 64 * 1024 ]字节按1024bytes对齐
- freeList(桶位置)[128, 184)
- [64 * 1024 + 1, 256 * 1024]字节按8* 1024 bytes对齐
- freeList(桶位置)[184, 208)
这样就可以控制最多10%左右的内存碎片浪费。前期的对齐数小一点,后面的对齐数变大。
// "common.h"中
// 最大的自由链表数量
static const size_t NFREE_LISTS = 208;
// threadcache中最大分配的内存块的大小
static const size_t MAX_BYTES = 256 * 1024;
class SizeClass
{
public:
static inline size_t _RoundUp(size_t size, size_t alignNum)
{
// 将size按alignNum对齐数对齐
return ((size + alignNum - 1) & ~(alignNum - 1));
// 也可以这样
//return (size + alignNum - 1) / alignNum * alignNum;
}
// 为了保证在类外可以直接调用函数,而不是使用对象调用函数
// 所以可以将函数设置成static的
static inline size_t RoundUp(size_t size)
{
if (size <= 128)
{
return _RoundUp(size, 8);
}
else if (size <= 1024)
{
return _RoundUp(size, 16);
}
else if (size <= 8 * 1024)
{
return _RoundUp(size, 128);
}
else if (size <= 64 * 1024)
{
return _RoundUp(size, 1024);
}
else if (size <= 256 * 1024)
{
return _RoundUp(size, 8 * 1024);
}
else
{
// 分配的内存不能大于256KB
assert(false);
return -1;
// 其实如果超过256KB也是可以申请的,后面会讲
}
}
static inline size_t _Index(size_t size, size_t align_shift) {
// 其实就是size/2^(align_shift)上取整然后-1
return ((size + (1 << align_shift) - 1) >> align_shift) - 1;
}
// 计算自由链表所在哈希桶中的位置
static inline size_t Index(size_t size)
{
// 每一个区间中有多少的自由链表
static int group_array[4] = { 16, 56, 56, 56 };
if (size <= 128)
{
return _Index(size, 3);
}
else if (size <= 1024)
{
return _Index(size - 128, 4) + group_array[0];
}
else if (size <= 8 * 1024)
{
return _Index(size - 1024, 7) + group_array[0] + group_array[1];
}
else if (size <= 64 * 1024)
{
return _Index(size - 8 * 1024, 10) + group_array[0] + group_array[1] + group_array[2];
}
else if (size <= 256 * 1024)
{
return _Index(size - 64 * 1024, 13) + group_array[0] + group_array[1] + group_array[2] + group_array[3];
}
else
{
assert(false);
return -1;
}
}
};
// "ThreadCache.h"中
class ThreadCache
{
public:
void* Allocate(size_t size);
void Deallocate(void* ptr, size_t size);
// 从centralcache中获取内存
void* FetchFromCentralCache(size_t index, size_t size);
private:
// 用数组模拟哈希表,最多有NFREE_LISTS
FreeList _freeLists[NFREE_LISTS];
};
// ”ThreahCache.cpp“中
void* ThreadCache::Allocate(size_t size)
{
// threadcache最多只能分配256KB
assert(size <= MAX_BYTES);
// size对齐之后的字节数
size_t alignSize = SizeClass::RoundUp(size);
// size字节数对应的哈希桶的位置
size_t index = SizeClass::Index(size);
// 如果申请内存大小对应的哈希桶中的自由链表为空,就去centralcache中拿
// 否则直接从自由链表中获取即可
if (_freeLists[index].Empty())
{
return FetchFromCentralCache(index, alignSize);
}
else
{
return _freeLists[index].Pop();
}
}
void ThreadCache::Deallocate(void* ptr, size_t size)
{
// ...
}
7. TLS – thread local storage
问题0:什么是TLS?
TLS(线程局部存储),是一种变量的存储方法,这个变量在它所在的线程内是全局可访问的,但是不能被其他线程访问到,这样就保证了数据的线程独立性。
问题1:为什么需要
TLS?
为了保证每一个线程都可以有自己专属的thread cache,所以可以使用TLS,来保证每一个线程都可以无锁地获得自己的thread cache对象。TLS分为静态和动态的,使用静态的LTS最简单,只需要声明一个_declspec(thread)的变量就会给每一个线程单独的一个拷贝。
问题2:"ConcurrentAlloc.h"是什么作用?
这里需要专门准备两个函数给每一个线程调用分配内存。
问题3:
.h文件中很多的static修饰的变量和函数是为什么?
static修饰函数,改变链接属性,一个.h文件中可以被多个.cpp文件包含,所以这里使用static保证其中的static的变量或者函数只保存一份,这样就不会再生成.obj文件的时候相互冲突了,static保证了变量或者函数只在当前文件可见 。
// "ThreadCache.h"中
// 问题1
// TLS,保证每一个线程的独立
static _declspec(thread) ThreadCache* pTLSThreadCache = nullptr;
// "ConcurrentAlloc.h"中
// 问题3 && 问题2
static void* ConcurrentAlloc(size_t size)
{
// 通过TLS,每一个线程可以获得自己专属的ThreadCache对象,并且这个过程是无锁的
// 如果ThreadCache的自由链表中节点的话,那么效率则非常高
if (pTLSThreadCache == nullptr) {
pTLSThreadCache = new ThreadCache;
}
cout << std::this_thread::get_id() << ":" << pTLSThreadCache << endl;
return pTLSThreadCache->Allocate(size);
}
// 这里需要将内存归还给threadcache中,所以需要知道对应哈希桶中归还的自由链表的位置
// 但是concurrentFree()不应该有size,这里暂时这样写
static void ConcurrentFree(void* ptr, size_t size)
{
assert(pTLSThreadCache);
pTLSThreadCache->Deallocate(ptr, size);
}
8.central cache的整体设计

申请内存的过程
-
central cache也是一个哈希桶的结构。并且因为所有的线程如果自己的thread cache中没有内存的话,就都需要从central cache中获取,因此central cache需要加锁,但是是桶锁,也就是每一个哈希桶中都有一个单独的锁。central cache也有一个哈希映射的spanlist,spanlist中挂着span,从span中取出对象给thread cache这个过程也是需要加锁的。 -
central cache映射的spanlist中的所有span都没有内存之后,然后需要从page cache中申请一个新的span对象,拿到span之后将span管理的内存大小切好作为自由链表连接到一起。 -
central cache中挂的**span中的use_count记录分配了多少个对象出去。**
释放内存
- 当
thread cache归还内存的时候(可能是自由链表过长或者线程销毁了)则会将内存释放回central cache中(为了形成”均衡调度“(优点1)。),释放回来时span中的use_count --。当所有的对象都回到span中的,则span释放回到page cache,page cache中会对前后相对空闲页进行合并。(缓解了外碎片问题(优点2))
9.central cache结构设计
central cache中是以span为单位分配内存的,如果一个span中的所有节点内存都分配完了之后,central cache的哈希桶中就会申请新的span。
span是管理多个连续页大块内存跨度结构。
问题1:在32位和64位不同的平台下,页数是不同的
因为32位下最多只有 2 32 / 2 13 = 2 1 9 2^{32}/2^{13}=2^19 232/213=219个页(一页是8KB),但是64位平台下有 2 64 / 2 13 = 2 51 2^{64}/2^{13}=2^{51} 264/213=251个页,因此需要使用不同的类型保存页的个数。
所以我们要是要条件编译,并且x86下只有_WIN32,而x64下既有_WIN64也有_WIN32,因此我们需要先判断_WIN64,才可以适应两个平台
问题2:哈希桶中的结构
哈希桶中有不同的页,由span为单位,每一个span下都挂着一个自由链表。并且span之间形成一条链表。因为当span下没有可以使用的对象的时候,就需要回收,因此对于链表中的节点需要容易删除,所以采用带头双向循环链表的结构组织SpanList。
问题3:哈希桶中的锁怎么实现?
因为central cache可能会有很多的线程同时的竞争,所以我们需要上锁。但是只有多个线程竞争同一个哈希桶中的span中的内存的时候,才需要上锁,所以我们就可以在SpanList中加上锁。
// 问题1
#ifdef _WIN64
typedef unsigned long long PAGE_ID;
#elif _WIN32
typedef size_t PAGE_ID; // size_t->unsigned int
#else
// linux下
#endif
struct Span
{
// 问题1
PAGE_ID _pageId = 0; // 大内存起始页的页号
size_t _n = 0; // 页数量
Span* _next = nullptr; // Span双向链表结构
Span* _prev = nullptr;
size_t _usecount = 0; // span中的对象个数
void* _freeList = nullptr; // span中自由链表
bool _isUse = false; // span是否正在被使用
};
// 问题2
// 带头双向循环
class SpanList
{
public:
SpanList()
{
_head = new Span;
_head->_next = _head;
_head->_prev = _head;
}
// 将span插入到双向链表中
void Insert(Span* pos, Span* newSpan)
{
assert(pos);
assert(newSpan);
Span* prev = pos->_prev;
prev->_next = newSpan;
newSpan->_prev = prev;
newSpan->_next = pos;
pos->_prev = newSpan;
}
// 将span从双向链表中删除
void Erase(Span* pos)
{
assert(pos);
assert(pos != _head);
pos->_prev->_next = pos->_next;
pos->_next->_prev = pos->_prev;
// 这里可以不用删除这个节点,因为当span中没有节点的时候就会自动的归还给pagecache
// delete pos;
}
private:
Span* _head;
// 问题3
std::mutex _mtx; // 桶锁
};
10.central cache核心实现
问题1:线程怎么保证只从一个
central cache取用内存?
通过TLS指针可以使得每一个线程都有一个独立的thread cache。而所有的thread cache都需要从一个共享的central cache中取用内存,所以需要保证一个程序中只有central cache对象,因此要对这个类实行单例模式。
问题2:每一个哈希桶中的
span的中的内存块每一个从central cache中拿几个?
如果一次只拿一个,那么可能下次还需要再拿,如果遇到了两个线程同时竞争资源的话就会降低效率。但是也不能一次性给很多的内存块,否则用不完的话就会浪费。而且哈希桶中的大内存块一次性给10个和小内存块一次性给10个概念也是不同的,例如256KB对象的span可能不用着10个,但是可能8B的内存块中对象10个还不够。因此可以采用慢启动的方法平衡一下内存块分配的数量。
- 最开始可能不会需要central cache分配太多的内存块,如果分配多了可能就会浪费了多余分配的内存空间
- 如果不断地向central cache索取内存的话,会根据自己的size,批量分配的内存块数量(batchNum)会有不同程度的增长
- size越大,一次性向central cache要的batchNum越小。
- size越小,一次性向central cache要的batchNum越大。
问题3:如何从
central cache中的span中获取内存到thread cache中?
首先要从central cache上获取一个span(后面会讲解如果获取span),然后从span中获取batchNum个内存块,但是可能一个span上的内存块不足batchNum,那么有几个内存块就获取几个内存块。注意这个从central cache中的哈希桶中获取span和从span获取内存是需要加锁的。用于保持线程之间互斥性。
问题4:获得actualNum个内存块的实现过程
因为end表示指向分配内存的最后一块内存对象的指针。所以需要前提预备一块内存。即actualNum初始化值为1。也就是end最后只会链表中的最后一块内存,也就是当NextObj(end) == nullptr的时候。
// 在SizeClass中算出span中自由链表分配内存的上限
static size_t NumMoveSize(size_t size)
{
assert(size > 0);
// 根据size的大小决定内存块num的个数
size_t num = MAX_BYTES / size;
if (num < 2) {
num = 2;
}
if (num > 512) {
num = 512;
}
return num;
}
// 从centralcache的哈希桶中的链表中的span获得内存块
void* ThreadCache::FetchFromCentralCache(size_t index, size_t size)
{
// 问题2
// 慢开始反馈调节算法
// SizeClass::NumMoveSize(size)算的是这个自由链表中内存块分配的上限(根据不同的size决定上限的大小)
// _freeLists[index].MaxSize()算的是span中自由链表中的下限,并且每一次触及下限的时候会不断的增加下限
size_t batchNum = std::min(_freeLists[index].MaxSize(), SizeClass::NumMoveSize(size));
if (_freeLists[index].MaxSize() == batchNum)
{
_freeLists[index].MaxSize() += 1;
}
// [start,end]是centralcache分配的空间
// start和end都是输出型参数
void* start = nullptr;
void* end = nullptr;
// 实际从centralcache中获得内存块对象的数量
size_t actualNum = CentralCache::GetInstance()->FetchRangeObj(start, end, batchNum, size);
assert(actualNum >= 1);
// 如果内存块数量等于1,直接返回
// 否则就返回一块给用户,其余的内存块保留在threadcache中
if (actualNum == 1) {
assert(start == end);
return start;
}
else {
_freeLists[index].PushRange(NextObj(start), end);
return start;
}
}
// 获取一个非空的span
Span* CentralCache::GetOneSpan(SpanList& list, size_t size)
{
// ...
}
// 问题3
// 从central cache中获取一定数量的对象给thread cache
size_t CentralCache::FetchRangeObj(void*& start, void*& end, size_t batchNum, size_t size)
{
// 给这个从这个哈希桶中的线程加锁
size_t index = SizeClass::Index(size);
_spanLists[index]._mtx.lock();
// 从central cache中获取一个span
Span* span = GetOneSpan(_spanLists[index], size);
// 确保span中一定有_freeList(中的内存块)
assert(span);
assert(span->_freeList);
// 获取span中的节点
start = span->_freeList;
end = start;
// 如果span中的对象不够batchNum的话,span中有多少对象就给多少
size_t i = 0;
size_t actualNum = 1;
// 问题4
while (i < batchNum - 1 && NextObj(end))
{
end = NextObj(end);
i++;
actualNum++;
}
span->_freeList= NextObj(end);
NextObj(end) = nullptr;
// usecount为span中申请出去的小内存块的个数
span->_usecount += actualNum;
_spanLists[index]._mtx.unlock();
return actualNum;
}
11. page cache的整体设计

central cache需要按哈希桶的映射规则
问题1:
pagecache的整体设计。
- 首先
page cache也是一个哈希桶,哈希桶中挂着的也是span,而哈希桶中映射规则和central cache,thread cache不同,不是根据对齐的字节数来分配的,而是根据不同的page大小来分配的,在[1page, 128page]之间,最大只能按128页为单位分配内存。 - 其次
page cache也是所有的线程都共享的一个结构,所以需要使用单例模式。 - 另外
central cache因为不同的线程需要到不同的哈希桶中对应不同的字节数中取用节点,因此需要使用桶锁。但是**page cache需要对整个page cache进行上锁**。因为像page cache获取内存会设计到多个哈希桶中的内存一起变化,所以需要对整个page cache都上锁。- 其获取内存的方式是:如果要申请的
page哈希桶下没有span的话,那么就去从现存在page cache的大page下分割大page然后分成当前的需要的page,也就是一开始什么都没有的时候,page central应该会先去堆中申请一个128page大小的span,然后慢慢分割。正是这种对page central都需要多个线程去申请,所以需要对整个page cache整体上锁。(如果使用桶锁的话,就需要在有大页分割成小页的过程中就会不断的加锁解锁,这样通过在不同的哈希桶中不断切换的方式来获取资源的方式,如果使用桶锁就会带来巨大的性能消耗)
- 其获取内存的方式是:如果要申请的
page cache中的内存回收机制
如果central cache中的**span的usecount等于0**,说明分给thread cache的小块内存对象都还回来到了span中,则central cache那这个span还给page cache,page cache通过页号,查看前后的相邻页是否存在空闲,如果是空闲的话就合并两个页形成一个更大的页,缓解了内存碎片的问题。
// pagecache的哈希桶中桶的个数
static const size_t NPAGES = 128;
// 问题1
class PageCache
{
public:
// 单例模式(饿汉模式)
PageCache* GetInstance()
{
return &_sInst;
}
// 获取一个K也的span
Span* NewSpan(size_t k);
private:
SpanList _spanLists[NPAGES];
private:
PageCache() {}
PageCache(const PageCache&) = delete;
PageCache& operator=(const PageCache&) = delete;
static PageCache _sInst;
// pagecache中使用一个大锁可以锁住整个pagecache,而不是桶锁
// 因为这个时候不同页对应的哈希桶中已经产生了相互的关系
std::mutex _pageMtx;
};
12 page cache中获取Span上
问题1:可以从哪些地方获取Span?获取Span的顺序?
如果想要获取一个Span的话,可以从从centralcache的哈希桶中的SpanList中获取Span。也可以向pagecache获取Span。
我们应该先在centralcache的哈希桶中的SpanList中查看是否存在Span。如果centralcache本身就有Span,就不用向系统申请了。如果没有,就需要从pagecache中再获取。
问题2:如何计算一次系统获取几个页内存?
计算出size大小的节点需要的batchNum(自由链表中的内存节点数量)的上限。利用页数计算出字节数然后换算成页数。
问题3:获取Span后,需要堆Span做哪些处理?
因为从pagecache中获取的是NumMovePage(size)大小的的内存块,所以这个内存块是连续整块的。而threadcache中需要的是大小为size 的内存对象,所以需要对从pagecache获取的span进行切割。
- 通过页号和页中
span个数计算出span的起始地址和内存大小。- 注意:接收span的起始地址的时候,需要使用
char*接收。是为了后面方便切分内存。
- 注意:接收span的起始地址的时候,需要使用
- 把span切分并且组织成链表的形式,放在
span->_freeList下- 采用尾插的方式插入内存节点,所以可以先将第一块内存切下来,然后将后面切割的内存尾插在第一个内存的后面
- 将切分好的
span放入centralcache对应的哈希表的SpanList双链链表中
// "common.h"中
// 计算一次项centralcache申请的页数的上限
static size_t NumMoveSize(size_t size)
{
assert(size > 0);
// 根据size的大小决定内存块num的个数
size_t num = MAX_BYTES / size;
if (num < 2) {
num = 2;
}
if (num > 512) {
num = 512;
}
return num;
}
// 计算一个向系统申请的页数
static size_t NumMovePage(size_t size)
{
// 问题2
size_t batchNum = NumMoveSize(size);
size_t npage = batchNum * size;
npage >>= PAGE_SHIFT;
if (npage == 0)
npage = 1;
return npage;
}
// central cache向pagecache要一个span
// 获取一个非空的span
Span* CentralCache::GetOneSpan(SpanList& list, size_t size)
{
// 问题1
Span* it = list.Begin();
while (it != list.End())
{
if (it->_freeList != nullptr)
{
return it;
}
it = it->_next;
}
// 走到这里说明当前的spanlist中没有空闲的span了,需要找page cache要
// 问题2
Span* span = PageCache::GetInstance()->NewSpan(SizeClass::NumMovePage(size));
// 问题3
char* start = (char*)(span->_pageId << PAGE_SHIFT);
size_t bytes = span->_n << PAGE_SHIFT;
char* end = start + bytes;
span->_freeList = start;
void* tail = span->_freeList;
start += size;
while (start < end)
{
// 尾插内存节点到span的自由链表中
NextObj(tail) = start;
tail = start;
start += size;
}
// 将切分好的span放入哈希桶中
list.PushFront(span);
return span;
}
13page cache中获取Span中
上面说的是假设central cache已经从page cache中获取一个span了,如何处理这个大块的内存(以页数为单位)。
下面要说的是
page cache如何分配给central cachek页的span。
问题1:对于
central cache的桶锁和page cache的整个锁怎么处理?两者之间的关系?
整个page cache都加锁(因为可能小页数的page的哈希桶会向大页数的page的哈希桶要切割下来的page大内存)。在page cache整体加锁的时候,这个时候central cache的桶锁最好解掉。
虽然当申请span的线程还是需要等待申请span(因为page cache被锁住一定是内存不够用),但是此时如果有central cache中的线程归还内存的话就会降低归还的效率了。
当线程向pagecache申请Span的时候,可能会有其他向centralcache申请内存的线程,所以为了不影响在等待从pagecache中申请内存的效率,因此可以在一个线程向pagecache申请span的时候,将centralcache的桶锁解掉。
所以需要在centralcache的GetOneSpan中的向page cache的NewSpan前将锁解掉。并且为了显式地证明page cache是整体锁住的,所以可以直接在NewSpan外面用所锁住。在得到page cache给的span后,可以不用着急的用锁锁住,因为当前的Span不在哈希桶的双链表(双链表是临界资源)中,所以不可能会出现多线程竞争的问题,这个Span只能被当前线程访问,所以可以等到span被切分之后插入到_spanList中的时候会对申请_spanList的线程竞争的时候需要将锁在锁住。
并且根据NewSpan中的递归逻辑,可以知道只能将锁加在调用NewSpan函数的外面,而不能在NewSpan内部加锁。 因为如果在NewSpan内部加锁的话,就会使得相同锁因为递归调用被锁了两次,最终导致死锁的现象。(在C++11中有recursive_mutex可以解决在递归调用时递归使用锁的问题)
问题2:怎么从
page cache中获取span?
有三步需要考虑:
- 如果
page cache的哈希桶中存在k页的span的话直接返回 - 如果没有的话,就将大页切割成
k页的span和n-k的span。 - 如果没有更大页的
span,就直接向堆申请,然后重复执行一遍切割这个大内存的逻辑。
// 获取一个非空的span
Span* CentralCache::GetOneSpan(SpanList& list, size_t size)
{
// 查看当前Span下的SpanList中是否还有未分配对象的span
// 如果有就直接返回span,如果没有就需要从page cache中再获取
Span* it = list.Begin();
while (it != list.End())
{
if (it->_freeList != nullptr)
{
return it;
}
it = it->_next;
}
// 问题1
// @@先将central cache的桶锁解掉,这样的话如果有其他的线程内存释放对象的话不会阻塞
list._mtx.unlock();
// @@对page cache整体加锁
PageCache::GetInstance()->_pageMtx.lock();
// 走到这里说明当前的spanlist中没有空闲的span了,需要找page cache要
// 这里是size传入NumMovePage()中后,就可以根据size算出需要的内存块的节点数量的上下
// 进而推导出需要的页数
Span* span = PageCache::GetInstance()->NewSpan(SizeClass::NumMovePage(size));
PageCache::GetInstance()->_pageMtx.unlock();
// 将span进行切分
char* start = (char*)(span->_pageId << PAGE_SHIFT);
size_t bytes = span->_n << PAGE_SHIFT;
char* end = start + bytes;
span->_freeList = start;
void* tail = span->_freeList;
start += size;
while (start < end)
{
// 尾插内存节点
tail = NextObj(tail) = start;
start += size;
}
// @@在span切割的时候不用加锁,因为其他线程在外函数外面不能访问到span
// @@而下面需要在list中插入span的时候会对向centralcache申请的线程造成影响
// @@所以这个时候需要加锁
list._mtx.lock();
list.PushFront(span);
return span;
}
// "PageCache.cpp"中
Span* PageCache::NewSpan(size_t k)
{
// 问题2
assert(k > 0 && k < NPAGES);
// 判断是否存在k页的span
if (!_spanLists[k].Empty())
{
return _spanLists[k].PopFront();
}
// 如果哈希桶中不存在k页的span的话
// 就需要将大的span切分成k页的span和n-k页的span
// 将k页的span返回,然后将n-k页的span直接挂在n-k页的哈希桶中
for (size_t i = k + 1; i < NPAGES; i++)
{
if (!_spanLists[i].Empty())
{
Span* nSpan = _spanLists[i].PopFront();
Span* kSpan = new Span;
// 从nSpan的头部切出kSpan来,返回kSpan,重新挂nSpan
kSpan->_pageId = nSpan->_pageId;
kSpan->_n = k;
nSpan->_pageId += k;
nSpan->_n -= k;
_spanLists[nSpan->_n].PushFront(nSpan);
return kSpan;
}
}
// 走到这个位置说明后面没有更大的页了
// 这时就只能向堆申请了
Span* bigSpan = new Span;
void* ptr = SystemAlloc(NPAGES - 1);
// 将地址转换成页号
bigSpan->_pageId = (PAGE_ID)ptr >> NPAGES;
bigSpan->_n = NPAGES - 1;
// 将大内存插入到第NPAGES-1号桶中
_spanLists[bigSpan->_n].PushFront(bigSpan);
return NewSpan(k);
}
%%# 14 申请内存过程联调
从堆中申请的内存的地址可以转成span->_pageId页号,这样通过页号可以找到这块地址的地址了。
测试一:
void TestConcurrentAlloc1()
{
void* p1 = ConcurrentAlloc(6);
void* p2 = ConcurrentAlloc(8);
void* p3 = ConcurrentAlloc(1);
void* p4 = ConcurrentAlloc(6);
void* p5 = ConcurrentAlloc(8);
cout << p1 << endl;
cout << p2 << endl;
cout << p3 << endl;
cout << p4 << endl;
cout << p5 << endl;
}
第一次申请内存,在ThreadCache中没有内存,所以去Central Cache中的span中要,但是Central Cache中index位置没有span,所以此时就要从Page Cache中第k个哈希桶中获得span。此时pagecache中第k个哈希桶中也没有span,所以就需要从系统中获取一个128页的内存挂在哈希桶中的第128的位置上。然后将128位置上的内存块切成n-k页的内存块和k页的内存块。将k页的span返回
central cache拿到span后将span分成k页数的字节/size块小内存,然后拿其中batchNum个内存块。并且返回给ThreadCache,并且将后面没有使用的小内存块放在第index号哈希桶中。最后用threadcache返回给用户想要的得到的内存块。
第二次申请内存的时候,还是相同的逻辑。但是因为central cache中有span所以可以直接从span中切出batchNum个小内存块给threadCache。(注意这里只需要一个但是由于上次一次也是分配8字节内存,这次也是分配8字节内存,所以这次因为慢增长会获得2个内存块。
第三次因为上一次慢增长,所以这一次直接从threadcache中获得内存块。
测试二:
void TestConcurrentAlloc2()
{
for (int i = 0; i < 1024; i++)
{
void* ptr = ConcurrentAlloc(8);
}
void* p = ConcurrentAlloc(8);
}
因为第一次会从page cache中的128号桶中获取分配给central cache一页的内存,但是在分配1024个8字节内存块的时候就会重新要从page cache中获取span了。
总结:
thread cache
- 作用
- 将经过慢增长的
actulNum个内存块给用户
- 将经过慢增长的
- 相关接口
Allocate:获取size字节大小的内存FetchFromCentralCache:通过慢增长获得内存块数量
central cache
- 作用
- 从central cache中分配span
- 将拿出的span切分成小块内存块
- 相关接口
GetOneSpan:返回一块已经切分好的span其中的一块。如果span没有切分好(因为使用page cache中刚获取的),可以切分好再归还。FetchRangeObj:将span切分好的自由链表中获取batchNum块。
page cache
- 作用
- 分配以页为单位的内存
- 相关接口
NewSpan:返回k页的span,如果有就返回。如果没有就看看是否可以从更大页的span分割。如果没有更大的span就直接从系统要128页的内存。%%
14. threadcache回收内存
为什么需要
threadcache回收内存?
当thread cache的哈希桶中保留的自由链表的的长度过长的话,因为使用不上,所以可以进行回收。
tcmalloc中的机制:
tcmalloc:使用链表的长度和内存的大小来判断是否回收。
在这个项目中简化一下:
如果归还的内存块超过了一次批量(_freeLists[index].MaxSize())的内存块的长度,就整体做出归还。
问题1:什么时候将哈希桶中的自由链表中的节点回收?
当_freeLists[index].Size() == _freeLists[index].MaxSize()的时候,就会因为第index号桶中的自由链表的长度过长而导致需要回收。此时并不是将所有的size字节大小的内存全部收回,而只是将其中MaxSize块回收。
tcmalloc中的回收机制其实处理的很细致,所以很复杂。
还可以控制哈希桶中整体申请内存的大小,如果所有申请的内存大小超过2M的话,就从centralcache的多个哈希桶中回收内存。
可以使用一个变量记录thread cache中整体申请的剩余内存的大小,如果大于2M的时候,就可以对哈希桶中的各个桶中的链表进行一个清扫。
问题3:如果自由链表太长怎么回收?
可以增加接口回收_freeLists[index]中的n个内存块。在FreeList类中增加接口。
问题4:将自由链表中的内存块怎么处理?
将自由链表中的内存块归还给块给central cache中的span,因为在central cache需要有可以接收从thread cache内存块放到span中的接口。
// "ThreadCache.cpp"中的回收内存接口
void ThreadCache::Deallocate(void* ptr, size_t size)
{
assert(ptr);
assert(size <= MAX_BYTES);
// 找到对应的自由链表哈希桶,将内存块回收回_freeList[index]中
size_t index = SizeClass::Index(size);
_freeLists[index].Push(ptr);
// 问题1
// 如果_freeList[index]中自由链表的长度过长(大于一次批量申请的内存)的话,就需要回收给central cache
if (_freeLists[index].Size() > _freeLists[index].MaxSize())
{
ListTooLong(_freeLists[index], size);
}
}
// 释放对象时,链表过长,回收内存回中心缓存中
void ThreadCache::ListTooLong(FreeList& list, size_t size)
{
// 将一批数量的内存块拿出
void* start = nullptr;
void* end = nullptr;
// 问题3
list.PopRange(start, end, list.MaxSize());
// 问题4
// 以自由链表的形式还给central cache中
CentralCache::GetInstance()->ReleaseListToSpans(start, size);
}
// "Commom.h"中FreeList的PopRange接口
void PopRange(void*& start, void*& end, int n)
{
assert(n >= _size);
// 将n个内存块从自由链表中移出
start = _freeList;
end = start;
for (int i = 0; i < n - 1; i++)
{
end = NextObj(end);
}
_freeList = NextObj(end);
NextObj(end) = nullptr;
_size -= n;
}
15. central cache回收内存
问题0:如何将小块内存还给对应的
span?
从thread cache中回收的内存块组成的链表,它们每一个内存块原来所属的span都不确定。
因为小块内存是从span中切来的,所以可以通过计算得到小块内存的页号,而在同一个span下的小块内存下计算的页号是相同的(因为地址会整除)。这样就可以使得所有的小块内存找到自己对应的span了。
因为同一个Span中的小块内存对象的页号都是相同的。所以可以通过建立页号和Span的对应关系方式使得在只有小块内存地址的情况下,找到其对应的Span。
我们可以根据小块内存的地址,可以计算出这个小块内存的页号。方法:属于同一个span的内存块由于是连续的,所以这些内存块的地址/8K之后应该相同,并且等于span->_pageId。
问题1:如何将
span*和页号进行映射?
因为后面page cache回收内存的时候也可以使用建立映射相同的映射关系,所以unordered_map放到page cache类中,使用page cache的单例调用这个容器,这样在centralcach和pagecache中就都可以使用映射关系了。
而且在NewSpan中需要将每一页和span进行映射。
问题2:如何处理回收的小块内存?
将小块内存找到对应的span,并将它们头插到span中。并且每当一个小块内存归还的时候,该span对应的usecount就需要减去1。当usecount减到0的时候,就需要将该span归还给pagecache。
问题3:当一个
Span中的所有小块内存都已经归还回来后(即Span的_usecount等于0的时候)怎么办?
当usecount==0的时候Span中已经是原来的一段连续空间了,所以需要将span归还给pagecache。
归还方法:将该span从_spanList中剥离下来,调用ReleaseSpanToPageCache交给pagecache处理。
// "PageCache.h"
// 问题1
// 将页号和Span*建立一个映射
std::unordered_map<PAGE_ID, Span*> _idSpanMap;
// "PageCache.cpp"
// 问题1
// 将span和每一页的地址进行一个映射
// 方便central cache回收小块内存时,找到小内存块和span的对应关系
for (PAGE_ID i = 0; i < kSpan->_n; i++)
{
_idSpanMap[kSpan->_pageId + i] = kSpan;
}
// "PageCache.cpp"
// 问题1
// 获取小块内存和span的映射
Span* PageCache::MapObjectToSpan(void* obj)
{
// 将小块内存的页号算出,然后返回该页号对应的span
PAGE_ID id = (PAGE_ID)obj >> PAGE_SHIFT;
if (_idSpanMap.count(id))
{
return _idSpanMap[id];
}
else
{
// 如果程序正确,应该一定会有对应的span
assert(false);
return nullptr;
}
}
// "CentralCache.cpp"
// 将一定数量的小内存块归还给central cache的span
// 需要归还[start, end]这一段空间,但是因为end后面已经手动地指向空了,所以可以只传start这个参数即可
void CentralCache::ReleaseListToSpans(void* start, size_t size)
{
size_t index = SizeClass::Index(size);
// 使用桶锁
_spanLists[index]._mtx.lock();
// 将回收的小块内存插入到对应的span中
while (start)
{
// 问题2
void* next = NextObj(start);
Span* span = PageCache::GetInstance()->MapObjectToSpan(start);
// 将小块内存头插到span中
NextObj(start) = span->_freeList;
span->_freeList = start;
start = next;
span->_usecount--;
// 问题3
// 当span的usecount等于0的时候,说明span切出去的所有小块内存都已经回收
// span整个回收回pagecache中,然后pagecache可以进行前后也的合并
if (span->_usecount == 0)
{
// 将span从这个哈希桶的index位置上剥离下来
_spanLists[index].Erase(span);
span->_freeList = nullptr;
span->_next = nullptr;
span->_prev = nullptr;
// 解除桶锁,因为当前线程已经不在对当前哈希桶中的自由链表造成影响了
// 所以为了不影响其他的线程申请和归还内存,这样需要解除桶锁,加上pageMtx
_spanLists[index]._mtx.lock();
PageCache::GetInstance()->_pageMtx.lock();
PageCache::GetInstance()->ReleaseSpanToPageCache(span);
PageCache::GetInstance()->_pageMtx.unlock();
_spanLists[index]._mtx.unlock();
}
}
_spanLists[index]._mtx.unlock();
}
16. pagecache回收内存
问题0:
pagecache回收Span的机制
如果page cache将从central cache回收回来的span直接挂在哈希桶的第k个位置上的话,那么最后就是一个由span组成的链表,这样还是没有缓解内存碎片的问题。
只有对span前后的页,尝试进行合并,使得前后的Span可以连接起来,最终能所有的内存可以连续,这样才能缓解外碎片问题。
问题1:
span前后合并空闲页需要的条件?
合并的过程中是一个循环的过程。其中需要满足三个条件。
- 如果一个
span可以和前面的span合并的话,那么在合并之后需要再判断是否还可以再往前合并。直到前面的span不能再合并 - 前面没有
span - 前后合并的页数超过了
NPAGES-1(128页)为止。
问题2:如何合并前后两个
Span?
通过查找一个页的前后的相邻页(前提是相邻页是空闲页,也就是在page cache中剩余的内存页),如果相邻页是空闲的话可以尝试进行合并。
使用unordered_map找到相邻页对应的Span,然后修改Span的属性就相当于合并相邻页了。
合并完相邻页之后,就可以将Span放入pagecache中对应大小的哈希桶中了。
问题3:如何比较,合并前后两个
span?
Span前面一个prevSpan的页号,即prevSpan->_pageId,等于span->_pageId-1。因为span*是Span的开头,所以前面一个页就是前一个Span。
但是Span后面一个nextSpan的页号,等于span->_pageId + span->_n。因为span的页数可能会有很多,所以加上span->_n之后,才是prevSpan的首地址。
合并span前面的空闲页只需要修改span中的属性信息即可。即让span去管理prevSpan/nextSpan的自由链表,并且修改对应的页数量,首地址,是否使用等信息。
在合并相邻空闲页之后,由于span已经接管了相邻页。所以相邻页需要从原来pagecache的哈希桶中的位置剥离下来。将合并过后的span放入对应的哈希桶中。最后将管理相邻页的prevSpan/nextSpan销毁掉
在合并完相邻页之后,需要对span进行映射关系的处理,将其span和pageId也进行映射。
小提示:
每一个内存块都由自己的Span管理,为了找到自己的Span所以也可以建立和Span的映射关系。所以处理每一个内存的时候,都需要修改管理自己Span的属性信息。并且要建立内存块和自己Span的映射关系。
问题4:如何找到一个
span是否为空闲页,即span是在pagecache中还是在centralcache中呢?
不能使用usecount判断,因为会导致线程不安全。
因为pagecache在锁住的时候,centralcache的哈希桶中并没有锁的限制。所以一个在回收并且合并Span的时候,可能会有另一个线程在开辟一个新的Span,这个时候新的Span的usecount也是等于0的。所以可能会出现一个线程刚刚开辟的Span被另一个线程回收合并了。
因为需要给span加一个属性_isUse,_isUse专门用于判断这个span是否真正被使用。如果_isUse == true的话,说明当前的Span不能回收。
问题5:如何将
pagecache中所有的的span进行和页号映射?
如果我们需要对所有空闲的span的都需要回收的话,就需要对所有的空闲span都建立和页号的映射。但是前面我们为了将所有小内存块和span进行回收的时候只讲小内存块和span进行映射,而从大内存分下来的其余部分的内存并没有建立映射。所以我们需要建立两者的映射。但是也没有必要向需要分配给central cache的内存一样切分的那么细致,而只需要将内存的收尾页建立映射即可,因为当一个span找空闲页的时候,只会找前后相邻的两页,所以只需要对在pagecache中的空闲页的收尾两页的内存上建立和span的映射即可。
// 存储nSpan的收尾页号和nSpan的映射,方便回收pagecache内存时候进行合并
_idSpanMap[nSpan->_pageId] = nSpan;
_idSpanMap[nSpan->_pageId + nSpan->_n - 1] = nSpan;
// 问题0
// span回收回PageCache中,并且合并相连的span
void PageCache::ReleaseSpanToPageCache(Span* span)
{
// 对span前后的页,不断尝试进行合并
// 问题1
// 向前合并
while (true)
{
// 问题2&&问题3
PAGE_ID prevId = span->_pageId - 1;
auto ret = _idSpanMap.find(prevId);
// 如果前面的内存没有分配空间形成span就不合并
if (ret == _idSpanMap.end())
{
break;
}
// 问题4
// 如果当前的span正在centralcache中使用的话,不能合并
Span* prevSpan = ret->second;
if (prevSpan->_isUse == true)
{
break;
}
// 如果前面页和当前页合并后超过128页太大了,不合并
if (prevSpan->_n + span->_n > NPAGES - 1)
{
break;
}
_spanLists[span->_n].Erase(span);
// 问题5
span->_pageId = prevSpan->_pageId;
span->_n += prevSpan->_n;
// 将prevSpan从pagecache的_n的位置上剥离下来
_spanLists[prevSpan->_n].Erase(prevSpan);
delete prevSpan;
}
// 向后合并
while (true)
{
PAGE_ID nextId = span->_pageId + span->_n;
auto ret = _idSpanMap.find(nextId);
if (ret == _idSpanMap.end())
{
break;
}
Span* nextSpan = ret->second;
if (nextSpan->_isUse == true)
{
break;
}
if (nextSpan->_n + span->_n > NPAGES - 1)
{
break;
}
_spanLists[span->_n].Erase(span);
span->_n += nextSpan->_n;
_spanLists[nextSpan->_n].Erase(nextSpan);
delete nextSpan;
}
// 问题5
// 最后将span放入_n的哈希桶桶中即可
// 并且记录span的pageId和span的对应关系
_spanLists[span->_n].PushFront(span);
span->_isUse = false;
_idSpanMap[span->_pageId] = span;
_idSpanMap[span->_pageId + span->_n - 1] = span;
}
%%# 释放内存过程联调
可以测试ConcurrentAlloc()7次,然后再ConcurrentAlloc7次,这样正好就可以将原来将pagecache中128页切割成的127页和1页全部的还回去了。
因为前面分配了内存7次内存,所以这些内存应该都是从一个1页的span中获得的(因为1页的span可以切成1024块大小为8bytes的小内存块)
到了第7次释放的时候,首先是小内存块全部都还给span中了,所以span就可以将所有的小内存块合并,并且往上交给pagecache了。
由于这1页的span(从centralcache中剥离下来的)原本是由128页的内存块切成的127页和1页中的span,所以在合并的时候,这个span往后就可以找到pageId=127的span进行合并。最终threadcache和centralcache中都没有剩余的内存块了,而pagecache中有一个128页的内存块。%%
17. 大于256KB的大块内存申请问题
问题0:大于
256KB的内存的申请的设计方案。
- size <=256KB(使用三层缓存)
- size>256KB(256KB=32 * 8K,即32页)
- 128 * 8K >= size > 32 * 8K(找
pagecache) - size > 128 * 8K(找系统堆)
- 128 * 8K >= size > 32 * 8K(找
- 如果申请的内存<256KB(32页)的话,可以使用
threadcache,centralcache,pagecache共同完成即可。 - 如果256KB<申请的内存<小于128页内存的话,就可以不用切分成小内存了,而是直接从
pagecache中以页为单位申请内存。 - 如果申请的内存>128页的话,那么
pagecache也不能分配内存了,这样时候最好就直接向系统堆中申请。
问题1:怎么统一处理大于32页小于128页的内存和128页的内存的申请?
因为大于32页小于128页的内存申请还是向pagecache申请一个span,因此直接可以跳过去threadcache和centralcache申请的部分,直接向pagecache申请一个span,所以可以算出这个申请内存的页数,然后向pagecache要内存即可。
为了统一的调用接口,大于128页的内存也可以当做一个span向pagecache申请。而在NewSpan中可以特殊这里超过128页内存的申请,可以直接调用SystemAlloc向系统调用。
问题2:怎么统一处理大于32页小于128页的内存和128页的内存的释放?
因为大于32页小于128页的内存释放还是将span归还给pagecache,而且可以和前后span的空闲页合并。为了统一接口,也可以将归还超过128页内存的过程看成归还一个span给pagecache。但是实际上可以使用SystemFree将内存直接归还给系统。
// 问题0
static void* ConcurrentAlloc(size_t size)
{
/->
// 大于256KB的时候,需要特殊处理
if (size > MAX_BYTES)
{
size_t alignSize = SizeClass::RoundUp(size);
size_t kpage = alignSize >> PAGE_SHIFT;
// 问题1
// 这里会访问pagecache的哈希桶(临界资源),所以需要上锁
PageCache::GetInstance()->_pageMtx.lock();
Span* span = PageCache::GetInstance()->NewSpan(kpage);
PageCache::GetInstance()->_pageMtx.unlock();
void* ptr = (void*)(span->_pageId << PAGE_SHIFT);
return ptr;
}
/<-
else
{
// 通过TLS,每一个线程可以获得自己专属的ThreadCache对象,并且这个过程是无锁的
// 如果ThreadCache的自由链表中节点的话,那么效率则非常高
if (pTLSThreadCache == nullptr) {
pTLSThreadCache = new ThreadCache;
}
cout << std::this_thread::get_id() << ":" << pTLSThreadCache << endl;
return pTLSThreadCache->Allocate(size);
}
}
static void ConcurrentFree(void* ptr, size_t size)
{
//->
if (size > MAX_BYTES)
{
// 问题2
Span* span = PageCache::GetInstance()->MapObjectToSpan(ptr);
PageCache::GetInstance()->_pageMtx.lock();
PageCache::GetInstance()->ReleaseSpanToPageCache(span);
PageCache::GetInstance()->_pageMtx.unlock();
}
///<-
else
{
assert(pTLSThreadCache);
pTLSThreadCache->Deallocate(ptr, size);
}
}
// 问题1
// 大于的128页的内存页放在这里,就是为了可以让这个函数统一处理分配span的问题
// 如果小于128页的span可以从这里拿,大于128页的span也可以从这里拿
if (k > NPAGES - 1)
{
void * ptr = SystemAlloc(k);
Span* span = new Span;
span->_pageId = (PAGE_ID)ptr >> PAGE_SHIFT;
span->_n = k;
_idSpanMap[span->_pageId] = span;
return span;
}
// 问题2
// 大于128页的内存直接还给堆
if (span->_n > NPAGES - 1)
{
void* ptr = (void*)(span->_pageId << PAGE_SHIFT);
SystemFree(ptr);
delete span;
return;
}
18. 释放对象时优化为不传对象大小
在tcmalloc中不应该出现new,malloc等关键字,因为tcmalloc本身设计出来就是要和malloc相比较的。
所以我们可以使用前面写的一个定长的内存池,去替代new的作用。
因为只有pagecache的哈希桶中需要有一个双向带头循环的链表,所以需要new一个Span,因为可以在SpanList中定义一个ObjPool专门用于new其中的Span。
除此之外,在ThreadCache中还需要new一个ThreadCache给TLS,可以定义一个static的ObjPool保证全局只有一个定义ThreadCache的内存池。
19. 多线程环境对比malloc测试
测试多线程下malloc和ConcurrentAlloc的性能。
// ntimes:一轮申请释放内存的次数
// rounds:释放的轮数
// nworks:创建的线程数
void BenchmarkMalloc(size_t ntimes, size_t nworks, size_t rounds)
{
std::vector<std::thread> vthread(nworks);
std::atomic<size_t> malloc_costtime = 0;
std::atomic<size_t> free_costtime = 0;
for (size_t k = 0; k < nworks; k++)
{
// nworks个线程依次执行lambda表达式
// lambda表达式中执行rounds轮线程申请内存和释放内存的过程
// 每一轮的都申请ntimes次内存和释放ntimes次内存
vthread[k] = std::thread([&]() {
std::vector<void*> v(ntimes);
for (size_t j = 0; j < rounds; j++)
{
size_t begin1 = clock();
for (size_t i = 0; i < ntimes; i++)
{
v.push_back(malloc(16));
}
size_t end1 = clock();
size_t begin2 = clock();
for (size_t i = 0; i < ntimes; i++)
{
free(v[i]);
}
size_t end2 = clock();
v.clear();
malloc_costtime += end1 - begin1;
free_costtime += end2 - begin2;
}
});
}
for (auto& e : vthread)
{
e.join();
}
printf("%u个线程并发执行%u轮次,每轮次malloc%u次,花费:%u ms\n",
nworks, rounds, ntimes, malloc_costtime);
printf("%u个线程并发执行%u轮次,每轮次free%u次,花费:%u ms\n",
nworks, rounds, ntimes, free_costtime);
printf("%u个线程并发执行malloc&free %u轮次,总花费:%u ms\n",
nworks, nworks * rounds * ntimes, malloc_costtime + free_costtime);
}
// ntimes:一轮申请释放内存的次数
// rounds:释放的轮数
// nworks:创建的线程数
void BenchmarkConcurrentAlloc(size_t ntimes, size_t nworks, size_t rounds)
{
std::vector<std::thread> vthread(nworks);
std::atomic<size_t> malloc_costtime = 0;
std::atomic<size_t> free_costtime = 0;
for (size_t k = 0; k < nworks; k++)
{
// nworks个线程依次执行lambda表达式
// lambda表达式中执行rounds轮线程申请内存和释放内存的过程
// 每一轮的都申请ntimes次内存和释放ntimes次内存
vthread[k] = std::thread([&]() {
std::vector<void*> v(ntimes);
for (size_t j = 0; j < rounds; j++)
{
size_t begin1 = clock();
for (size_t i = 0; i < ntimes; i++)
{
v.push_back(ConcurrentAlloc(16));
}
size_t end1 = clock();
size_t begin2 = clock();
for (size_t i = 0; i < ntimes; i++)
{
ConcurrentFree(v[i], 16);
}
size_t end2 = clock();
v.clear();
malloc_costtime += end1 - begin1;
free_costtime += end2 - begin2;
}
});
}
for (auto& e : vthread)
{
e.join();
}
printf("%u个线程并发执行%u轮次,每轮次ConcurrentAlloc%u次,花费:%u ms\n",
nworks, rounds, ntimes, malloc_costtime);
printf("%u个线程并发执行%u轮次,每轮次ConcurrentFree%u次,花费:%u ms\n",
nworks, rounds, ntimes, free_costtime);
printf("%u个线程并发执行ConcurrentAlloc&ConcurrentFree %u轮次,总花费:%u ms\n",
nworks, nworks * rounds * ntimes, malloc_costtime + free_costtime);
}
int main()
{
size_t n = 10000;
// 4个线程执行10轮每轮执行n次
cout << "==========================================" << endl;
BenchmarkMalloc(n, 4, 10);
cout << endl << endl;
BenchmarkConcurrentAlloc(n, 4, 10);
cout << "==========================================" << endl;
return 0;
}
20. 性能瓶颈分析
%%性能优化:如果想要分析性能瓶颈,不能靠感觉,而是要使用性能分析的工具。
vs下,性能与诊断,性能导向,检测。%%
经过诊断后,发现centralcache,pagecache中桶锁和大锁的竞争消耗了大量的时间。还有在MapObjectSpan建立映射的时候,unique_lock会消耗大量的时间。
在tcmalloc中是使用基数树来优化提高这个性能的,
21. 针对性能瓶颈使用基数树优化
基数树其实就是哈希表的变形。
一层的基数树就是采用直接定址法的哈希表。
基数树需要传入分类型模板参数,BIIT表示存储页号需要的位数。
- 32位下,
BITS = 32 - PAGE_SHIFT。- 2 32 / 2 13 = 2 19 2^{32}/2^{13}=2^{19} 232/213=219,占用内存为 2 19 ∗ 4 = 2 M 2^{19}*4 = 2M 219∗4=2M
- 64位下,
BITS = 64 - PAGE_SHIFT。- 2 64 / 2 13 = 2 51 2^{64}/2^{13}=2^{51} 264/213=251,占用内存为 2 51 ∗ 8 = 2 54 B y t e s 2^{51}*8=2^{54}Bytes 251∗8=254Bytes
// 一层的基数树
template <int BLTS>
class TCMalloc_PageMap1
{
private:
// 32位下,一共有2^19个页号和span*映射
static const int LENGTH = 1 << BITS;
void** array_;
}
两层的基数树就是分层哈希

分层哈希
- 将一个整数分成两个部分分别哈希,拿到一个页号,使用页号的前5位计算在哪一个页槽,在使用后13位计算在哪一个位置。 。
- 而且如果使用分层哈希的话,也可以一定程度上节省空间。因为第一层的基数树并且要有对应的映射才会开辟下一层的
values数组哈希,所以如果没有第一层的映射的话,第二层就不会开空间。
三层的基数树也是同样的原理,只不过是将一个页号分成了三个部分,第一层映射了前x位,第二层映射了中间的y位,第三层映射了最后的z位。
// 两层的基数树
template <int BITS>
class TCMalloc_PageMap2
{
private:
static const int ROOT_BITS = 5;
static const int ROOT_LENGTH = 1 << ROOT_BITS;
static const int LEAF_BITS = BITS - ROOT_BITS;
static const int LEAF_LENGTH = 1 << LEAF_BITS;
// 叶节点
struct Leaf
{
void* values[LEAF_LENGTH];
};
Leaf* root_[ROOT_LENGTH]; // 指向232个孩子
void* (*allocator)(size_t); // 内存分配
}
完整代码如下:
#pragma once
#include"Common.h"
// Single-level array
template <int BITS>
class TCMalloc_PageMap1 {
private:
static const int LENGTH = 1 << BITS;
void** array_;
public:
typedef uintptr_t Number;
//explicit TCMalloc_PageMap1(void* (*allocator)(size_t)) {
// array_ = reinterpret_cast((*allocator)(sizeof(void*) << BITS));
// memset(array_, 0, sizeof(void*) << BITS);
//}
explicit TCMalloc_PageMap1() {
size_t size = sizeof(void*) << BITS;
size_t alignSize = SizeClass::_RoundUp(size, 1 << PAGE_SHIFT);
array_ = (void**)SystemAlloc(alignSize >> PAGE_SHIFT);
memset(array_, 0, sizeof(void*) << BITS);
}
// 直接定址法
void* get(Number k) const {
if ((k >> BITS) > 0) {
return NULL;
}
return array_[k];
}
// REQUIRES "k" is in range "[0,2^BITS-1]".
// REQUIRES "k" has been ensured before.
//
// Sets the value 'v' for key 'k'.
void set(Number k, void* v) {
array_[k] = v;
}
};
// Two-level radix tree
template <int BITS>
class TCMalloc_PageMap2 {
private:
// Put 32 entries in the root and (2^BITS)/32 entries in each leaf.
static const int ROOT_BITS = 5;
static const int ROOT_LENGTH = 1 << ROOT_BITS;
static const int LEAF_BITS = BITS - ROOT_BITS;
static const int LEAF_LENGTH = 1 << LEAF_BITS;
// Leaf node
struct Leaf {
void* values[LEAF_LENGTH];
};
Leaf* root_[ROOT_LENGTH]; // Pointers to 32 child nodes
void* (*allocator_)(size_t); // Memory allocator
public:
typedef uintptr_t Number;
//explicit TCMalloc_PageMap2(void* (*allocator)(size_t)) {
// allocator_ = allocator;
// memset(root_, 0, sizeof(root_));
//}
explicit TCMalloc_PageMap2() {
memset(root_, 0, sizeof(root_));
// 构造函数的时候,就直接将所有位置上的内存空间全部开好
PreallocateMoreMemory();
}
// 第一层的基数树
void* get(Number k) const {
const Number i1 = k >> LEAF_BITS;
const Number i2 = k & (LEAF_LENGTH - 1);
if ((k >> BITS) > 0 || root_[i1] == NULL) {
return NULL;
}
return root_[i1]->values[i2];
}
// 第二层基数树
void set(Number k, void* v) {
const Number i1 = k >> LEAF_BITS;
const Number i2 = k & (LEAF_LENGTH - 1);
ASSERT(i1 < ROOT_LENGTH);
root_[i1]->values[i2] = v;
}
bool Ensure(Number start, size_t n) {
for (Number key = start; key <= start + n - 1;) {
const Number i1 = key >> LEAF_BITS;
// Check for overflow
if (i1 >= ROOT_LENGTH)
return false;
// Make 2nd level node if necessary
if (root_[i1] == NULL) {
Leaf* leaf = reinterpret_cast<Leaf*>((*allocator_)(sizeof(Leaf)));
if (leaf == NULL) return false;
memset(leaf, 0, sizeof(*leaf));
root_[i1] = leaf;
}
// Advance key past whatever is covered by this leaf node
key = ((key >> LEAF_BITS) + 1) << LEAF_BITS;
}
return true;
}
bool Ensure(Number start, size_t n) {
for (Number key = start; key <= start + n - 1;) {
const Number i1 = key >> LEAF_BITS;
// Check for overflow
if (i1 >= ROOT_LENGTH)
return false;
// Make 2nd level node if necessary
if (root_[i1] == NULL) {
static ObjPool<Leaf> leafPool;
Leaf* leaf = (Leaf*)leafPool.New();
memset(leaf, 0, sizeof(*leaf));
root_[i1] = leaf;
}
// Advance key past whatever is covered by this leaf node
key = ((key >> LEAF_BITS) + 1) << LEAF_BITS;
}
return true;
}
void PreallocateMoreMemory() {
// Allocate enough to keep track of all possible pages
Ensure(0, 1 << BITS);
}
};
// Three-level radix tree
template <int BITS>
class TCMalloc_PageMap3 {
private:
// How many bits should we consume at each interior level
static const int INTERIOR_BITS = (BITS + 2) / 3; // Round-up
static const int INTERIOR_LENGTH = 1 << INTERIOR_BITS;
// How many bits should we consume at leaf level
static const int LEAF_BITS = BITS - 2 * INTERIOR_BITS;
static const int LEAF_LENGTH = 1 << LEAF_BITS;
// Interior node
struct Node {
Node* ptrs[INTERIOR_LENGTH];
};
// Leaf node
struct Leaf {
void* values[LEAF_LENGTH];
};
Node* root_; // Root of radix tree
void* (*allocator_)(size_t); // Memory allocator
Node* NewNode() {
Node* result = reinterpret_cast<Node*>((*allocator_)(sizeof(Node)));
if (result != NULL) {
memset(result, 0, sizeof(*result));
}
return result;
}
public:
typedef uintptr_t Number;
explicit TCMalloc_PageMap3(void* (*allocator)(size_t)) {
allocator_ = allocator;
root_ = NewNode();
}
void* get(Number k) const {
const Number i1 = k >> (LEAF_BITS + INTERIOR_BITS);
const Number i2 = (k >> LEAF_BITS) & (INTERIOR_LENGTH - 1);
const Number i3 = k & (LEAF_LENGTH - 1);
if ((k >> BITS) > 0 ||
root_->ptrs[i1] == NULL || root_->ptrs[i1]->ptrs[i2] == NULL) {
return NULL;
}
return reinterpret_cast<Leaf*>(root_->ptrs[i1]->ptrs[i2])->values[i3];
}
void set(Number k, void* v) {
ASSERT(k >> BITS == 0);
const Number i1 = k >> (LEAF_BITS + INTERIOR_BITS);
const Number i2 = (k >> LEAF_BITS) & (INTERIOR_LENGTH - 1);
const Number i3 = k & (LEAF_LENGTH - 1);
reinterpret_cast<Leaf*>(root_->ptrs[i1]->ptrs[i2])->values[i3] = v;
}
bool Ensure(Number start, size_t n) {
for (Number key = start; key <= start + n - 1;) {
const Number i1 = key >> (LEAF_BITS + INTERIOR_BITS);
const Number i2 = (key >> LEAF_BITS) & (INTERIOR_LENGTH - 1);
// Check for overflow
if (i1 >= INTERIOR_LENGTH || i2 >= INTERIOR_LENGTH)
return false;
// Make 2nd level node if necessary
if (root_->ptrs[i1] == NULL) {
Node* n = NewNode();
if (n == NULL) return false;
root_->ptrs[i1] = n;
}
// Make leaf node if necessary
if (root_->ptrs[i1]->ptrs[i2] == NULL) {
Leaf* leaf = reinterpret_cast<Leaf*>((*allocator_)(sizeof(Leaf)));
if (leaf == NULL) return false;
memset(leaf, 0, sizeof(*leaf));
root_->ptrs[i1]->ptrs[i2] = reinterpret_cast<Node*>(leaf);
}
// Advance key past whatever is covered by this leaf node
key = ((key >> LEAF_BITS) + 1) << LEAF_BITS;
}
return true;
}
void PreallocateMoreMemory() {
}
};
22. 使用基数树进行优化代码实现
// 将页号和Span*建立一个映射
//std::unordered_map _idSpanMap;
// 使用TCMalloc_PageMap2对象代替unordered_map哈希表建立的映射
TCMalloc_PageMap2<32 - PAGE_SHIFT> _idSpanMap;
基数树的优点
- 基数树(在32位下可以是一层基数树或者是两层基数树)在建立映射前就已经开好了空间,所以在建立映射的过程中,基数树的整体结构不会发生改变。 如果结构不会变的话,那么之前已经建立的映射关系就不会发生改变。因此就不需要在使用映射关系的时候加锁保护。 使用基数树是以空间内存为代价,使得整个映射对的结构不会改变。
- 但是无论是使用
unordered_map底层的哈希表还是map底层下的红黑树都会随着插入的过程中产生这个数据结构的变化。而因为整体结构的改变,那么当多个线程进入函数搜索的时候,可能会发生当一个线程因为在建立
- 但是无论是使用
- 基数树的读写是分离的
- 在对基数树读的时候,那么是在空间释放
ConcurrentFree,那么是在合并内存ReleaseListToSpans,这个时候其实基数树都是已经分配好结构的,所以可以直接读取。 - 在对基数树写的时候,是在
ReleaseSpanToPageCache合并归还内存和NewSpan开辟新的内存。**都是在pagecache中进行的,而pagecache都是有锁保护的。并且一块新开辟的内存也不可能会同时在释放。**所以也不会发现线程不安全的问题。
- 在对基数树读的时候,那么是在空间释放
其实就算是多个线程同时访问基数树的话,因为同一块内存不可能同时在进行创建和释放,所以也是没有必要对基数树进行加锁保护的。
因为基数树本身读写比哈希表更快,而且在使用MapObjectToSpan的时候不用加锁了,所以使用整体性能上比原来更快。
CentralCache的作用
- 在ThreadCache和PageCache中形成一个过渡,到达“负载均衡”
- 当Span下的小内存来回来之后可以合并还给PageCache,缓解了内存碎片问题
Span为什么设计成双链表?
- 因为当Span可能会被合并还给PageCache,而使用双链表可以更好的来插入和删除Span
为什么CentralCache中要使用Span来管理内存,而不是直接挂内存节点?
- PageCache的哈希桶中挂的就是Span
- 使用Span来管理内存有助于后面的合并内存,前后的Span在合并的时候,需要使用到Span中的属性。前面的Span合并后可以缓解内存碎片的问题。
项目的完整代码存放