Python实例:用Pandas处理表格(简单的增删改查)
目录
- 任务描述
- 实现过程
任务描述
描述:现有一个excel表格《补充SCI模板》,其中包括6个子表:中科院1区(表1)、JCR-Q1(表2)、教研室补充(表3)、CCF-A(表4)、CCF-B(表5)、CCF-C(表6)。每个表格第一列为期刊名称,需要为这些期刊名称,添加9列内容:‘ISSN’,‘大类’,‘大类分区’, ‘小类’,‘小类分区’,‘JCR分区’,'影响因子‘,’平均影响因子‘,’表格名称‘。添加的前6项内容,来自一个excel表格《2019年中国科学院文献情报中心期刊分区表》,'影响因子‘,’平均影响因子‘两项内容,来自另一个excel表格《2020最新影响因子》。
《2019年中国科学院文献情报中心期刊分区表》内容如下图:
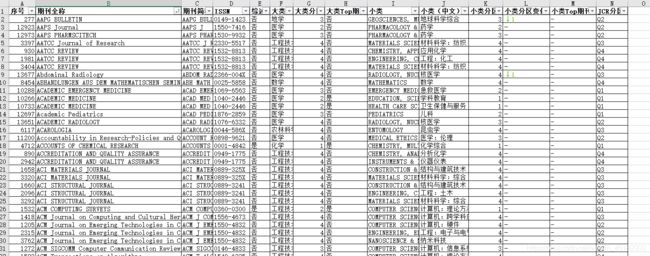
《2020最新影响因子》内容如下图。其中第一行是一个图片,用pandas读取excel时相当于是一个空行;第二行是一个title,也不属于有用的信息。所以,应该从第三行读取该excel表的信息。

其中,表1、表2(如下图)内容比较完善,只需要添加'影响因子‘,’平均影响因子‘,’表格名称‘三列。
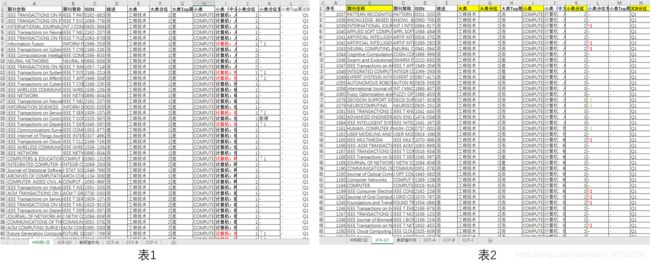
表3-6只有期刊名一列,所以需要将需要的列全部添加上。
注:可以发现,这些列表中的期刊名,大小写并不统一。有些列表的期刊名全为大写,有些则每个单词开头为大写,所以在匹配时,需要统一它们的名称,这里把期刊名全部转换成小写
实现过程
1. import pandas
import os
import pandas as pd
2. 补全表1、表2
表1和表2,只需要添加'影响因子‘,’平均影响因子‘,’表格名称‘三列。首先读取表格:
#设置路径
path = r'D:\文档\计算机专业认可的期刊和顶级会议'
os.chdir(path)
首先读取包含影响因子信息的Excel,并提取需要的列。这里直接写成一个函数,方便后面调用
#读取数据:2020最新影响因子
def get_impact_factor(form_name,sheet_name=0):
#读取Excel
data = pd.read_excel(form_name,sheet_name=0,header=None)
#删除空列
data = data.dropna(axis=1,how='all')
#删除含有空值的行
data = data.dropna(axis=0,how='any')
#设置列名
data.columns = data.loc[2].tolist()
data = data.drop([2])
data.reset_index(drop=True,inplace=True)
#找到各期刊的名称(全部转换成小写),以及对应的影响因子,平均影响因子
all_journal_name = data['Full Journal Title'].str.lower()
all_journal_IF = data['Journal Impact Factor']
all_journal_avg_IF = data['Average Journal Impact Factor Percentile']
#合并数据
all_IF_info = pd.concat([all_journal_name,
all_journal_IF,
all_journal_avg_IF],
axis=1)
return all_IF_info
读取表1,获取列名:
#读取要补充的Excel
form_name = '补充SCI模板.xlsx'
sheet_name = '中科院1区'
data = pd.read_excel(form_name,sheet_name=sheet_name)
journal_name = data['期刊全称'].str.lower()
接下来要从2020最新影响因子列表中匹配表1的期刊名,这里通过查找期刊名对应的索引,来定位影响因子所在行:
#获取子表中的期刊(sub_name)在总表中(main_name)的对应索引
def get_index(sub_name, main_name):
#用tolist(),将pd.Series转换成List,便于查找对应期刊名
sub_name_ls = sub_name.tolist()
main_name_ls = main_name.tolist()
ls_index = []
for name in sub_name_ls:
if name in main_name_ls:
#根据布尔条件选择行索引,储存到列表中
index = main_name[(main_name == name)].index.tolist()[0]
ls_index.append(index)
else:
ls_index.append(new_row_index)
return ls_index
先从表1中筛选需要的信息,再为表1添加列:
#筛选指定列
columns_avl = ['期刊全称', 'ISSN', '大类', '大类分区',
'小类', '小类分区', 'JCR分区']
data = data[columns_avl]
#获得影响因子表中的所有期刊名
all_journal_name = compare_data[compare_data.columns[0]]
#在影响因子表中添加一行信息,用来代替没有在此表中查找到的期刊
new_row_index = len(compare_data)
compare_data.loc[new_row_index] = 'Not Found'
#从影响因子表中找到当前表对应期刊名的索引
name_index = get_index(journal_name, all_journal_name)
#根据索引获取对应的影响因子、平均影响因子百分比
IF_info = compare_data.iloc[name_index].reset_index(drop=True)
# 修改列名
IF_info.rename(columns={IF_info.columns[0]:'期刊全称',
IF_info.columns[1]:'影响因子',
IF_info.columns[2]:'平均影响因子百分比'},
inplace=True)
如此表1的内容就补充完成了,补充表2用同样的方法。
3. 补全表3-6
这几张表需要添加添加9列内容:‘ISSN’,‘大类’,‘大类分区’, ‘小类’,‘小类分区’,‘JCR分区’,'影响因子‘,’平均影响因子‘,’表格名称‘。可以分成两个步骤:
(1)从《2019年中国科学院文献情报中心期刊分区表》中添加分区等信息;
(2)从《2020最新影响因子》中添加影响因子等信息。
相比表1、2,只多了一个步骤——从《2019年中国科学院文献情报中心期刊分区表》中添加信息。后面的方法就与表1、2一样,所以可以将补充信息的方法写成一个函数,添加一个判断:是否需要执行步骤(1)
#完善子表格
def improve_form(form_name, sheet_name, compare_data,
need_supplement=False, supplement=None):
#读取子表
data = pd.read_excel(form_name,sheet_name=sheet_name)
try:
journal_name = data['期刊全称'].str.lower()
except KeyError:
#修改列名
data.rename(columns={data.columns[0]:'期刊全称'}, inplace=True)
journal_name = data['期刊全称'].str.lower()
#需要修改列名的表格,需要补充信息
need_supplement = True
supplement = r'2019年中国科学院文献情报中心期刊分区表.xlsx'
#获取子表中的期刊(sub_name)在总表中(main_name)的对应索引
def get_index(sub_name, main_name):
#用tolist(),将pd.Series转换成List,便于查找对应期刊名
sub_name_ls = sub_name.tolist()
main_name_ls = main_name.tolist()
ls_index = []
for name in sub_name_ls:
if name in main_name_ls:
#根据布尔条件选择行索引,储存到列表中
index = main_name[(main_name == name)].index.tolist()[0]
ls_index.append(index)
else:
ls_index.append(new_row_index)
return ls_index
#判断子表是否需要补全表格信息
if need_supplement:
#读取补充材料
supplement_data = pd.read_excel(supplement)
supplement_name = supplement_data['期刊全称'].str.lower()
#在补充材料中添加一行信息,用来代替没有在此表中查找到的期刊
new_row_index = len(supplement_data)
supplement_data.loc[new_row_index] = 'Not Found'
#获取对应索引
sub_index = get_index(journal_name, supplement_name)
#通过索引,从主表中获取信息
data_info = supplement_data.iloc[sub_index].reset_index(drop=True)
#拼接信息(子表的期刊名,拼接补充材料中对应的信息)
data = pd.concat([data[data.columns[0]],
data_info[data_info.columns[2:]]],
axis = 1)
#筛选指定列
columns_avl = ['期刊全称', 'ISSN', '大类', '大类分区',
'小类', '小类分区', 'JCR分区']
data = data[columns_avl]
#获得影响因子表中的所有期刊名
all_journal_name = compare_data[compare_data.columns[0]]
#在影响因子表中添加一行信息,用来代替没有在此表中查找到的期刊
new_row_index = len(compare_data)
compare_data.loc[new_row_index] = 'Not Found'
#从影响因子表中找到当前表对应期刊名的索引
name_index = get_index(journal_name, all_journal_name)
#根据索引获取对应的影响因子、平均影响因子百分比
IF_info = compare_data.iloc[name_index].reset_index(drop=True)
# 修改列名
IF_info.rename(columns={IF_info.columns[0]:'期刊全称',
IF_info.columns[1]:'影响因子',
IF_info.columns[2]:'平均影响因子百分比'},
inplace=True)
#拼接成一个完整的表格
data_imporved = pd.concat([data,
IF_info[IF_info.columns[1:]]],
axis = 1)
#添加一列信息:来源表格
data_imporved['来源表格'] = sheet_name
return data_imporved
4. 去除重复信息
补充完成后,需要检查是否有重复的内容,可以调用pandas中的dt.drop_duplicates()方法。
#写成一个main函数
def main():
#设置路径
path = r'D:\文档\计算机专业认可的期刊和顶级会议'
os.chdir(path)
#读取数据:2020最新影响因子'
all_journal_info = get_impact_factor(r'2020最新影响因子.xlsx')
'''第一步:整理子表格'''
form_name = r'补充SCI模板.xlsx'
sheet_ls = ['中科院1区', 'JCR-Q1', '教研室补充',
'CCF-A', 'CCF-B', 'CCF-C']
sheet_dict = {}
print('Organizing')
for sheet in sheet_ls:
print('%s'%sheet)
form_info = improve_form(form_name, sheet, all_journal_info)
sheet_dict[sheet] = form_info
'''第二步:合并表格,去除重复的期刊信息'''
# ===================================================
# 期刊去重的时候,如果一个期刊来源于某一个表,也同时来源于
# CCF-A或CCF-B表,那么去重后,保留其来源为CCF-A或CCF-B
# ===================================================
form_group = pd.concat([sheet_dict['CCF-A'],sheet_dict['CCF-B'],
sheet_dict['CCF-C'],sheet_dict['中科院1区'],
sheet_dict['JCR-Q1'],sheet_dict['教研室补充']],
ignore_index=True)
group_name = form_group['期刊全称'].str.lower()
#drop_duplicates()参数keep'first',即默认保留第一次出现的值
final_data = form_group.loc[group_name.drop_duplicates().index]
#写入Excel
save_form = '补充SCI模板_已完善.xlsx'
six_in_one = '六合一表格.xlsx'
with pd.ExcelWriter(save_form) as writer:
print('\nWriting')
for key in sheet_dict:
print('%s'%key)
sheet_dict[key].to_excel(writer,sheet_name=key,index=False)
final_data.to_excel(six_in_one,index=False)
- 一些Pandas 的常用方法(持续更新)
链接:。。