Ultipa图数据库与图计算—服务与架构概述(上)
在本篇中,我们将介绍实时图数据库的基础特征、优势、架构与服务,如模式、数据建模、API/接口和部署等。
一.实时图计算系统的优点:
Ultipa实时图数据库旨在解决其他(非实时)图数据解决方案中经常遇到的性能、可扩展性、用户友好性和健壮性的问题。

· 极致的高性能,通过高密度并发图计算实现的超高性能(高吞吐率、低时延)。各项性能指标稳定的超越Neo4j或Apache Spark
GraphX等系统的100倍以上。·高并发系统,高并发的图计算系统是通过高并发的数据结构与对底层硬件的并发处理能力的充分释放而实现的!值得指出的是,图中的许多操作/处理在微秒内完成,在非常深层计算的场景中,它在毫秒内完成,而非实时的图数据库系统则通常要慢数百甚至数千倍。
·支持超深图层搜索(或遍历):我们讨论的是在大型图中实时执行20跳甚至30跳的深层操作。请注意,在实时的前提下,大部分非实时图计算引擎只能进行3跳深度的运算,当达到5跳或更深时,可能需要几个小时或者干脆宕机。毕竟每多一层,都会带来指数级别的算力挑战。
·线性的可拓展性:图系统的可扩展性是多维度的,一个维度是如何应对不断增长的数据量,另一个维度是如何应对增长的用户访问请求。这两个维度都可以通过水平、弹性的分布式系统架构来实现性能与存储容量的线性增长。
· 支持OLTP+OLAP的统一 ==> HTAP:实时图数据库通过融合OLTP与OLAP的界限,实现了HTAP(HybridTransactional & Analytical
Processing),这意味着所有以前离线或需要T+1之类的批处理的分析类工作现在都可以在线、实时(或近实时)完成,而这当然得益于实时图引擎带来的(指数级的)性能提升。
·
· 直观易用的图查询语言:直观易懂是Ultipa图查询语言UQL的一个显著特征,随着业务对数据关联性、深度(递归)穿透查询的需求的不断增长,它注定会超越并颠覆传统的SQL。· 通过Restful API和多语言SDK,以及其他方式来全面支持各种图操作和图数据集的建模与优化。
· 支持不断增长的、热拔插图算法集,以满足用户的图数据库查询、搜索、统计、设置等诸多操作需求。此外,还可以通过可编程接口定制实现其他算法,或者通第三方独立软件开发商/集成商(甚至是开源社区)来支持算法集成。Ultipa图算法集中很多功能是其它图数据库厂家所望尘莫及的,例如鲁汶社区识别算法,速度是其它厂家的1,000倍以上(相比Python而言可能是数万倍以上的性能提升)。
· 与现有的IT基础架构兼容:与当前的IT基础设施无缝衔接、配合工作(见下图)。
· 知识图谱:尽管图数据库是非常基础的数据处理引擎,但是通过集成知识图谱,大量的图操作实现了可视化,对于过程可解释、决策可视化、结果-推导可视化而言意义不菲。
· 提供最佳的性价比和非常低的总拥有成本(TCO):基于通用PC架构搭建的Ultipa图系统有助于将总拥有成本至少降低70%,同时比现行的图架构提升性能10至1000倍(或与现行的SQL架构相比,性能或许超过1万倍)。
· 白盒人工智能、类脑计算:它可以说是人工智能世界中争论最激烈的话题,今天的人工智能和各种神经网络都是以黑盒为中心的,这使得审计和人的控制能力极为困难,但是图数据库和知识图谱的作用可以为白盒化、可解释的神经网络提供可能,因为图中的每个操作都是确定的(所有的点、边都有自己的权重和属性,它不会像深度学习或神经元网络那样基于概率的猜测工作)。而知识图谱则可以作为整个操作和决策过程的前端可视化层。
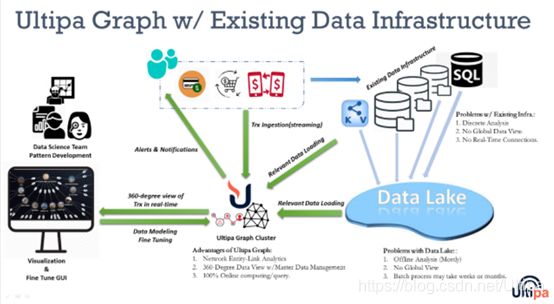
下面列出一组Ultipa实时图数据库所能实现的能力:
· 单实例算力:每秒遍历可达10—15亿点、边。
· N个节点集群算力:10-15亿N,接近100%的线性可扩展能力。
· 每个实例的数据导入能力:无属性情况下每秒超过3000万条边,在有多个属性的情况下每秒1—2百万点或边。
·单节点每秒查询数(QPS)/每秒处理事务数(TPS):20000—30000QPS,取决于每次查询或处理的复杂程度。大部分3跳深度的处理在微妙级以内完成。对于那些拥有超级节点的大型图(例如,具有超过100万条相邻边的节点),Ultipa实时图系统依然可以优雅的实时完成,而相同情况下,大部分其他的图引擎已经崩溃、内存耗尽或无法完成任务。
· 更小的动态运行时内存占用:通过优化内存中的数据结构,从而实现在运行时占用更小的空间。如果您考虑使用更小的内存设置来处理相同大小的图形数据集,以及更加稳定/强壮的图计算系统,最终这些都将转化为成本节约。
·无索引近邻存储模式:这个概念容易理解但很难实现。在构建一个(或任何)图计算引擎时,与传统的关系型数据库管理系统相比,最大的不同之处在于,Ultipa的实时图计算核心引擎构建在相邻哈希(Adjacency Hash)的基础之上,内存计算部分无需任何基于磁盘或硬盘的索引数据结构,且基于近邻无索引存储数据结构允许在高并发场景下的数据预加载进入CPU缓存,进而可以实现指数级的计算性能提升。
· 广度优先 vs. 深度优先:从算法的角度看,无论是广度优先还是深度优先,都可以实现图遍历。针对不同的图上查询请求,需要使用不同的算法来完成,有些是广度优先,其余则是深度优先。例如:K邻(K-hop)是典型的广度优先算法(BFS)的任务;而普通路径查询、模板路径查询或者是图算法则不一定是只能用BFS所能解决的问题,很多时候深度优先可以更快的返回结果。
·最大化并发性:在当今的计算机体系结构中,在单个节点(计算机)上或多节点集群使用多核上的多线程是实现最大并发的唯一途径和最有希望的方法。而关键是要避免线程资源闲置以及线程间的锁死,否则CPU会处于空闲状态,这是对计算资源的完全浪费。实时图系统上的大多数操作(查询、计算、图算法等)都经过了高并发优化,以充分利用底层CPU资源,因此,假设一个图计算节点上有32个虚拟CPU,则CPU的利用率可达到3200%,在多节点的分布式系统中,例如5节点,CPU全部利用率可达16,000%,而大多数其它图计算系统的CPU利用率都低得可怜(大多数情况下只能和主流的Python代码一样只能以单线程的方式运行)。这种高并发的能力在Ultipa上面也称作高密度并发图计算(High-Density Parallel Graph Computing)。
· 数据结构控制采用最细的粒度:如果能够使高并发的数据结构的锁的颗粒度足够细小,那么并发运行的速度的提升将非常显著。关于这一问题有兴趣的读者可以参阅《图数据结构的演进》一文。
二.实时图计算系统的架构
关于数据库架构的设计,没有所谓的唯一正确的答案。但是,笔者认为在众多可选方案当中,最为重要的是常识!当然,有的时候也包含一些逆向思维。
常识:
· 内存比外存快很多;
· CPU的3级缓存比内存快很多;
· 数据缓存在内存中要比在外存上快很多; · Java的内存管理很糟糕;
·树状数据结构(索引)的搜索时间复杂度是O(LogN),但是哈希数据结构的复杂度是O(1)。
逆向思维:
· SQL和RDBMS是世界上最好的组合了 — 在过去30年中,大抵如此,但是业务场景的不断推陈出新决定了新的挑战中,需要有新的架构来满足业务需求!互联网业务中通过大量的多计算实例并发来满足海量用户请求,但是每台计算实例(服务器)的计算密度并没有很高,图计算恰恰需要通过提升计算密度来实现高并发!
· 庞大有如BAT类的大企业一定是图技术最强大的提供商— 如果按照这个思路,BAT根本不会在过去20年中从小不点成长到今天的巨无霸。每一次新的巨大的IT升级换代的的机遇出现时,总会有一些小公司跑赢大盘。迷信BAT和迷信互联网一样,剩下的不是一个烂摊子就是一个死胡同。
下图是Ultipa实时图数据库的总体架构设计:
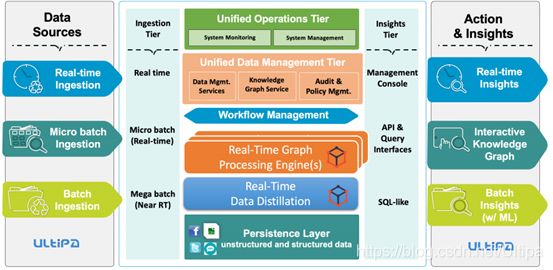
Ultipa实时图数据库的核心部件:
· 图计算引擎:充分利用多级存储加速
· 图存储引擎:数据持久层,采用近计算存储架构设计
· API和微服务,用于与数据交互、原型和应用程序
· 知识图谱和其他上层管理层与组件
图数据库的上层结构:
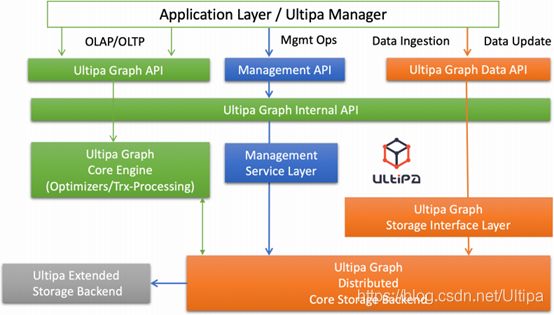
实时图数据库的基本概念
数据库模式和数据模型
图数据库普遍被认为采用的是模式自由(schemaa-free或无模式schema-less)的方式来处理数据,也就是说有别于我们熟知的关系型数据库,无需明确定义表格的模式。尽管任何图数据库依然存在模式这个核心概念,但是它被很大程度的简化为只包含以下组件:
· 节点:也称为顶点(对应的复数为Nodes和Vertices)
· 边:通常称为关系,每条边通常连接一对顶点(注:也有复杂的边模式会连接大于2个节点,但这非常罕见并且混乱。为避免复杂化,在本篇文档中不处理此类情况)。
· 边的方向:对于由边连接在一起的每对节点,方向是有意义的。例如:A–>父亲(是)–>B;用户A–>(拥有)账户–>账号A。 ·
节点的属性:每个节点相关的属性,每个属性用一个键值对来表达,例如:参考书-与神对话,波折号前是主键的名称,波折号后是数值字符串。
·边的属性:边的属性可能包括很多内容,从关系类型,到时间跨度,地理位置数据,描述信息,以及装饰边的键值对。
·标签:标签可以被看做是一种特殊点或边的属性,标签这一概念是Neo4j图数据库中的一种特有概念,它并不具备通用性,确切的说Neo4j可以通过标签进行检索加速,但是却无法对边的属性进行加速,这个可以看做Neo4j的一个底层设计与架构的缺陷。在Ultipa系统中,并不需要单独的”标签“定义,可以把标签看做就是一个图上的属性而已。
请注意,在那些动态构造的图中(通常是OLTP或HTAP类的场景),节点或边的属性甚至是点和边本身都可能是飞行数据(flight data)–意味着它们在某个特殊的时间点可能突然产生或消失。这就要求图系统支持增删改查(CRUD)的操作功能,它在银行和金融服务领域是特别常见的应用,而图计算框架则通常无法支持这种高度动态变化的图数据,这也是图数据库与图计算的本质区别之一。
图数据库的数据源中所对应的数据类型如下:
| 数据类型 | 描述 |
|---|---|
| 整数(Integer) | 4个字节 |
| 长整型(Long) | 8个字节整数(在大图中) |
| – | – |
| 字符型(String) | 变量 |
| 布尔值(Boolean) | 1或0(真或假) |
| – | – |
| 字节(Byte) | 1个字节 |
| 短整型(Short ) | 2个字节 |
| – | – |
| 单精度浮点型(Float) | 4个字节浮点精度 |
| 双精度浮点型(Double) | 8个字节浮点精度 |
| – | – |
| 唯一识别码(UUID) | 基本上是字符型 |
| 日期(Date) | 时间戳和子类型 |
| – | – |
| 其他类型 | 种类过多不一一列举 |
还有其他类型的数据,特别是那些半结构化、类结构化和非结构化的数据类型。但是,在图计算引擎运转时,这些丰富的数据类型并不一定需要被加载到引擎中去。因为这种操作可能既无意义,也不重要。或者说,它们应该加载到辅助数据库(例如文档数据存储),或者在持久化存储层,来满足客户的延展查询的需求。
核心计算与存储引擎如何处理不同的数据类型?
需要记住的是,某些类型的数据对高性能计算并不友好,以字符类型或唯一标识码(UUID)为例,这些数据类型往往会因为体量的巨大而造成存储空间膨胀,因此必须进行一些数据压缩处理(数据蒸馏)。
举个例子,一张图有10亿个节点,50亿条边,每条边用最简单的形式记录包含2个节点,如果使用唯一标识码(UUID)来代表每个节点,每个UUID是32字节的字符串,那么这张图最少占用内存的计算公式如下:
32 * 2 * 5,000,000,000 = 320 Billion Bytes = 320 GB RAM
如果你想进一步存储每一条边,并将节点对反转(图遍历加速的一种常见智能技术),则可以将其加倍为:640GB,而且这不包括任何标签、属性数据、不考虑任何缓存、运行时内存加载量……显然UUID并不适合作为数据库的主键,或者说主键要使用更为精简的数据类型。
使用适合的数据结构会如何?
· 实现最小foot-print(足迹)存储空间占用;
· 使用适合的数据结构来实现最快的点、边遍历;
· 记住: 内存仍然比CPU慢100-1000倍,简单的把所有运算放在内存中完成意味着CPU(它的多核与多线程)依然没有饱和;想办法使CPU饱和并让他们全速运行是每个高性能系统的终极目标。当然,这也与多线程代码如何组织和操作工作线程以尽可能高效地生产有关。这与所使用的数据结构密切相关— 如果你在JAVA中使用过堆(HEAP),它一定不像映射(MAP)或矢量(vector)那样的类型更有效率,列表和数组(list versus array)等也是一样。
另外,并非所有数据都需要或应该直接加载到图核心计算引擎中,这里要特别注意的是,点与边属性的绝对数量可能远远大于点和边的聚合存储大小的总和,因此在图遍历的过程中,它们并不总是构成关键组件—这也意味着它们可能是次要的和辅助的材料,在实时图计算过程中,这些辅助信息通常都并不参与计算。
为了更好的说明这些特点,下面列举一些例子:
· 为了计算一个人朋友的朋友的朋友,等同于图计算中的K跳(K-hop)操作,一个典型的广度优先(BFS)工作。
· 要了解2个人之间的所有关系,是一种点到点的路径查询,中间涉及非常多的节点,可能是人、账户、地址、电话、社保号、IP地址,公司等。
·查看公司高管的电话记录,近30天内的来电与呼出电话,以及这些来电者或和接受者如何进一步打电话,了解通话网络并知晓他们之间的关系?
这三个例子是典型的社会网络分析或反欺诈的场景。不同的图系统可以采用不同的方法来解决这一问题,但关键是:
· 尽可能快的完成工作,只要成本不高、可控,实时性总是更好的。
· 数据建模会影响作业的完成速度—假设存在大量噪声,这些噪声不仅会减慢作业速度,还会使作业容易出错。
·性价比一直是考虑因素,如果相同的操作总是要一遍又一遍的运行,那么为它创建一个专用的图表是有意义的。如果无法使用专用图,请利用图遍历优化器来高效地完成任务。
图遍历优化器有两种工作方式:
· 遍历所有的点、边然后过滤;
· 遍历的同时进行过滤(所谓动态剪枝)。
最能说明核心区别的是:
· 在第一种方法中,遍历是通过一个高度并发的多线程图引擎完成的,先获得一张子图,然后再根据过滤规则筛选并保留可能的路径集合。
·在第二种方法中,过滤规则在图遍历过程中以动态剪枝的方式来实现,一边遍历,一边筛选。
·这两种方法在真实的业务场景中可能有很大的不同,因为它影响属性(对于节点/边)的处理方式!第二种方法要求属性与每个节点/边共存;而第一种方法则可以允许属性单独存储。
· 不同的图形模型建模机制和不同的查询逻辑可能会在一种方法中比另一种方法运行得更快。这就是为什么我们在某些业务场景中,可以同时支持两种方法,并建议同时运行两个实例。通过这种对比,我们可以帮助您优化并找到图数据建模(和模式)的最合适的方法。
·未完待续·