浅谈大数据如何存储?
【前言】大数据的五大问题:
当传统的方法已无法应对大数据的规模、分布性、多样性以及时效性所带来的挑战时,我们需要新的技术体系架构以及分析方法来从大数据中获得新的价值。McKinsey Global Institute在一份报告中认为大数据会在如下几个方面创造巨大的经济价值:
·通过让信息更透明以及更频繁被使用,解锁大数据价值
·通过交易信息的数字化存储可以采集更多更准确、详细的数据用于决策支撑
·通过大数据来细分用户群体,进行精细化产品、服务定位 ·深度的、复杂的数据分析(及预测)来提升决策准确率
·通过大数据(反馈机制)来改善下一代产品、服务的开发
规划大数据战略、构建大数据的解决方案与体系架构、解决大数据问题以及大数据发展历程中通常会依次涉及大数据存储、大数据管理、大数据分析、大数据科学与大数据应用等五大议题。我们在接下来的几个篇章中会依次讨论。此外,鉴于大数据管理与分析的紧密关系,我们将把两者一并讨论。
今天,老孙主要讲大数据存储。

从19世纪开始到今天的近200年间,按时间轴顺序,数据存储至少经历了如下5大阶段,并且这些技术直到今天依然在我们的生活中随处可见。
**·穿孔卡(Punched Card)
**,穿孔卡设备(又称打孔机)
打孔机早在18世纪上半叶就在纺织行业用于控制织布机,不过最早把打孔机用于信息存储与搜索是在一个世纪之后,俄国人Semen Korsakov发明了一系列用于对穿孔卡中存储的信息进行搜索与比较的设备(homeoscope,ideoscope及comparator10)并且拒绝申请专利而是无偿地开放给公众使用,今天依然有很多设备在使用与穿孔卡同样原理的技术,如投票机、公园检票机等。
 图:穿孔卡片就是织布机能进行设计的本质,当这些穿孔卡片被送入织布机时,它们将下降或升起相应的线,用丝线重新创造图案
图:穿孔卡片就是织布机能进行设计的本质,当这些穿孔卡片被送入织布机时,它们将下降或升起相应的线,用丝线重新创造图案
*·磁带机(Magnetic Tape)
最早的磁带机可以追溯回20世纪之初,但在数据量爆炸式发展的今天,磁带作为一种低成本可用作长期存储的介质,依然具有一定优势。在2014年索尼与IBM宣布它们制造了一款容量高达185TB的磁带,平均每平方英寸的存储密度达到惊人的18GB11。

如果没有见到过磁带的年轻朋友们,只能说数字化浪潮太成功、太浮华了,很容易让我们觉得只有硬盘是“王道”。这就好比“各种豪”天天在高谈阔论,忘记了还有好几亿人的月收入不足¥2K。直到今天,世界的每一个角落的数据中心里面依然有大量的磁带机在被用作“冷数据”存储 , 比如像AWS这类的无论是公有云还是私有云的全球数据中心(IDC)中依然会大量使用磁带存储冷数据——因为它的成本是最低的!
·磁盘(Magnetic Disk)
磁盘有两种形式:
硬盘(Hard Disk Drive,HDD)
软盘(Floppy Disk Drive,FDD)
两者都是最早由IBM推出的(1956年的IBM 350RAMAC HDD,3.75MB(见下图);1971年IBM 23FD,79.75KB只读8英寸盘)。硬盘经60年来的发展在容量、速度、体积、价格与信息存储密度上提升到最初的百万倍。
 图:数据存储介质发展历程
图:数据存储介质发展历程
·光盘(Optical Disc)
光盘作为一种晚于硬盘出现的存储形式,因为其轻便、易于携带而在音响制品的传播中成为主要介质。
另外,它也可以作为永久(长期)数据存储的媒介。主要有3代OD产品:
·第一代的Compact Disc与Laser Disc
·第二代的DVD
·第三代的Blue-ray Disc(蓝光)、HD DVD等
光盘的存储能力在过去40年中并没有像硬盘一样快速增长,只是从最早期的CD的700MB到蓝光的100GB,只有约150倍的增长量而已。比起硬盘与下面要介绍的SSD类存储,光盘的数据吞吐速率是其短板,第三代的蓝光也只有63MB/s,大约是普通SATA类硬盘的1/3。
这种不与时俱进也解释了为何光盘在市场上真的是快完全灭绝了。中关村核心区的那些20—30年前卖光盘的地方如今都已经是一幢幢的创业孵化中心了。
·半导体内存(Semiconductor Memory)
半导体内存包含易失性(RAM)与非易失性(ROM、NVRAM)两大类存储器。
易失性的RAM有我们熟知的DRAM(计算机内存)与SRAM(CPU缓存);非易失性的ROM是只读内存,主要用于存放计算设备初始启动的引导系统;而NVRAM则是我们今天俗称的闪存(Flash Memory)。
闪存是由EEPROM(电可擦编程只读存储器)演化而来,早期主要是NOR类型闪存,如可拔插存储CompactFlash,后来逐渐被性价比更高的NAND类型闪存替代。不过值得了解的是,NAND是牺牲了NOR的随机访问与页内代码执行等优点来换取NAND的高容量、高密度与低成本优势的。大多数的固态硬盘(SSD)是采用NAND架构设计的,而SSD的数据吞吐率从消费者级的600MB/s到普通企业级的几GB/s(DRAM中最快的DDR4类内存可以工作在10—20GB/s的量级)。
传统意义上,按照冯·诺依曼计算机体系架构(Von Neumann Architecture)的分类方式,我们通常把CPU可以直接访问的RAM类的半导体存储称为主存储或一级存储;把HDD、NVRAM类的称为辅助存储或二级存储(Auxiliary or Secondary Storage);而三级存储(Tertiary Storage)则是通常由磁带与低性能、低成本HDD构成;最后一类存储则称为线下存储(Off-line Storage),包括光盘、硬盘以及磁带等可能组合方式。
前面我们是以时间轴为顺序,了解了存储介质的发展历程。在业界,我们通常还会按照数据存储的其他特性来对一种存储介质进行定性、定量分析,例如数据的易失性、可变性、各项性能指标、可访问性等。
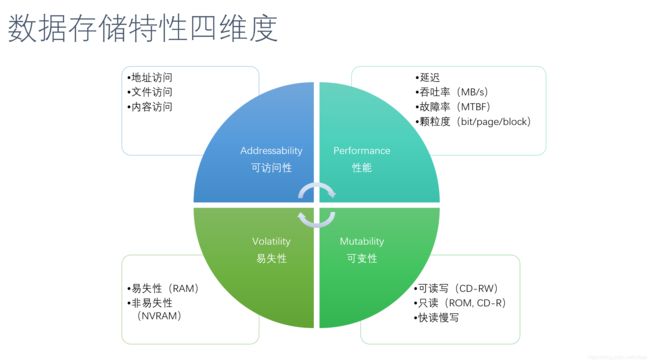 图:数据存储特性之四维度
图:数据存储特性之四维度
另外,存储逐渐由早期的单主机单硬盘存储发展为单主机多硬盘、多主机多硬盘、网络存储、分布式存储、云存储、多级缓存+存储以及软件定义的存储等形式。在存储的发展过程中有大量为了提高数据可访问性、可靠性、吞吐率以及节省存储空间或成本的技术涌现:
· RAID(磁盘阵列)技术
· NAS(网络附属存储)技术
· SAN(高速存储网络)技术
·Dedup(去重)技术、压缩、备份、镜像、快照技术等
· 软件定义存储(Software Defined Storage,SDS)技术
· RAID磁盘阵列技术
RAID(Redundant Array of Inexpensive Disks)
RAID,顾名思义,是用多块便宜的硬盘组建成存储阵列来实现高性能或(和)高可靠性。从这一点上看,早在1987年由UC Berkeley的David Patterson教授(David也是RISC精简指令集计算机概念的最早命名者)和他的同事们率先实现的RAID架构与十几年后的互联网公司推动的使用基于X86的商用硬件来颠覆IBM为首的大、小型机体系架构是如出一辙的。单块硬盘性能与稳定性虽然可能不够好,但是形成一个水平可扩展(scale-out)的分布式架构后可以做到线性提高系统综合性能。
RAID标准一共有7款,从RAID0一直到RAID6,不过最常见的是RAID0、RAID1、RAID。RAID0是分条(Striping)方式,它的原理是把连续的数据分散到多块磁盘上存储以线性提高读写性能。RAID1采用镜像(Mirroring)方式来实现数据的冗余备份,同时可以通过并发读取来提高读性能(写的性能则无任何帮助)。在实践中几乎不会见到RAID,一方面是RAID2与RAID3的低并发访问能力与实现复杂(RAID2/3分别采用了比特级与字节级的分条存储方式,而RAID0,4-6都是块级,显然后者的效率会相对更高);另一方面是它们存在的价值大抵只是为了保证RAID体系架构的学术完整性。 而RAID4则几乎被RAID5全面取代,因为后者均衡的随机读写性能弥补了前者的弱随机写性能缺陷。在企业环境中,通常采用RAID5或RAID6来实现均衡的数据读取性能提升,唯一的区别是RAID5采用分布式的奇偶校验位,而RAID6则多用一块硬盘来存储第二份奇偶校验位,例如RAID5最少需要3块盘,而RAID6则需要4块盘。
还有其他类型的非标准化RAID方案,如RAID1+0(常被简称为RAID1/0或RAID10,后者容易引起混淆,很难想象RAID[7-10…]是何等复杂)、RAID0+1、RAID7等。RAID0+1采用分条+镜像的硬盘组合,而RAID1+0采用镜像+分条的方式,后者在出现磁盘故障后重构的效率高于前者,因此也更为常见。RAID1+0适用于需要频繁、随机、小数据量写操作,因此对于OLTP、数据库、大规模信息传递等具有高I/O需求的业务常在存储层使用RAID1/0硬件设置。闪存也越来越广泛地应用(NAND逐步取代HDD)。基于NAND闪存构建的RAID存储架构被称作RAIN(Redundant Array of Independent NAND),有趣的是,这里是Independent而非Inexpensive,大抵是因为NAND的造价还是高于HDD硬盘数倍……
在高阶RAID中(如RAID[3-6]、RAID1/0、RAID0/1),Parity(奇偶)功能被广泛使用,它的主要目的是在硬盘故障掉线后以低于镜像成本的方式保护分条(Striped)数据。在一个RAID所构成的硬盘组中,硬盘越多则通过Parity可以节省的空间越多。例如,5块一组的RAID中有4块用来存储数据,1块存储奇偶校验位数据,开销(Overhead)为25%。如果把RAID扩容到10块硬盘,依然可以使用1块硬盘来存放校验数据,则摊销降低到只有10%,而用类似RAID1镜像的方法,开销为100%。
奇偶校验位的计算使用的是布尔型异或(XOR)逻辑操作,如下所示。如果盘A或B因故下线,剩下的B或A盘与Parity数据做简单的XOR操作就可以恢复A或B盘。
Drive A: 01011010
XOR Drive B: 01110101
Parity: 00101111
在云存储中通过对海量非常用数据、备份数据使用Parity操作可以实现大幅度的存储成本节省,近些年越来越常见的编码存储技术Erasure Coding(擦除码)的核心算法正是XOR逻辑运算。以Hadoop的HDFS作为大数据存储平台为例,它默认会对数据保存3份拷贝,这意味着200%的额外存储开销用来保证数据可靠性,通过Erasure Code可以让存储额外开销降低到50%(Windows Azure Storage12)甚至30%(EMC Isilon OneFS),从而大幅度提升存储空间利用率。随着数据的保障性增长,越来越多的技术型公司开始关注并采用擦除码技术,特别是那些先前需要对数据保存多份副本的。例如谷歌、淘宝的某些数据集需要多达6份副本,使用擦除码类技术的经济价值不言而喻。
NAS与SAN
网络存储技术如NAS、SAN是相对于非网络存储技术而言的。
在NAS、SAN出现之后我们把先前的那种直接连接到主机的存储方式称为DAS(Directly Attached Storage,直连存储或内部存储)。
NAS与SAN先后在20世纪80年代中期与90年代中期由Sun Microsystems推出最早的商业产品,它们改变了之前那种以服务器为中心的存储体系结构(例如各种RAID,尽管RAID系统也是采用块存储),形成了以信息为中心的分布式网络存储架构(见下图)。
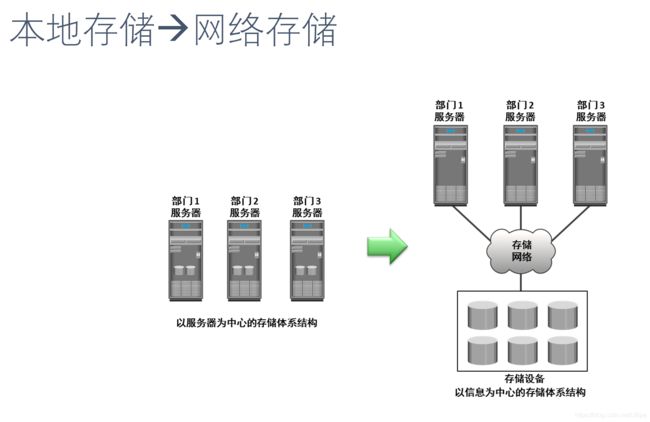
NAS与SAN的主要区别如下:
·NAS提供了存储与文件系统
·SAN提供了底层的块存储(上面可以叠加文件系统)
·NAS的通信协议主要有NFS/CIFS/SMB/AFP/NCP,它们主要是在NAS发展过程中由不同厂家开发的协议:Sun开发并开源的NFS,微软的SMB/CIFS,苹果开发的AFP以及Novell开发的NCP
·SAN在服务器与存储硬件间的通信协议主要是SCSI,在网络层面主要使用Fibre Channel(光纤通道)、Ethernet(以太网)或InfiniBand(无限宽带)协议堆栈来实现通信
SAN的优势如下:
·网络部署容易,服务器只需要配备一块适配卡(FC HBA)就可以通过FC交换机接入网络,经过简单的配置即可使用存储
·高速存储服务。SAN采用了光纤通道技术,所以它具有更高的存储带宽,对存储性能的提升更加明显。SAN的光纤通道使用全双工串行通信原理传输数据,传输速率高达8~16Gbit/s
·良好的扩展能力。由于SAN采用了网络结构,扩展能力更强
NAS的优点如下:
·真正的即插即用:NAS是独立的存储节点存在于网络之中,与用户的操作系统平台无关
·存储部署简单:NAS不依赖通用的操作系统,而是采用一个面向用户设计的、专门用于数据存储的简化操作系统,内置了与网络连接所需要的协议、因此使整个系统的管理和设置较为简单
·共享的存储访问:NAS允许多台服务器以共享的方式访问同一存储单元 · 管理容易且成本低(相对于SAN而言)
对象存储
分布式存储(Distributed Storage)架构中除了NAS与SAN两大阵营,还有一大类叫作Object-based Storage(基于对象的存储)—对象存储出道又比SAN大概晚了8~10年。与基于文件(File)的NAS和基于块(Block)的SAN不同,对象存储的基本要素是对存储数据进行了抽象化分隔,将存储数据分为源数据(Rawdata)与元数据(Metadata)。应用程序通过对象存储提供的API访问存储数据实际上可看作是对源数据与元数据的访问。一种流行的观点是对象存储集合了NAS与SAN的优点,不过对象存储具有NAS、SAN所不具有的如下3点优势:
· 应用可对接口直接编程
· 命名空间(寻址空间)可跨多硬件实体,每个对象具有唯一编号
· 数据管理颗粒细度为对象
对象存储在高性能计算特别是超级计算机领域应用极为广泛,全球排名前100的超级计算机系统有超过70%的使用开源的Lustre(Linux + Cluster)对象存储文件系统,其中也包括排名第一的中国天河2号与排名第二的Titan超级计算机。在商业领域,对象存储被用于归档(Archiving)及云存储(Cloud Storage),如早在2002年推出的EMC Centera以及HDS的HCP。在云存储领域最为知名的是2006年推出的AWS S3(S3已经成为云存储的事实标准,有大量竞争对手及开源解决方案的存储服务都兼容S3 API,如Rackspace的Cloud Files、Cloudstack、Openstack Swift、Eucalyptus等)以及微软、谷歌的Windows Azure Storage与Google Cloud Storage等,还有如Facebook为了存储数以十亿计的海量照片等非结构化数据而定制开发的对象存储系统Haystack13。
Amazon S3的架构设计以及提供的API超级简洁,可以存储任意大小的对象文件(小于5TB),每个文件对应2KB的元文件,多个对象文件可以被组织到一个bucket(桶)之中,每个对象在桶中被赋予唯一的key,可以通过REST风格的HTTP或SOAP接口来访问桶及其中的对象,对象下载直接通过HTTP Get或BitTorrent协议,对对象访问直接通过以下任何一款HTTP URL:
http://bucket/key
http://http://s3.amazonaws.com/bucket/key
http://bucket.http://s3.amazonaws.com/key
随着云计算、大数据与软件定义数据中心的出现,对存储管理有了更高的要求,传统存储也面临着诸多的挑战。
· 对于服务器内置存储来说,单一磁盘或阵列的容量与性能都是有限的,而且也很难对其进行扩展。也缺乏各种数据服务,例如数据保护、高可用性、数据去重等。最大的麻烦在于这样的存储使用方式,导致了一个个的信息孤岛,这对于数据中心的统一管理来说无疑是一个噩梦。
· 对于SAN和NAS来说,目前的解决方案首先存在一个供应商绑定的问题。与服务器的商业化趋势不同,存储产品的操作系统(或管理系统)仍然是封闭的。不用说不同的厂商之间的系统互不兼容,就是一家提供商的不同产品系列之间也不具有互操作性。供应商绑定的问题,也导致了技术壁垒和价格高企的现状。此外,管理孤岛的问题依旧存在,相对于DAS来说只是岛大一点,数量少一点而已。用户管理存储产品的时候仍然需要一个个单独登录到管理系统进行配置。最后,SAN与NAS的扩展性也仍然是个问题。
· 另外,一些全新的需求也开始出现,例如对多租户(Multi-tenancy)模式的支持,云规模(Cloud-scale)的服务支持,动态定制的数据服务(Data Service),以及直接服务虚拟网络的应用等。这些需求并不是可以通过对现有存储架构的简单修修补补就可以满足的。
软件定义存储技术
在这样的背景下,一种新的存储管理模式开始出现,这就是软件定义的存储(SDS)。
SDS不同于存储虚拟化(Storage Virtualization),SDS的设计理念与SDN(软件定义的网络)有着诸多相似之处。软件定义的存储旨在开辟这样的一个新世界:
· 把数据中心里所有物理的存储设备转化为一个统一的、虚拟的、共享的存储资源池。其中的存储设备包括专业的SAN/NAS存储产品,也包括内置存储和DAS。这些存储设备可以是同构的,也可以是异构的、来自不同厂商的
· 把存储的控制与管理从物理设备中抽象(Abstract)与分离(Decouple)出来,并将其纳入统一的集中化管理之中。换言之,也就是将控制模块(Control Plane)和数据模块(Data Plane)解耦合
· 基于共享的存储资源池,提供一个统一的管理与服务/编程访问接口,使得SDS与SDDC或者云计算平台下其他的服务之间具有良好的互操作性
· 把数据服务从存储设备中独立出来,使得跨存储设备的数据服务成为可能。专业的数据服务甚至可以运行在复杂的、来自不同提供商的存储环境中
· 让存储成为一种动态的可编程资源,就像我们现在在服务器(或者说计算平台)上看到的一样,即基于服务器虚拟化的软件定义计算(SDC)
· 让未来的存储设备采购与选择变得像现在的服务器购买一样简单直接
· 存储的提供商必须要适应并精通于为不同的存储设备提供关键的功能与服务,即使他们并不真正拥有底下的硬件
在过去的十多年中,服务器虚拟化、计算虚拟化、软件定义的计算已经彻底改变了我们对计算能力的理解。现在存储领域也在经历从存储虚拟化到软件定义存储的变革。前面我们提到过对象存储中出现的对源数据与元数据的分离,这实际上已经是一种存储虚拟化(抽象化)的概念:数据平面与控制平面,另外,存储资源池化(形成虚拟资源池)也是软件定义存储的重要概念。
软件定义存储的解决方案有很多种,有针对NAS/SAN网络存储设备的,有针对服务器内置磁盘与DAS的,有通用的解决方案,还有专为虚拟化平台优化而生的。这些不同的解决方案之间虽然存在诸多的差异,但大致上我们仍然可以把软件定义存储的科技栈(Technology Stack)自下而上分为三个层次:数据保持层、数据服务层与数据消费层。
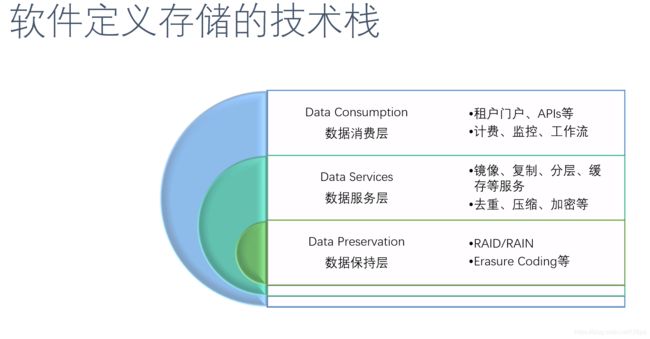 图:软件定义的存储的科技栈
图:软件定义的存储的科技栈
最下面一层是数据保持层,这是存储数据最终被保存的地方。这一层负责的工作是将数据保存到存储媒介中,并保证之后读取的完整性。保持数据的方式有很多种,具体的选择取决于对成本、效率、性能、冗余率、可扩展性等指标的需求,也取决于需要SATA磁盘、SCSI磁盘还是固态磁盘等不同的因素。此外,由于这部分的功能经过了虚拟化的抽象,我们可以根据需要选择各种不同的方案而不会影响到上层数据服务和数据消费的选择与实现。常见的数据保持方法包括前面提到的RAID磁盘阵列,基于廉价NAND型闪存阵列(RAIN)、简单副本(Replica)、Erasure Coding等。
中间层为数据服务层。这一层的组件主要的职责就是负责数据的移动并向上层提供服务接口:复制(Replication)、分层(Tiering)、快照(Snapshot)、备份(Backup)、缓存(Caching)。其他的职责还包括去重(Deduplication)、压缩(Compression)、加密(Encryption)、病毒扫描(Virus Scanning)等。一些新兴的存储类型也被归入数据服务层中,如对象存储(Object Storage)和Hadoop分布式文件系统(HDFS)等。需要指出:复制(Replication)与数据保持层的副本(Replica)功能的差异。副本只是最简单的一种数据冗余机制,防止硬件问题引起的数据丢失,对用户来说是完全透明的;而复制作为一种附加的数据保护服务,多用于高可用性、远程数据恢复(Remote Data Recovery)等场景,其中一个非常有特色的产品就是EMC的RecoverPoint。有兴趣的读者可以去详细了解一下,在此就不展开介绍了。
在理想的情况下,数据服务是独立于其下的数据保持层与其上的数据消费层的,各层的具体技术实现并不存在强依赖关系。同样,由于经过了虚拟化和抽象,数据服务得以从存储硬件设备中分离出来,可以按需动态创建(Provisioning),从而具有很大的灵活性。创建出来的数据服务可以根据软件定义存储控制器统一调度运行在任何一个合适的服务器或者存储设备上。
数据消费层是最贴近用户的一层。这里首先展现给用户的是一系列数据访问接口(Presentation),包括块存储(Block)、文件存储(File)、对象存储(Object)、Hadoop文件系统(HDFS),以及其他随着云计算与大数据发展而出现的新型访问接口。数据消费层的另一个重要的组成部分是展现给租户的门户(Tenant Portal),也就是每个用户的管理平台(GUI/CLI)。每个租户可以自己来进行,如部署(Provisioning)、监控(Monitoring)、事件及警报管理、资源的使用、报表生成、流程管理或者定制服务等。灵活的编程接口(API)也是这一层的核心组件,用于更好地支持存储与用户应用的整合。与普通的编程接口相比,软件定义存储的接口有着更高的标准和更多的功能需求。
软件定义存储作为软件定义数据中心的一个核心组成部分,与系统中的其他组件(软件定义计算、软件定义网络)存在大量的交互,因此对互操作性(Interoperability)有着很高的要求。关于组件之间的互操作与协同工作,详细内容可参见后续章节。从数据消费层的视角来看,其下的数据服务层与数据保持层提供的是一个统一的虚拟化资源池,本层基于此虚拟资源池根据用户需求进行分配、创建与管理。
综上所述,海量数据的存储历程下图所示,从本地存储,到网络存储(尤其是以NAS和SAN为代表的分布式存储),到以对象存储为实施标准的云存储阶段,未来的发展方向当是软件定义的存储,通过软件定义存储来实现低成本、高效率、高灵活性以及高度可扩展性。
·文/ 老孙(孙宇熙:云计算、大数据、高性能存储与计算系统架构专家 )
·END·