Pytorch中in-place操作相关错误解析及detach()方法说明
文章目录
-
-
- 0. 前言
- 1. 背景问题描述
- 2. 报错解析:in-place(置位)操作相关理解&说明
- 3. detach()方法的作用
-
- ①给变量指派一个新的内存
- ②把变量变成叶子节点
- 4. 更正后代码
-
0. 前言
*感谢荼靡,对本文的大力支持。
*感谢新星计划让我认识了优秀的博主。
按照国际惯例,首先声明:本文只是我自己学习的理解,虽然参考了他人的宝贵见解,但是内容可能存在不准确的地方。如果发现文中错误,希望批评指正,共同进步。
最近在构建nn.RNN模型,及以nn.RNN为基础的nn.LSTM模型遇到了下面这个让人非常头疼的good luck报错:
RuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation: [torch.FloatTensor [1, 1]], which is output 0 of AsStridedBackward0, is at version 3; expected version 2 instead. Hint: the backtrace further above shows the operation that failed to compute its gradient. The variable in question was changed in there or anywhere later. Good luck!
CSDN上关于上面错误提示的说明文章有很多,但是几乎都是直接说明解决方案(而且大部分还没用),欠缺对这个报错的机理解释。因此写作本篇博客记录本问题的解决过程及相关理解。
1. 背景问题描述
把基于nn.RNN的模型简化成以下代码:
import torch
rnn = torch.nn.RNN(input_size=1, hidden_size=1, num_layers=1)
train_set_x = torch.tensor([[[1]],[[2]],[[3]],[[4]],[[5]]], dtype=torch.float32)
train_set_y = torch.tensor([[[2]],[[4]],[[6]],[[8]],[[10]]], dtype=torch.float32)
h0 = torch.tensor([[0]], dtype=torch.float32)
h_cur = h0
loss = torch.nn.MSELoss()
opt = torch.optim.Adadelta(rnn.parameters(), lr = 0.01)
with torch.autograd.set_detect_anomaly(True):
for i in range(5):
opt.zero_grad()
train_output, h_next = rnn(train_set_x[i], h_cur)
rnn_loss = loss(train_output,train_set_y[i])
rnn_loss.backward(retain_graph=True)
opt.step()
print(train_output)
h_cur = h_next
运行这段代码发现在训练网络模型是出现以上错误提示。
原问题链接:Pytorch框架nn.RNN训练时反向传播报错
2. 报错解析:in-place(置位)操作相关理解&说明
上面的错误提示“one of the variables needed for gradient computation has been modified by an inplace operation”,直译就是过来“梯度计算需要的一个变量被一个置位操作更改了”
之前这个问题一直困扰我的原因就是对置位操作的理解不到位,原来我理解置位操作只有形如“x += 1”或“x -= 1”这种运算。但我的原代码中是没有这种运算的,却在报置位操作的错误。
其实置位操作是泛指直接更改内存中的值,而不是先复制一个值再更改复制后的这个值的操作。
An in-place operation is an operation that changes directly the content of a given Tensor without making a copy. Inplace operations in pytorch are always postfixed with a , like .add() or .scatter_(). Python operations like += or *= are also inplace operations.
我们常用的赋值方法"a = b",虽然a和b的值是相同的,但是这个相同的值是在两个完全不同的物理地址中,这样如果更改a就不会对b造成任何影响,反之亦然。
但是如果上面的“a = b”是一个置位操作,那么如果改了a,对应b也会做同样的变更,因为他们完全共用一个物理地址,共享同一块内存。
所以置位操作应该慎用,因为可能共享的变量多了,在对这些变量做计算(变更)时,就可能带来一些非期望的变量变更。
那上面的问题代码置位操作在哪?
答:在 “h_cur = h_next” 。通过id()方法,可以看到这两个变量的地址一致。我们认为的赋值操作被Pytorch变成了置位操作。
print(id(h_cur))
print(id(h_next))
输出-------------------------------------
2943427659952
2943427659952
回顾上面报错的后半句“[torch.FloatTensor [1, 1]], which is output 0 of AsStridedBackward0, is at version 3; expected version 2 instead. ” 有一个[1,1]的tensor(也就是RNN中的隐层输出h)已经是第3版(version)了,而期望的是第2版(version)。这里的版(version)我理解的就是置位操作的次数。
因为上面 “h_cur = h_next” 这次运算,导致h_cur多操作了一次(版),尽管实际上它的值没变,但是导致了版次不匹配(version mismatch),最终造成了上面的报错。
那为什么Pytorch要默认存在置位操作?
答:为了节省内存,提高运行速度。上面已经说过了,置位操作可以直接更改内存中的数据,而不用先复制一份数据。现在大型的神经网络动辄几万,几十万,甚至上百万个参数,如果不用置位操作,每次backward前都先复制一份参数,再在复制后的参数中进行计算,将会耗费大量的内存来存储这些参数。
隐层输出h如何影响梯度计算?
答:计算公式为:

具体过程请见我此前手推的RNN数学模型:基于Numpy构建RNN模块并进行实例应用(附代码)
当然,如果实在对数学推导过程很抗拒,直接了解这个结论也行:在RNN中隐层输出h是直接参与反向传播梯度计算过程的。
最终如何解决in-place操作导致的错误?
答:取消in-place操作。给我们实际上要“赋值”的变量强制指派一块新的内存,可以实现这个目的的方法有detach()方法,clone()方法。由于detach()应用更广泛,下面仅说明detach()方法。
通过常规的引入一个中间变量的方法是不行的,比如:h_cur = mid , mid = h_next 。因为Pytorch仍会默认是置位操作,通过打印id可以看到,h_cur,mid,h_next仍是共用物理地址。
3. detach()方法的作用
①给变量指派一个新的内存
把上面的代码改成:
h_cur = h_next.detach()
print(id(h_cur))
print(id(h_next))
输出---------------------------------------------
3197060036944
3197060036864
两个变量彻底分开,本问题解决。
②把变量变成叶子节点
通过is_leaf()方法可以识别一个变量是否为叶子节点:
h_cur = h_next.detach()
print('h_next_requires_grad:',h_next.requires_grad)
print('h_cur_requires_grad:',h_cur.requires_grad)
print('h_next_is_leaf:',h_next.is_leaf)
print('h_cur_is_lear:',h_cur.is_leaf)
输出---------------------------------------------
h_next_requires_grad: True
h_cur_requires_grad: False
h_next_is_leaf: False
h_cur_is_lear: True
可见detach()方法中断了h_cur的反向传播,把requires_grad设定成了False,且把h_cur设成了叶子节点。
关于叶子节点/非叶子节点的定义及作用,非本文说明对象,推荐一篇写的非常好的博客:Pytorch 叶子张量 leaf tensor (叶子节点) (detach)
4. 更正后代码
更正后完整代码如下:
import torch
rnn = torch.nn.RNN(input_size=1, hidden_size=1, num_layers=1)
train_set_x = torch.tensor([[[[1]]],[[[2]]],[[[3]]],[[[4]]],[[[5]]]], dtype=torch.float32)
train_set_y = torch.tensor([[[[2]]],[[[4]]],[[[6]]],[[[8]]],[[[10]]]], dtype=torch.float32)
h0 = torch.tensor([[[0]]], dtype=torch.float32)
h_cur = h0
loss = torch.nn.MSELoss()
opt = torch.optim.Adadelta(rnn.parameters(), lr = 0.01)
for i in range(5):
opt.zero_grad()
train_output, h_next = rnn(train_set_x[0], h_cur)
rnn_loss = loss(train_output,train_set_y[0])
h_cur = h_next.detach()
rnn_loss.backward()
opt.step()
print(train_output)
# print(id(h_cur))
# print(id(h_next))
# print('h_next_requires_grad:',h_next.requires_grad)
# print('h_cur_requires_grad:',h_cur.requires_grad)
# print('h_next_is_leaf:',h_next.is_leaf)
# print('h_cur_is_lear:',h_cur.is_leaf)
另外说明,在有些版本中,即使不用detach(),最开始的代码也是可以运行的,例如下面:
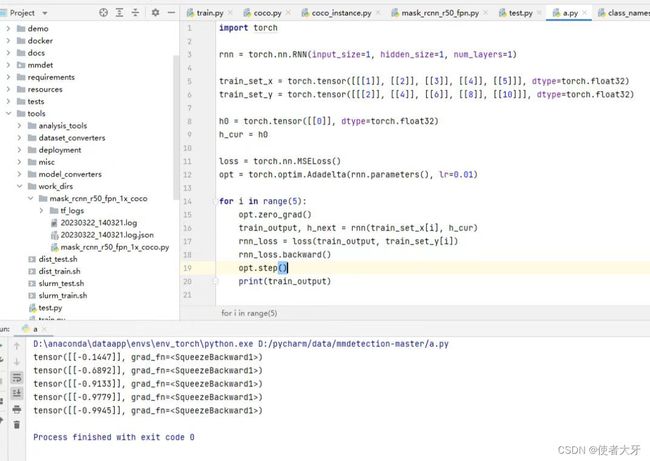
推测这可能是较早期的Pytorch中没有默认in-place操作,当然这就会导致上面说的内存消耗变多的问题。