6.Python中使用Pandas定位DataFrame的位置、排序、替换数值
1.Pandas_isin()选择
df.isin(values) 返回结果为相应的位置是否匹配给出的 values,最常用的是对于单列的选择
values 为序列:对应每个具体值
values 为字典:对应各个变量名称
values 为数据框:同时对应数值和变量名称
import pandas as pd
df = pd.read_excel('stu_data.xlsx')
# 1.value为序列:当value的值等于匹配的值时,返回True,其余返回False。再把返回的列表传入数据表中,可以返回出目标值所对应的内容
# 1.1 匹配索引
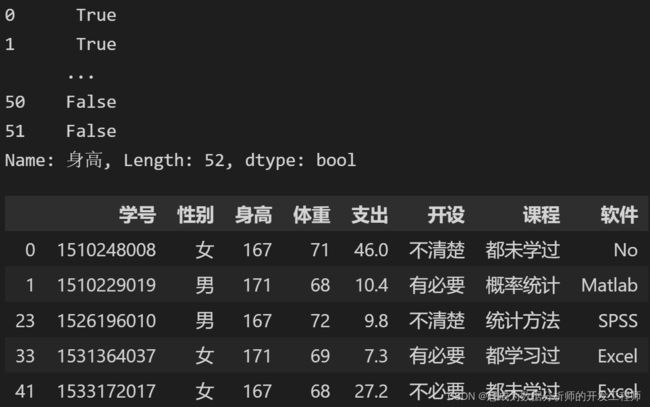
print(df.index.isin([0,1,2,51]))
df[df.index.isin([0,1,2,51])]
# 1.2 单列值匹配:获取身高 df.col.isin([ , ])
pd.options.display.max_rows = 5
print(df.身高.isin([167,171]))
df[df.身高.isin([167,171])]
# 2.传入值为字典:数据表中的值与字典中的匹配值相等时,返沪true
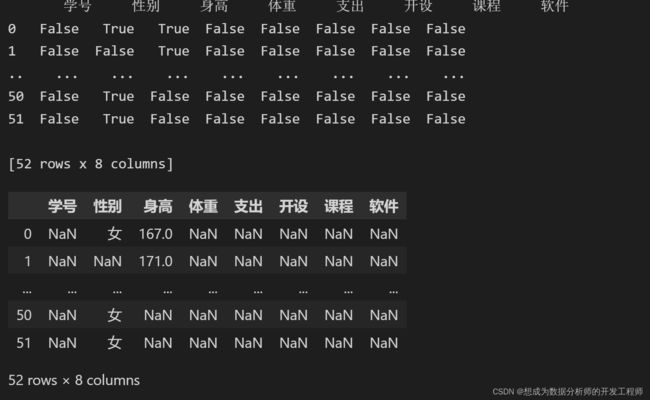
print(df.isin({'身高':[167,171],'性别':['女']}))
df[df.isin({'身高':[167,171],'性别':['女']})]
# 3.传入DataFrame对象: 数据表与DataFrame对应的值相等时返回True(不是全部值都完全相等才行)
df2 = pd.DataFrame({'身高':[167,171],'性别':'女'})
print(df2)
df.isin(df2)


2.Pandas_query()的使用
使用boolean值表达式进行筛选
df.query(
expr:语句表达式
inplace=False;是否直接替换原数据框
)
可以使用前缀“@”引用环境变量
等号为==,而不是=
import pandas as pd
pd.options.display.max_rows = 5
df = pd.read_excel('stu_data.xlsx')
# 1.单个条件筛选:身高高于170
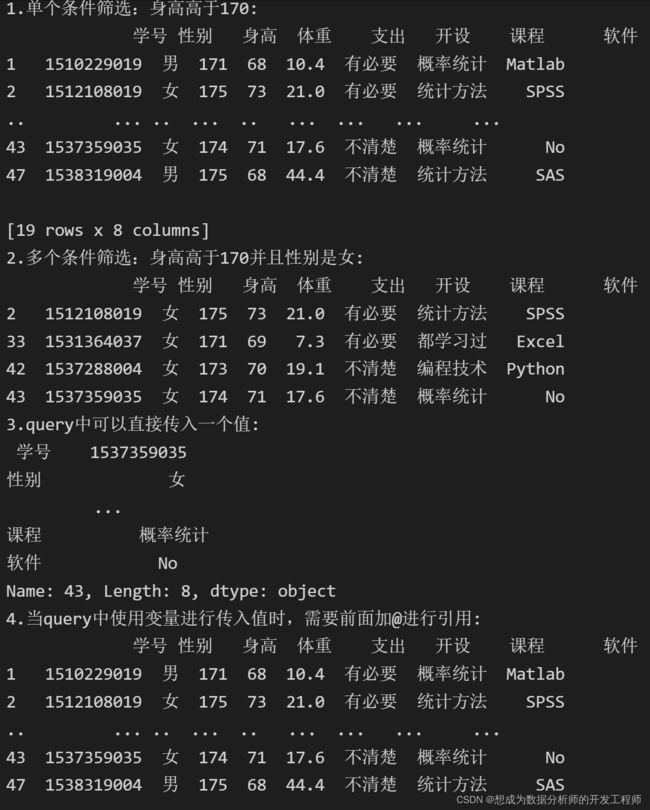
print('1.单个条件筛选:身高高于170:\n',df.query('身高>170'))
# 2.多个条件筛选:身高高于170并且性别是女
print('2.多个条件筛选:身高高于170并且性别是女:\n',df.query('身高>170 and 性别=="女"' ))
# 3.query中可以直接传入一个值:从行索引中匹配相等的索引
print("3.query中可以直接传入一个值:\n", df.query('43'))
# 4.当query中使用变量进行传入值时,需要前面加@进行引用
height = 170
print('4.当query中使用变量进行传入值时,需要前面加@进行引用:\n',df.query('身高>@height'))
3.Pandas_排序
3.1 Pandas_sort_index排序
df.sort_index(
level :(多重索引时)指定用于排序的级别顺序号/名称18
ascending = True :是否为升序排列,多列时以表形式提供
inplace = False : 是否要修改原表
na_position = 'last‘ :缺失值的排列顺序,
first/last
3.2 Pandas_sort_values排序
df.sort_values(
by :指定用于排序的变量名,多列时以列表形式提供
ascending = True :是否为升序排列
inplace = False :
na_position = 'last‘ :缺失值的排列顺序,
first/last
)
3.3 代码展示
import pandas as pd
# 1.Series对象排序
data = pd.Series([12,2,14,100,32], index=list('faecd'))
# 1.1按照索引排序
print('1.1按照索引排序升序\n',data.sort_index())
print('1.1按照索引排序降序\n',data.sort_index(ascending=False))
# 1.2按照变量值排序
print('1.2按照变量值排序升序\n',data.sort_values())
print('1.2按照变量值排序降序\n',data.sort_values(ascending=False))

import pandas as pd
pd.options.display.max_rows = 100
df = pd.read_excel('stu_data.xlsx',index_col=[2,4])
# 2.DataFrame排序
# 2.1 指定一个目标值排序索引降序
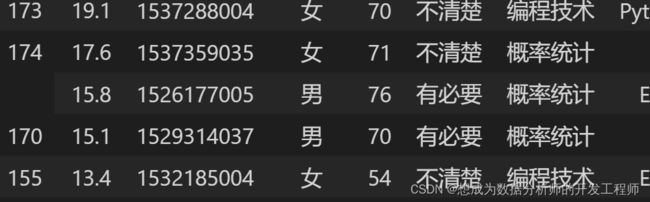
df.sort_index(level='支出', ascending=False)
# 2.1 指定多个目标值排序索引(对两个指标用不同的排序方式进行排序)
df.sort_index(level=['支出','身高'],ascending=[False,True])
# 2.2通过变量值进行混合排序
df.sort_values(by=['体重','学号'],ascending=[False,True])

4.Pandas_计算新变量
df[‘vamame’] = value
import pandas as pd
df = pd.read_excel('stu_data.xlsx')
pd.options.display.max_rows = 5
# 1.对某一列进行赋值
# 1.1 方法1:
df.身高 = 190
# 1.2 方法2:
df['体重'] = 50
# 2.简单DataFrame中新增列
# 2.1 方法1:
df['col1'] = 10
# 2.2 方法2:
df.col2 = 9 # 注意:该方法不会抛异常,但是不会新增新的一列
# 3.DataFrame中进行运算后新增一列
df['col2'] = df.身高-10
df['col3'] = df.身高-df.体重
# 4.DataFrame中进行数学运算后新增
import math
import numpy as np
df['col4'] = math.sqrt(25)
df['col5'] = np.sqrt(36)
# df['col6'] = math.sqrt(df.体重) # TypeError: cannot convert the series to 会抛异常,处理方法见5.
df['col6'] = np.sqrt(df.体重)
# 5.基于一个原变量做函数运算apply用法
# df.apply(
# func : 希望对行/列执行的函数表达式
# axis = 0 :针对行还是列逬行计算
# 0 ' index':针对每列进行计算
# 1' columns ':针对每行逬行计算
# )
df['col7'] = df.体重.apply(math.sqrt)
df['col8'] = df.体重.apply(np.sqrt)
# apply传入自定义函数
def get_msg(msg):
return msg[0:1]
df['col9'] = df.课程.apply(get_msg)
df
# 6.assign() 生成新的DataFrame对象,并且不修改原本的DataFrame
df2 = df.assign(col10 = df.开设.apply(get_msg))
df2
# 7.在指定位置插入新变量列
# df.insert(
# loc :插入位置的索引值,0 <= loc <= len (columns)
# column :插入的新列名称
# value : Series 或者类数组结构的变量值
# allow_duplicates = False :是否允许新列重名
# )#该方法会直接修改原 df
df.insert(1,'col0',200)
df.insert(0,'col',df.支出*100)
df
df2:

df:
5.Pandas修改替换变量的值(如何定位DataFrame中的某个位置)
本质上是如何直接指定单元格的问题,只要能准确定位单元地址,就能够做到准确替换。
import pandas as pd
df = pd.read_excel('stu_data.xlsx')
# 修改替换变量的值
# 方法1:直接定位 —— 通过位置去定位后修改
df.性别[0] = "不清楚"
# 方法2:loc与iloc —— 通过位置去定位后修改
# loc[普通行索引,普通列索引] iloc[位置行索引, 位置列索引]
df.loc[0,'学号'] = 123
df.iloc[0,2] = 185
# 方法3:isin修改 —— 通过值去定位后修改
df.开设[df.开设.isin(['不清楚'])] = 'isin修改为不清楚'
# 方法4:replace修改 —— 通过值去定位后修改
# 修改性别为标签值
df.性别.replace(['男','女'],[1,2],inplace=True)
df.性别.replace({1:'男人',2:'女人'},inplace=True)
df
6.Pandas指定数值范围替换
import pandas as pd
df = pd.read_excel('stu_data.xlsx')
# 方法1:使用正则表达式完成替换:将开设中的不清楚 替换为 不可以
df.开设.replace(regex='不.+', value='不可以', inplace=True)
# 方法2:使用行筛选方式完成替换:用行筛选方式得到行索引,然后用 loc 命令定位替换 目前也支持直接筛选出单元格进行数值替换
# loc [start:end] = [start:end]
# iloc [start:end] = [start:end)
df.身高.loc[0:2] = 170
df.身高.iloc[0:2] = 180
# 方法3:满足条件筛选后替换
# 先获取列后筛选出值
df.体重[df.体重 > 70] = 99
# 先筛选后 获取列值
df[df.体重>70].体重 = 88 # 可以发现,这种方法无法去修改值!!!! 需要使用query去修改
# 方法4:query筛选
df.loc[df.query('性别=="女" and 体重>60').体重.index,'体重'] = 50
df
