找工作必看,用Python爬取数据分析岗位信息并可视化分析
导读:
最近经常收到人事小姐姐和猎头小哥哥的面试邀请,想想最近也不是招聘旺季呀。但又想到许多小伙伴们有找工作这方面的需求,今天就来分享一篇简单的爬虫案例,旨在跟大家一起分析一下部分招聘市场。以"数据分析"为例。
Tips: 本次爬虫案例分析结果仅供学习参考,不做就业指导,根据自己实际需求自行分析决策。
需要用到的模块
import requests
import time
import random
import os
import requests
from bs4 import BeautifulSoup
import openpyxl
import numpy as np
爬虫代码
本次爬虫难度不大,属于入门级别的,只要懂得requests请求,BeautifulSoup解析即可轻松上手,下面是本次爬虫的主要代码。
def getPosition(url):
times=time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
print(u'\n本地时间:',times)
print(u'\n开始采集数据...')
# 请求获取返回值
data = getData(url)
# BeautifulSoup解析网页
soup = BeautifulSoup(data.text, features='lxml') # 对html进行解析,完成初始化
results = soup.find_all(attrs={'class': "job-list"})
job_list = results[0].find_all(attrs={'class': "job-primary"})
lens = len(job_list)
for num in range(lens):
positions = []
job = job_list[num]
# 根据节点查询相应数据
positions.extend(job.find_all(attrs={'class': "job-title"})[0].text.split())
positions.append(job.find_all(attrs={'class': "job-limit"})[0].text.split()[0])
job_limit = job.find_all(attrs={'class': "job-limit"})[0]
positions.extend(str(job_limit.p).rstrip('').lstrip(''
).split(''))
positions.append(job.find_all(attrs={'class': "company-text"})[0].text.split()[0])
company = job.find_all(attrs={'class': "company-text"})[0].p
positions.extend(company.a.text.split())
positions.extend(str(company).rstrip('').split('')[1:])
positions.extend(job.find_all(attrs={'class': "info-desc"})[0].text.split())
positions.append(','.join(job.find_all(attrs={'class': "tags"})[0].text.split()))
write_to_excel(positions)
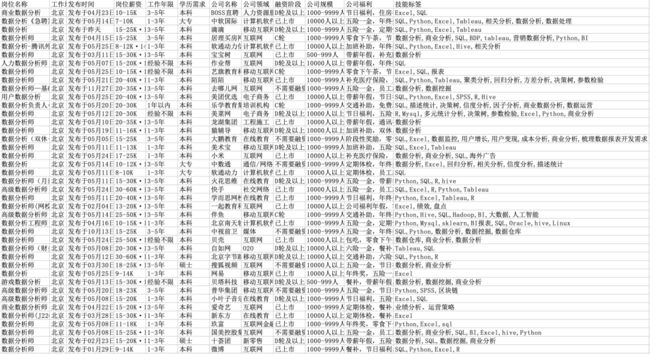
数据结果
获取到数据之后,需要对原始数据进行一些简单的清洗工作。清洗前需要先思考下你需要获取哪些信息,有针对性的清洗。
一探究竟
本次可视化分析工具是 Pyecharts
从技能标签找学习方向
将所有公司的技能标签统计后,绘制前十的技能需求直方图。从图中很明显地看到遥遥领先的分别是Python、SQL,数据分析思维及能力及Excel也紧跟其后。像小编做的数据挖掘技能需求量也不小。

似乎在数据分析职位中,Pythoner和SQL boy都是非常抢手的。
哪些城市的数分岗位更热门

由全国地理图可看的出,北上广深加苏州、厦门、杭州等都是很热门的城市,你会选择哪个城市?
全国都有哪些公司招聘数分职位
以公司名称的大小来表示各个公司招聘职位数,绘制招聘公司词云图。很明显地看的出如腾讯、阿里、OPPO、Boss等大厂需求量较大,因此机会也多。所以大家学好数据分析,进入大厂不是梦。

谈钱不伤感情
大家最关心的还是一个职位能给到我多少钱,比较还要养家糊口。
从全国各城市平均薪资排行榜看,遥遥领先的是北京、深圳、上海和杭州,分别是23K、19.7K、18.6K和18.5K。而小编所在的城市——成都,只有9K。文章不想写了,我想静静。。。

看完各城市平均薪资,再来瞧瞧各个行业的平均薪资吧。人力资源服务及银行这两个行业均超过了20K。
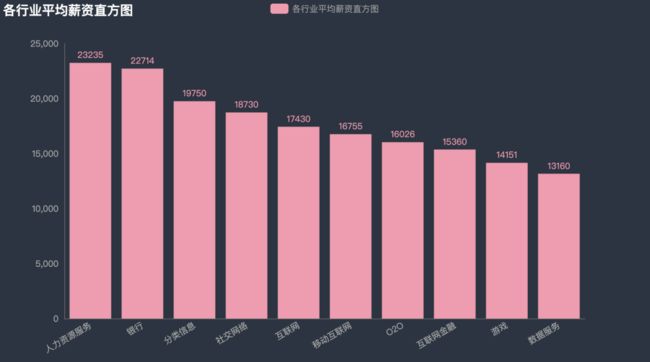
首先随机查看一个人力资源服务的,这类职位多为商业数据分析,该职位的特点是高学历是硬性,但对于工具使用要求不高,只需熟练使用EXCEL即可,需要些管理经验。

再看看银行行业,薪资水平真香!虽然没有说学历要求,但可能是一个默认的情况吧。职位描述中多次提及到业务数据,说明他对业务要求较高。需要会SQL语句,需要会搭建数据分析模型,这类模型不一定是机器学习模型,也会有很多统计类、数学类模型等等。
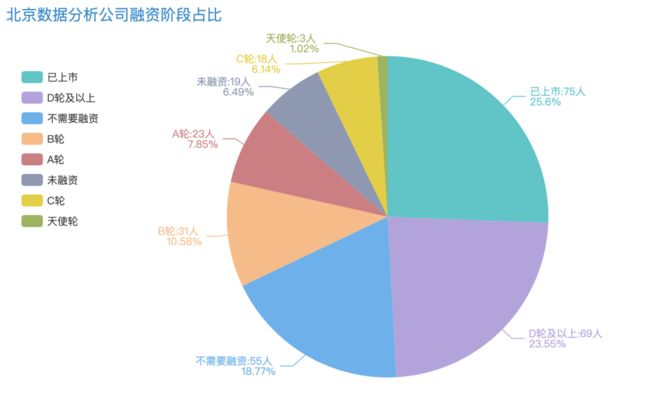
为啥北京公司的工资高
单独分析下北京的数据分析公司情况,公司规模在1000-9999人占比第一,达到37.2%,10000人以上的公司也高达22.87%,都是些大厂,工资水平能不高么。

有人说,公司人多,不一定有钱呐。好嘛,再来看看他们公司的融资阶段情况呢。D轮及以上上市的公司已经接近一半了,多半都是有钱的主哇。
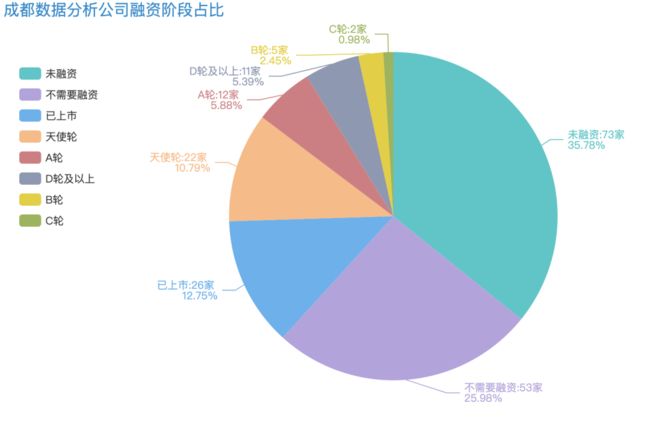
成都数据分析公司啥情况
占比最多的是20-99人的小型公司,规模在1000-9999人的公司仅有34家,跟首都简直不能比。所以成都平均公司水平不过万,也是有原因的。

再来看看公司融资情况,大部分都是未融资的,上市公司仅占12.75%,D轮及以上的也只有5.39%呐。但从另一个角度想想,成都的发展潜力还是很大的。作为西南的重要枢纽城市,相信他会越来越棒的。
你还有啥想了解的——福利呐
最后再来看看大家比较关心的公司福利状况。
通过绘制福利词云图,看到大部分公司的常见福利都还是有的。意外的是少部分公司有提供不一样的福利,如无息住房借款、专属健身房、孝顺金等,真让人羡慕哇。

写在最后
最后多说两句。我们上面分析的内容仅是从一些常见的指标,并不能作为你入职一家公司的主要判断依据。个人觉得还需要从一家公司的企业文化、公司发展方向、提供职位的发展空间、所处行业跟你预期是否符合等等方面综合衡量。
打铁还需自身硬,选择都是双向的,你想入职一个理想的公司,首先还是需要达到他的岗位要求。
关于Python技术储备
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
Python学习路线汇总
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。(全套教程文末领取哈)

Python必备开发工具

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
Python学习视频600合集
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

100道Python练习题
检查学习结果。

面试刷题


资料领取
上述这份完整版的Python全套学习资料已经上传CSDN官方,朋友们如果需要可以微信扫描下方CSDN官方认证二维码输入“领取资料” 即可领取
