mysql树形结构表设计(Path Enumerations,Closure Table)
效果
首先看下返回到前台的效果:

下面是返回给前台的json:
{
"code": 1,
"data": [
{
"children": [
{
"children": [
{
"id": 76,
"parent_role_id": 74,
"parentname": "管理员1号",
"role_name": "群员1号",
"role_type": "111"
},
{
"id": 77,
"parent_role_id": 74,
"parentname": "管理员1号",
"role_name": "群员2号",
"role_type": "2222"
}
],
"id": 74,
"parent_role_id": 73,
"parentname": "群主",
"role_name": "管理员1号",
"role_type": "111"
},
{
"children": [
{
"id": 78,
"parent_role_id": 75,
"parentname": "管理员2号",
"role_name": "群员3号",
"role_type": "333"
}
],
"id": 75,
"parent_role_id": 73,
"parentname": "群主",
"role_name": "管理员2号",
"role_type": "222"
}
],
"id": 73,
"parent_role_id": 0,
"role_name": "群主",
"role_type": "111"
}
],
"msg": "执行成功"
}引言
一般比较普遍的就是四种方法:(具体见 SQL Anti-patterns这本书)
Adjacency List:每一条记录存parent_id
Path Enumerations:每一条记录存整个tree path经过的node枚举
Nested Sets:每一条记录存 nleft 和 nright
Closure Table:维护一个表,所有的tree path作为记录进行保存。
各种方法的常用操作代价见下图

作者:卢钧轶
链接:https://www.zhihu.com/question/20417447/answer/15078011
来源:知乎
著作权归作者所有,转载请联系作者获得授权。
正文
如上所见,我们选择方案2和方案4来进行设计
方案2(Path Enumerations)
因为我使用的是方案4,所以方案2我就直接引用别人的代码。
详情可查看http://blog.csdn.net/biplusplus/article/details/7433625

简单说说,图中的path存的是每个层级的关系,像第6条记录的意思就是我的上级是5,5的上级是2,2的上级是1,其他记录同理可得。
这种方法乍看很清晰很明了,但其实维护是比较难维护的,而且有可能会产生脏数据,毕竟你所维护的都是通过字符串来维护
不做过多介绍,因为这个方案确实是最简单的,如上所说,每种方案都适用不同业务。
方案4(Closure Table)
这个方案我也是参考上面的博客,可以先看看他的表结构图

下面是本文的表结构:
这是角色表,包含角色名称,父角色ID
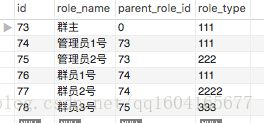
这是角色关系表,ancestor_id是父级和祖父级ID,level是当前角色相对ancestor_id而言的层次,rold_id则是角色ID

举个例子,群主这个角色是属于最顶层,那么只插入一条关联数据,表示自身,即 73,0,73
管理员1号是属于群主下面的一个角色,那么首先同样需要先创建一个表示自身的数据,即74,0,74 ,然后创建管理员1号和群主关联的数据,即73,1,74 这里的1就是代表管理员1号对于群主而言,他是一级直属关系,所以level为1
规律
每个子角色都需要和自身以及所有的上级角色关联,假设有5个等级,A1-A2-A3-A4-A5,当创建A5的时候,先插入自身数据,然后循环所有上级进行关联。
代码部分
public class RoleTree {
private Integer id;
private Integer ancestor_id;
private Integer level;
private Integer role_id;
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public Integer getAncestor_id() {
return ancestor_id;
}
public void setAncestor_id(Integer ancestor_id) {
this.ancestor_id = ancestor_id;
}
public Integer getLevel() {
return level;
}
public void setLevel(Integer level) {
this.level = level;
}
public Integer getRole_id() {
return role_id;
}
public void setRole_id(Integer role_id) {
this.role_id = role_id;
}
}添加操作代码:
private void insertIntoRoleTreeTable(Role record) {
//插入自身数据
RoleTree roleTree = new RoleTree();
roleTree.setAncestor_id(record.getId());
roleTree.setLevel(0);
roleTree.setRole_id(record.getId());
roleTreeMapper.insert(roleTree);
if (record.getParent_role_id() == 0) {
//如果父级ID为0代表他是最根部的角色,则只插入自身数据
return;
}
//插入自身和父级关联的数据
roleTree.setAncestor_id(record.getParent_role_id());
roleTree.setLevel(1);
roleTree.setRole_id(record.getId());
roleTreeMapper.insert(roleTree);
//查询父级的所有上级
List roleTreeList = roleTreeMapper.selectAllParentOfRole(record.getParent_role_id());
//循环父级并和新插入的数据关联
for (RoleTree aRoleTreeList : roleTreeList) {
RoleTree r = new RoleTree();
r.setRole_id(record.getId());
r.setLevel(aRoleTreeList.getLevel() + 1);
r.setAncestor_id(aRoleTreeList.getAncestor_id());
roleTreeMapper.insert(r);
}
}
<select id="selectAllParentOfRole" resultMap="BaseResultMap" parameterType="java.lang.Integer">
select
<include refid="Base_Column_List"/>
from b_role_tree_relation
where role_id = #{role_id,jdbcType=INTEGER}
and level != 0
select>
<select id="selectAllChildOfRole" resultMap="BaseResultMap" parameterType="java.lang.Integer">
select
<include refid="Base_Column_List"/>
from b_role_tree_relation
where ancestor_id = #{ancestor_id,jdbcType=INTEGER}
and level != 0
select>
<select id="deleteTreeRelationOfRole" parameterType="java.lang.Integer">
delete from b_role_tree_relation where role_id in (
select role_id from (SELECT role_id FROM b_role_tree_relation where ancestor_id= #{role_id,jdbcType=INTEGER} ) a
)
select>更新操作:
由于子角色在更新的时候,可能会从一个层级很深的角色变成根部角色或者根部的直属角色,如果使用更新不仅要删除原来数据,还要判断更新数据ID,因此我的做法是直接删除原有的所有关系,再重新插入新的关系
总结
虽然方案4处理起来较为麻烦,但是确实适用于各种业务的方案,而且他不会产生脏数据,维护以及管理时也能一目了然.