python数据分析之pandas数据合并
这一章节来介绍pandas中的DateFrame实现数据合并的操作,类似于SQL中的内连接、外连接的操作.
目录
- 1. 合并数据的方式
- 2. Merge合并方法
-
- 2.1 连接
-
- 2.1.1 直接用on连接
- 2.1.2 采用left_on 和 right_on连接
- 2.1.3 采用left_index 和 right_index连接
- 2.2 合并数据
-
- 2.2.1 多对一的数据合并
- 2.2.1 多对多的数据合并
- 3. concat合并数据
-
- 3.1 纵向表合并
- 3.1 横向表合并
- 4. 参考资料
1. 合并数据的方式
DataFrame中合并数据主要有两种方式 :Merge 、Concat
2. Merge合并方法
首先介绍一下merge方法的参数
pandas.merge(
right, #合并对象,dataframe或者series对象
how="inner",#合并类型
on= None,#连接键
left_on = None,#左连接键
right_on= None,
left_index=False,
right_index=False,
sort=False,
suffixes=("_x", "_y"),
copy=True,
indicator= False,
validate = None
)
参数说明
- right:合并对象,DataFrame 对象或 Series 对象。
- how:合并类型,可以是左连接 left,右连接 right,外部连接 outer,内部连接 inner,类似于数据库的左、右、外、内连接。
- on:标签、列表或者数组,默认为none,是指dataframe对象连接的列或索引列名称。
- left_on: 标签、列表或数组,默认值为 None。要连接的左数据集的列或索引级名称:也可以是左数据集长度的数组或数组列表。
- right_on: 标签、列表或数组,默认值为None。要连接的右数据集的列或索引级名称,也可以是右数据集长度的数组或数组列表。
- left_index:布尔型,默认为False。使用左数据集的索引作为连接键。如果是多重索引,则其他数据中的键数(索引或列数)必须匹配索引级別数。
- right_index: 布尔型,默认为False。使用右数据集的索引作为连接键。
- sort:布尔型,默认为False,在合并结果中按字典顺序对连接键进行排序。如果为 False,连接键的顺序取决于连接类型how参数。
- suffixes:元组类型,默认值为(_x,_y)。当左侧数据集和右侧数据集的列名相同时,数据合并后列名将带上“x”和“y”后级。
- copy:是否复制数据,默认值为True,如果为False,则不复制数据。
- indicator:布尔型或宇符串,默认值为False。如果值为True,则添加一个列以输出名为“Merge”的 Dataframe 対象,共中包合每一行信息。如果是字符串,将向輸出的 DataFrame 対象中添加包含每一行信息的列,并将列命名为字符型的值。
- validate:字符串,检查合并数据是否为指定类型。
2.1 连接
2.1.1 直接用on连接
import pandas as pd
#解决数据输出时列名不对齐的问题
pd.set_option('display.unicode.east_asian_width', True)
df1 = pd.DataFrame({'编号':['mr001','mr002','mr003'],
'语文':[110,105,109],
'数学':[105,88,120],
'英语':[99,115,130]})
print(df1)
df2 = pd.DataFrame({'编号':['mr002','mr001','mr003','mr004'],
'体育':[34.5,39.7,38,45]})
print(df2)
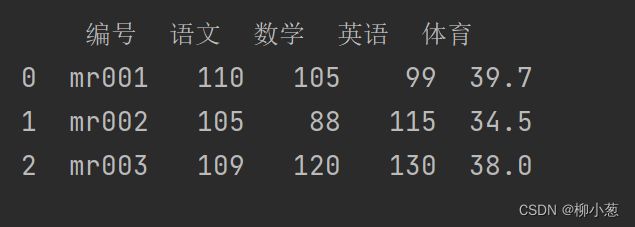
df_merge=pd.merge(df1,df2,on='编号')
print(df_merge)
用on的时候需要注意两个df表的关联键名称需要一样,这里df1 和 df2 关联键是‘编号’(过程中可使用how来控制是左、右、内、外连接)
结果如下:
2.1.2 采用left_on 和 right_on连接
import pandas as pd
#解决数据输出时列名不对齐的问题
pd.set_option('display.unicode.east_asian_width', True)
df1 = pd.DataFrame({'编号01':['mr001','mr002','mr003'],
'语文':[110,105,109],
'数学':[105,88,120],
'英语':[99,115,130]})
print(df1)
df2 = pd.DataFrame({'编号02':['mr002','mr001','mr003','mr004'],
'体育':[34.5,39.7,38,45]})
print(df2)
df_merge=pd.merge(df1,df2,left_on='编号01',right_on='编号02')
print(df_merge)
当关联键不同时,可以用left_on和 right_on的时候,需要两者同时出现,说明左右表的连接键。(过程中可使用how来控制是左、右、内、外连接)
结果如下:

2.1.3 采用left_index 和 right_index连接
import pandas
import pandas as pd
#解决数据输出时列名不对齐的问题
pd.set_option('display.unicode.east_asian_width', True)
df1 = pd.DataFrame({'编号01':['mr001','mr002','mr003'],
'语文':[110,105,109],
'数学':[105,88,120],
'英语':[99,115,130]})
print(df1)
df2 = pd.DataFrame({'编号02':['mr002','mr001','mr003','mr004'],
'体育':[34.5,39.7,38,45]})
print(df2)
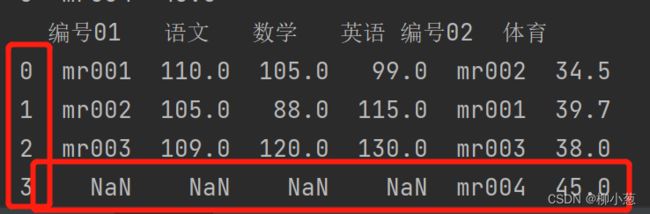
df_merge=pd.merge(df1,df2,how='outer',left_index=True,right_index=True)
print(df_merge)
使用left_index 和 right_index连接是指使用两张表的索引进行连接,当然需要两者同时出现。(过程中可使用how来控制是左、右、内、外连接)
结果如下:这里采用的外连接,大家可以看见连接的结果是对不上的。
2.2 合并数据
这一章节主要是通过how来控制合并数据,这一章节单独介绍是因为有些同学可能没有接触过SQL的左、右、内、外连接的数据合并方式,这里单独介绍一下。
2.2.1 多对一的数据合并
主要是通过连接键来控制数据合并的形式
import pandas as pd
#解决数据输出时列名不对齐的问题
pd.set_option('display.unicode.east_asian_width', True)
df1 = pd.DataFrame({'编号':['mr001','mr002','mr003'],
'学生姓名':['明日同学','高猿员','钱多多']})
print(df1)
df2 = pd.DataFrame({'编号':['mr001','mr001','mr003'],
'语文':[110,105,109],
'数学':[105,88,120],
'英语':[99,115,130],
'时间':['1月','2月','1月']})
print(df2)
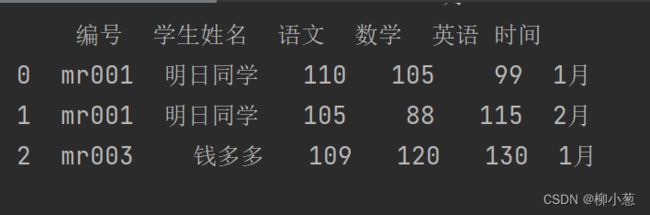
df_merge=pd.merge(df1,df2,on='编号')
print(df_merge)
这里的数据中,mr001的同学有2个成绩,我们需要一对多地展示2行数据。
结果如下:
2.2.1 多对多的数据合并
主要是指两个数据集中的列数据不是一对一的关系,是多对多的关系,这个时候我们需要将他们都连接起来一起展示。
import pandas as pd
#解决数据输出时列名不对齐的问题
pd.set_option('display.unicode.east_asian_width', True)
df1 = pd.DataFrame({'编号':['mr001','mr002','mr003','mr001','mr001'],
'体育':[34.5,39.7,38,33,35]})
print(df1)
df2 = pd.DataFrame({'编号':['mr001','mr002','mr003','mr003','mr003'],
'语文':[110,105,109,110,108],
'数学':[105,88,120,123,119],
'英语':[99,115,130,109,128]})
print(df2)
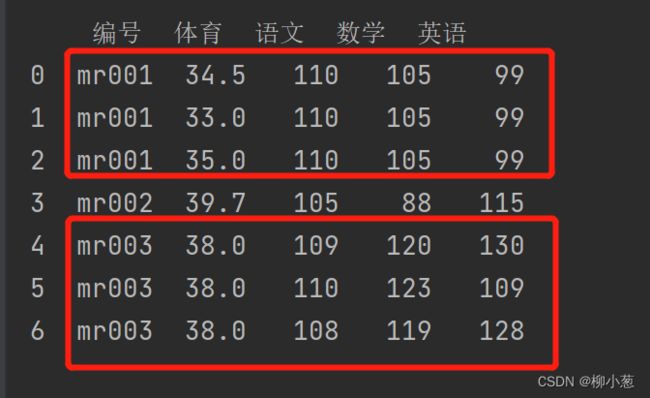
df_merge=pd.merge(df1,df2,on='编号')
print(df_merge)
这里两个数据表中的数据都是多对多的关系,这里将他们一一匹配出来。
结果如下:
3. concat合并数据
介绍一下concat参数
pandas.concat(
objs,
axis=0,
join="outer",
ignore_index:False,
keys=None,
levels=None,
names=None,
verify_integrity: False,
sort: False,
copy: True
)
参数说明
- objs:series、 dataframe 或Panel 对象的序列或映射。如果传递一个字典,则排序的键将用作键参数。
- axis : 拼接的方式,axis=1表示行,axis=0 表示列,默认值为0
- join :值为inner(交集)或outer(联合),处理其他轴上的索引方式。默认值为 outer。
- ignore_index:布尔值,默认值为False。需要保留索引时,索引值为0,⋯,n-1;如果为True,则忽略索引。
- keys:序列,默认值无。使用传递的键作为最外层构建层次索引。如果为多索引,应该使用元组。
- levels:序列列表,默认值无。用于构建 Multiindex 参数的特定级別(唯一值)。否则,它们将从键推断。
- names: list 列表,默认值为None,结果层次索引中的级别的名称。
- verity_ integrity :布尔值,默认值为False。检查新连接的轴是否包含重复项。
- sort :布尔值,默认值为True(在1.0.0以后版本默认值为False,即不排序)。如果连接为外连接时 Cjoin-outer),则对未对齐的非连接轴进行排序;如果连接为内连接时 (join=inner),该参数不起作用。
- copy:是否复制数据,默认值为True;如果为False,则不复制数据。
3.1 纵向表合并
import pandas as pd
#解决数据输出时列名不对齐的问题
pd.set_option('display.unicode.east_asian_width', True)
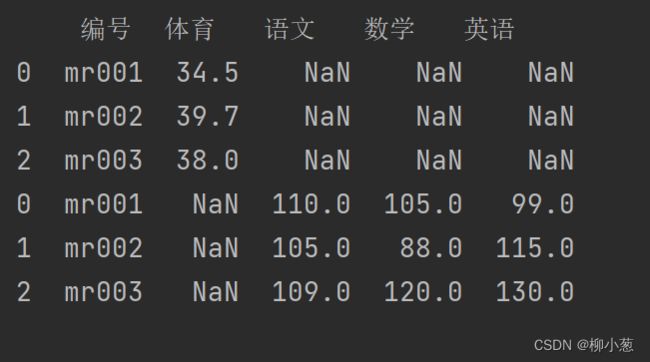
df1 = pd.DataFrame({'编号':['mr001','mr002','mr003'],
'体育':[34.5,39.7,38]})
print(df1)
df2 = pd.DataFrame({'编号':['mr001','mr002','mr003'],
'语文':[110,105,109],
'数学':[105,88,120],
'英语':[99,115,130]})
print(df2)
df_concat=pd.concat([df1,df2],axis=0)
print(df_concat)
将俩个数据集纵向进行合并,结果如下:
3.1 横向表合并
import pandas as pd
#解决数据输出时列名不对齐的问题
pd.set_option('display.unicode.east_asian_width', True)
df1 = pd.DataFrame({'编号':['mr001','mr002','mr003'],
'体育':[34.5,39.7,38]})
print(df1)
df2 = pd.DataFrame({'编号':['mr001','mr002','mr003'],
'语文':[110,105,109],
'数学':[105,88,120],
'英语':[99,115,130]})
print(df2)
df_concat=pd.concat([df1,df2],axis=1)
print(df_concat)
通过控制axis来控制表的横向和纵向连接

总的来说,concat多用于长度相同的数据集进行横向连接。
4. 参考资料
《python数据分析从入门到实践》