Pandas学习笔记(四)concat&append&merge合并
文章目录
- 前言
- 一、concat()方法
-
- 1.导入库&建表
- 2.axis 纵向&横向合并
- 3.join 连接合并
-
- 1)重定义表
- 2)outer合并
- 3)inner合并
- 4.join_axes合并
- 二、append()方法
-
- 1.引入库&建表
- 2.append() 纵向合并
-
- 1)纵向合并两张表
- 2)纵向合并多张表
- 3)添加序列
- 三、merge()方法
-
- 1.导入库&建表
- 2.一组关键词合并
- 3.两组关键字合并
- 4.indicator 显示合并方式
- 5.根据index序列合并
- 6.suffixes解决名字重叠
前言
本次主要介绍三种合并的方法concat&append&merge
一、concat()方法
1.导入库&建表
import numpy as np
import pandas as pd
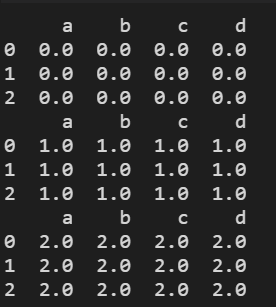
df0 = pd.DataFrame(np.ones((3, 4)) * 0, columns=["a", "b", "c", "d"])
df1 = pd.DataFrame(np.ones((3, 4)) * 1, columns=["a", "b", "c", "d"])
df2 = pd.DataFrame(np.ones((3, 4)) * 2, columns=["a", "b", "c", "d"])
print(df0)
print(df1)
print(df2)
结果显示:
2.axis 纵向&横向合并
res = pd.concat([df0, df1, df2], axis = 0, ignore_index = True) # 0纵向(上下) , 1横向(左右)
# ignore_index 将序列进行重新排序
print(res)
结果显示:

3.join 连接合并
1)重定义表
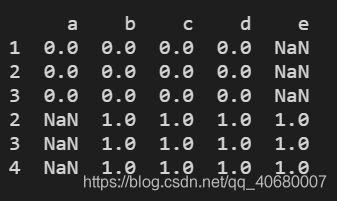
df0 = pd.DataFrame(np.ones((3, 4)) * 0, columns=["a", "b", "c", "d"], index = [1, 2, 3])
df1 = pd.DataFrame(np.ones((3, 4)) * 1, columns=["b", "c", "d", "e"], index = [2, 3, 4])
print(df0)
print(df1)
结果显示:

2)outer合并
res = pd.concat([df0, df1], join='outer') # 默认方法outer 相当于并集
print(res)
结果显示:
3)inner合并
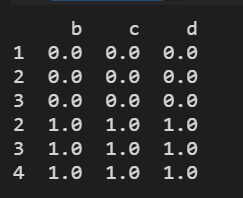
res = pd.concat([df0, df1], join='inner') # inner 相当于交集
print(res)
结果显示:
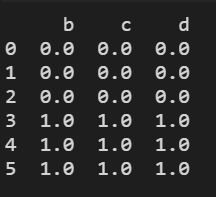
res = pd.concat([df0, df1], join='inner', ignore_index=True)
print(res)
结果显示:
4.join_axes合并
当前版本pandas中的concat()已经弃用
二、append()方法
1.引入库&建表
import numpy as np
import pandas as pd
df0 = pd.DataFrame(np.ones((3, 4)) * 0, columns=["a", "b", "c", "d"])
df1 = pd.DataFrame(np.ones((3, 4)) * 1, columns=["a", "b", "c", "d"])
df2 = pd.DataFrame(np.ones((3, 4)) * 1, columns=["a", "b", "c", "d"])
df3 = pd.DataFrame(np.ones((3, 4)) * 1, columns=["b", "c", "d", "e"], index=[2, 3, 4])
2.append() 纵向合并
1)纵向合并两张表
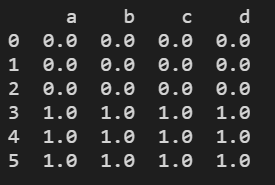
res = df0.append(df1, ignore_index=True) # 向df0向下添加df1
print(res)
结果显示:
2)纵向合并多张表
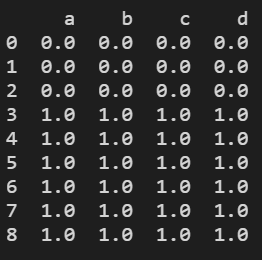
res = df0.append([df1, df2], ignore_index=True) # df0向下添加df2,df2
print(res)
结果显示:
3)添加序列
s1 = pd.Series([1, 2, 3, 4], index = ["a", "b", "c", "d"]) # 序列
res = df1.append(s1, ignore_index=True)
print(res)
结果显示:

三、merge()方法
1.导入库&建表
import pandas as pd
2.一组关键词合并
1)建表
left = pd.DataFrame({"key": ["K0", "K1", "K2", "K3"],
"A": ["A0", "A1", "A2", "A3"],
"B": ["B0", "B1", "B2", "B3"]})
right = pd.DataFrame({"key": ["K0", "K1", "K2", "K3"],
"C": ["C0", "C1", "C2", "C3"],
"D": ["D0", "D1", "D2", "D3"]})
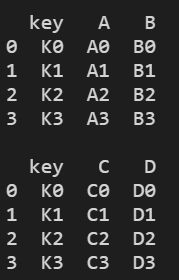
print(left)
print("")
print(right)
结果显示:
2)合并
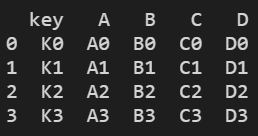
res = pd.merge(left, right, on="key") # 在key值这一列进行合并
print(res)
结果显示:
3.两组关键字合并
1)建表
# 有两个列关键字值
left = pd.DataFrame({"key1": ["K0", "K0", "K1", "K2"],
"key2": ["K0", "K1", "K0", "K1"],
"A": ["A0", "A1", "A2", "A3"],
"B": ["B0", "B1", "B2", "B3"]})
right = pd.DataFrame({"key1": ["K0", "K1", "K1", "K2"],
"key2": ["K0", "K0", "K0", "K0"],
"C": ["C0", "C1", "C2", "C3"],
"D": ["D0", "D1", "D2", "D3"]})
print(left)
print("")
print(right)
结果显示:

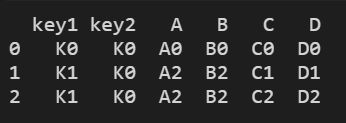
2)4种合并
how = [“left”, “right”, “inner”, “outer”]
默认:inner合并
res = pd.merge(left, right, on=["key1", "key2"], how="inner")
# merge合并默认inner 交集
print(res)
结果显示:
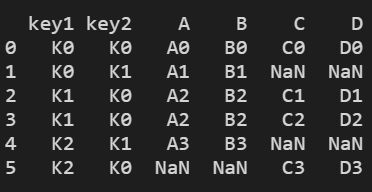
outer合并
res = pd.merge(left, right, on=["key1", "key2"], how="outer") # 并集
print(res)
结果显示:
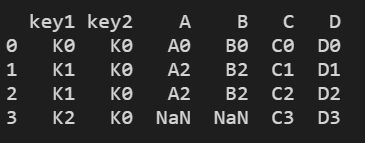
right合并
res = pd.merge(left, right, on=["key1", "key2"], how="right") # 基于right的key值进行合并
print(res)
结果显示:
left合并
res = pd.merge(left, right, on=["key1", "key2"], how="left") # 基于left的key值进行合并
print(res)
结果显示:

4.indicator 显示合并方式
1)建表
df1 = pd.DataFrame({"col1": [0, 1], "col_left": ["a", "b"]})
df2 = pd.DataFrame({"col1": [1, 2, 2], "col_right": [2, 2, 2]})
print(df1)
print("")
print(df2)
结果显示:

2)indicator
res = pd.merge(df1, df2, on="col1", how="outer", indicator=True)
# indicator 默认为False
# True 显示有数据的部分,如何合并的
print(res)
结果显示:

3)更改indicator名
res = pd.merge(df1, df2, on="col1", how="outer", indicator="indicator column") # 进行命名
print(res)
结果显示:

5.根据index序列合并
1)建表
left = pd.DataFrame({"A": ["A0", "A1", "A2", "A3"],
"B": ["B0", "B1", "B2", "B3"]},
index = ["K0", "K1", "K2", "K3"])
right = pd.DataFrame({"C": ["C0", "C2", "C3", "C4"],
"D": ["D0", "D2", "D3", "D4"]},
index = ["K0", "K2", "K3", "K4"])
print(left)
print("")
print(right)
结果显示:
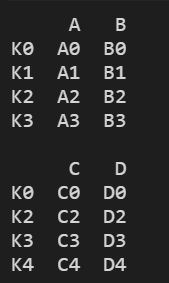
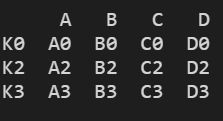
2)左右表index outer合并
res = pd.merge(left, right, left_index=True, right_index=True, how="outer")
print(res)
结果显示:
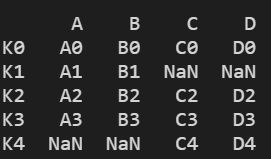
3)左右表index inner合并
res = pd.merge(left, right, left_index=True, right_index=True, how="inner")
print(res)
结果显示:
6.suffixes解决名字重叠
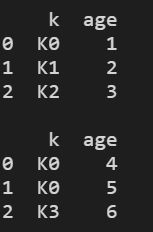
1)建表
boys = pd.DataFrame({"k": ["K0","K1", "K2"], "age":[1, 2, 3]})
girls = pd.DataFrame({"k": ["K0","K0", "K3"], "age":[4, 5, 6]})
print(boys)
print("")
print(girls)
结果显示:
2)增加后缀
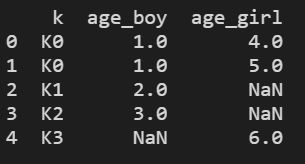
res = pd.merge(boys, girls, on="k", suffixes=["_boy","_girl"], how="inner")
# suffixes 后缀
print(res)
结果显示: